Dependency Grammar Based Feature
Extraction for Text Summarization
D.Y.Sakhare, Dr.Rakjumar,
ABSTRACT
Recently, there has been a lot of significant research in automatic text summarization. Many researchers use feature-based techniques. Feature based techniques most of the times are based on the soft computing. So they can add only the stastical information. These techniques have shown the efficient results. They fail to add the semantic information in the summary. Here we present an approach to improve the summarization systems. We aim to achieve this target with the use of dependency grammar (DG). This is not been widely applied for text summarization due to its difficulty of handling it in summarization process. At first the input document is subjected for the sentence segmentation. The segmented sentence is then given to the POS tagger, which will be based on DG, for extracting the syntactic structure of the sentence. Every keyword of the sentence is tagged by the POS tagger that is used to extract the syntactic structure of the sentence. The dependency grammar then constructs the syntactic structure trees. Then the neural network is trained based on the syntactic structure of sentences. Finally, the neural network is used with weighted average to find the sentence score .The sentences with high sentence score will be added in summary. The experimentation is carried out using DUC 2002 dataset.
Keywords: - Text summarization, dependency grammar, syntactic structure, POS tagger.
1. Introduction
Language which is the ability to speak, write and communicate is the most fundamental aspects of human behavior. As the study of human-languages developed the concept of communicating with the help of non-human devices started developing. This is the origin of natural language processing (NLP). Natural Language Processing (NLP) is an area of research and application in the field of cognitive science. It analyzes how computers can be used for understanding and manipulating natural language text or speech to achieve the desired tasks.. The goal of NLP researchers is to develop and build the computer system which can analyze, understand as well can generate natural human-languages. Natural language communication is considered as major goal of artificial intelligence [1]. There are many applications of natural language processing developed over the years. These applications are divided in two parts. First the text based applications involve examples such as searching a topic or a keyword in a huge data base, information extraction from a large document, translation, summarizing the text. Secondly the dialogue based applications involve examples like question answering systems, tele answering machines, teaching systems, voice controlled machines (that take instructions by speech) and general problem solving systems.
There are more useful goals for NLP; most of them are related to the particular application for which it is being employed. The aim of the NLP system is to represent the exact meaning and purpose of the user’s inquiry, which can be expressed in a usual language as if they were speaking to a reference librarian. Moreover, the contents of the documents that are being searched will be represented at all their levels of meaning so that a true match between need and reply can be found, despite how they are represented in their surface form. Researchers mainly focus on techniques that have been developed in Information Retrieval while most try to influence both IR approaches and some features of NLP [1,2].
should meet the major concepts of the original document set, should be redundant-less and ordered [6]. These attributes are the basis of the generation process of the summary. The quality of summary is sensitive for those attributes relating to how the sentences are scored on the basis of the employed features. Consequently, the estimation of the efficacy of each attribute could result the mechanism to distinguish the attributes possessing high priority and low priority [7].
In this paper, we have presented a technique to extract the syntactical structure of a sentence with the use of dependency grammar. Initially, the preprocessing steps are applied to the input document to extract the sentences Then, to make use of the dependency grammar, the syntactic structure of every sentence is identified using the POS tagger that is a necessary component of most text analysis systems, as it assigns a syntax class (e.g., noun, verb, adjective, and adverb) to every word in a sentence. Subsequently, training matrix is generated with the help of the syntactic structure to train the neural network separately. For testing phase, every sentence are subjected to the feature extraction and structure extraction phase to generate the feature vector and the structure vector. Then, vectors are given to the trained neural network for finding the sentence score and sentence score obtained for every sentence from two neural networks are combined with the weighted average formulae. Finally, sentences are selected as summary based on the sentence score obtained and the ordering process is carried out to make the summary in a meaningful manner.
The paper is organized as follows: Section 2 describes the review of recent works presented in the literature. Section 3 presents the proposed approach for text summarization. Section 4 discusses the experimentation and discussion about the experimental results. Finally,
conclusion is given in section 5.
2. REVIEW OF RELATED WORKS
During these days there is significant contribution in the field of summarization. We tried to review some recent work in this fields. a deep learning model based frame work is proposed by Yan Liu et al. [8] .this frame work has demonstrated distinguished extraction ability in document summarization. Basically this framework has three parts:1)concepts extraction, 2)summary generation 3)reconstruction validation. They developed a query oriented A query-oriented extraction technique was proposed to concentrate information distributed in multiple documents to hidden units layer by layer. Then, the whole deep architecture was fine-turned by minimizing the information loss in reconstruction validation part. According to the concepts extracted from deep architecture, dynamic programming was used to seek most informative set of sentences as the summary. The efficiency of this framework was demonstrated using on three benchmark dataset.
