Using gaze to predict text readability
Ana V. Gonz´alez-Gardu˜no University of Copenhagen Department of Computer Science
Anders Søgaard University of Copenhagen Department of Computer Science
Abstract
We show that text readability prediction improves significantly from hard param-eter sharing with models predicting first pass duration, total fixation duration and regression duration. Specifically, we in-duce multi-task Multilayer Perceptrons and Logistic Regression models over sen-tence representations that capture various aggregate statistics, from two different text readability corpora for English, as well as the Dundee eye-tracking corpus. Our ap-proach leads to significant improvements over Single task learning and over previ-ous systems. In addition, our improve-ments are consistent across train sample sizes, making our approach especially ap-plicable to small datasets.
1 Introduction
When we read, our eyes move rapidly back and forth between fixations. These movements are called saccades. The distribution of fixations and saccades can provide us with important insight about the reader and the text being read. For exam-ple, long regressive eye movements, which typi-cally involve regressing more than 10 letter spaces (Rayner,1998), may indicate that the reader is fac-ing some difficulty in understandfac-ing the text ( Fra-zier and Rayner, 1982; Rayner, 2012). In addi-tion, regressions have been shown to occur dur-ing the disambiguation of a sentence (Frazier and Rayner,1982). This relationship between text and eye movements, has led to an influx of studies in-vestigating the use of eye tracking data to improve and test computational models of language i.e. Barrett et al.(2016);Demberg and Keller(2008); Klerke et al. (2015). In this study we aim to in-corporate eye movement data for the task of
auto-matic readability assessment.Automatic readabil-ity assessment is the task of automatically label-ing a text with a certain difficulty level. An accu-rate and robust system has many potential applica-tions, for example it can help educators obtain ap-propriate reading materials for students with nor-mal learning capacities, as well as students with disabilities and language learners. It can also be used to assess the performance of machine trans-lation, text simplification and language generation systems. Eye-tracking data has previously been used to evaluate readability models (Green,2014; Klerke et al.,2015), however, our main contribu-tion is to explore the way that eye tracking data can help improve models for readability assessment through multi-task learning (Caruana, 1997) and parser metrics based on the surprisal theory of syn-tactic complexity (Hale,2001, 2016). Multi task learning allows the model to learn various tasks in parallel and improve performance by sharing pa-rameters in the hidden layers.
The work most related to ours is bySingh et al. (2016), who used eye tracking measures taken from the Dundee corpus in order to predict word by word reading times for each sentence. Sub-sequently, they used these word by word read-ing times as features for predictread-ing readability. The two tasks were performed separately, and their feature representations were different from the ones presented here. In contrast, we present a model that predicts gazeandsentence-level read-ability simultaneously.
We use gaze data from the Dundee cor-pus (Kennedy et al., 2003) and two different datasets for the readability prediction task: aligned Wikipedia sentences used for the task of text sim-plification byCoster and Kauchak(2011) and the OneStopEnglish dataset used byVajjala and Meur-ers(2014).
Contributions This is, to the best of our knowl-edge, the first application of multi-task learning to readability prediction. Our model is also different from previous applications of multi-task learning to natural language processing in that we combine a classification task and a regression task. We ex-periment with two multi-task learning algorithms, namely hard parameter sharing for multi-layered perceptrons (Caruana,1997) and a novel approach to hard parameter sharing between logistic and lin-ear regression. We evaluate our models on Simple Wikipedia and the OneStopEnglish corpus. Fi-nally, we present learning curves that show that the improvements are robust across different sam-ple sizes.
2 Experiments
Data Our target task is sentence-level readabil-ity prediction, i.e. a binary classification problem of sentences into easy-to-read and hard-to-read.
Our main corpus is a sentence-aligned cor-pus of 137,000 simple versus normal English sentences from Wikipedia (Coster and Kauchak, 2011). Similar datasets have been used in the past, e.g., in Ambati et al. (2016) and Hwang et al. (2015). The easy-to-read sentences were taken from Simple Wikipedia and paired with sentences from the standard Wikipedia using cosine similar-ity.
In addition, we also evaluate our models on the OneStopEnglish corpus (Vajjala and Meurers, 2014), specifically the elementary-intermediate and elementary-advanced sentence pairs. This dataset has been used for readability assessment (Vajjala and Meurers, 2014) using the WeeBit model presented by (Vajjala and Meurers,2012), so we compare our results with theirs.
