University of California
Los Angeles
eel
: Tools for Debugging, Visualization
and Verification of Event-Driven Software
A thesis submitted in partial satisfaction of the requirements for the degree Master of Science in Computer Science
by
Ryan Brice Cunningham
c
Copyright by Ryan Brice Cunningham
The thesis of Ryan Brice Cunningham is approved.
Jens Palsberg
Rupak Majumdar
Eddie Kohler, Committee Chair
University of California, Los Angeles 2005
Table of Contents
1 Introduction . . . 1
1.1 Programming with Threads . . . 2
1.1.1 Problem with Threads . . . 2
1.2 Programming with Events . . . 3
1.2.1 Problem with Events . . . 6
1.3 Related Work . . . 8
1.4 Our Approach . . . 9
2 The Explicit Event Library: libeel . . . 12
2.1 Design Points . . . 12
2.1.1 libevent . . . 13
2.1.2 libeel . . . 14
2.2 The libeel Interface . . . 16
2.3 Implementation . . . 20
2.4 Limitations . . . 20
3 Visualizing Control Flow: eelstatechart . . . 22
3.1 The Chart . . . 22
3.2 Implementation . . . 30
3.3 Limitations . . . 34
4.1 BLAST . . . 38
4.2 Program Transformations . . . 39
4.2.1 Independent State Transformation . . . 40
4.2.2 Full Program Transformation . . . 40
4.3 Safety Properties . . . 47
4.3.1 Proper Library Use . . . 47
4.3.2 Group Identifier Leaks . . . 48
4.3.3 File Descriptor Usage . . . 50
4.4 Experimental Results . . . 52
4.4.1 crawl . . . 52
4.4.2 plb . . . 56
4.5 Limitations . . . 58
4.6 Summary . . . 59
5 Debugging with eel: eelgdb . . . 60
5.1 eelgdb . . . 61
5.2 Implementation . . . 64
5.3 Limitations . . . 66
6 Discussion . . . 67
6.1 Duality . . . 68
6.2 Working With CIL and BLAST . . . 69
7 Conclusion . . . 73
A Appendix of eelstatecharts . . . 75
List of Figures
1.1 A simple HTTP fetch program written using a hypothetical thread
library. “. . . ” signifies where code has been omitted for brevity. . 3
1.2 Part of a simple HTTP fetch program adapted from crawl-0.4 [Proa]. 5 2.1 The entire libeel C interface. . . 17
2.2 A typical libeel program. Error checking is also omitted. . . 19
3.1 Chart g0 from plb-0.3 [plb]. . . 23
3.2 Code from plb.c,main, that corresponds to Figure 3.1 and Figure 3.4. 24 3.3 Code from plb session.c, new client, that corresponds to Fig-ure 3.1 and the starting point of FigFig-ure 3.7. . . 25
3.4 Chart g1 from plb-0.3 [plb]. . . 26
3.5 Function body of periodic cleanup, from plb cleanup.c, that cor-responds to Figure 3.4 and the starting point of Figure 3.6. . . 27
3.6 Chart g2 from plb-0.3 [plb]. . . 27
3.7 Chart g3 from plb-0.3 [plb]. . . 28
3.8 Pseudocode for labeling callgraph with libeel information. . . 32
3.9 Pseudocode for visiting a chart. . . 33
3.10 eelstatechart DOT output for chart g2 of plb. . . 34
4.1 Example of the output from the independent state transformation. 41 4.2 Chart g2 from plb-0.3 [plb]. . . 42
4.4 eel initialize/eel unitialize .spc instrumentation file. . . . 48
4.5 libeel group identifier new/delete .spc instrumentation file. . . 51
4.6 Chart g0 from crawl-0.4 [Proa]. . . 55
5.1 Two libeel event registration calls and their callbacks. . . 63
A.1 Chart g0 for eelstatechart from crawl-0.4 [Proa]. . . 76
A.2 Chart g1 for eelstatechart from crawl-0.4 [Proa]. . . 77
A.3 Chart g0 for eelstatechart from plb-0.3 [plb]. . . 77
A.4 Chart g1 for eelstatechart from plb-0.3 [plb]. . . 77
A.5 Chart g2 for eelstatechart from plb-0.3 [plb]. . . 78
A.6 Chart g3 for eelstatechart from plb-0.3 [plb]. . . 79
A.7 Chart g0 for eelstatechart from nch-0.01 [nch]. . . 80
List of Tables
2.1 Description oflibeel API functions. . . 18
3.1 eelstatechart arrow abbreviations and their meanings. . . 24
5.1 Commands added to gdb user interface. . . 61
Acknowledgments
Foremost I would like to thank my adviser, Professor Eddie Kohler, for guid-ance, ideas, and inspiration. I am grateful to him for encouraging me to think deeply and thoroughly. I would also like to thank the members of my committee, Professor Rupak Majumdar and Professor Jens Palsberg. To everyone in the 3436 Lab, Nikitas Liogkas, Robert Nelson, Jeff Fischer, Petros Efstathopoulos, Steve VanDeBogart, Shane Markstrum, Alex Warth, Ru-Gang Xu, Manav Ratan Mital, Michael Emmi, Brian Chin, and Professor Todd Millstein, thank you for discussing and entertaining. As well, thank you to Professor Gerald Popek for encouraging me to come back to school.
I would also like to acknowledge the Nation Science Foundation. This work was supported by NSF grant number 0427202, Event-Driven Software Quality.
To my family, thank you for the support and encouragement. Finally, to Rebekah, thanks for being patient, making the journey, and a lot more.
Abstract of the Thesis
eel
: Tools for Debugging, Visualization
and Verification of Event-Driven Software
by
Ryan Brice Cunningham
Master of Science in Computer Science University of California, Los Angeles, 2005
Professor Eddie Kohler, Chair
Using an event-driven model for high-concurrency I/O servers has the primary problem of programmability. Whereas a threaded model has the syntactic ap-pearance of serial execution, event-driven programs divide program control flow into a series of callback functions, making program behavior difficult to follow. In this thesis, we apply current program analysis techniques to preserve the event model while making it easier to read, write, debug and maintain. We designed an event notification library, the Explicit Event Library (libeel), to be amenable to program analysis and created tools based on it. We present three tools here and evaluate their effectiveness. eelstatechart analyzes a libeel program and produces a graphical chart of the program control flow. eelverify uses program transfor-mations and model checking to check safety properties of the program. Finally, eelgdb provides control-flow aware debugging support. The result sustain all the advantages of using the event-driven model while adding the important advantage of programmability.
CHAPTER 1
Introduction
This thesis presents tools to improve the programmability of event-driven high-concurrency I/O servers.
Event-driven programming was developed to allow server programs to handle concurrent network connections. Conventional operating system interfaces block when network operations can’t complete immediately. The blocked application is put to sleep until the operation completes. However, servers cannot afford to sleep for a single connection because they maintain multiple connections, some of which may be ready for I/O. Events solve this problem by returning a special value when an operation would block and by providing a polling mechanism to alert the application when operations can complete. The only blocking operation in the application is to poll for events using select or one of its variants (poll, kqueue [Lem01], epoll [epo], aio suspend [aio]). Typically the polling mechanism is wrapped with an interface that allows the application to post acallback function that will be executed once the operation can complete. A central dispatch loop repeatedly polls the system for completed events, executing the corresponding callbacks. The application executes as a series of cooperatively scheduled callback functions running on a single thread of control. The fastest known Web servers are event-driven [RP04, Kro04]. However, event-driven programming is typically considered difficult because the control flow of the program is broken into a chain of callbacks and because context data must be managed manually.