Shasha Xie and Yang Liu [9] have used a supervised learning approach for the summarization task. They used a classifier for the selection of a summary based on an affluent set of features. The two important problems are addressed there. Firstly a diverse sampling technique has been proposed to handle the imbalanced data problem for the task in which the summary sentences are the minority class. Secondly a regression model has been used rather than binary classification for reframing the extractive summarization task in order to deal with human annotation disagreement problem.
Allan Borra et al. [10] have developed a system that would be able to summarize a given document while still maintaining the reliability and saliency in the text. To achieve this, two main existing methods such as keyword extraction and discourse analysis based on Rhetorical Structure Theory (RST) have been included in ATS by the system architecture.
Rafeeq Al-Hashemi [11] has used an extractive technique to solve the problem with the idea of extracting the keywords, even if it does not exist explicitly within the text. The main role of their proposed project is the design of the keyword extraction subsystem which supports to select the more meaningful sentences to be in the summary. Their model contain four stages, mainly for the purpose of eliminating the stop words, extracting the keywords, ranking the sentences based on the keywords available in the sentences and finally for reducing the sentences using KFIDF measurement. Ju-Hong Lee et al.[12] have proposed an innovative technique using Non-negative Matrix Factorization (NMF) in order to select the sentences for automatic generic document summarization. Non-negative constraints have been used by the proposed technique, which are more similar to the human cognition process. Also, the technique does not require any training summaries for the summarizer. Moreover, they have proved that their proposed technique has selected more meaningful sentences for generic document summarization than the sentence selected using Latent Semantic Analysis (LSA).
Nadira Begum et al. [13] have proposed an approach for a trainable summarizer, which consider several features such as sentence position, sentence centrality, sentence resemblance to the title, sentence insertion of name entity, sentence inclusion of numerical data, sentence relative length, bushy path of the sentence and aggregated similarity for each sentence to create summaries. Then the Support Vector Machine (SVM) has been trained by using all features score function in order to build a text summarizer model.
designed fuzzy analyzers based on human acuity. The text summarization system includes: the text preprocessor that extracts the information necessary for fuzzy analysis and the analyzers that have fuzzy inference systems. Weighted score of good sentences has been calculated for each sentence and the scores of relevance have been ranked. The sentences having highest relevance score than the threshold value set has been included in the summary.
R.S.Prsad proposed a connectionist approach for text summarization. The work discusses the POS disambiguation issues They proposed that that connectionist approach to Text Summarization has a natural way of learning grammatical structures through experience [15].
The most popular method of summarization is the centroid based method is one of the most popular extractive summarization methods. MEAD (http://www.summarization.com/mead/) is an implementation of the centroid based method for either single- or multi-document summarizing. It is based on sentence extraction by clustering. The clusters are made for the related articles. MEAD computes three features centroid score, position, and overlap. Then a linear combination of these three is used to determine the most salient sentences. For the given clusters it computes centroid topic characterizations with the help of tf-idf-type data. The sentence ranking is done by combining sentence scores against centroid, text position value, and tf-idf title/lead overlap.
3. PROPOSED SYNTACTIC APPROACH FOR TEXT SUMMARIZATION
The literature survey shows that most of the times the emphasis is given only on the stastical methods like TF-IDF, SVM, keyword extraction etc. There is only a little light thrown on the use of particular grammar to find the syntactical structure of the sentence. Our idea here is to use the dependency grammar to find out the syntactical structure of the sentence, which may be combined later on with the statistical methods. Dependency Grammar is a kind of linguistic theory. Based on the dependency relation between two words, it constructs the syntactic structure. The basic concept of dependency is based on the idea that the syntactic structure of a sentence consists of binary asymmetrical relations between the words of the sentence [16]. Several researchers have attempted to identify the linguistic text reduction techniques which maintain meaning [17]. These techniques differ significantly and some techniques are much difficult to implement than the others; however, all necessitate a fairly good syntactic analysis of the source text. This technique challenges several existing systems because it involves a wide-coverage grammar, a robust parser, and generation techniques. The dependency grammar constructs syntactic trees. These trees contain nodes which are corresponding to the words of the sentence, and links between nodes are labeled with grammatical relations (of the type “subject”, “direct object”, “subordinate clause”, “noun complement”, etc.). as it recognizes this type of relations it automatically adds some semantical knowledge in the system which uses it. The grammar aims to do a complete syntactic analysis of the sentence. In case of failure that is, due to severe writer error or to limits of the grammar, it provides a series of incomplete analyses of fragments of the sentence. However, determining the salient textual segments is only half of what a summarization system needs to do because, in most cases, the simple catenation of textual segments does not produce lucid outputs [18].
