Research Article
July
2017
Computer Science and Software Engineering
ISSN: 2277-128X (Volume-7, Issue-7)
Punjabi Pos Tagger: Rule Based and HMM
Umrinderpal Singh, Vishal GoyalPunjabi University, Patiala, Punjab, India DOI: 10.23956/ijarcsse/V7I7/0106
Abstract: The Part of Speech tagger system is used to assign a tag to every input word in a given sentence. The tags may include different part of speech tag for a particular language like noun, pronoun, verb, adjective, conjunction etc. and may have subcategories of all these tags. Part of Speech tagging is a basic and a preprocessing task of most of the Natural Language Processing (NLP) applications such as Information Retrieval, Machine Translation, and Grammar Checking etc. The task belongs to a larger set of problems, namely, sequence labeling problems. Part of Speech tagging for Punjabi is not widely explored territory. We have discussed Rule Based and HMM based Part of Speech tagger for Punjabi along with the comparison of their accuracies of both approaches. The System is developed using 35 different standard part of speech tag. We evaluate our system on unseen data with state-of-the-art accuracy 93.3%.
General Terms: NLP, Part of Speech Tagger Additional Key Words and Phrases: POS, Punjabi, Rule Based, HMM
I. INTRODUCTION
Part of Speech (POS) is a linguistic category of a word based on predefined part of speech tags or word classes. Part of speech can be categorized into closed word class and open word class. Lexical that conveys the true meaning of the sentence belongs to open word class like noun, verbs, adjectives etc. The closed word class has small number of classes to define lexical categories like prepositions, postposition, determiners etc. The Part of Speech tagger assigns a particular tag to a word based on its context in a sentence. Part of speech tagger is an important system that is used in many Natural Language Processing tasks like Machine Translations, Information Extraction, Grammar checker, Parsing etc. In most of the cases, the accuracy of these NLP applications depends upon the accuracy of POS tagger. Therefore, efforts are put to develop an accurate POS tagger for Punjabi. There are different approaches to implement POS tagger, but we have opted to use Rule Based and HMM approach. Rule based approach use linguist rules to tag a given word in a sentence and resolve ambiguities based on these rules. HMM tagger is a machine learning approach based on probability model, where we train system using annotated corpus.
II. ABOUT PUNJABI LANGUAGE
Punjabi is an Indo-Aryan language spoken by 130 million people worldwide
(http://en.wikipedia.org/wiki/Punjabi_language). Punjabi is tenth widely spoken language in the world and the eleventh most widely spoken language in India. Punjabi is the mother tongue of the Indian state of Punjab and Pakistan Punjab. In Pakistan and in Indian Punjab, Punjabi is written in different forms. In India Punjabi is written in Gurmukhi script while in Pakistan it is written in Shahmukhi script. There are many Punjabi speaking people in the UK and in Canada. Therefore, there are huge numbers of Punjabi speaking people worldwide and vast amount of literature is written in Punjabi language. We need to create Natural Language Processing tools so that Punjabi speaking people and other communities take benefits from this tool. For Punjabi language, much work has been done at (http://www.learnpunjabi.org/) Punjabi University, Patiala, which has developed many different Punjabi language systems like Punjabi to Hindi Machine Translation (MT) System, Hindi to Punjabi MT system, Punjabi OCR, Legacy Font Converter, Grammar Checker etc.
III. RELATED WORK
Mandeep Singh[3,4] developed the first part of speech tagger for Punjabi. This was developed as a module in Punjabi grammar checker system. Around 630 tags used. This system was developed using rule based approach. Tagger used the handwritten linguist rules to tag words and to remove the ambiguities. The accuracy of the system was reported to 80.29%. Sapna Kanwar[7] developed HMM based part of speech tagger for Punjabi. Bi-Gram HMM model was used to build this system. Accuracy of the system was 86.2%. Sharma, S.K[7,8] developed HMM based Punjabi part of speech tagger. The Bi-Gram HMM model was used to develop the part of speech tagger, which was trained on annotated corpus, containing 20,000 words. The accuracy of the system is 90.11%. Dinesh Kumar [1] developed part of speech tagger using neural network. This was the first part of speech tagger was developed using Neural Network approach. Multilayer Perceptron with fixed context length was used. To train the Neural Network, Back-Propagation learning algorithm was used. Accuracy of the system was 85.95%. Navneet Garg[6] developed rule based tagger for Hindi, system used lexicon resources, morphological information and various rules to tag unknown words and to resolve ambiguities. S. Singh[11] work suggested how morphological information can be useful to cover-up unknown words and how it can be helpful for resource poor languages. For other part of tagger systems for Indian Languages, reader may refer to Shambhavi. B.R
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Wall street journal of Penn Treebank and French Treebank. Thorsten Brants[15] TnT POS tagger trained on 50k
sentences and delivers 96.7% accuracy using
HMM(http://aclweb.org/aclwiki/index.php?title=POS_Tagging_(State_of_the_art)).
To the best of our knowledge(http://pgc.learnpunjabi.org/#Tagger), there is only one Punjabi POS tagger system available online for use. All the Punjabi POS tagger which has been developed were not using any standard POS tag set, so without any standardization it is difficult to compare one tagger accuracy with the other. The Punjabi annotated corpus contains 20,000 words Sharma, S.K [7,8] was used to train HMM model, which is not adequate training data for any statistical model.
In our work, we have used standard tag set proposed by TDIL (Technology Development for Indian Languages) and
annotated data developed under ILCI (Indian Languages Corpora Initiative) consortium of TDIL, DeitY, GoI, New Delhi, India, for training the POS tagger.
IV. APPROACHES TO POS TAGGER 4.1 Rule Based Approach:
The Rule Based approach is based on linguistic rules. Different linguistic rules are used to tag given word in a sentence[13]. To develop linguistic rules one should have a deep understanding of the target language. Developing the rule-based system is a time consuming task. These systems mainly use large lexicon and many language specific rules[2]. Creating such large dictionaries and rules need ample time and language specific proficiency. The Rule Based systems are mostly domain specific and one cannot extend the rule based system developed for specific domain for some other domain, and these systems are not easily portable.