To better understand why programming with events is difficult, let us begin with a brief comparison of threads and events. Next, we will frame the problem by examining related work. Then we will summarize our approach to the problem and outline the thesis.
1.1
Programming with Threads
Threads maintain the syntactic appearance of serial execution, greatly easing the burden on programmers. Figure 1.1 shows a simple HTTP document fetch pro-gram written using threads. Error handling and other details have been omitted from the figure for brevity. In this case only one document is fetched using one thread, but in general any number of documents could be fetched concurrently using this program. The sequence of the program is immediately apparent when reading it because it executes sequentially through the lines of code. Data struc-tures, such as the buffer declared on line 8, are primarily automatically managed on a per-thread stack. Other resources are more easily managed because con-trol paths that exit the function are more visible. Blocking calls on lines 12 and 14 maintain the thread state while waiting for the operation to complete. If other threads were present, they could execute during these wait times (or at any time if the threads were preemptive). Debugging is also easy and/or sequential, assuming the debugger has thread support.
1.1.1 Problem with Threads
Although threads make programming easy, they have problems with performance and robustness [Ous96, DZK02]. Much work has gone into mitigating perfor-mance problems [BCB03, BCZ01]. However, because threads share the same
1 int main (int argc, char **argv) {
2 // create a new thread to fetch an HTTP document
3 thead_id tid = create_thread(http_fetch_thread_entry, NULL); 4 wait_for_all_threads();
5 }
6 int http_fetch_thread_entry(void *arg) { 7 int read_ret, buf_offset = 0;
8 char response_buf[READ_BUF_LEN];
9 // open a file descriptor, fd, to the server, create request buffer, req 10 ...
11 // write the request out 12 write(fd, req, strlen(req)); 13 // read the response
14 while ((read_ret = read(fd, response_buf+buf_offset, READ_BUF_LEN-buf_offset)) > 0) { 15 buf_offset += read_ret;
16 }
17 // data is all read, do something with it, close the fd 18 ...
19 }
Figure 1.1: A simple HTTP fetch program written using a hypothetical thread library. “. . . ” signifies where code has been omitted for brevity.
address space, they also typically suffer from concurrency complexity problems such as sharing, locking, deadlock, race conditions, etc. that can be subtle and difficult to avoid.
1.2
Programming with Events
Event-driven programs call select, or one of its variations, to wait for I/Oevents on a list of non-blocking file descriptors. I/O events are one of two readiness events, read or write, or an error event if there is a problem (called “except” for select). Events are used when a file descriptor is not ready for a requested operation. For example, if the program wishes to read data from a file descriptor it would call the read system call. If the file descriptor is not ready to be read, the call returns-1and setserrnotoEAGAINto indicate that the call would block. Since the call would block the program must somehow wait for the file descriptor
to be ready for the operation and then continue executing where it left off. select is used when there is no file descriptor ready for the next operation the program wishes to perform. select takes three arrays of file descriptors structures, one for each event type; a timeout; and a maximum file descriptor value, n.
int select(int n,
fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
It returns when one or more events of interest have occurred or if the timeout is reached with no events. The program then iterates through the file descriptor structures to find any events that have occurred, and continues the program for those. Other system interfaces eliminate having to copy the entire array for each wait call and having to iterate through all file descriptors [Lem01, epo]. Typically
select is called continuously in adispatch loop that is separated from the code fragments that process readiness events. This makes it easy to add new readiness events as the program evolves. In the most common design, the program calls an event registration function to specify interest in an event. The registration function is passed a file descriptor and a callback — in C, a function pointer. When the file descriptor becomes ready, the dispatch loop will call the callback. Event notification libraries were created to simplify event programming and to abstract the particular OS polling mechanism available. These allow the pro-grammer to dynamically register a callback function and context data to be associated with an event on a file descriptor [Prob]. The dispatch loop of the event notification library simply calls the polling function using the file descrip-tor events that have been registered, then for each event that has occurred it calls the corresponding callback function and passes it the correct context data.
1 int main (int argc, char **argv) { 2 ... // parse command line, config files 3 eel_initialize();
4 // create a new connection and start the document fetch 5 http_fetch( new_uri(start_address), eel_new_group_id() ); 6 // the main dispatch loop
7 eel_dispatch_loop(); 8 eel_uninitialize(); 9 return 0;
10 }
11 // assume uri->fd is ready for write
12 void http_fetch(struct uri *uri, eel_group_id gid) { 13 char request[1024];
14 // create the HTTP request and write it to uri->fd
15 snprintf(request, sizeof(request), "%s %s HTTP/1.0\r\n" ... ); 16 atomicio(write, uri->fd, request, strlen(request));
17 // wait for a read event on uri->fd or timeout 18 eel_add_read_timeout(
gid, http_readheader, http_readheader_timeout, uri, uri->fd, HTTP_READTIMEOUT); 19 }
20 // the timeout occurred before uri->fd was ready to read
21 void http_readheader_timeout(eel_group_id gid, void *arg, int fd) { 22 // clean up all resources; ends the callback chain
23 uri_free_gid((struct uri *)uri, URI_CLEANCONNECT, gid); 24 }
25 // uri->fd is ready to read
26 void http_readheader(eel_group_id gid, void *arg, int fd) { 27 char line[2048];
28 struct uri *uri = arg;
29 // read some data from uri->fd 30 n = read(uri->fd, line, sizeof(line)); 31 if (n == -1) {
32 if (errno == EINTR || errno == EAGAIN)
33 goto readmore; // wait for another read event 34 // real error: free and return
35 uri_free_gid(uri, URI_CLEANCONNECT, gid); 36 return;
37 } else if (n == 0) ... // handle other conditions 38 ...
39 // copy unparsed header info into uri structure 40 http_parseheader(uri, gid);
41 return; // Is there another callback after this return??? 42 readmore:
43 // wait for another read event or timeout 44 eel_add_read_timeout(
gid, http_readheader, http_readheader_timeout, uri, uri->fd, HTTP_READTIMEOUT); 45 }
Figure 1.2 shows part of an event-driven program for fetching an HTTP doc-ument. Some error handling and other details have been omitted from the figure for brevity. One document is fetched from start address using one chain of callback functions, but other document fetches happen concurrently once more addresses are discovered (not shown). The program entry point, main, calls
http fetch, which registers a callback on line 18 for a read readiness event with a timeout. The program continues once the event or its timeout occurs when eel dispatch loop callshttp readheader orhttp readheader timeout.
http readheader attempts to read data from the connection (line 30) then takes appropriate action depending on its result. If more header data must be read, a read readiness event is added again (line 44). Although it is not shown, the program proceeds to other callbacks following the call to http parseheader on line 40.
1.2.1 Problem with Events
The problem with events is not runtime performance; event-driven programming produces fast and robust programs [DZK02]. However, events lack programma-bility: the ability to read, write, debug and maintain the program. To explain, please again refer again to Figure 1.2. It seems simple enough to extract the pro-gram control flow: from main the program waits for a read event or a timeout, then proceeds to the appropriate callback function. However, it is not clear what happens following the execution of http parseheader on line 40. One would have to read the function http parseheader as well as any functions it calls in order to determine the next callback in the chain, if any. As well, all control paths within http readheader must be read to determine if gid and uri are cleaned up or passed to another callback. In general, determining the control
flow of event-driven programs requires reading the entire function call graph to assemble the callback chain.