We are using the dependency grammar because of the following properties of DG: 1.DG is based on relationships between words, i.e., dependency relations e.g. A → B means A governs B or B depends on A...
2. Dependency relations can refer to syntactic properties, semantic properties, or a combination of the two some variants of DG separate syntactic and semantic relations by representing different layers of dependency structures.
3. These relations are generally things like subject, object/complement, (pre-/post-) adjunct, etc e.g. Subject/Agent: Dipti worked.
Object/Patient: Shambhavi hit Asit.
Many summarization systems use phase structure grammar (PSG).PSG is based on groupings, or constituents. In that very less stress is given on the relations.
Here we list some of the advantages of dependency grammar 1. Close connection to semantic representation
2. More flexible structure for, e.g., non-constituent coordination 3. Easier to capture some typological regularities
4. Vast & expanding body of computational work on dependency parsing
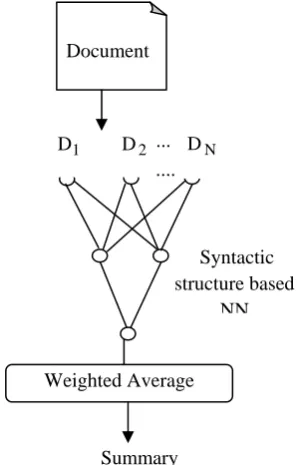
Initially, the input to the approach is a large document that has to be summarized. The document utilized for text summarization is prepared by a set of preprocessing steps namely, sentence segmentation, tokenization, stop words removal and word stemming. The syntactic structure of the extracted sentences is analyzed through the use of dependency grammar that converts the sentences into tokens/words and these tokens/words are connected using the dependency relations. Then another neural network will be trained for normally used features. Those two techniques will be effectively combined with neural network to obtain the final result that is a complete as well as a diminutive form of the input document. In this paper we present our work till the feature extraction using dependency grammar. Figure 1 shows the block diagram of our work done till date.
Figure 1.Block diagram of dependency grammar based summarization.
4.1. Preprocessing
Preprocessing is the initial step involved in the system which is a three stage process consisting of sentence segmentation, removing stop words and, stemming. The output yielded after employment of preprocessing techniques is the individual sentences and their unique IDs which are obtained from the text document.
Segmentation of the input is done by finding out the delimiter commonly denoted by “.”, known as full stop. This results in separating the sentences in the document and will be useful for user to understand each individual sentence which is there in the document.
Stop words are removed from the document at the time of feature extraction step as they are considered as insignificant and include noise. Stop words are predefined words which are stored in an array and the array is made use of when the comparison with the words in the documents is carried out. The document consists of individual words after the process in order to proceed with the word stemming process.
Word stemming transforms every individual word into its root base form. Word stemming basically removes the prefix and suffix of the concerned word to get the base form. This will in turn be used for comparison with other words.
4. SYNTACTIC STRUCTURE EXTRACTION
At first, the segmented sentence is given to the POS tagger for extracting the syntactic structure of the sentence. Every keywords of the sentence is tagged by the POS tagger that is used to extract the syntactic structure of the sentence. The dependency grammar constructs syntactic trees. These trees contain nodes which are corresponding to the words of the sentence, and links between nodes are labeled with grammatical relations
Weighted Average
Syntactic structure based
NN ...
... 1 1 1
1
D D2 DN
(of the type “subject”, “direct object”, “subordinate clause”, “noun complement”, etc.). The grammar aims to do a complete syntactic analysis of the sentence. In case of failure that is, due to severe writer error or to limits of the grammar, it provides a series of incomplete analyses of fragments of the sentence. The theoretical tradition of dependency grammar is combined by the assumption that an important portion of the syntactic structure of sentences exist in binary asymmetrical relations holding between lexical elements. This dependency between the words in a sentence acts as the base for the compaction of the sentence and also maintains the sense of the original document. Also, the use of linguistic analysis for summarization purposes promises an increase in the efficacy.