4.2 Statistical System:
Statistical system is an approach for developing Part of Speech tagger. Statistical systems are based upon probabilities. The system calculates the probability of occurrence of the given word from the training corpus. These systems need large annotated corpus for training the system. In training data, we always try to incorporate all kinds of training examples covering all domains, so that the system will be able to perform well for all kinds of inputs. Development of annotated corpus for training the statistical systems is also a challenging and time consuming task. In statistical system, we have different probabilistic models like SVM, CRF, MaxEnt, HMM etc.
We have used the trigram HMM model to develop POS tagger for Punjabi. HMM model is an interlocked state and all the different states are connected through set of transition probabilities. Transition probability defining the probability of traveling from one state to another state.
The output of HMM is the highest probability state sequence which was hidden corresponding to the given observed
sequence. If we have sentences (s1,s2,...sn) and tag sequence (t1,t2,...tn) and generative model is defined as:
𝑓 𝑠1… 𝑠𝑛 = argmax𝑡…𝑡𝑛𝑃 𝑠1… 𝑠𝑛, 𝑡1… 𝑡𝑛 (1)
Input of s1 to sn we take the highest probability tag sequence as output of model.
Trigram HMM model is defined as:
𝑝 𝑠1… 𝑠𝑛 ,𝑡1… 𝑡𝑛 = 𝑞 𝑡𝑛 𝑡𝑛−2𝑡𝑛−1 𝑒 𝑠𝑖 𝑡𝑖 (2)
𝑖 𝑖
𝑞 𝑡𝑛 𝑡𝑛−1𝑡𝑛 −2 =
𝐹(𝑡𝑛−2𝑡𝑛−1𝑡𝑛)
𝐹(𝑡𝑛−2𝑡𝑛−1) (3)
𝑒 𝑠𝑖 𝑡𝑖 =
𝐹(𝑡𝑖 → 𝑠𝑖) 𝐹(𝑡𝑖)
(4)
Where 𝐹(𝑡𝑛−2𝑡𝑛−1𝑡𝑛) is number of occurrence of the trigram (𝑡𝑛−2𝑡𝑛−1𝑡𝑛) in corpus and 𝐹(𝑡𝑛−2𝑡𝑛−1) is the number of
occurrences of bigram (𝑡𝑛 −2𝑡𝑛 −1) . A trigram HMM consists of a finite set V of possible words vocabulary, and a finite
set of K possible tags. Any trigram (𝑡𝑛−2𝑡𝑛−1𝑡𝑛) such that 𝑡𝑛∈ 𝐾 ∪ {𝑠𝑡𝑜𝑝} , 𝑡𝑛−2𝑡𝑛−1∈ 𝐾 ∪ {𝑠𝑡𝑎𝑟}. The value for
𝑞 𝑡𝑛 𝑡𝑛 −2𝑡𝑛−1 can be interpreted as the probability of seeing the tags immediately after the bigram of tags (𝑡𝑛−2𝑡𝑛 −1).
𝐹(𝑡𝑖 → 𝑠𝑖) Define number of occurrence of word 𝑠𝑖 with tag 𝑡𝑖 divided by total occurrence of tag 𝑡𝑖 . For any 𝑠𝑖∈ 𝑉,
𝑡𝑖∈ 𝐾. The value for 𝑒 𝑠𝑖 𝑡𝑖 can be interpreted as the probability of seeing observation 𝑠𝑖 paired with state 𝑡𝑖.
To find the highest probability tag sequence we used Viterbi Algorithm for decoding the HMM. Viterbi algorithm defined as:
ALGORITHM 1. Viterbi
Input: a Sentence 𝑥1… 𝑥𝑛 𝑎𝑛𝑑 𝑃𝑎𝑟𝑎𝑚𝑒𝑡𝑒𝑟𝑠 𝑞 𝑡𝑛 𝑡𝑛−1𝑡𝑛−2 , 𝑒 𝑠𝑖 𝑡𝑖
Define K to set of all tags. 𝐾−1=𝐾0= (𝑠𝑡𝑎𝑟𝑡)
𝜋 0, 𝑠𝑡𝑎𝑟𝑡, 𝑠𝑡𝑎𝑟𝑡 =1
𝐹𝑜𝑟 𝑘 = 1 … . 𝑛
𝐹𝑜𝑟 𝑎 ∈ 𝐾𝑘−1 , 𝑏 ∈ 𝐾𝑘
𝜋 𝑘, 𝑎, 𝑏 = 𝑎𝑟𝑔𝑚𝑎𝑥(𝜋 𝑘 − 1, 𝑎, 𝑏 ∗ 𝑞 𝑐 𝑎, 𝑏 ∗ 𝑒(𝑥𝑘|𝑐))
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 4.3 Hybrid System:
Hybrid system is a combination of Rule based and Statistical systems. Hybrid system is trained using annotated corpus, along with rule based approach where language specific rules are used[14].
V. TAG SET USED BY OTHER TAGGERS FOR PUNJABI
First tag set used for Punjabi was proposed in 2008[3]. That tag set included many new tags for Punjabi, reason behind the development of a new tag set was that, the existing tag set for other languages like Penn treebank tag set can't be directly used for Punjabi grammar checking. Moreover, there was no well defined and standardized tag set available in any Indian language [3]. Around set of 630 tags were used in this tagger, to choose a best possible tag for a word was a challenging task for a tagger. Word specific tags were also included in tag set, otherwise we use only one tag that represent postposition word, but in this tag set all the postposition having a different tag name for different words. Following Table I shows the excerpt of the tag set.