Writing event-driven programs is also problematic. Consider a programmer writing Figure 1.2’s code in top-down order. Once she finishes writing http -readheader, she might write http parseheader. Unfortunately she would need to keep in mind that, since http parseheader is the final call from http -readheader, she must take care of the resource management of the arguments as well as defining the next callback. Taking the responsibility for cleaning up function arguments is not unusual, but there are no syntactic means to remind the programmer to take responsibility for the next callback; and it is still easy to forget to clean up function arguments for rarely used paths, such as errors. Compounding the problem is the requirement to save state in a heap data struc-ture to be passed along the callback chain. If a function that originally executed sequentially is modified to wait for an event, it must move all of its relevant state information, possibly including stack variables, to the heap structure passed to the next callback. This might include, for example, thereqbuffer used on line 16. The programmer has (probably safely) assumed that writing an HTTP request will never block; but if it does, any unused portion of req must be passed on. This is referred to as “stack ripping” [AHT02].
Say the programmer now wishes to debug the code by stepping line by line through the source code, observing variable values. She runs the program in a debugger and sets a breakpoint at main to begin the process. After stepping a few lines the debugger steps to the dispatch loop. There is no convenient way to continue stepping on to the next line of logical program flow (either line 21 or 26). This program only shows a single HTTP fetch, so it’s simple enough to set breakpoints on the possible next callback functions and continue stepping once
one is reached. However, if the program performed multiple concurrent fetches a breakpoint specific to the particular connection would be required.
In practice, people have primarily turned to threads as a strategy to avoid these programmability problems. Those that do choose to use events have little recourse but to suffer through with ad-hoc solutions. For instance, separate documentation might be manually created to show the callback chain. Memory and resource management is most likely done manually. The programmer might debug the program using printf or logging.
1.3
Related Work
In 1978, Lauer and Needham proved that threads and events are duals of each other [LN78]. Since then, arguments have raged as to which model is better. Typ-ically, a new implementation of the favored model is built and then performance and qualities analyzed and compared with the most recent improvement of the other model. Ousterhout argued that threads are a bad idea because of inferior performance and being error-prone due to concurrency issues [Ous96]. Adya et al. took programmability issues of events to the extreme by building one-shot continuations and showing that stack-ripping is a major issue [AHT02]. Dabek et al. argue for use of their libasyncC++ library for building robust event-driven software [DZK02]. libasync primarily addresses the problem of ensuring program safety by exercising C++ templates to check that data types of callback functions and their context data are correct. They also address the problem of manual re-source management in event-driven programs by adding in automatic reference counted objects. Von Behren et al. argue for the use of cooperatively scheduled threads that have the appearance of serial execution [BCB03, BCZ01]. They aim to improve the runtime performance to a level that is comparable to events while
maintaining the ease of programming of threads. Threads and event are even dual in this regard: threads require compiler and runtime support while events require static tools to improve programmability. A few others focus on building the fastest web servers using events [RP04, Kro04]. Work has also gone into im-proving the performance of operating system event polling mechanisms [Lem01].
1.4
Our Approach
Our approach to programming event-driven software is to build tools that attack the problems at their common source: the difficulty of following an event-driven program’s control flow. Tools that can follow program control flow can auto-matically perform duties that are typically done manually by event-driven pro-grammers, such as documenting the logical control flow, finding resource leaks, and stepping through code in a debugger. While our tools do not necessarily bring event-driven programming to parity with threads, they maintain a pure event-driven model and all of its benefits while helping the programmer read, write, debug, and maintain event-driven software. The three tools presented here were chosen because they focus on what we believe to be the three greatest problem areas of programming with events. The first problem is control flow vis-ibility, yielding eelstatechart. The second is buggy manual resource management of “stack-like” data, yieldingeelverify. And the third is debugging programs that have concurrent connections, yielding eelgdb.
Our eel tools use current program analysis techniques to extract and use the control flow to improve programmability. eel stands for the Explicit Event Library — explicitness being the primary design goal. We designed a simple event notification library, libeel, to be amenable to automatic program analysis and to simplify development of event-driven software. Using the carefully-crafted
libeel semantics, three tools were build for the purposes of assisting with control flow visibility, finding resource leaks, and debugging. eelstatechart tackles control flow visibility directly by extracting the possible callback chains within a libeel program and displaying them in easily-read box and arrow charts. With these charts the programmer can avoid the error-prone process of searching the program callgraph to determine the callback chain. eelverifyuses program transformations in conjunction with a model checker to find potential resource leaks within libeel programs. This assists the programmer with the manual memory and resource management required by event-driven programs. eelgdb is a debugger that can automatically continue program stepping when a callback is registered and then later executed. With such a debugger the programmer can debug connection instances individually.
Although eel does much for the programmability of event-driven software, it is not without its limitations. Even though libeel encourages programming practices that make program analysis easier, eelstatechart is limited to common libeel usage patterns. eelverify, in fact, cannot verify a program, but rather provides a framework for finding potential resource leak-related bugs. eelgdb does allow connection instance level debugging, but requires the user to step line by line through any event registration calls in order to work correctly. eel nevertheless does really help programmability issues. As well, the work on eel provides inroads to more complete solutions.
Our event notification library, libeel, is covered in Chapter 2. Chapter 3 describes using eelstatechart to visualize the control flow of a libeel program. Finding bugs in an event-driven program usingeelverify is explained in Chapter 4. Chapter 5 presents eelgdb for debugging individual connection instances. We discuss our experience and future work in Chapter 6. Finally, we conclude in
CHAPTER 2
The Explicit Event Library:
libeel
libeel was designed to be an event notification C library that is amenable to automatic program analysis, and one that simplifies the development of event-driven software. This chapter covers everything one could possibly want to know about libeel in detail. First is a comparison between libeel and another event notification C library for the purposes of highlightinglibeel’s design points. Next is a detailed description of the libeel interface and how it is used. Last is all the details of implementation.
2.1
Design Points
The libeel interface was designed with the purposes of flexibility, ease of use, and ease of analysis. It is simpler than other event notification library interfaces in that the callback functions are explicitly named for each event registration and that each event registration is atomic. This simplicity makes program analysis easier because it avoid having to do any alias analysis. The goal of the analysis is to determine the control flow of the program. To understand how libeel’s design makes this easier, let us compare a typical libeel event registration to that of a similar event notification library, libevent [Prob].
2.1.1 libevent
libevent registration code:
1 //
2 // libevent registration of a read event on fd 3 // set up the timeout data structure
4 struct timeval tv;
5 tv.tv_sec = timeout_seconds; 6 tv.tv_usec = timeout_microseconds;
7 // set the values in the event data structure, stored in the context data 8 event_set(&argument->ev, fd, EV_READ, read_callback, argument);
9 ...