Feature representation In this study, features known to affect the complexity of text, such as syntactic, lexical and total surprisal (Hale, 2001; Demberg and Keller,2008), were used. Most of these features were extracted using a probabilis-tic top-down parser introduced by Roark (2001). After removing duplicate sentences and sentences with typos, the final corpus used was of about 80,000 sentence pairs. The features extracted are shown in table 1.
The prefix probabilityof wordwnis explained
by Jelinek and Lafferty (1991) as the probability thatwnoccurs as a prefix of some string generated
by a grammar. It is the sum of the probabilities of
Features
1. Prefix probability -word1 2. Total surprisal - word1 3. Syntactic Surprisal -word1 4. Lexical Surprisal - word1 5. Ambiguity - word1 6. Prefix probability -word2 7. Total surprisal - word2 8. Syntactic Surprisal - word2 9. Lexical Surprisal - word2 10. Ambiguity - word2 11. Total surprisal – sent mean 12. Syntactic Surprisal – sent mean 13. Lexical Surprisal – sent mean 14. Ambiguity – sent mean 15. Total surprisal – sent sd 16. Syntactic Surprisal – sent sd 17. Lexical Surprisal – sent sd 18. Ambiguity – sent sd 19. Sentence length 20. Ave. Word length 21. Parse Tree height
22. Num of Subordinate clauses(SBARs) 23. Num of Noun phrases
24. Num of Verb phrases 25. Num of Prepositional phrases 26. Num of Adv phrases 27. Ratio nouns 28. Ratio verbs 29. Ratio adjectives 30. Ratio pronouns 31. Ratio adverbs 32. Ratio Det
33. Mean Age of Acquisition
Table 1: Features extracted for the readability data.
all trees from the first word to the current word. Surprisalis then the difference between the log of the prefix probability ofwnandwn−1.
If we describe D(G, W[1, n]) as the set of all possible leftmost derivations D with respect to probabilistic context free grammarG and whose last step used a production with terminal Wn.
We can then express the prefix probability of W[1, n] with respect to G as P PG(W[1, n]) =
P
D∈D(G,W[1,n])ρ(D), whereρ(D) is the
proba-bility of the derivation of a certain tree. The total surprisal ofWnis then defined as:
SG(Wn) =−logP PP PG(W[1, n]) G(W[1, n−1])
Syntactic surprisalandlexical surprisalare calcu-lated to account for high surprisal scores (Roark et al., 2009). AsRoark et al. (2009) mentions, a word may surprise because it is unconventional, or because it occurs in an unusual context.
[image:2.595.335.498.59.405.2]components of surprisal, the incremental parser calculates partial derivations immediately before wordWnis integrated into the syntactic structure.
Syntactic surprisal (SynSG(Wn)) is defined as:
−log P
D∈D(G,W[1,n])ρ(D[1,|D| −1])
P PG(W[1, n−1])
and lexical surprisal (LexSG(Wn)) as:
−logP P PG(W[1, n])
D∈D(G,W[1,n])ρ(D[1,|D| −1])
Where D[1,|D| − 1] is the set of the partial derivations before each word is integrated into the structureD(G, W[1, n]). Total surprisal turns out to be sum of syntactic surprisal and lexical sur-prisal.
We also obtain an entropy score using the parser. Entropy over a set of derivations D, de-noted asH(D), quantifies the uncertainty over the partial derivations. We call this featureAmbiguity, defined as:
− X
D∈D
ρ(D) P
D0∈Dρ(D0)log
ρ(D) P
D0∈Dρ(D0)
Furthermore, features corresponding to the first and second words were included, as the initial words in a sentence allow the reader to make pre-liminary guesses of what the structure will be for the rest of the sentence, although these predic-tions can often turn out to be wrong. In addition, mean syntactic scores and standard deviations for all words in the sentence are included as features. We also include the mean age of acquisition for the words in a given sentence, using data from Kuper-man et al.(2012). Finally, we include basic counts and ratios used previously in readability prediction such as sentence length, parse tree height, num-ber of SBAR’s, noun phrases, verb phrases, among others .
In order to predict gaze, we extract the features seen in Table1from the Dundee corpus. As men-tioned earlier, these features offer a good repre-sentation of cognitive load, which is also reflected in reading times. A feature vector of size 33 was built for each sentence, and this information was used in order to predict an average first pass du-ration, regression path duration and total fixation duration.