Table I: Word Specific Tags
Word POS Description
ਦਾ PPIDA Post Position Inflected DA
ਦੀ PPIDA Post Position Inflected DA
ਨੇ PPUNE Post Position Uninflected NE
ਨੂੂੰ PPUNU Post Position Uninflected NU
ਤੋਂ PPUTON Post Position Uninflected TON
ਕੁ PTUKU Particle Uninflected KU
ਕ PTUKE Particle Uninflected KE
VI. POS TAG SET USED FOR OUR TAGGER
TDIL (Technology Development for Indian Languages) is the Government body constituted by the DeitY (Department
of Electronics and Information Technology), MoC&IT (Ministry of Communications and Information Technology), GoI (Government of India), New Delhi, India for setting up standards and development of language resources for Indian languages using the expertise of language and Engineering experts working in various reputed institutes/Universities throughout India Like IITs, NITs, State Universities, Autonomous bodies etc. The TDIL has released BIS Part of Speech tag set for Indian Languages available on their website for using it freely after getting their permission. This is the first standard Part Of Speech (POS) tag set proposed for Indian languages after the contribution of various organizations across India. 22 Indian languages are included in this POS tag set standardization process, and Punjabi is one of them. In Punjabi POS tag set, 35 tags have been defined. There are 11 main categories in tag set and all these main categories are further divided into sub-categories like verb category is divided into five different categories.
Table II: Verb POS Categories
POS Category Main-Category Sub Category POS Tag
Verb
Main Verb V_VM
Non-Finite V_VM_VNF
Infinite V_VM_VINF
Gerund V_VM_VNG
Auxiliary Verb V_VAUX
All 35 tags are given in Appendix 1. We have used this standard POS tag set for implementing POS tagger.
VII. ANALYSIS OF ANNOTATED CORPUS
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Table III: Most Frequent Word-Tag pair
S.No. Words POS Freq
1 | RD_PUNC 49319
2 (Hai) V_VAUX 35737
3 ਦ(Dē) PSP 31256
4 , RD_PUNC 21113
5 ਅਤ(Atē) CC_CCD 16358
6 ਦੀ(Dī) PSP 16161
7 ਵਿੱਚ(Vica) PSP 15542
8 ਦਾ(Dā) PSP 14886
9 ਨੂੂੰ(Nū) PSP 12590
10 ਵਚ(Vica) PSP 12096
Chart 1: Percentage of Occurrence of Tags in Training Corpus
29.27 1.78
0.15 0.57 0.31
0.42 0.01
0.19 0.01
1.44 0.27 0.35 0.02
12.25 2.44
0.03 0.01
5.26 7.74 1.66
16.83 2.86
1.02 0.84 0.01
0.28 1.21 1.16 1.95 0.23 0.21 1.05
8.16 0
0.01
0 5 10 15 20 25 30
N_NN N_NNP N_NST PR_PRP PR_PRF PR_PRL PR_PRC PR_PRQ PR_PRI DM_DMD DM_DMR DM_DMQ DM_DMI V_VM V_VM_VNF V_VM_VINF V_VM_VNG V_VAUX JJ RB PSP CC_CCD CC_CCS RP_RPD RP_INJ RP_INTF RP_NEG QT_QTF QT_QTC QT_QTO RD_RDF RD_SYM RD_PUNC RD_UNK RD_ECH
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Chart 1 shows percentage of per tag in corpus. As we can see that N_NN and PSP tags are most frequently used tags. During this analysis, we also found different ambiguous words along with their frequency. These ambiguous words help us to create different linguistic rules to resolve ambiguities. Some ambiguous words are shown in Table IV.
Table IV: Ambiguous Words
S.No. Word POS Freq
1 ੀਰਾ(Hīrā) N_NN 4
2 ੀਰਾ(Hīrā) N_NNP 2
3 ੀ(Hī) RP_RPD 4497
4 ੀ(Hī) QT_QTF 6
5 ੀ(Hī) V_VAUX 3
6 ੀ(Hī) N_NN 2
7 ੀ(Hī) V_VM 2
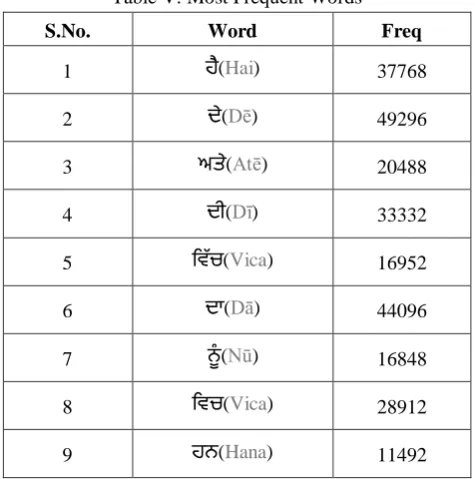
Following Table V shows most frequent words in the corpus. Here we are not considering punctuation marks and symbols otherwise ' | ' punctuation mark is most frequent one which has occurred 49319 times.
Table V: Most Frequent Words
S.No. Word Freq
1 (Hai) 37768
2 ਦ(Dē) 49296
3 ਅਤ(Atē) 20488
4 ਦੀ(Dī) 33332
5 ਵਿੱਚ(Vica) 16952
6 ਦਾ(Dā) 44096
7 ਨੂੂੰ(Nū) 16848
8 ਵਚ(Vica) 28912
9 ਨ(Hana) 11492
The purpose of this analysis was to create some tagging rules for unknown and for ambiguous words. We have used all these rules in HMM and Rule Based tagger to tag unknown words which are not the part of the training data.