10 // add the event
11 event_add(&argument->ev, &tv);
The most significant feature from the above code is that the event registration occurs in two separate calls (lines 8 and 11). From a program analysis point of view, during the execution of the omitted line 9 anything could happen to change the argument->ev data. This makes it very difficult to determine what callback is being registered and for what event. Any event add that is not immediately preceded by the corresponding event set would require searching backwards through all possible control paths to determine the values the structure holds. In general this would also require accurate alias analysis because the address of the structure could be held elsewhere and used to update the data. Alias analysis is difficult [Lan92, MP01]. In practice, libevent programs tend to reuse their struct event data structures throughout the program, so the problem is very real. libevent also requires the programmer to manage the data structure that stores event registration information. Aside from the additional burden, the behavior of libevent is unspecified should the structure be modified while it is currently registered. It is possible to do a conservative analysis that assumes the data is not modified, but we didn’t.
Another issue with libevent is that multiple events of different types may be registered to the same callback in a single call. The parameterEV READis a value
that can be combined by the bitwise OR operator (|) withEV WRITE,EV TIMEOUT, and/or EV PERSIST. EV TIMEOUT gets set automatically if the second argument toevent add is notNULL; EV WRITEwill cause the callback to be called if a write readiness event is received; and EV PERSIST will cause the same event(s) to stay registered for any number of events on the file descriptor unless it is cancelled through another call. libevent calls the same callback function with an argument to indicate what type of event occurred. This combination of event cases and event type indirection limits what information can be gathered through analysis and requires the programmer to handle multiple cases in one callback function.
2.1.2 libeel
libeel registration code:
1 //
2 // libeel registration of a read event on fd, in one call
3 eel_add_read_timeout(gid, fd, read_callback, read_timeout_callback, argument, timeout_milliseconds);
The most significant difference between the libeel and libevent interfaces is that the event registration call occurs in a single atomic call for libeel (line 3). From a program analysis point of view, only the single library function call needs to be analyzed to determine what type of event was registered and to what callbacks it can go, thus simplifying the determination of the program’s control flow. Obviously a programmer could use function pointers in the libeel call to make the analysis more difficult, but there is no advantage to doing this for the programmer. Another simplification is that libeel manages event registration data internally, freeing the programmer from having to do so and making data modification issues less likely.
The libeel interface was designed to decouple semantic cases from one another so analysis is simpler. Whereas libevent could create multiple event registrations
with one API call and callbacks could handle multiple event types, libeel sep-arates these cases explicitly by pairing a single event registration with a single callback execution. libeel explicitly states each event being registered by having separate API functions for each event type, including timers or timeouts to I/O events. Event registration calls are always paired with a single callback call, and there are no persistent registrations, which keeps the library semantics clear and simple. Flexibility is not limited by the semantics, but more registration calls may be required to get the same result. Also, timeouts tend to be error paths, so making them a separate explicit callback function helps to ensure the pro-grammer remembers to handle this case. By separating each of these cases into different callback functions the program control flow, with regards to the order callbacks are executed in, can be determined without having to resort to data flow analysis.
A unique requirement of libeel is that it requires the programmer to specify a program’s call chain by using an identifier token, the “group identifier”, in reg-istration calls. The group identifier can be thought of as a manually managed analogue of a thread ID in the threading model. A thread ID is an identifier that is automatically managed by the threading library or OS and is associated with a thread’s execution information (program counter, stack frame, etc.). The thread-ing library creates a new thread ID for each new thread and uses it throughout the lifetime of the thread. Similarly, a libeel program creates a new group ID in-stance through theeel new group idcall for eachlogical sub-program and uses it throughout the sub-program’s lifetime. For example, if the program had a series of callbacks and event registration calls that implemented an HTTP document fetch, a new group ID instance would be created and used during the registra-tions for the entire chain during a single document fetch. A logical sub-program typically corresponds to a single network connection’s use but is not limited to
just a single connection.
While the requirement to use and manage group IDs does impose some work on the programmer, it usually is not a large amount. Context data and resources passed along the call chain are usually allocated in a single location and deallo-cated in another; the group identifier can be created and released at these sites as well. An alternative design could rely on an instance of an unknown context data structure, but this would limit the flexibility of the library because programs could not dynamically change what data structure is used. Also, in the interest of keeping the program behavior clear, requiring an explicit group ID forces the programmer to clearly define the callback chain.
Whilelibeel was designed to make program analysis easier it was also designed to simplify development of event-driven software. Its explicitness results in a well-designed and well-understood program. It is no coincidence that code that is easier to automatically analyze is also easier for people to understand. Semantics that are simpler tend to be easier to reason about and use. libeel’s group identifier requires programmers to actually think about and make explicit the organization of the callback chain. And because each event registration is explicitly generated by a single libeel call and handled by a single callback function, the programmer is encouraged to separate and handle each of these cases. The result is better software.
2.2
The
libeel
Interface
Figure 2.1 shows the entire libeel C interface. The “ID types” are library-private structures with pointer typedefs, eel event id and eel group id, to be used when calling the library. The “Basic types” define the type for callback functions
1 // Some ID types 2 struct eel_event; 3 struct eel_group;
4 typedef struct eel_group* const eel_group_id; 5 typedef struct eel_event* const eel_event_id; 6 // Basic types
7 enum eel_cb_return_value_enum { 8 EEL_SUCCESS = 0,
9 EEL_ERROR = -1 10 };
11 typedef enum eel_cb_return_value_enum eel_cb_return_value;
12 typedef eel_cb_return_value(*eel_callback)(eel_group_id gid, void *arg, int fd); 13 //
14 // API 15 //
16 // Library initialization / unintialization 17 int eel_initialize(int exit_on_signal); 18 int eel_uninitialize(void); 19 // Library 20 int eel_dispatch_loop(void); 21 int eel_dispatch_once(void); 22 int eel_no_events(void); 23 void eel_exit_loop(void);
24 // Event functions, return NULL on failure
25 eel_event_id eel_add_timer(eel_group_id gid, eel_callback cb, void *cb_arg, int timeout_milliseconds);
26 eel_event_id eel_add_read(eel_group_id gid, eel_callback cb, void *cb_arg, int fd); 27 eel_event_id eel_add_write(eel_group_id gid, eel_callback cb, void *cb_arg, int fd); 28 eel_event_id eel_add_error(eel_group_id gid, eel_callback cb, void *cb_arg, int fd); 29 // Compound event functions, return NULL on failure
30 eel_event_id eel_add_read_timeout(eel_group_id gid, eel_callback cb, eel_callback timeout_cb, void *cb_arg, int fd, int timeout_milliseconds); 31 eel_event_id eel_add_write_timeout(eel_group_id gid, eel_callback cb,
eel_callback timeout_cb, void *cb_arg, int fd, int timeout_milliseconds); 32 eel_event_id eel_add_error_timeout(eel_group_id gid, eel_callback cb,
eel_callback timeout_cb, void *cb_arg, int fd, int timeout_milliseconds); 33 // Event operations
34 // Events must be in the same group to be exclusive, as well events must be valid 35 int eel_make_exclusive(eel_event_id eid_in_out, eel_event_id eid_in);
36 // Group Operations
37 eel_group_id eel_new_group_id(void); 38 void eel_delete_group_id(eel_group_id gid); 39 int eel_has_events(eel_group_id gid); 40 int eel_remove_events(eel_group_id gid);
• Library initialization / unintialization
libeel must be initialized before any other functions are called and uninitialized when finished. Ifexit on signalis set to1,eel dispatch loopwill exit if a signal is received.
eel initializehas an error (-1) if no OS polling mechanism is available or if there is a problem initializing the polling mechanism chosen. eel uninitializecurrently always returns0.
