How To Solve The Fmfontham Equation In A Two Level Iterative Computer Science Project
138
0
0
Full text
(2)
(4)
(5)
(6)
(7)
(8)
(9)
(11)
(12)
(13)
(14)
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
(28)
(29)
(30)
(31)
(32)
(33)
(34)
(35)
(36)
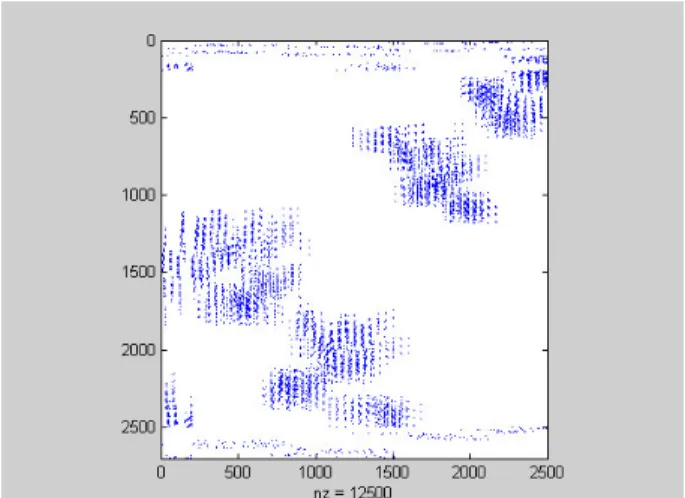
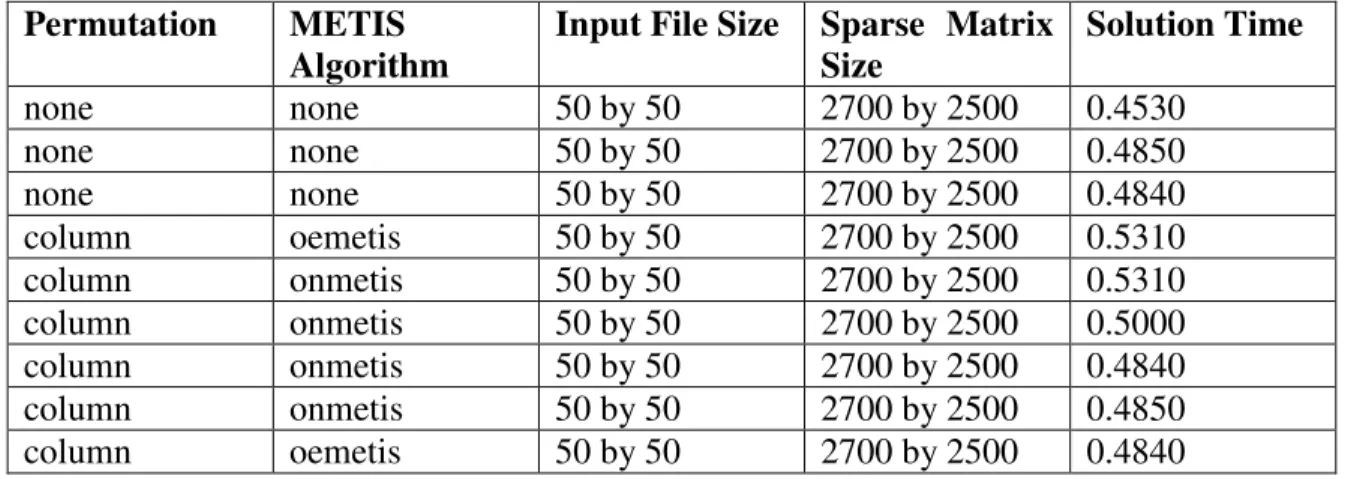
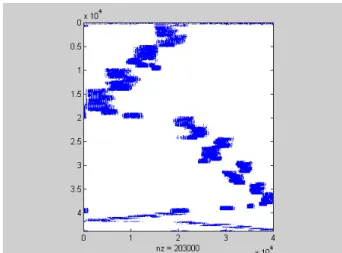
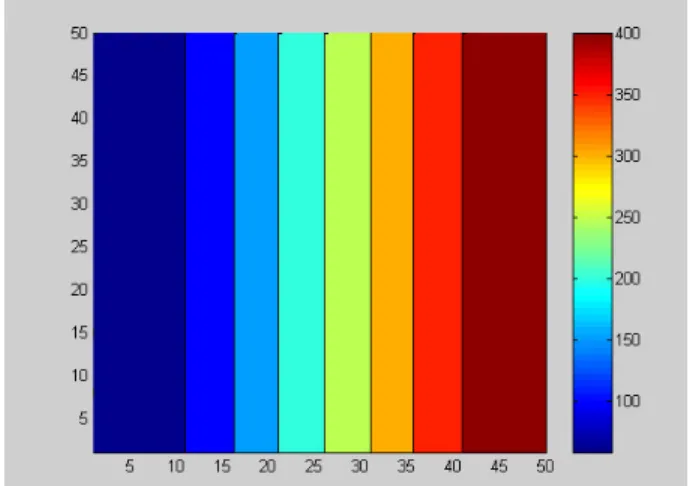
Figure
+7

Related documents
Hydraulic schemes of fish attraction Dam Dam Fish pass Fish pass Attractive flow Attractive flow Current velocity Current velocity Fish guiding facility Vc – critical Vt – threshold
Thirteen of these were included in the BBN, while one (“frequency with which carcasses are removed from pens”) was excluded because all farms adopted the same practice. Two
BIJAGÓS IN-MIGRANT Total livelihood activities undertaken X X Total number of fishing gear types used X X Proportion of time observed allocated to fishing X X Proportion
The findings indicated that families put forward the following reasons for sending their children to preschool: preschool education prepares children for school and helps form
speci?ed anchor contact. 1 is a pictorial illustration of a system and method for matching nearest contacts in a contact hierarchy in accordance With one aspect of the
a remote computer in communication With the server, the server causing the display of the associated member of the ?rst group at the remote computer, the remote com puter having
Tendo em vista que o principal objetivo do trabalho é verificar a influência do desempenho do setor bancário obtido por meio de indicadores contábeis ou financeiros sobre
Our limits on the ejecta mass together with estimated rates directly confirm earlier purely theoretical or indirect observational conclusions that double neutron star mergers are