VIII. RULE BASED TAGGER
The Rule Based system uses large gazetteer list and various linguistic rules to tag input words. We have developed linguistic rules to tag given input text and a large gazetteer list of word-tag mapping. This list contains 73713 unique words along with their tags. By the analysis of annotated corpus, we got various ambiguous words that can be tagged to different word classes. We create an ambiguous word list; this list contains 20214 unique words. Ambiguous words are 27% of all unique words. To remove the ambiguity and assign a correct tag to a word we have developed various rules. For example, to remove ambiguity of PR_PRP tag, we have used following rules to tag it as DM_DMD:
CW="PR_PRP" AND NW="PR_PRP" THEN CW=" DM_DMD" CW="PR_PRP" AND NW="N_NN" THEN CW=" DM_DMD"
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205
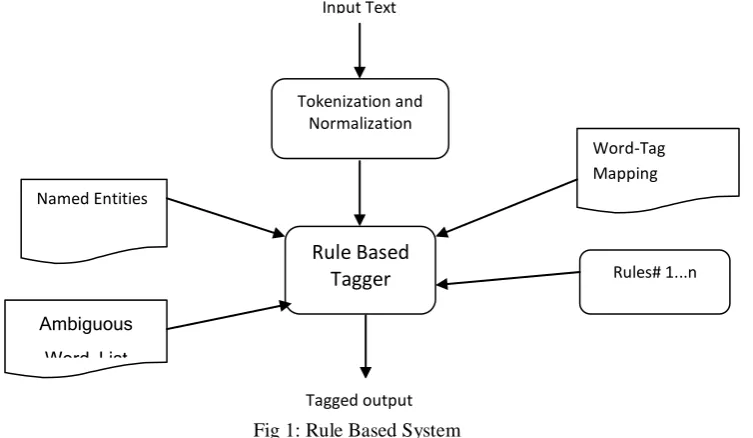
Fig 1: Rule Based System
Firstly, the system finds the current word in word-tag mapping lexicon. This lexicon contains unique and unambiguous words, if word found in the lexicon we simply tag that word with its POS, otherwise the system verify that word in the ambiguous word list collection and apply various rules to resolve its ambiguity.
To tag unknown words, which are not part of our lexicon, we have developed many rules to tag all these words. These rules are also used to resolve ambiguity of any given word tag token. Following rules has been used to tag unknown and ambiguous words.
Rule 1: if PW="N_NN" and NW="N_NN" then CW="PSP"
Exp: ਉਨਹਾਂ\DM_DMD ਦੀਆਂ\PSP ਅਿੱਖਾਂ\N_NN ਵਚ\PSP ੂੰਝੂ\N_NNਨ\V_VAUX
{ Unhāṁ\DM_DMD dī'āṁ\PSP akhāṁ\N_NN vica\PSP hajhū\N_NN} English: Tears in their eyes.
Rule 2: if PW=" V_VM_VF" and NW=" RD_PUNC" then CW=" V_VAUX"
Exp: ਕਾਰਨ\N_NN ਫਣ\V_VM ਸ਼ਕਦਾ\V_VM_VF \V_VAUX |\RD_PUNC
{ Kārana\N_NN baṇa\V_VM sakadā\V_VM_VF hai\V_VAUX |\RD_PUNC } English: This may cause of
Rule 3: if PW=" PSP" and NW="N_NN" then CW=" PSP"
Exp: ਉਸ਼\PR_PRP ਦੀ\PSP ਘਰ\N_NN ਾਲੀ\PSP
{Usa\PR_PRP dī\PSP ghara\N_NN vālī\PSP} English: His wife.
Rule 4: if PW="PSP" and NW="N_NN" then CW="JJ"
Exp: ਸ਼ਰਕਾਰ\N_NN ਦੀਆਂ\PSP ਅਵਭ\JJ ਰਾਤੀਆਂ\N_NN
{ Sarakāra\N_NN dī'āṁ\PSP ahima\JJ prāpatī'āṁ\N_NN } English: Main achievement of government.
Rule 5: if PW="CC_CCD" and NW="PSP" then CW="N_NN"
Exp: ਭਸ਼ੂੜ\N_NN ਅਤ\CC_CCD ਦੂੰਦਾਂ\N_NN ਦੀਆਂ\PSPਿੱਡੀਆਂ\N_NN
{ Masūṛē\N_NN atē\CC_CCD dadāṁ\N_NN dī'āṁ\PSP haḍī'āṁ\N_NN} English: Gums and teeth bones.
Rule 6: if NW="PSP" and NNW="N_NN" then CW="N_NN"
Exp: ਫੁਤ\QT_QTF ਲਕ\N_NN ਦੂੰਦਾਂ\N_NN ਦੀ\PSP ਦਖਬਾਲ\N_NNਵਚ\PSP
{Bahutē\QT_QTF lōka\N_NN dadāṁ\N_NN dī\PSP dēkhabhāla\N_NN vica\PSP} English: Caring of teeth.
Rule 7: if NW="PSP" and NNW="JJ" then CW="N_NN"
Exp: ਦੂੰਦਾਂ\N_NN ਵਚ\PSP ਠੂੰਢਾ\JJ -\RD_PUNC ਗਰਭ\JJ ਾਣੀ\N_NN
Rule Based
Tagger Rules# 1...n
Input Text IextText
Tagged output Tokenization and
Normalization
Named Entities
Word-Tag Mapping
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 { Dadāṁ\N_NN vica\PSP ṭhaḍhā\JJ -\RD_PUNC garama\JJ pāṇī\N_NN}
English: Sensitivity in teethes.
Rule 8: if PW="N_NN" and NW="PSP" then CW="JJ" Exp:ਰਗਾਂ\N_NN ਦਾ\PSP ਭੂਲ\JJ ਕਾਰਨ\N_NNਇਕ\QT_QTC
{ Rōgāṁ\N_NN dā\PSP mūla\JJ kārana\N_NN ika\QT_QTC} English: Main cause of disease.