• Library
1. eel dispatch loop executes the libeel dispatch loop until no events are being waited on,eel exit loopwas called, or a signal is received and exit on signal
was set ineel initialize. It returns the last return value ofeel dispatch once. 2. eel dispatch oncewaits on all currently registered events, dispatches all callbacks for events that occurred and then returns. It returns1if there are no events,-1if exiting on signal or if there was an error with the OS polling call, and0on success. 3. eel no eventsreturns1if there are no registered events, or0otherwise.
4. eel exit loopcauseseel dispatch loopto exit before its next wait.
• Event functions
Register an event (read, write, or error) on the fd file descriptor for the gid group ID with the cb callback function to be passed cb arg as a context argument. eel -add timer registers a callback to be called after timeout milliseconds milliseconds have elapsed. These return aneel event idthat isNULLon error or can be used with
eel make exclusiveif done so before returning control to the dispatch loop.
• Compound event functions
These functions combine a file descriptor event with a timeout event. If the event occurs before the timeout,cbis called and the timeout is cancelled. If the timeout occurs before the event,timeout cbis called and the event is cancelled.
• Event operations
eel make exclusive ensures that only one of eid in out or eid in is called and the other cancelled depending on which happens first. The events are combined into the
eid in outevent ID. It returns0on success and-1on error (invalid event).
• Group Operations
1. eel new group idcreates and returns a new group ID or NULLif out of memory. 2. eel delete group id releases a group ID previously created with eel new
-group id
3. eel has eventsreturns1if gidcurrently has any events registered,0otherwise. 4. eel remove eventscancels all event registered usinggid.
1 ...
2 // initialize the library 3 eel_initialize(1); 4 ...
5 // create context data that includes a group ID instance and any file descriptors 6 some_context_data_type *cd = create_new_context_data();
7 ...
8 eel_add_read_timeout(cd->gid, cd->fd, read_callback, read_timeout_callback, cd, TIMEOUT); 9 ...
10 // execute the dispatch loop until there are not more events or a signal is received 11 int dispatch_ret = eel_dispatch_loop();
12 ...
13 // during the dispatch loop, callbacks are executed that usually create other context data 14 // instances to use throughout a callback chain; callback chains typically
15 // cleans up resources when completed or error out 16 ...
17 // uninitilize the library 18 eel_uninitialize(); 19 ...
Figure 2.2: A typical libeel program. Error checking is also omitted.
that can be used with the library,eel callback, as well as constant return values from these callback functions, EEL SUCCESS and EEL ERROR. The API section declares all library functions, described in detail in Table 2.1.
A typical libeel C program follows the pattern shown in Figure 2.2. Within callbacks that are called during execution of the dispatch loop, new instances of context data and group identifiers are created and passed through the callback chain. For example, a web crawler might have the initial event be an HTTP connection to the starting web page. It downloads the starting web page by going through a series of callbacks designed to handle an HTTP fetch. It then parses the page for new web addresses, creates an new instance of context data, and registers initial events for each web page it wishes to fetch. Each of the newly registered events plus context data proceed down the HTTP fetch callback chain as the initial connection did. Likely it continues this process to a certain depth, then ceases to create new instances. Once there are no events left to be waited on, the dispatch loop returns and the program exits.
2.3
Implementation
libeel is implemented as a C library of about 3,000 lines, including comments and blank lines. It contains implementations for three different Linux wait mecha-nisms, epoll, poll, and select, favoring them in that order. These mechanisms are used to implement an abstract internal interface that contains five functions: init, end, add, remove, and wait. Internally libeel uses a queue of data structures that each correspond to an event registration as well as a red-black tree of timer events to always maintain the next timeout value to be used for a wait call. As events are registered it adds items to the queue and tree. When the wait function is finished, it dispatches any timer events that have expired and any I/O events that occurred. To dispatch, it moves all triggered events from the main queues to a dispatch queue to prevent interference from registrations taking place during callback function execution. It also uses a ring structure to maintain exclusive relationships created by eel make exclusive, used internally for the compound event functions. The group ID internally is nothing more that a queue of event registration structures for that group ID. Details of the implementation are hid-den from the programmer as much as possible, limiting the required knowledge to use libeel to that of Figure 2.1 and Table 2.1.
2.4
Limitations
There is some up-front work for the programmer to use libeel; programs must be originally written for libeel or ported. However, porting is somewhat trivial if the event library is similar to libeel, such as with libevent. Writing a libeel program does involve some amount of extra work because the group ID must be managed. However, because it forces the programmer to specify the callback chain explicitly
CHAPTER 3
Visualizing Control Flow:
eelstatechart
Understanding the control flow of an event-driven program is problematic because the program is separated into a series of dynamically registered callback functions. eelstatechart extracts all the possible callback chains of a libeel program and displays them graphically in the form of easily-read box and arrow charts. The charts can be used to help understand a libeel program that has already been written, or as a tool to verify that the program being worked on follows the desired control flow. The charts we generate here are equivalent to the graph described by Lauer and Needham in 1978 [LN78] and the blocking graph described by von Behren et al [BCB03]. eelstatechart also helps libeel programmers create more comprehensible programs. Even with very little knowledge of the program, simply reading the charts of a program can uncover areas where the program design is unclear.
3.1
The Chart
Each program corresponds to several charts, one per group type. Group types are numbers like g0 and g1. Each group type corresponds to a single eel new -group id call site in the program. If we think of group IDs as thread identifiers, then, a single chart represents the callback functions that a single “thread” might traverse. A thread can’t change its group type, but it can spawn new group types;
Chart g0: main - New([email protected]:358)
main -g0-g1
delete
new_client -g3
R
R
Figure 3.1: Chart g0 from plb-0.3 [plb]. we show this with “-gi” in the state chart.
eelstatechart generates the charts based on the static callgraph of a libeel program. Figure 3.1 shows the first chart from plb-0.3 [plb], an HTTP load balancer. Each chart represents one callback chain that begins with a call to
eel new group id and ends with a call to eel delete group id. Nodes in an eelstatechart are labeled with callback function names and edges with abbrevi-ations for I/O or timer events (shown in Table 3.1). One special node, delete, signifies the end of the callback chain and has no corresponding event associated with it. Callbacks to timeout events anddeleteare colored grey to de-emphasize these paths because they are usually error paths. This chart corresponds to the call to eel new group idon line 4 of the code shown in Figure 3.2.
To explain eelstatechart in more detail, let us examine the charts and corre-sponding code of plb beginning with chart g0 shown in Figure 3.1 and code in Figure 3.2. The starting node ismain, the entry point of the program. The dashes following the label of mainindicate it can generate chart g0 or g1. Every chart’s entry function can generate itself by definition because it calls eel new group id
1 // code from plb.c, main() 2 ...
3 eel_initialize(0);
4 eel_group_id listen_gid = eel_new_group_id(); 5 eel_group_id cleanup_gid = eel_new_group_id(); 6 eel_add_read(listen_gid, new_client, NULL, listenfd);
7 eel_add_timer(cleanup_gid, periodic_cleanup, NULL, TIMEVAL_TO_MILLISECONDS(timeout_cleanup)); 8 eel_dispatch_loop();
9 eel_delete_group_id(cleanup_gid); 10 eel_delete_group_id(listen_gid); 11 eel_uninitialize();
12 ...