4.1. Syntactic structure matrix for training of syntactic structure-based neural network
The syntactic structure of the matrix is applied to the neural network to train the syntactic structure of the important sentences. Once the neural network trained with the important structure, the neural network can suggest the importance sentences based on the structures. Here, the syntactic structure matrix is represented as S with the size of
NxK
, in whichN
is the number of sentences in the document andK
1
is the number of unique POS tags identified by the POS tagger. Every element of the matrix is identified by finding the total number of corresponding POS tags presented in the sentence. But, the last vector column is the POS unique id sequence of the corresponding sentence. For finding the POS unique id sequence of a sentence, every POS tag is represented with the unique id and then the sequence of the unique id is generated for the POS sequence.Training phase: The samemulti-layer perceptrons feed forward neural network is also utilized here as learning mechanism, in which the propagation algorithm can be utilized to train neural networks. The back-propagation algorithm can be utilized successfully to train neural networks. Here, the input layer is an individual (syntactic structure vector) obtained from the step and the target output is zero or one that signifies whether its importance or not.
Testing phase: In testing phase, the input text document is preprocessed and the syntactic matrix of input document is computed. The computed syntactic score is applied to the trained network that returns the sentence score of every sentence presented in the input text document.
4.2. Layered neural network
Here, layered neural network structure is designed to train the syntactic structure-based neural network. Without making use of syntactic structure of the sentences, the summary generated will not be concise and understandable manner.
4.3.Combining sentence score
For the input text document, the sentence score obtained from the neural network is combined with the following formulae. Here, weighted average formulae are used to combine the sentence score of both neural networks. The advantage of the weight age formulae is that the different weights can be given to syntactic structure with respect to its importance in text summarization.
S
S
S
*
Where,
S
Sentence score of the input sentence SS
Sentence score obtained by the syntactic structure-based neural network
Weightage constants4.3 Ranking of sentence
100
C
N
SN
Where,
N
S Total number of sentences in the documentC
Compression rate5. RESULTS AND DISCUSSION
This section describes the detailed the experimental results and it and analysis of the document summarization. The proposed syntactic and sentence feature-based hybrid approach is implemented in MATLAB (Matlab7.11) and the experimentation is carried out with i5 processor having 3GM RAM.
5.1 DUC 2002 dataset
For experimentation, we have used DUC 2002 dataset [20] that contains documents on different categories and extractive summary per document.
5.2 Experimental Results
At first, the input document is given to the proposed approach for document summarization. Then, the syntactic feature is computed for every sentence those sample result is given in table 1. Here, the neural network is trained with the sentences available in the DUC 2002 and the corresponding target label is identified with the summary given in DUC 2002 dataset.
Sentenc e ID
Feature score
F1 F2 F3 F4 F5 F6 F7 F8 F9 F10
1 0 8 0 0 3 0 4 616161114 114461 0
2 3 7 0 0 1 1 2 514061011 61011 0
3 5 15 0 0 2 0 5 611146114 111111600 116001601
4 1 6 1 1 2 0 1 246301411 111 0
5 0 2 3 1 4 1 2 661244224 3451 0
6 0 3 0 0 2 0 0 14411 0 0
7 1 5 1 0 5 1 1 244611411 44051 0
8 3 6 2 3 5 0 0 144201114 200413334 1
Table 1.Feature score for the text document (Cluster No. d071f and Document No. AP880310-0062)
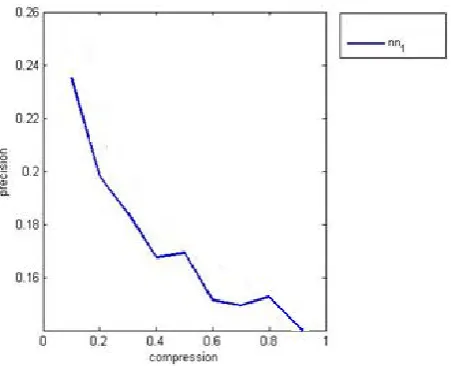
The figure 2 shows the precision measure from the features extracted. Precision measures the ratio of correctness for the sentences in the summary. For precision, the higher the values, the better the system is in excluding irrelevant sentences. The above graph shows that the system has considerable precision ratio. In future we will try to combine it with regular feature extraction techniques and then we will compare the performance. | sentences} {Retrieved | | sentences} {Relevant } sentences {Retrieved | Precision 6. CONCLUSION
As per the literature survey done by us, it was the first attempt of using the dependency grammar for sentence structure extraction for text summarization. Our approach shows the considerable precision measure. To study the cognitive aspect of text summarization we feel that use of dependency grammar is very helpful. In future we will try to use this aspect to improve the performance of text summarization system..
