Parallel Aligned Treebanks at LDC:
New Challenges Interfacing Existing Infrastructures
Xuansong Li, Stephanie Strassel, Stephen Grimes, Safa Ismael,
Mohamed Maamouri, Ann Bies, Nianwen Xue
Linguistic Data Consortium, University of Pennsylvania Philadelphia, PA 19104 USA
Computer Science Department, Brandeis University Waltham, MA 02453 USA
Email:{xuansong,strassel,sgrimes,safa,maamouri,bies}@ldc.upenn.edu [email protected]
Abstract
Parallel aligned treebanks (PAT) are linguistic corpora annotated with morphological and syntactic structures that are aligned at sentence as well as sub-sentence levels. They are valuable resources for improving machine translation (MT) quality. Recently, there has been an increasing demand for such data, especially for divergent language pairs. The Linguistic Data Consortium (LDC) and its academic partners have been developing Arabic-English and Chinese-English PATs for several years. This paper describes the PAT corpus creation effort for the program GALE (Global Autonomous Language Exploitation) and introduces the potential issues of scaling up this PAT effort for the program BOLT (Broad Operational Language Translation). Based on existing infrastructures and in the light of current annotation process, challenges and approaches, we are exploring new methodologies to address emerging challenges in constructing PATs, including data volume bottlenecks, dialect issues of Arabic languages, and new genre features related to rapidly changing social media. Preliminary experimental results are presented to show the feasibility of the approaches proposed.
Keywords: machine translation; word alignment; parallel aligned treebank
1.
Introduction
PATs are parallel treebanks annotated with morphological and syntactic structures that are aligned at sentence as well as sub-sentence levels. They are valuable resources for natural language processing and other research fields, such as automatic word alignment system training and evaluation, transfer-rule extraction, word sense disambiguation, translation lexicon extraction, and cultural heritage and cross-linguistic studies. With machine translation particularly, PAT data can help to improve system performance with enhanced syntactic parsers (Marecek, 2011), with better learned empirical rules for flexibly capturing factual and linguistic knowledge of language pairs (Simov et al, 2011), with effective syntactic re-ordering of languages that are far-apart (DeNero & Uszkoreit, 2011), and with reduced automatic word error rate (Ittercheriah & Roukos, 2005). However, such corpora are hard to find. Prominent PAT efforts are the Japanese-English-Chinese PAT (Uchimoto et al. 2004), the English-German-Swedish PAT (Volk et al., 2006), and the SMULTRON corpus built in English, Swedish, and German (Gustafson-Capkova et al., 2007). A recent contribution is the PAT data at LDC, notable for its large volume (Table 1). It is a part of the GALE Program funded by DARPA (Defense Advanced Research Projects Agency), targeting Arabic, Chinese and English languages.
The GALE program significantly improved MT technologies while exposing impediments for further MT breakthroughs. Arabic-English translation systems don’t port well to dialect texts. Models for both Arabic and
Chinese have to handle unfamiliar genres due to rapidly
Arabic-English PAT
Genre Arabic Words
ATB Tokens
English Words
Segments
NW 198558 290064 261303 8322
BN 201421 259047 266601 12109
BC n/a n/a n/a n/a
WB 19296 28138 26382 853
Chinese-English PAT
Genre Chinese Characters
English Words
CTB Words
Segments
NW 240920 164161 145925 5322
BN n/a n/a n/a n/a
BC 176448 91650 122714 7156
WB 129594 89866 82585 3920
Table 1: PAT Corpora at LDC
2.
Existing Infrastructures and
Methodologies
2.1 Arabic-English PAT
The “Arabic language”, as a general term, includes Modern Standard Arabic (MSA) and a collection of spoken dialects. “Arabic” herein refers to MSA.
,
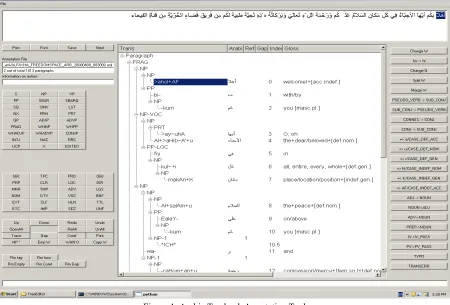
were also created at LDC (Bies et al., 2012). LDC developed an annotation tool to assist treebank annotation (Figure 1).