Figure 3.2: Code from plb.c,main, that corresponds to Figure 3.1 and Figure 3.4. is the other eel new group id call site in main (line 5) whose returned value is used in registration calls that create a separate callback chain in the program; we will analyze chart g1 later. From main, a read readiness event triggers new -client to be called, which can generate chart g3; it can also trigger another read readiness event where new client is called again. The corresponding code from
new client is shown in Figure 3.3. Line 6 shows theeel new group id call that generates chart g3. Line 8 shows the re-registration of the read readiness event. This read loop makes perfect sense knowing that the program is an HTTP load balancer. The program listens on a port or ports and accepts new connections as
• R= read readiness event
• W= write readiness event
• E= error or exception event
• T= timer event
• TO= timeout event, always exclusive with R, W, or E
1 // code from plb_session.c, new_client() 2 ...
3 // accept the new connection 4 ...
5 // start processing the new connection 6 eel_add_read_timeout( eel_new_group_id(), client_read, client_read_timeout, client, client_fd, TIMEVAL_TO_MILLISECONDS(timeout_header_client_read)); 7 // make sure we still handle more READs to the listen fd 8 eel_add_read(listen_gid, new_client, NULL, listenfd); 9 return EEL_SUCCESS;
Figure 3.3: Code from plb session.c, new client, that corresponds to Figure 3.1 and the starting point of Figure 3.7.
they are triggered by read readiness events. The new connections follow a differ-ent callback chain, g3, that starts with the function where the first registration took place,new client. Also coming from main is an arrow todeleteindicating that eel delete group id is called with the same group ID, shown by the code on line 10 of Figure 3.1. Because there is no arrow from new clienttodeleteit is clear the program remains in the new client read readiness loop until it exits the dispatch loop because of a signal or a call to eel exit loop.
Before we get to the accepted connection’s chart, g3, generated in the listen loop, let us briefly examine charts g1 and g2 shown in Figure 3.4 and Figure 3.6. As noted earlier, chart g1 is generated by main; its call to eel new group id is on line 5 of Figure 3.2. Chart g1 is similar to chart g0 in that it is a simple loop that generates another chart, in this case g2. A difference is that the loop waits for timer events instead of read events. Being that the timer event callback function is named periodic cleanup this makes sense. The timer results in
Chart g1: main - New([email protected]:359)
main -g0-g1
delete
periodic_cleanup -g2
T
T
Figure 3.4: Chart g1 from plb-0.3 [plb].
entire code for periodic cleanup is shown in Figure 3.5. It appears the call to
spawn cleanupon line 9 generates chart g2, a function call thateelstatechart has traversed to search for other libeel calls. Other than generating chart g2, this callback simply registers a new timer (line 12) so that it is called again later.
The chart g2 generated by g1 is shown in Figure 3.6. It shows that it waits for a write readiness event or a timeout to expire before calling cleanup connect -ready or cleanup connect ready timeout, respectively. Because the arrow to
cleanup connect ready timeout is a timeout (labeled with “TO”), we know that either one of these functions is executed, but not both. Following the ex-ecution of either of these functions the callback chain is ended as indicated by the arrows to delete. Upon closer inspection of cleanup connect ready, it is clear that this function and its timeout clean up unresponsive connections from the load balancer’s pool of servers.
Figure 3.7 shows chart g3, which is generated by the listen loop from chart g0. Obviously the bulk of the program takes place in this callback chain. Although the chart looks somewhat complex at first, look first at the I/O events only, shown in black, and the program flow becomes very simple. The timeout functions
1 // function body of periodic_cleanup, from plb_cleanup.c 2 register Server *cleaned_server;
3 if ((cleaned_server = serverpool_head) == NULL) { 4 plb_log(LL_ERROR, "No server pool");
5 return EEL_ERROR; 6 } 7 do { 8 if (cleaned_server->status <= 0U) { 9 spawn_cleanup(cleaned_server); 10 }
11 } while ((cleaned_server = cleaned_server->next) != NULL);
12 eel_add_timer(gid, periodic_cleanup, ev, TIMEVAL_TO_MILLISECONDS(timeout_cleanup)); 13 return EEL_SUCCESS;
Figure 3.5: Function body of periodic cleanup, from plb cleanup.c, that cor-responds to Figure 3.4 and the starting point of Figure 3.6.
Chart g2: periodic_cleanup - New(tmp___8@plb_cleanup.c:113) periodic_cleanup -g2 cleanup_connect_ready W cleanup_connect_ready_timeout TO delete
Chart g3: new_client - New(tmp___3@plb_session.c:184) new_client -g3 client_read_timeout TO client_read R delete TO R server_forward_request_timeout TO server_forward_request W server_send_header W server_send_header_timeout TO TO W W TO server_forward_reply_timeout TO server_forward_reply R TO R client_forward_reply_timeout TO client_forward_reply W TO R TO W Figure 3.7: Chart g3 from plb-0.3 [plb]. 28
are nearly always error handling functions, so can be ignored when trying to understand the most common path through the callback chain. The arrows to
delete are also error paths except those at the end of the chain. Beginning from
new client, the program waits for a read readiness event then executesclient -read. The program must read the client’s HTTP request before forwarding it to a server. Next it has two write readiness events, one going to server send -header and the other going toserver forward request. Next the server is sent the HTTP header that was read from the client, but a write readiness event on the server connection must be waited for first. Followingserver send header, a write readiness event can again go to server send header if there is more data to send, or a read readiness event toserver forward reply. server forward -reply and client forward reply then exchange for read and write readiness events to forward the server’s response back to the client.
An interesting point is brought up with the one I/O callback function not discussed yet, server forward request. It is called on a write readiness fol-lowing client read the same as server send header. After reading the code in client read, it is clear that the write readiness to server send header is generated first and then, if more data is received from the client, it is forwarded to the server via server forward request. For HTTP this extra data is non-header data, or POST data. What makes this somewhat unclear in the chart is that these two cases are handled by one client read readiness callback function,
client read. The code for client read shows the only logic being to call one of two other functions, client read header or client forward request. The eelstatechart brings out a subtle design point of the program that could easily be improved. client read makes its decision between the two function calls based on a “state” variable that has a value representing the the stage of the client reading. If client read were broken into two callback functions, the program
stages would be more clear, both in code and in the eelstatechart. There would be no need for the “state” variable because the correct callback would be called based on its registration not whether the variable had been modified. In fact, the variable is only modified immediately before registering client read, confirming the more natural design suggested. This example highlights how using
eelstate-chart along with libeel urges programmers into more clear and comprehensible
designs.
Charts for other programs are shown in the Appendix.
3.2
Implementation
As suggested by the chapter introduction, the entire program callgraph must be read to generate the charts. eelstatechart accomplishes this by using the C Intermediate Language (CIL) [cil]. eelstatechart is a CIL module that uses an implementation of the the CIL visitor interface to generate a static callgraph. Each node in the graph holds function variable information (type, definition location, etc.), a hashtable to all functions that it calls (“calls”), a hashtable to all functions that call it (“called”), and a libeel label. The libeel label holds detailed libeel information about any libeel calls. Embedded in this label information is the key to eelstatechart. Each libeel operation (new group ID, delete group ID, and all event registrations) happens relative to a group ID variable. So, for each operation the group ID argument’s variable information is stored. The source of the group ID is also determined as explained below.
