Available online:http://internationaljournalofresearch.org/ P a g e | 1169
Progressive Identical Finding
Mr. D.Rammohan Reddy Ms. J. Ramani
Associate Professor M.Tech in Computer Science
Department of CSE Department of CSE
Vaagdevi Engineering College, Bollikunta, Warangal and Telangana State, India.
Abstract: Duplicate detection is the process of identifying multiple representations of equal actual global entities. Nowadays, replica detection techniques want to manner ever large datasets in ever shorter time: maintaining the first-rate of a dataset turns into increasingly more difficult. We present two novel, modern
reproduction detection algorithms that
drastically growth the performance of finding duplicates if the execution time is restricted: they maximize the gain of the overall method within the time available with the aid of reporting most outcomes a whole lot earlier than conventional tactics. Complete experiments show that our revolutionary algorithms can double the efficiency through the years of traditional replica detection and substantially improve upon related paintings.
Index terms: reproduction detection, entity decision, pay-as-you-move, progressiveness, facts cleaning
I. INTRODUCTION
Information is most of the most essential assets of a employer. But because of records adjustments and sloppy facts access, errors consisting of reproduction entries would possibly occur, making records cleansing and in particular reproduction detection fundamental. However, the pure size of now-a-day’s datasets render duplicate detection tactics pricey. On-line
shops, as an instance, offer large catalogs comprising a continuously developing set of gadgets from many different suppliers. As impartial individuals trade the product portfolio, duplicates arise. Even though there is an apparent need for de-duplication, on line stores without downtime cannot have the funds for
conventional de-duplication. Innovative
reproduction detection identifies most duplicate pairs early within the detection process. In place of reducing the overall time wished to finish the complete system, innovative strategies try to reduce the common time and then a replica is discovered. We gift numerous use cases where this becomes essential:
1) A consumer has only limited, perhaps unknown time for information cleaning and desires to make quality feasible use of it. Then, surely begin the algorithm and terminate it when wanted. The result size can be maximized.
2) A user has little information about the given information but nonetheless needs to configure
the cleaning manner. Then, allow the
progressive algorithm select window/block sizes and keys mechanically.
Available online:http://internationaljournalofresearch.org/ P a g e | 1170
run quickly reviews possibly large
consequences.
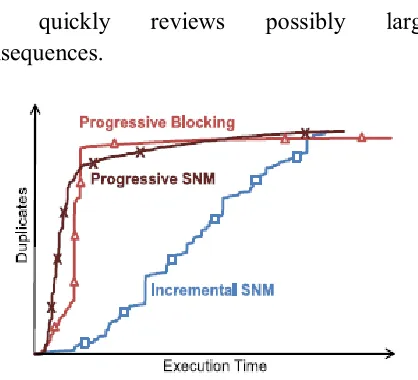
Fig. 1. Duplicates pairs found by an incremental and our two progressive algorithms
4) A person has to obtain a positive consider. Then, use the result curves of modern algorithms to estimate how many more duplicates can be found similarly; in popular, the curves asymptotically converge against the actual wide variety of duplicates within the dataset. We suggest novel, innovative replica detection algorithms particularly revolutionary sorted neighborhood method (psnm), which performs exceptional on small and almost easy datasets, and revolutionary blocking (pb), which performs best on large and very dirty datasets. Each beautify the performance of replica detection even on very large datasets. In contrast to conventional replica detection, progressive reproduction detection satisfies the conditions: stepped forward early exceptional. Allow t be an arbitrary target time at which ends are wanted. Then the progressive set of rules discovers more replica pairs at t than the corresponding traditional algorithm. Generally, t is smaller than the general runtime of the traditional set of rules. Equal eventual satisfactory: If both a conventional algorithm and its revolutionary
model end execution, without early termination at t, they produce the equal effects.
II. Associated work
A lot research on replica detection, additionally called entity resolution and by way of many other names, specializes in pair selection algorithms that try to maximize don't forget on the only hand and performance however. The most distinguished algorithms in this vicinity are blocking and looked after neighborhood approach (snm).
Adaptive techniques: previous guides on duplicate detection often consciousness on lowering the general runtime. Thereby, some of the proposed algorithms are already capable of estimating the pleasant of evaluation candidates. The algorithms use these facts to pick the contrast candidates extra carefully. For the same purpose, other procedures utilize adaptive
windowing strategies, which dynamically
modify the window size depending on the amount of currently found duplicates. Those adaptive strategies dynamically enhance the efficiency of reproduction detection, but in assessment to our progressive techniques, they want to run for sure intervals of time and can't maximize the efficiency for any given time slot.