First pass durationrefers to the sum of all fix-ations on a region once the region is first entered until it is left. Regression path duration includes regressions made out of a region prior to moving forward in the text and total fixation duration is the sum of all fixations in the region including, re-gressions to that region. As mentioned inRayner et al.(2006), these measures typically concern re-search questions focusing on sentence or discourse processing.
Logistic/linear regression and MLPs Logistic Regression (LR) models have been widely used in document level readability classification i.e. Feng et al. (2010) and (Xia et al., 2016). LR models are linear models and can be thought of as single-layer perceptrons with softmax or sigmoid activa-tion funcactiva-tions. The objective is typically to mini-mize a cross-entropy loss function. The same ar-chitecture can be used for linear regression, how-ever, when trained to minimize mean squared er-ror. Here, we compare LR with a 3-layered Multi Layer Perceptron (MLP). For our MLP architec-ture, we use sigmoid activation at the input and output layers and use ReLu activation in the hid-den layer. The hidhid-den layer contains 100 neu-rons. All models presented here use the Adam op-timizer, and a drop-out rate of 0.5. We also use Adam to learn logistic and linear regression mod-els.
As already mentioned, we go beyond single-task LR and MLP models and present two multi-task learning architectures with heteroge-neous loss functions (cross-entropy and minimum squared error). In multi-task learning (Caruana, 1997), the training signals of one task are used as an inductive bias in order to improve the general-ization of another task. Specifically, we use the the task of gaze prediction in order to improve the generalization of readability prediction.
Multi-task MLP Our multi-task learning archi-tecture is identical to that ofCaruana(1997) and Collobert et al.(2011), i.e., two MLPs that share all parameters in their hidden layers. The only difference is that one of the MLPs in our case is trained to minimize a minimum squared error to predict gaze statistics.
LR models can be thought of as single-layer per-ceptrons. We tie a single-layer perceptron with sigmoid activation to another single-layer percep-tron with linear activation by sharing their single layer and giving a higher weight to our main task. While this is in fact a simpler model than the deep multi-task learning model above, this model has, to the best of our knowledge, not been suggested before, and in many ways, it is surprising that it works.
Baselines Ambati et al. (2016) obtained 78.87 percent accuracy on the Wikipedia dataset. They use features extracted from a Combinatory Cate-gorical Grammar (CCG) parser. We also compare our results to Vajjala and Meurers (2014), who use their WeeBit model in order to predict read-ability at the sentence level. In addition, for the Wikipedia dataset, we include the best results from Singh et al. (2016) as it is the study most related to ours.
3 Results
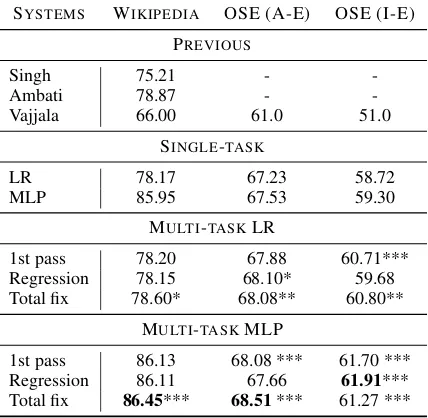
Our results are shown in Table2.
For the Wikipedia corpus, our best multi-task learning system shows an improvement in accu-racy over previous work by about 8%. A big part of the improvement can be attributed to using a deep learning architecture. Single-task MLPs do about 8% better than logistic regression on this dataset, in absolute numbers. Multi-task learning buys us another .5%, absolute. For the advanced-elementary sentence pairs in the OneStopEnglish corpus, a slightly larger improvement is seen from task learning to single-task. For all multi-task systems, there is an improvement over the corresponding single-task system with at least two of the gaze inputs. The best result was achieved using Multi-Task MLP. Inclusion of gaze data im-proved our results about 2.6 % over the best single-task result.
We performed various paired T tests in order to assess whether or not the improvements ob-tained using multi-task learning was significant. We compared the results of each MTL model to its corresponding STL model. We report p values using asterisks in Table2. P values smaller than 0.001 are described using ***, ** indicate p val-ues ranging from 0.001 to 0.01 and p valval-ues from 0.01 to 0.5 are shown with *. No asterisk indicates that there was no statistically significant changes.