After adding all these rules, the system performed well for unknown and for ambiguous words, but system still left many words untagged or choose wrong tags. The main problem was in (N_NNP) proper nouns, name of the locations and person. Therefore, we collect Punjabi person's name along with their surname and create a list of popular cities and towns. After using this proper name list, system is able to tag proper noun words correctly. We have developed rules to tag location and unknown person names as well, which are not part of the dictionary. These rules related to Named Entity
Recognition also help us to resolve ambiguity in the person's name like the word "ਲਾਲ"(lal) (meaning: Red) is an
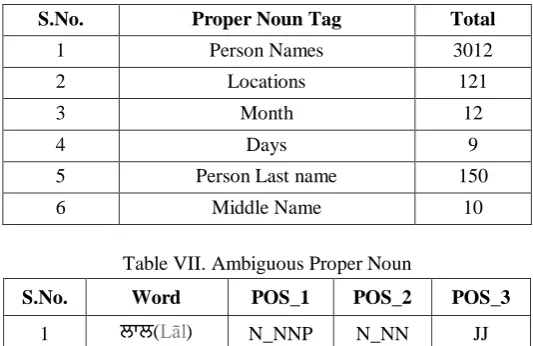
ambiguous word. It can be a noun or it can be a proper noun. Table VI shows Information about the collection of Named Entities and Table VII shows some ambiguous NE words and candidate POS tags found in corpus.
Table VI. Proper Name Collection
S.No. Proper Noun Tag Total
1 Person Names 3012
2 Locations 121
3 Month 12
4 Days 9
5 Person Last name 150
6 Middle Name 10
Table VII. Ambiguous Proper Noun
S.No. Word POS_1 POS_2 POS_3
1 ਲਾਲ(Lāl) N_NNP N_NN JJ
2 ੀਰਾ(Hīrā) N_NNP N_NN
3 ਤਾਰਾ(Tārā) N_NNP N_NN
4 ਲਾਬ(Lābha) N_NNP N_NN JJ
Alongside this, we have used some morphological features. Suffix stripping is used to determine the POS tag of OOV (out of vocabulary) words. To tag unknown location, we create various rules, based on the suffix of that that word. In
Punjab as well as in other States of India UmrinderPal [9], most of the location names usually end with suffix "ੁਰ"(pur),
"ਫਾਦ"(abad) etc. Therefore, we have used these clues to tag them as proper nouns.
Following Rules help to tag person name with the help of last name. Rule 1: if CW="Last Name" then PW="N_NNP"
Exp: ਗੁਜਰਾਤ\N_NNP ਦ\PSP ਭੁਿੱਖ\JJ ਭੂੰਤਰੀ\N_NNP ਨਵਰੂੰਦਰ\N_NNP ਭਦੀ\N_NNPਨੇ
{ Gujarāta\N_NNP dē\PSP mukha\JJ matarī\N_NNP naridara\N_NNP mōdī\N_NNP nē } English: Narinder Modi Chief Minister of Gujarat.
Rule 2: if CW="Middle Name" then PW="N_NNP" AND NW=N_NNP
Exp: ਰਣਫੀਰ\N_NNP ਲਾਲ\N_NNP ਗੁਰਦਾਸ਼ੁਰ\N_NNP
{ Raṇabīra\N_NNP lāla\N_NNP guradāsapura\N_NNP } English: Ranbir lal Gurdaspur
Following rules based on suffix of the word to tag locations:
Rule 1: if CW="Ends with ੁਰ" then CW="N_NNP"
Exp: ਭਣੀੁਰ\N_NNPਦ\PSP ਲਕ\N_NN
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 English: People of Manipur.
Rule 2: if CW="Ends with ੁਰਾ" then CW="N_NNP"
Exp: ਉ\PR_PRP ਵਕਵਨੁਰਾ\N_NNPਵਚ\PSP ਰਵਦਾ\V_VM_VF \V_VAUX ।\RD_PUNC
{Uha\PR_PRP kiśanapurā\N_NNP vica\PSP rahidā\V_VM_VF hai\V_VAUX।\RD_PUNC}
English: He lives in Kishanpura.
Rule 3 if CW="Ends with ਫਾਦ" then CW="N_NNP"
Exp: ਉ\PR_PRP ਅਵਭਦਾਫਾਦ\N_NNPਵਗਆ\V_VM_VF ।\RD_PUNC
{Uha\PR_PRP ahimadābāda\N_NNP gi'ā\V_VM_VF।\RD_PUNC}
English: He went to Ahmadabad.
To tag OOV words that ends with "ਾਂਗ"(Vāṅgē) , "ਾਂਗਾ"(Vāṅgā) , "ਾਂਗੀ"(Vāṅgī), tagged as Infinitive Verb, for example:
ਲਾਂਗ(Lavāṅgē)("will take"), ਲਾਂਗੀ(Lavāṅgī)(will take; feminine), ਦਾਂਗਾ(Dēvāṅgā)(will give). Words ends with
"ਾਕ(Vākē)", tagged as Non-finite Verb, for example: ਫਣਾਕ(Baṇavākē).
IX. HMM BASED TAGGER
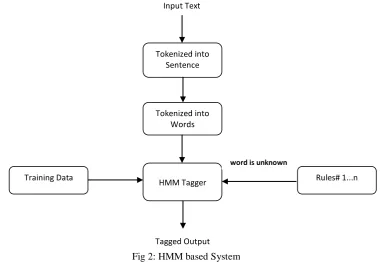
Along with the Rule based system, we have developed Trigram HMM based tagger, a statistical tool used for sequence categorized by a set of observable sequence described in section 4. HMM has rich history in sequence data modeling [10] and very successfully used by many researchers [5,12,15]. We have developed HMM system using C#.net. To train the system we used annotated corpus provided by TDIL. Corpus has 49 thousand sentences. Around 44387 sentences has been used to train the HMM system, which was 90% of the total available corpus.
Fig 2: HMM based System
Tokenization and Normalization module clean and tokenize the text into sentences and words for further processing. Vitirbi algorithm is used for decoding process. To cover up new and unknown words, which are not part of the training data, we used same rules, which have been developed in rule-based tagger. Suffix of the word used as features to tag token as NE. With the help of these rules, we are able to cover up all the unknown words.