To build the static callgraph, eelstatechart visits all function definitions in the program and all the function calls within those definitions. To the “calls” hashtable of the function definition’s node it adds the functions that are called,
and adds itself to the “called” hashtables of each. Calls to function pointers are ignored, but recursive functions are handled correctly; this works for common cases. However, mutually recursive functions are not handled correctly. At the same time as generating the static callgraph, eelstatechart discovers alllibeel calls and uses them to create the label information. It determines the libeel operation by the name of a function being called and saves the group ID argument’s vari-able information. It then searches for the source of the group ID varivari-able. The group ID’s source is determined to be one of four possibilities: a global variable, a local variable that was assigned from a call to eel new group id, an argument to the function, or “unknown.” If the variable information indicates it is a global variable, it is marked as such and nothing more is done. If the variable informa-tion indicates it is an argument to the funcinforma-tion, it is marked as such only if all statements in the function definition show it is never re-assigned, and the address of it is never taken. Either of these cases indicate the variable value could have changed before being used in thelibeel call, so it is marked as having an unknown source. If the variable information indicates it is a local variable, eelstatechart searches backwards through a predecessor control flow graph (generated by CIL) to find what it was assigned from. If assigned from a call to eel new group id it is marked as such. If assigned from another variable, it recursively looks for the source of that variable. All of the predecessor paths must agree on the source; otherwise it is marked as having an unknown source. Using this logiceelstatechart conservatively handles the common cases.
Finally, thelibeel labels are percolated up the callgraph by doing a depth first search as shown by the pseudocode in Figure 3.8. Each time a label is transferred to a calling function, its group ID source is verified. If the source of the group ID was an argument passed into the function call, it must be updated. The same logic for determining the group ID source mentioned above is re-applied
1 // just traverse each entry node
2 for each node in global list of callback functions and main() 3 traverseNode(node)
4 function traverseNode(node) 5 begin
6 if traverseNode has not been called with node 7 for each called_node in node
8 begin
9 traverseNode(called_node)
10 updateNodeFromCall(node, called_node, call_context) 11 end
12 end
13 function updateNodeFromCall(node, called_node, call_context) 14 begin
15 for each libeel label of called_node 16 begin
17 if the source of the group ID was an argument then
18 add libeel label to node with source = getGroupIdSource(call_context.gid_arg) 19 else
20 add same libeel label to node 21 end
22 end
Figure 3.8: Pseudocode for labeling callgraph with libeel information.
in each of these cases (call to getGroupIdSource on line 18 in the pseudocode). Labels that have a unknown group ID source are percolated unchanged. The root nodes of the callgraph are the program entry point and all the callback functions, because these are not called directly. The labels on these root nodes consist of libeel operations that have group ID sources that are either new, global, from the group ID argument passed into the callback function, or unknown. The labels now contain enough information to generate the charts for the program.
To export the chart, an eelstatechart visitor pattern is used to traverse the label information with the simple interface: beginChart, state, transition, end-Chart. Figure 3.9 shows pseudocode for visiting the charts of a program. First all new group ids must be discovered so that a chart can be created for each (lines 3 and 4). The visit follows the new group ID variable through its use in a callback call chain by examining the label information from the start function
1 function visitCharts(visitor) 2 begin
3 for each callback function and main
4 for each eel_new_group_id() call in label
5 visitChart(callback, chart_number, new_call, gid, visitor) 6 end
7 function visitChart(start_callback, chart_number, new_call, gid, visitor) 8 begin
9 visitor.beginChart(chart_number, start_callback) 10 add start_callback to Q
11 for each item in Q
12 for each libeel label in item
13 if label is for our gid and it is not a duplicate 14 begin
15 visitor.state(item)
16 if label generates a callback 17 begin
18 visitor.transition(item, callback)
19 if the new callback has not been ever added to Q 20 add the new callback to Q
21 end
22 else if label is for a delete 23 visitor.transition(item, delete) 24 end
25 visitor.endChart() 26 end
digraph g2 {
label="Chart g2: periodic_cleanup - New(tmp___8@plb_cleanup.c:113)" node [shape=box,width=.1,height=.1];
periodic_cleanup [label="periodic_cleanup -g2"]; periodic_cleanup -> cleanup_connect_ready [label="W"];
periodic_cleanup -> cleanup_connect_ready_timeout [label="TO",color=grey,fontcolor=grey]; cleanup_connect_ready -> delete [color=grey,fontcolor=grey];
delete [color=grey,fontcolor=grey];
cleanup_connect_ready_timeout [color=grey,fontcolor=grey];
cleanup_connect_ready_timeout -> delete [color=grey,fontcolor=grey]; }
Figure 3.10: eelstatechart DOT output for chart g2 of plb.
to see what operations that group ID participated in. For each callback regis-tration, it generates a new “state” (line 15) for the callback if it has not already been generated, then it adds the appropriate “transition” (line 18) to indicate the causal event. Labels with a unknown group ID source are ignored. For the charts seen here, a chart visitor was built that exports a DOT [dot] file and later runs DOT to create a PostScript output. Figure 3.10 shows the DOT output for chart g2 of plb. eelstatechart has other visitors implemented as well that dump the chart out in text, dump the entire label information out, and a couple for generating parts of the program transformations done for eelverify.
3.3
Limitations
eelstatechart has a number of limitations that the observant reader may have
noticed. One limitation to the charts created by eelstatechart is that they do not show event exclusivity or whether a particular event is always registered — something that would require some data flow analysis. A limitation to the im-plementation is that because determining the group ID source involves traversing a control flow graph, there is an exponential explosion of complexity as distinct flows are traversed. In practice, this is rarely a problem because the only group
ID variables that use this logic are local variables that are nearly always assigned from a call toeel new group id within just a couple instructions beforehand. The logic for determining if a group ID source is actually from a function argument is specifically designed to avoid having to do a control flow graph traversal. How-ever, by using a shortcut here, eelstatechart cannot handle any cases where a group ID argument is re-assigned. A more sophisticated data flow analysis could fix this. Also, the use of a depth first search of the static callgraph can cause eelstatechart to run out of stack space when there are too many nested function calls. The DFS problem could easily be fixed by repeatedly transferring labels up a single level of the callgraph until no more transfers take place. This fix would have the added benefit of handling mutually recursive functions correctly.
Another limitation is that group ID variables used in libeel must come from one of the simple sources listed above: global variable, local variable, or argument to the function. This case actually causes a problem in crawl-0.4 [Proa], a small and efficient HTTP web crawler. crawl uses a pool of forked child processes to do DNS lookups because the DNS lookup calls are blocking. It communicates with the child processes with pipes, file descriptors that can be used to wait for I/O readiness events. So the libeel program can continue processing events while the child processes block and then return the DNS information when ready. The problem arises because there is a limited number of these child processes. So if a new connection is desired, and there are no available child processes, its information including its group ID is saved on a queue that is checked each time a child completes its previous DNS lookup. The problem is thateelstatechart cannot determine the source of the group identifier when it is pulled off the queue. So the group ID used is marked as having an unknown source and excluded from the chart. In this case the chart does not change, but in general anytime a group ID is used outside of the specified ways it can result in the exclusion of some
parts of a callback chain. A fix for this might involve building connection queues into libeel so that eelstatechart could be aware of them. The reasoning here is that the only time a group ID needs to be put on a complex data structure is when there are a limited number of connections, something that queuing solves well.