SYSTEMS WIKIPEDIA OSE (A-E) OSE (I-E) PREVIOUS
Singh 75.21 -
-Ambati 78.87 -
-Vajjala 66.00 61.0 51.0
SINGLE-TASK
LR 78.17 67.23 58.72
MLP 85.95 67.53 59.30
MULTI-TASKLR
1st pass 78.20 67.88 60.71***
Regression 78.15 68.10* 59.68
Total fix 78.60* 68.08** 60.80** MULTI-TASKMLP
1st pass 86.13 68.08 *** 61.70 *** Regression 86.11 67.66 61.91*** Total fix 86.45*** 68.51*** 61.27 ***
Table 2: Accuracy for all models. Most results obtained using MTL-MLP yield statistically sig-nificant improvements of STL-MLP (p <0.001).
4 Discussion
Performance of features The features extracted using the probabilistic top down parser have previ-ously been used in order to predict word by word reading times (Singh et al., 2016; Demberg and Keller, 2008), but have not been thoroughly ex-plored in the task of readability prediction. Here, we used surprisal and entropy, along with other low-level features in order to predict the reading level of single sentences. Using the STL-MLP, we predicted readability using feature groups, sepa-rated by syntactic features and low level features. Our syntactic features include features 1-18, while our low level features are 19-33 in table 1. We found that low level features are more predictive for our datasets than syntactic features, however, it is a combination of both that yields the best re-sults. These results can be seen in table3.
[image:4.595.309.523.64.273.2]Feature Set Wikipedia OSE I-E OSE A-E Syntactic Features 60.35 54.90 59.79 Low level Features 78.15 57.30 65.17 All Features 85.95 59.30 67.53
Table 3: Accuracy when predicting readability us-ing features in groups. The results show, that a combination of both sets of features provide the best result.
eval-uation, where each feature was used to predict readability using the STL-MLP model. The 10 most predictive features for the Wikipedia dataset are presented in table4. The results reaffirm the previous finding that although syntactic features are predictive of readability, low level features re-main the most predictive.
Wikipedia
Feature Accuracy
Ratio Verbs 67.90
Ratio Adjectives 66.46 Sentence Length 61.96
Ratio Adverbs 57.53
[image:5.595.327.501.113.363.2]Mean Age of Acquisition 57.34 Average Word Length 56.17 Ambiguity – sent SD 55.66 Lexical suprisal – sent SD 55.37 Num of verb phrases 55.13 Ambiguity Sent Mean 55.00
Table 4: Accuracy on Wikipedia dataset when pre-dicting readability using single features.
Effects of using gaze data The main objective of this study was to explore how the use of eye tracking data improved our readability prediction model. Using the Dundee eye tracking corpus, we were able to learn models for predicting an aver-age first pass duration, total regression to dura-tion, and total fixation duration for a given sen-tence in our readability datasets. Using hard pa-rameter sharing, we learned to predict a readabil-ity label and gaze simultaneously. This method allows us to exploit the information contained in one task to better generalize another. Our results demonstrate that gaze data does improve readabil-ity models significantly.
Learning curves In figure 1 we compare the learning curves for the best MTL and STL mod-els for each dataset. We show the accuracy on both validation sets using varying amounts of train samples. The first train sample used consisted of 100 sentences. At this small sample size, the ef-fect of the gaze data is more clear. For example, for the Wikipedia dataset the validation accuracy using 100 samples is about 74.5 % for the MTL MLP system, while for the STL MLP system, the accuracy is about 10 % lower. At about 20,000 samples the difference in performance between the two systems begins to level off, however, MTL re-mains slightly higher the entire time. This is in line with Caruana(1997), who mentions that the
[image:5.595.105.261.167.304.2]improvements using MTL are typically stronger when using smaller sample sizes.
Figure 1: Learning curves for the OSE A-E and Wikipedia datasets varying the train sample size. The first sample size consisted of 100 sentences.
Similar results can be seen for the Advanced-Elementary sentence pairs. We begin training our model on about 100 samples and incrementally in-creased the train set size. Neither of the models achieve high accuracy, however, the MTL system improves the result about 5 %, and as the training set size increases, this trend persists. Similar re-sults are observed for the Intermediate-Advanced pairs.
5 Conclusion
References
Ram Bharat Ambati, Siva Reddy, and Mark Steedman. 2016. Assessing relative sentence complexity using
an incremental ccg parser. In Proceedings of the
2016 Conference of the North American Chapter of the Association for Computational Linguistics: Hu-man Language Technologies, pages 1051–1057. Maria Barrett, Joachim Bingel, Frank Keller, and
An-ders Søgaard. 2016. Weakly supervised
part-of-speech tagging using eye-tracking data.