X. EVALUATION
Evaluation is done on 10% of the corpus data. Test data includes 4932 sentences of Health and tourism domain. Besides this, we have also collected test data related to Health and Tourism News from the online news website http://www.ajitjalandhar.com. This data contains 250 sentences. Detail of testing data is in following Table VIII:
HMM Tagger Rules# 1...n
Input Text
Tokenized into Words
Tagged Output
word is unknown
Training Data
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Table VIII. Detail of testing data
Test Set Domain No. of Sentences No. of Words
Set 1 Health Related Data 2098 36023
Set 2 Tourism Related Data 3084 40144
Total 5182 76167
We have used 150 rules to tag unknown words and to resolve ambiguity. During the testing phase, we come to know that some of the rules failed in some typical sentences. We have done analysis showing that which rule is frequently used and which one is least used. Accuracy and rules applied to tag words in testing data may vary based on test data domain. In testing data, 699 words were unknown or new, those are tagged using assorted rules. Analyses of the rules, which have been used throughout the testing phase of HMM and Rule Based Tagger to tag unknown words, are shown in following chart.
Chart 2. Rules used in Testing
Rule 1 is most frequently used rule for tagging unknown word, defined as if NW="PSP" then CW="N_NN"
Similarly Rule 2 is most used rule which is if NW="N_NN" then CW="PSP"
Total 29 rules are used out of 150 rules during testing. Rules details are presented in Appendix 2. Sometimes the system failed to tag the given word with correct POS for example:
Punjabi Sentence: ਭੈਂਨੀਂਵਦਿੱਲੀਵਗਆ|(Maiṁ navīṁ dilī gi'ā)
English: I went to New Delhi.
Output: ਭੈਂ\PR_PRP ਨੀਂ\JJਵਦਿੱਲੀ\N_NNP ਵਗਆ\V_VM_VF ।\RD_PUNC
Here New Delhi is a Proper noun, but system tagged word New as JJ (Adjective), which is also a valid candidate tag for word New.
The accuracy of the system has been calculated using standard evaluation metrics viz. Precision, Recall and F1-Score. When system assigns correct tags to the given words known as TP (True Positive). However, system might assign incorrect tags known as FP (False Positive), and when the system does not assign any tag to a given word known as FN (False Negative). F2-Score of test's accuracy, it include both precision and recall of the test to compute the score.
𝑅𝑒𝑐𝑎𝑙𝑙 𝑅 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁 (5) 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑃 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑃 (6) 𝐹1 − 𝑆𝑐𝑜𝑟𝑒 = 2 ∗ (𝑅 ∗ 𝑃)
(𝑅 + 𝑃) (7)
179
89
15 10
3138 39 19 17
9 11 7 13 12 25
8 8 29 29
14 14 12 12 8 1211 4 4 20
Ru le 1 Ru le 2 Ru le 3 Ru le 5 Ru le 7 Ru le 8 Ru le 9 Ru le 1 0 Ru le 1 1 Ru le 1 2 Ru le 1 3 Ru le 1 4 R u le 15 Ru le 1 7 Ru le 1 8 Ru le 1 9 Ru le 2 0 Ru le 2 2 R u le 23 Ru le 2 6 Ru le 2 7 Ru le 2 8 Ru le 2 9 Ru le 3 1 R u le 34 Ru le 3 5 Ru le 3 6 Ru le 3 8 Ru le 1 4 2 0 20 40 60 80 100 120 140 160 180 200
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Table IX: Accuracy using Rule Based System
Test Set Precision Recall F1-Score
Set 1 0.867 0.984 0.922
Set 2 0.92 0.929 0.924
Table X: Accuracy using HMM based System Test Set Precision Recall F1-Score
Set 1 0.869 0.993 0.927
Set 2 0.921 0.945 0.933
Chart 3. Accuracy of the System
Chart 4. Accuracy of the Rules 92.2
92.4
92.7
93.3
Set 1 Set 2
HMM
RuleBased
99 97 90 92
100 100 100 100 98 100 100 100 99
100 98 100 98 100 100 98
97
95 100
100 100 100 98 99
100
84 86 88 90 92 94 96 98 100 102 Rule 1
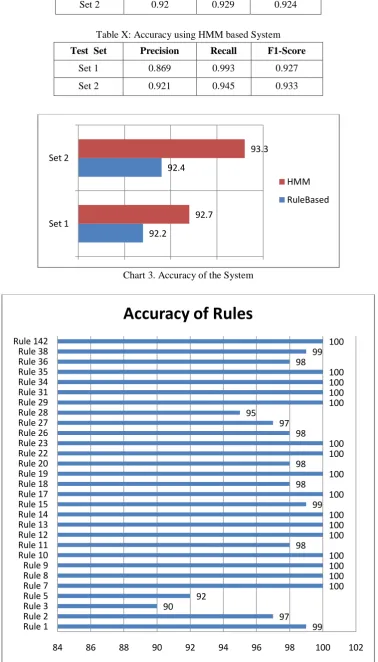
Rule 2 Rule 3 Rule 5 Rule 7 Rule 8 Rule 9 Rule 10 Rule 11 Rule 12 Rule 13 Rule 14 Rule 15 Rule 17 Rule 18 Rule 19 Rule 20 Rule 22 Rule 23 Rule 26 Rule 27 Rule 28 Rule 29 Rule 31 Rule 34 Rule 35 Rule 36 Rule 38 Rule 142
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 XI. CONCLUSION AND FUTURE WORK
We have developed POS tagger for Punjabi using two different approaches. Rule Based approach has been used where various rules to tag unknown words and to resolve ambiguity has been developed. HMM model is a statistical model, which is much simpler and faster than other statistical models to find out the correct tag of given word. Results shows that 49 thousand annotated text data is quite enough to train the HMM system. We have concluded from the evaluation results that both HMM system performed well as compared to Rule Based systems. We have achieved maximum F1-Score 0.933 on Tourism domain's data and 0.927 on Health domain data. Thus, the results may vary for other domains. To the best of our knowledge, this is maximum accuracy achieved by any POS tagger for Punjabi developed so far. For future work, we will try incorporate more morphological features to cover-up OOV words and to cover up other domains like science, agriculture, entertainment etc., we will try to collect annotated data of all these domains.