Ideally eelstatechart could show more detail of how libeel programs generate their next callback by showing the sequence of function calls resulting in the callback registration. The collected information contains these details, but to display them would result in a cluttered and unreadable chart. As well, since eelstatechart is not flow-sensitive, the resulting chart cannot distinguish between callback generations that are exclusive because of control flow, and those where multiple events are registered. Nor does it takeeel make exclusiveinto account for these explicit cases, except when embedded in a single compound call (eel -add * timeout) where an I/O event is generated exclusive with a timer event. Although the resulting chart fails to distinguish between these cases, in practice, most programs follow a linear path [BCB03]. Another feature that would help would highlight common callback paths by using the value returned from libeel callback functions (EEL SUCCESSorEEL ERROR). In practice, downplaying timeout callback paths helps in this regard because timeouts are usually error paths.
CHAPTER 4
Checking Safety Properties:
eelverify
eelverify provides a framework for checking safety properties oflibeel programs by supplying program transformations and defined instrumentation points. Safety properties are especially important in event-driven programs because many re-sources are managed manually. Despite the name eelverify, our approach is not always sound so in some cases cannot be used to verify that the program never violates a safety property. However, more importantly, it can be used to find violations of safety properties (i.e. bugs) in libeel programs. The libeel program is transformed, instrumented with a specification, and then run through a model checker to search for violations. The most important property we check for viola-tions is that the callback chain is not broken; the checker searches for any control paths where neither a next callback is registered nor the chain is ended. Other safety properties relevant to event-driven programs can be checked for using a similar methodology.
The group identifier is the natural target to check for leaks because its use defines the callback chain. This can reveal where the callback chain is broken and implies where resources may have been neglected to be cleaned up. The intuition behind why resource leaks can be found where group IDs are leaked is that the pattern of event-driven programs has group ID management coupled with resource management. More concretely, resources for a callback chain tend to be created at the same site as the group ID for that chain, and cleaned up
at the same site as the group ID is cleaned up. Armed with eelverify the libeel programmer can automatically find hard-to-spot resource leak errors.
eelverify can also check the correctness of simplelibeel library use. Although it was only used to check two actual properties, library use and group ID leaks, it can be used for others. We describe here two program transformations that prepare
a libeel program for model checking using BLAST [HJM03, bla]. A program
transformation is necessary because the sequence of callbacks is not present in the syntax of the code, so the model checker cannot symbolically explore these. Knowing the semantics of libeel,eelverify extracts the callback chain and exposes it to the model checker in the form of C code. Once the program has been transformed it is instrumented with BLAST specifications designed for libeel, then model checked to explore the possible control paths and find violations.
These techniques are used to model check two different event-driven programs that have been modified to use libeel, and the effectiveness evaluated. An intro-duction to BLAST is first, leading into a section on the program transformations. Then the safety properties and their specifications are explained. Finally the re-sults of applying eelverify on the two programs are discussed.
4.1
BLAST
The Berkeley Lazy Abstraction Software Verification Tool (BLAST) [HJM03, bla] is a model checker for C programs. It starts by instrumenting the program code using a C-like specification of a safety property that transforms it into program code that contains error labels for cases where the property is violated. The spec-ification enables a temporal safety property of C interfaces to be converted to a problem of error label reachability. The model checker then builds an abstract
model of the program, checks for the reachability of error labels, and if one is reachable proves the error exists in the concrete program by giving a counterex-ample. If it cannot prove reachability, it uses the proof failure information to refine the abstract model so it can try again. If it cannot reach any error labels in the abstract model, it quits and says the program is safe. It uses a theorem prover and a set of boolean predicates to build the counterexample or discover new useful predicates that rule it out.
4.2
Program Transformations
Although BLAST can prove temporal safety properties of a library interface, it cannot do so for an event-driven program without the help of some preprocessing. BLAST searches the program’s callgraph, but does not currently support function pointers; running it either produces an error when one is reached or ignores it altogether if an option is set. When BLAST is run on a libeel program, it does not even explore the callback chain or anything past the static callgraph of the program entry point. However, with the help of some simple program transformations, the callback chain can be explored to check for safety property violations. Knowing the semantics of libeel, a libeel program can be transformed into a sequential program that has its callback functions called explicitly in a way BLAST can explore. This section shows two such transformations that attempt to achieve this goal. They have been named “independent state transformation” and “full program transformation.” In this case the word “state” refers to a callback function that has been passed to an eel add *function in the program. Given these definitions, we can discuss the sequence of alibeel program as a series of possible transitions between states, relative to a group identifier.
4.2.1 Independent State Transformation
The independent state transformation is a very simple transformation that allows checking for property violations independent of the sequence of callback calls and independent of each other. This transformation simply creates a new program entry point,independent state check SCG, and fills the function body with ex-plicit calls to each function that is used as a callback function to calls of the libeel library. As the three arguments to these callback functions, a new group identi-fier is used (from a call to eel new group id) as well as calls to two undefined functions, new void NONDET SCG and new fd NONDET SCG. The two undefined functions cause BLAST to assume these values are unknown, giving it nonde-terministic behavior. This approach is sound because it includes all possible program behaviors. Following the callback call, a call to another undefined func-tion, check gid properties SCG, with the new group identifier as a parameter is made for the purposes of providing a mechanism for later instrumentation.
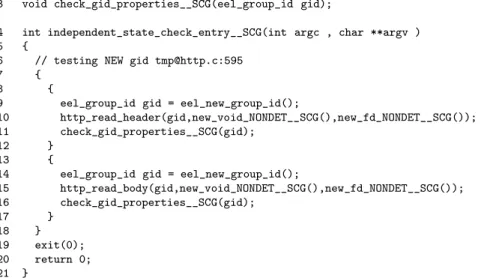
Figure 4.1 shows a sample transformation of a program with only two callbacks used, http read header and http read body. These callbacks are extracted from the program source during the transformation step. The transformation step is closely tied in with eelstatechart, hence the SCG “state chart generator” tag following all new functions generated. eelstatechart examines the program code and extracts the possible callback call sequence using the libeel semantics. The independent state transformation implements an eelstatechart visitor to iterate through the program’s callback functions and group them by group ID source.
4.2.2 Full Program Transformation
Although full program transformation was not accomplished, this section dis-cusses what was implemented and planned and some of its benefits and

![Figure 3.1: Chart g0 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/34.918.258.570.60.234/figure-chart-g-from-plb-plb.webp)
![Figure 3.4: Chart g1 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/37.918.222.605.59.228/figure-chart-g-from-plb-plb.webp)
![Figure 3.6: Chart g2 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/38.918.179.795.555.794/figure-chart-g-from-plb-plb.webp)
![Figure 3.7: Chart g3 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/39.1188.283.1131.183.559/figure-chart-g-from-plb-plb.webp)


![Figure 4.2: Chart g2 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/53.918.189.790.62.284/figure-chart-g-from-plb-plb.webp)
![Figure 4.3: Chart g3 from plb-0.3 [plb].](https://thumb-us.123doks.com/thumbv2/123dok_us/1814621.2761430/57.1188.285.1131.183.559/figure-chart-g-from-plb-plb.webp)