Rich Caruana. 1997. Multitask learning. Machine Learning, 28(41).
Ronan Collobert, Jason Weston, L´eon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug):2493–2537.
William Coster and David Kauchak. 2011. Simple
en-glish wikipedia: A new text simplification task. In
Proceedings of the 49th Annual Meeting of the Asso-ciation for Computational Linguistics:shortpapers, pages 665–669.
Vera Demberg and Frank Keller. 2008. Data from eye-tracking corpora as evidence for theories of syntactic processing complexity. Cognition, 109(2):192–210. Lijun Feng, Martin Jansche, Matt Huenerfauth, and No´emie Elhadad. 2010. A comparison of features for automatic readability assessment. In Proceed-ings of the 23rd International Conference on Com-putational Linguistics: Posters, pages 276–284. As-sociation for Computational Linguistics.
Lyn Frazier and Keith Rayner. 1982. Making and cor-recting errors during sentence comprehension: Eye movements in the analysis of structurally ambiguous
sentences.Cognitive psychology, 14(2):178–210.
Matthew J. Green. 2014.An eye-tracking evaluation of
some parser complexity metrics. InProceedings of
the 3rd Workshop on Predicting and Improving Text Readability for Target Reader Populations (PITR), page 38–46. Association for Computational Linguis-tics.
John Hale. 2001. A probabilistic earley parser as a
psy-cholinguistic model. InProceedings of the second
meeting of the North American Chapter of the Asso-ciation for Computational Linguistics on Language technologies, pages 1–8. Association for Computa-tional Linguistics.
John Hale. 2016. Information-theoretical complexity
metrics.Language and Linguistics Compass, 10(9).
William Hwang, Hannaneh Hajishirzi, Mari Ostendorf, and Wei Wu. 2015. Aligning sentences from stan-dard wikipedia to simple wikipedia. In Proceed-ings of the 2015 Conference of the North American Chapter of the Association for Computational Lin-guistics (NAACL).
Frederick Jelinek and John D. Lafferty. 1991. Compu-tation of the probability of initial substring genera-tion by stochastic context-free grammars. Computa-tional Linguistics, 17(3):315–323.
Alan Kennedy, Robin Hill, and Jo¨el Pynte. 2003. The dundee corpus. Proceedings of the 12th European conference on eye movement.
Sigrid Klerke, Sheila Castilho, Maria Barrett, and An-ders Søgaard. 2015. Reading metrics for estimating
task efficiency with mt output. In Conference on
Empirical Methods in Natural Language Process-ing, page 6.
Victor Kuperman, Hans Stadthagen-Gonzalez, and Marc Brysbaert. 2012. Age-of-acquisition ratings
for 30,000 english words. Behavior Research
Meth-ods, 44(4).
Keith Rayner. 1998. Eye movements in reading and
information processing: 20 years of research.
Psy-chological Bulletin, 124(3).
Keith Rayner. 2012. Eye movements in reading: Per-ceptual and language processes. Elsevier.
Keith Rayner, Kathryn H Chace, Timothy J Slattery, and Jane Ashby. 2006. Eye movements as reflec-tions of comprehension processes in reading. Scien-tific studies of reading, 10(3):241–255.
Brian Roark. 2001. Probabilistic top-down parsing
and language modeling.Computational Linguistics,
27(2).
Brian Roark, Asaf Bachrach, Carlos Cardenas, and Christophe Pallier. 2009. Deriving lexical and syntactic expectation-based measures for
psycholin-guistic modeling via incremental top-down parsing.
In Proceedings of the 2009 Conference on Empiri-cal Methods in Natural Language Processing, page 324–333. Association for Computational Linguis-tics.
Abhinav Deep Singh, Poojan Mehta, Samar Husain, and Rajakrishnan Rajkumar. 2016. Quantifying sentence complexity based on eye-tracking
mea-sures. InProceedings of the Workshop on
Compu-tational Linguistics for Linguistic Complexity, page 202–212.
Sowmya Vajjala and Detmar Meurers. 2012. On im-proving the accuracy of readability classification
us-ing insights from second language acquisition. In
The 7th Workshop on the Innovative Use of NLP for Building Educational Applications, page 163–173. Sowmya Vajjala and Detmar Meurers. 2014.
Readabil-ity assessment for text simplification. International
Journal of Applied Linguistics, 165(2).