References
[1] Gobinda G. Chowdhury, “Natural Language Processing”, Annual Review of Information Science and Technology, Vol: 37, pp: 51–89, 2003.
[2] E D Liddy, “Natural Language Processing”, In Encyclopedia of Library and Information Science, 2nd Edition, 2001.
[3] Kaustubh Patil and Pavel Brazdil, "Sumgraph: Text Summarization Using Centrality in the Pathfinder Network", In IADIS International Journal on Computer Science and Information Systems, Vol.2, No. 1, pp: 18-32, 2007.
[4] Liang Zhou, Miruna Ticrea and Eduard Hovy, "Multi-document Biography Summarization", in Proceedings of Empirical Methods in Natural Language Processing, 2004.
[5] Shiyan Ou, Christopher S.G. Khoo and Dion H. Goh, "Design and development of a concept-based multidocument summarization system for research abstracts", Journal of Information Science, vol. 34 , no. 3, pp. 308-326 , June 2008.
[6] You Ouyang, Wenji Li and Qin Lu, "An Integrated Multi-document Summarization Approach based on Word Hierarchical Representation", in proceedings of the ACL-IJCNLP, singapore, pp. 109–112, 2009.
[7] Mohammed Salem Binwahlan, Naomie Salim and Ladda Suanmali, "Swarm Based Features Selection for Text Summarization", IJCSNS International Journal of Computer Science and Network Security, vol. 9, no.1, January 2009.
[8] Yan Liu, Sheng-hua Zhong, Wen-jie Li, "Query-oriented Unsupervised Multi-document Summarization via Deep Learning", Under review in Journal of Neural Networks (NN).
[9] Shasha Xie, Yang Liu, “Improving supervised learning for meeting summarization using sampling and regression”, In Computer Speech and Language, Vol: 24, Issue 3, 2009.
[10] Allan Borra, Almira Mae Diola, Joan Tiffany T. Ong Lopez, Phoebus Ferdiel Torralba, Sherwin So, “Using Rhetorical Structure Theory in Automatic Text Summarization for Marcu-Authored Documents”, In titaniaaddueduph, 2010.
[11] Rafeeq Al-Hashemi, “Text Summarization Extraction System (TSES)Using Extracted Keywords”, International Arab Journal of e-Technology, Vol. 1, No. 4, pp: 164-168, 2010.
[12] Ju-Hong Lee, Sun Park, Chan-Min Ahn, Daeho Kim, “Automatic generic document summarization based on non-negative matrix factorization”, In Information Processing and Management, Vol: 45, No. 1, pp: 20–34, 2008.
[13] Nadira Begum, Mohamed Abdel Fattah, Fuji Ren, “Automatic text summarization using support vector machine”, International Journal of Innovative Computing, Volume 5, pp: 1987-1996, 2009.
[14] Farshad Kyoomarsi, Hamid Khosravi, Esfandiar Eslami, Pooya Khosravyan, “Optimizing Machine Learning Approach Based on Fuzzy Logic in Text Summarization”,International Journal of Hybrid Information Technology, Vol.2, 2009.
[15] Rajesh Shardanand Prasad, Uday Kulkarni’Implementation and Evaluation of Evolutionary Connectionist Approaches to Automated Text Summarization’ Journal of Computer Science 6(11):, 2010 ISSN 1549-3636 © 2010 Science Publications, pp1366-1376. [16] Joakim Nivre, “Dependency Grammar and Dependency Parsing”, In MSI report 05133, 2005.
[17] Michel Gagnon, Lyne Da Sylva, “Text Summarization by Sentence Extraction and Syntactic Pruning”, In Proceedings of Computational Linguistics in the North East, 2005.
[18] Kevin Knight, Daniel Marcu, “Summarization beyond sentence extraction:A probabilistic approach to sentence compression”, In Artificial Intelligence, Vol: 139, Issue 1, pp: 91–107, 2002.
[19] H Jing, K McKeown, “The decomposition of human-written summary sentences”, In 22nd International Conference on Research and Development in Information
Retrieval, pp: 129-136, 1999.
[20] DUC 2002 dataset from “http://www-nlpir.nist.gov/projects/duc/”.
Biographical sketches
1.Dipti Y Sakhare is research scholar at Bharati Veedyapeeth,DeemedUniversity,Pune, Maharashtra,India. She is currently working as Assistant Professor in Department of Electronics Engineering at MIT Pune’s MAE,Alandi,Pune.She has total Eight years of teaching experience. Her teaching areas are: Digital systems,information retrival,VLSI Design