The sentence alignment is performed during the translation stage and automatically re-aligned during the PAT process in the case of misalignment. The word-level
Figure 1: Arabic Treebank Annotation Tool
The MSA-English PAT data has four genres: newswire, broadcast news, broadcast conversation and weblogs. Source data are harvested from TV/broadcast programs, news agencies or online resources and subsequently sentence-segmented and translated into English. Treebank annotations are further conducted on source texts and their translations. The final PAT corpora are created with an infrastructure that integrates existing parallel treebank annotations through two levels of alignment with corpus-wide data mapping and indexing.
Treebank annotations are taken from the Penn Arabic Treebank (ATB) and its corresponding Penn English Treebank (EATB). The ATB and EATB are composed of two annotation levels: morphological/part-of-speech (POS) and syntactic/tree annotation. The former provides part-of-speech, morphological, and gloss information. The latter focuses on the constituent structures of sentences and word sequences, analyzing functional categories for each non-terminal node, and identifying null elements, co-reference, traces, etc. (Maamouri et al., 2008; Maamouri & Bies, 2004). English Treebanks
alignment is performed on leaf tokens, producing ground-level alignment. Tokens are directly extracted from the Penn English and Arabic treebanks. The English texts are tokenized in the following ways: words separated by white spaces, contractions split, punctuations separated from surrounding words, and the apostrophe (‘,‘s) treated as a separate token. Hyphens are separate tokens, but some of them are treated as part of words. Because of rich morphological features, tokenization or segmentation of Arabic texts is more complicated. We adopt Arabic treebank tokenization which splits clitics (except “determiner”) into separate tokens to allow for finer alignment. Annotation markups, such as “empty category” markers from treebank annotation, are tokenized into separate tokens. Punctuation marks are also separate tokens.
Figure 5: Alignment and Tagging Annotation Tool
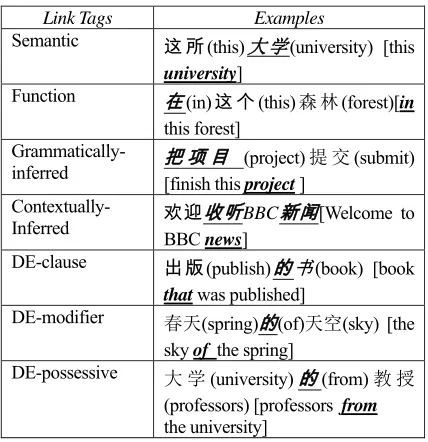
To more comprehensively address linguistic idiosyncrasies of both Chinese and English, including the Chinese particle 的 (DE), we further classified “translated correct links” into seven link types, and further classified the “not-translated correct” markup tag into fourteen word tags. These link and word types are illustrated in Table 2 and 3 (Li et al., 2010). LDC developed an interface to support the manual alignment and tagging annotation (Figure 5).
Chinese-English PAT corpora are structured and formatted similarly to Arabic-English PAT data, except that in the alignment file, tags are attached to an alignment pair. A word can have multiple tags, each corresponding to a character within the word. The tags are formatted for the convenience of easy removal since some less sophisticated translation systems may not need all such tagging information. As all the unaligned and attached words are categorized and tagged, users can choose to retain and investigate a particular type or several types of linguistic features. Therefore, the tagging data structure is designed to facilitate use for all models and by all users.
Link Tags Examples
Semantic 这 所(this)大 学(university) [this
university]
Function 在(in)这 个(this)森 林(forest)[in this forest]
Grammatically-
inferred 把 项 目[finish this (project)提 交(submit) project]
Contextually-
Inferred 欢迎收听BBC新闻[Welcome to
BBC news]
DE-clause 出版(publish)的书(book) [book
thatwas published]
DE-modifier 春天(spring)的(of)天空(sky) [the sky of the spring]
DE-possessive 大 学(university)的(from)教 授 (professors) [professors from the university]
Switzerland. pp. 63-70.
Volk, M., Gustafson-Capková, S., Lundborg, J., Marek, T., Samuelsson, Y. and Tidström, F. (2006). XML-based phrase alignment in parallel treebanks. In Proceedings of EACL Workshop on Multi-dimensional Markup in Natural Language Processing. Trento. pp. 93–96.