ACKNOWLEDGEMENT
This research work is an effort for the automation of the objective of the project funded to the author Vishal Goyal by TDIL, DeitY, MoC&IT, GoI, New Delhi, India. The project titled "Indian Languages Corpora Initiative (ILCI) - Phase II" is an initiative under the consortium of 17 Universities / Institutes led by JNU, New Delhi, India for developing the annotated corpora for Agriculture and Entertainment domain manually. The annotation task for Health and Tourism domain has already been completed in Phase I of this project. We are thankful to TDIL for supporting us and providing the annotated corpus of Health and Tourism domain which is used for training the tagger.
REFERENCES
[1] Dinesh Kumar and Gurpreet Singh Josan, 2010. Part of Speech Taggers for Morphologically Rich Indian
Languages: A Survey , International Journal of Computer Applications (0975 – 8887) Volume 6– No.5, 1-7
[2] Eric Brill, 1992. A Simple Rule-Based Part of Speech Tagger, in HLT '91 Proceedings of the workshop on
Speech and Natural Language, 112-116
[3] Mandeep Singh Gill, Gurpreet Singh Lehal and Shiv Sharma Joshi, 2008. Part of Speech Taggset for Grammer
Checking of Punjbai, Apeejay Journal of Management and Technology vol.3, No.2, 146-152
[4] Mandeep Singh Gill and Gurpreet Singh Lehal, 2008. A Grammar Checking System for Punjabi, Coling 2008:
Companion volume – Posters and Demonstrations, 149–152
[5] Manish Shrivastava, Pushpak Bhattacharyya, 2008. Hindi POS Tagger Using Naive Stemming : Harnessing
Morphological Information Without Extensive Linguistic Knowledge, In Proceedings of ICON-2008: 6th International Conference on Natural Language Processing, Macmillan Publishers, India.
[6] Navneet Garg, Vishal Goyal and Gurpeet Singh Lehal, 2012. Rule Based Hindi Part of Speech Tagger,
Proceedings of COLING 2012: Demonstration Papers, 163–174
[7] Sapna Kanwar, Mr Ravishankar and Sanjeev Kumar Sharma, 2011. POS Tagging of Punjabi language using
Hidden Markov Model, Research Cell: An International Journal of Engineering Sciences ISSN: 2229-6913 Issue July 2011, Vol. 1. 98-106
[8] Sanjeev Kumar Sharma and Gurpreet Singh Lehal, 2011. Using Hidden Markov Model to improve the accuracy
of Punjabi POS Tagger, Computer Science and Automation Engineering (CSAE), 2011 IEEE International Conference, Vol.2. 697-701
[9] UmrinderPal Singh, Vishal Goyal and Gurpreet Singh Lehal, 2012. Named Entity Recognition System for Urdu,
In Proceedings of COLING 2012 Technical Papers, 2507–2518
[10] L. Rabiner, 1989. A Tutorial on Hidden Markov Model and Selected Application in Speech Recognition, in
Proceeding on the IEEE, Vol. 77, Issue. 2, 257-286
[11] S. Singh , K. Gupta , M. Shrivastava and P. Bhattacharya, 2006. Morphological Richness offsets Resources
Demand- Experiences in Construction a POS Tagger for Hindi, In proceeding of COLING 2006, 779-786
[12] Manish Shrivastava and Pushpak Bhattacharyya, 2008. Hindi POS Tagger Using Naive Stemming: Harnessing
Morphological Information Without Extensive Linguistic Knowledge, In proceeding of ICON 08, Pune, India, December, 2008
[13] A. Bharati, V. Chaitanya, R. Sangal, 1995. Natural Language Processing : A Paninian Perspective . Prentice
Hall India
[14] Sandipan Dandapat, Sudeshna Sakar and Anupam Basu, 2004. A hybrid model for part-of-speech tagging and
its application to Bengali, in proceeding of International Conference on computation intelligence, 169-172
[15] Thorsten Brants, 2000. TnT -- A Statistical Part-of-Speech Tagger, In proceeding of the 6th Applied NLP
Conference, 224-231