Progressive strategies: inside the previous couple of years, the monetary need for progressive algorithms additionally initiated some concrete research in this domain. For example, pay-as-you-move algorithms for data integration on massive scale datasets were provided. Different works delivered innovative statistics cleansing algorithms for the analysis of
sensor records streams. However, these
Available online:http://internationaljournalofresearch.org/ P a g e | 1171
similarity be a part of that uses a unique index shape to estimate promising comparison applicants. This approach step by step resolves duplicates and also eases the parameterization hassle. Despite the fact that the end result of this technique is similar to our strategies (a listing of duplicates almost ordered through similarity), the focus differs: xiao et al. Find the top-ok maximum comparable duplicates no matter how long this takes by way of weakening the similarity threshold; we find as many duplicates as viable in a given time. That these duplicates also are the maximum comparable ones is a facet effect of our strategies.
The ton of studies on replica detection, additionally known as entity resolution and with the aid of many different names, specializes in pair selection algorithms that try to maximize remember on the one hand and efficiency on the other hand. The most outstanding algorithms on this vicinity are blocking and the taken care of neighborhood method (snm). xiao et al. Proposed a pinnacle-k similarity be part of that makes use of a unique index structure to
estimate promising comparison applicants. This approach step by step resolves duplicates and also eases the parameterization hassle. Pay-as-you-move entity resolution by way of whang et al. Brought sorts of innovative replica detection strategies, known as “guidelines”
A consumer has simplest confined, perhaps unknown time for information cleaning and wants to make satisfactory possible use of it. Then, sincerely begin the algorithm and terminate it while wished. The end result length will be maximized.
A user has little know-how approximately the given facts however nevertheless wishes to configure the cleaning process.
A user desires to do the cleansing interactively to, for example, locate excellent sorting keys by way of trial and errors. Then, run the modern algorithm time and again; each run quick reviews probably huge outcomes.
All provided suggestions produce static orders for the comparisons and leave out the
opportunity to dynamically adjust the
comparison order at runtime primarily based on intermediate effects.
III. SYSTEM ANALYSIS
In these paintings, however, we focus on progressive algorithms, which try to document most matches early on, at the same time as probably barely increasing their normal runtime. To achieve this, they need to estimate the similarity of all assessment candidates to be able to evaluate maximum promising report pairs first.
Available online:http://internationaljournalofresearch.org/ P a g e | 1172
looked after community approach (psnm), which plays great on small and nearly smooth datasets, and modern blocking (pb), which plays pleasant on large and very dirty datasets. Each beautifies the performance of reproduction detection even on very huge datasets.
We proposed a dynamic progressive duplicate detection algorithms, psnm and pb, which reveal special strengths and outperform modern-day processes.
We introduced a concurrent progressive
technique for the multi-skip method and adapt an incremental transitive closure set of rules that together bureaucracy the first complete modern replica detection workflow.
We outlined a unique pleasant measure for innovative replica detection to objectively rank the overall performance of various tactics.
We exhaustively evaluate on numerous real-international datasets trying out our very own and former algorithms
1) Progressed early fine
2) Identical eventual nice
Our algorithms psnm and pb dynamically regulate their conduct with the aid of robotically selecting finest parameters, e.g., window sizes, block sizes, and sorting keys, rendering their manual specification superfluous. In this
manner, we appreciably ease the
parameterization complexity for duplicate
detection in general and contribute to the development of more consumer interactive programs.
IV. Implementation
Dataset collection:
To accumulate and/or retrieve facts,
approximately activities, results, context and different factors. It is vital to bear in mind the type of information it want to gather out of your members and the approaches you will analyze that statistics. The data set corresponds to the contents of a unmarried database desk, or a unmarried statistical records matrix, where every column of the table represents a particular variable.
Preprocessing technique:
Facts preprocessing or information cleansing, facts is cleansed thru tactics which includes filling in missing values, smoothing the noisy statistics, or resolving the inconsistencies inside the statistics. And also used to disposing of the unwanted facts. Usually used as a initial records
mining practice, statistics preprocessing
transforms the statistics right into a layout with a view to be extra easily and effectively processed for the motive of the person.
Data separation:
After completing the preprocessing, the
statistics separation is to be finished. The blocking algorithms assign every report to a fixed group of similar information (the blocks) after which we evaluate all pairs of records within those businesses. Every block inside the
block assessment matrix represents the
comparisons of all data in a single block with all information in some other block, the equidistant blockading; all blocks have the identical length.
Replica detection:
Available online:http://internationaljournalofresearch.org/ P a g e | 1173
facts. To keep records great, you could time table a reproduction detection task to check for duplicates for all facts that healthy a sure standards. You may clean the facts with the aid of deleting, deactivating, or merging the duplicates said with the aid of reproduction detection.