[16] Anne Abeille,´ Nicolas Barrier, 2003. Building a Treebank for French, Text, Speech and Language Technology,
Vol 20. 165-187
[17] Shambhavi. B.R, Dr. Ramakanth Kumar P, 2010. Current State of Art POS Tagging for Indian Languages - A
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205 Appendix 1: Tag Set Proposed by TDIL, DeitY, GoI, New Delhi, India
No. Tag Tag Description Example
1 N_NN Common Noun ਘਰਵਕਤਾਫ(Ghara kitāba)
2 N_NNP Proper Noun ਵਰੂੰਦਰ,ਵਦਿੱਲੀ, ਤਾਜਵਭਲ(Harivadara,dilī,
tājamihala)
3 N_NST Noun loc ਉਤਥਿੱਲਅਿੱਗਵਿੱਛ(Utē thalē agē pichē)
4 PR_PRP Personal Pronoun ਭਤੁੂੰਉ(Mai tu uha)
5 PR_PRF Reflexive Pronoun ਆਣਾਆਖੁਦ(Āpaṇā āpa khuda)
6 PR_PRL Relative Pronoun ਜ, ਵਜਸ਼ਵਜਡ਼, ਜਦੋਂ,( Jō, jisa jihaṛa, jadōṁ)
7 PR_PRC Reciprocal Pronoun ਆਸ਼(Āpasa)
8 PR_PRQ Wh-word Pronoun ਕਣਕਦੋਂਵਕਿੱਥ(Kauṇa kadōṁ kithē)
9 PR_PRI Indefinite ਕਈ, ਵਕਸ਼(Kō'ī, kisa)
10 DM_DMD Deictic Demonstrative ਇਉ(Iha uha)
11 DM_DMR Relative Demonstrative ਜਵਜਸ਼(Jō jisa)
12 DM_DMQ Wh-word Demonstrative ਕਣ(Kauṇa)
13 DM_DMI indefinite Demonstrative ਕਈਵਕਸ਼(Kō'ī kisa)
14 V_VM Main Verb ਆਇਆਜਾਕਰਦਾਭਾਰਾਂਗਾਵਰੂੰਦਾ(Ā'i'ā jā
karadā mārāṅgā rihadā)
15 V_VM_VNF Non-finite Verb
ਜਾਵਦਆਂ, ਆਵਦਆਂ,ਕਵਰਦਆਂ, ਖਾਕ, ਜਾਕ(ādi'āṁ, ādi'āṁ,karida'āṁ, khākē,
jākē)
16 V_VM_VINF Infinitive Verb ਵਗਆਂਆਇਆਂਵਕਰਆਂ(Gi'āṁ ā'i'āṁ kira'āṁ)
17 V_VM_VNG Gerund Verb ਜਾਣੋਂਖਾਣੋਂੀਣੋਂਭਰਨੋਂ(jāṇōṁ khāṇōṁ pīṇōṁ
maranōṁ)
18 V_VAUX Auxiliary Verb , ਸ਼ੀ, ਵਸ਼ਕਆਇਆ(Hai, sī, sika'ā hō'i'ā)
19 JJ Adjective ਸ਼ਣਾਚੂੰਗਾਭਾਡ਼ਾਕਾਲਾ(Sōhaṇā cagā māṛā
kālā)
20 RB Adverb ਲ਼ੀਕਾਲੀ(Hauḻī kāhalī)
21 PSP Postposition ਨੇਨੂੂੰਤਨਾਲ(Nē nū tō nāla)
22 CC_CCD Co-ordinator ਅਤਜਾਂ(Atē jāṁ)
23 CC_CCS Subordinator ਵਕਉਵਕਵਕਜਤਾਂ(Ki'uki ki jō tāṁ)
24 RP_RPD Default Particles ੀਤਾਂੀ(Vī tāṁ hī)
25 RP_INJ Interjection Particles ਉਏਅਵਡਆਨੀਜਨਾਫ(U'ē aḍi'ā nī janāba)
26 RP_INTF Intensifier Particles ਫੁਤਫਡਾ(Bahuta baḍā)
27 RP_NEG Negation ਨੀਂਨਾਵਫਨਾਂਗਰ(Nahīṁ nā bināṁ
vagaira)
28 QT_QTF General ਥਡ਼ਾਫੁਤਾਕਾਪੀਕੁਝਇਿੱਕਵਲਾ(Thōṛā
ISSN(E): 2277-128X, ISSN(P): 2277-6451, DOI: 10.23956/ijarcsse/V7I7/0106, pp. 193-205
39 QT_QTC Cardinals ਇਿੱਕਦਵਤੂੰਨ(Ika dō tina)
30 QT_QTO Ordinals ਵਲਾਦੂਜਾ(Pihalā dūjā)
31 RD_RDF Foreign word Residuals
32 RD_SYM Symbol Residuals $, &, *, (, )
33 RD_PUNC Punctuation ., : ;
34 RD_UNK Unknown
35 RD_ECH Echo-words ਾਣੀ-ਧਾਣੀ , ਚਾ-ਚੂ(Pāṇī-dhāṇī,
cāha-cūha)
Appendix 2 : Rules used by System Rules to tag Unknown Words:
Rule 1: if NW="PSP" then CW="N_NN" Rule 2: if NW="N_NN" then CW="PSP"
Rule 18: if PW="PSP" and NW="PSP" then CW="N_NN" Rule 19: if PW="N_NN" and NW="PSP" then CW="N_NN" Rule 20: if PW="JJ" and NW="PSP" then NW="N_NN" Rule 22: if PW="PSP" and NW="N_NN" then CW="N_NN" Rule 23: if PW="RD_PUNC" and NW="PSP" then CW="N_NN"
Rule 26: if PW="V_VM_VF" and NW="V_VAUX" then CW="V_VM_VF" Rule 27: if PW="N_NNP" and NW="PSP" then CW="N_NNP"
Rule 28: if PW="RD_PUNC" and NW="N_NN" then CW="N_NN" Rule 29: if PW="V_VM_VNF" and NW="N_NN" then CW="PSP" Rule 31: if PW="CC_CCD" and NW="PSP" then CW="N_NN" Rule 34: if PW="N_NN" and NW="RB" then CW="PSP" Rule 35: if PW="JJ" and NW="N_NN" then CW="N_NN" Rule 36: if PW="JJ" and NW="RD_PUNC" then CW="V_VAUX" Rule 38: if PW="PSP" and NW="N_NN" then CW="JJ"
Rule 142: if PW="DM_DMD" and NW="QT_QTC" then CW="PSP"
Rules to resolve Ambiguity:
Rule3: if CW="JJ" then NW="N_NN" Rule 5: if CW="PR_PRL" then NW="N_NN" Rule 7: if CW="PR_PRF" then NW="N_NN" Rule 8: if CW="PR_PRP" then NW="N_NN" Rule 9: if CW="PSP" then PW="N_NN" Rule 10: if CW="V_VM" then PW="N_NN"
Rule 11: if CW="N_NN" then PW="N_NN" or NW="N_NN"
Rule 12: if CW="PR_PRP" and NW="PR_PRP" then CW="DM_DMD" Rule 13: if CW="PR_PRP" and NW="N_NN" then CW="DM_DMD" Rule 14: if CW="Last Name" then PW="N_NNP"