Pleasant measures:
The satisfactory of these structures is, for this reason, measured the use of a price-advantage calculation. Specifically for classic reproduction detection strategies, it's far tough to fulfill a price range hassle, due to the fact their runtime is difficult to predict. By turning in as many duplicates as viable in a given amount of time, progressive methods optimize the fee-benefit ratio. In production, a measure of excellence or a country of being free from defects, deficiencies and substantial versions. It is miles brought about through strict and constant dedication to sure standards that reap uniformity of a product in an effort to satisfy specific customer or user requirements.
Available online:http://internationaljournalofresearch.org/ P a g e | 1174 6. Conclusion and future works
This project delivered the modern looked after community approach and progressive blocking. Both algorithms growth the performance of reproduction detection for conditions with constrained execution time; they dynamically alternate the rating of evaluation applicants primarily based on intermediate effects to execute promising comparisons first and less promising comparisons later. To determine the performance advantage of our algorithms, we proposed a unique excellent measure for progressiveness that integrates seamlessly with existing measures. The usage of this degree, experiments confirmed that our procedures outperform the conventional snm by as much as one hundred percent and related work by up to 30 percent. For the construction of a fully progressive replica detection workflow, we proposed a progressive sorting technique, magpie, a revolutionary multi-pass execution
model, attribute concurrency, and an
incremental transitive closure algorithm. The adaptations ac-psnm and ac-pb use more than one sort keys simultaneously to interleave their
modern iterations. By way of reading
intermediate results, both processes dynamically
rank the distinctive kind keys at runtime, extensively easing the important thing choice problem. In future work, we want to mix our innovative processes with scalable processes for duplicate detection to deliver consequences even quicker. Especially, kolb et al. Delivered a two segment parallel snm , which executes a traditional snm on balanced, overlapping partitions. Here, we can as an alternative use our psnm to steadily find duplicates in parallel.
REFERENCES
[1] S. E. Whang, D. Marmaros, and H. Garcia-Molina, “Pay-as-you-go entity resolution,” IEEE Trans. Knowl. Data Eng., vol. 25, no. 5, pp. 1111–1124, May 2012.
[2] A. K. Elmagarmid, P. G. Ipeirotis, and V. S. Verykios, “Duplicate record detection: A survey,” IEEE Trans. Knowl. Data Eng., vol. 19, no. 1, pp. 1–16, Jan. 2007.
[3] F. Naumann and M. Herschel, An Introduction to Duplicate Detection. San Rafael, CA, USA: Morgan & Claypool, 2010.
[4] H. B. Newcombe and J. M. Kennedy, “Record linkage: Making maximum use of the
discriminating power of identifying
information,” Commun. ACM, vol. 5, no. 11, pp. 563–566, 1962.
[5] M. A. Hern_andez and S. J. Stolfo, “Real-world data is dirty: Data cleansing and the merge/purge problem,” Data Mining Knowl. Discovery, vol. 2, no. 1, pp. 9–37, 1998.
[6] X. Dong, A. Halevy, and J. Madhavan,
“Reference reconciliation in complex
Available online:http://internationaljournalofresearch.org/ P a g e | 1175
[7] O. Hassanzadeh, F. Chiang, H. C. Lee, and R. J. Miller, “Framework for evaluating clustering algorithms in duplicate detection,” Proc. Very Large Databases Endowment, vol. 2, pp. 1282– 1293, 2009.
[8] O. Hassanzadeh and R. J. Miller, “Creating probabilistic databases from duplicated data,” VLDB J., vol. 18, no. 5, pp. 1141–1166, 2009.
[9] C. Xiao, W. Wang, X. Lin, and H. Shang, “Top-k set similarity joins,” in Proc. IEEE Int. Conf. Data Eng., 2009, pp. 916–927.
Mr. RAMMOHANREDDY DONDETI was
born in India in the year of 1988. He received B.Tech degree in the year of 2009 from A.U & M.Tech PG in the year of 2012 from K.U. He was expert in Mathematical Foundations of Computer Science, Database Management Systems, Object Oriented Analysis and Design, Distributed Databases and Cloud Computing Subjects. He is currently working as An Associate Professor in the CSE
Department in Newton’s Institute of
Engineering, Aluguraju pally(v),
Koppunoor(p), Macherla, Guntur(Dt),A.P, India.
Mail ID: [email protected]
Ms. J.RAMANI was born in India. She is pursuing M.Tech degree in Computer Science & Engineering in CSE Department in Newton’s Institute of Engineering,
Alugurajupally (vill), Koppunoor (p),
Macherla, Guntur (Dist), A.P, India..