ISBN: 978-1-60595-626-8
Review Extract Using Word Embeddings
Zhen SHAO and Wei-bin GUO
*East China University of Science and Technology Shanghai, China
*Corresponding author
Keywords: Word2vec, PageRank, Review extract.
Abstract. Online reviews become the basis of evaluating alternatives before making purchase decision. So extracting useful information from a large number of reviews becomes a valuable act. Recently word embeddings methods have been widely used in binary sentiment classification tasks and perform well. They judge a review is negative or positive, but ignores the product characteristics of the reviews expression. It’s difficult to get valuable information from huge number of reviews. In this paper, we propose a method to get the core reviews from review collection. This methodology applies a combined approach of word embedding (word2vec) and PageRank named WVP to calculate the impact factor of a review. We training the model through an open source hotel review data. The methodology is applied to the data sets of hotel reviews was crawled from DianPing which a famous company on tourism. Experiment show that WVP is effective to get core reviews.
Introduction
With the rapid development of e-commerce, a large amount of reviews data has been generated. As a reported in Ref [1] 68% of customers would check at least four reviews and almost 25% of them would check at least eight reviews before buying. The reviews on any product help not only the customer to buy best product availables online but also help seller improve product experience. So it’s necessary to get core information from reviews quickly.
Many machine learning methods were applied to binary sentiment classification tasks. Both support vector machine (SVM) and artificial neural network (ANN) algorithms are used in combination for document-level sentiment classification from reviews [2]. Mario propose a deep-learning-based approach which based on convolutional neural network (CNN) and word2vec to judge the polarity of reviews [3] and Zhang, ZB adopt VC-Word2vec (Voting Based on Clustering Word2vec) to identify the aspects of online reviews [4] . Yuan Li use TextRank algorithm to extract multiple document summary, and feedback the summary to the experts [9], Onan use keyword-based representation of text documents to improve performance of text classification [10] and get the summary of the document [11]. TextRank perform well in document, but ignore the semantics of reviews and can't solve the sparseness of review. Sangho Ahn analyze online customer reviews to find the success factors of games by word2vec [8]. Some work have been done based on PageRank. Fiala predict the importance of citations[13] and Zhang, Fuli rank journal by HR-PageRank which combines weighted PageRank according to author’s H-index [14].In this paper, we propose a method for ranking of review. Different from mathematical statistics, we conduct the characterization of reviews based on natural language processing (NLP) terms. A widely used word2vec model is employed to transform the review to high-dimensional vectors [12]. The similarity between reviews depend on the distance between corresponding points in the low-dimensional space. The distance will influence the weight of side for PageRank model. We rank reviews by iterative graph calculation.
Materials and Related Work
Materials
In our experiments, we obtained the training datasets from online, which was manually organized and labeled. It contains 150,000 reviews comes from Ctrip users’ real review data on the hotel including negative and positive. We crawled hotel reviews from DianPing to evaluate our experimental efficiency.
Word Embedding Technique
Word embedding is a distributed representation for words in a vector space [5].It has become a popular tool in the field of NLP. It transform words into vectors, and we can evaluate the correlation between two words by calculating the distance between vectors. Word embedding contains two language models which Skip-gram and CBOW [6]. Skip-Gram is given input word to predict the context. And CBOW is the given context to predict the input word [7].
[image:2.595.225.369.304.487.2]The training is done through a neural network which consists of three layers, input, hidden, and output. Figure 1 shows the CBOW model. The training input of the CBOW model is the word vector corresponding to the context-dependent word of a certain feature word, and the output is the word vector of the specific word.
Figure 1. CBOW model Source [6].
PageRank Technique
PageRank is an algorithm proposed by Google, whose main purpose is to sort by analyzing the importance of web pages [15]. First initialize the probability distribution, generally evenly distributed. As show in Eq.1, where N is the total number of pages, and 𝑝𝑖; 0 is page i at time 0, PR is the value of page.
PR(𝑝𝑖; 0) =𝑁1 (1) Then iterate through the following algorithm until it reaches a smooth distribution. Where
𝑝1, 𝑝2, ⋯ , 𝑝𝑁 are the pages under consideration, M(𝑝𝑖) is the set of pages that link to 𝑝𝑖, L(𝑝𝑖) is
the number of outbound links on page 𝑝𝑗, 𝑁 is the total number of pages and 𝑑 is usually set to 0.85.
PR(𝑝𝑖) =1−𝑑𝑁 + 𝑑 ∑ 𝑃𝑅(𝑝𝑗)
𝐿(𝑝𝑗)
𝑝𝑗∈𝑀(𝑝𝑖) (2) Calculationprobability for each page at a time point, then repeated for the next time point. If the difference between two numbers is less than a small value ε, the iteration is terminated.
This part, we present our proposed method to get core information from reviews. It consist two parts. Sec 3.1 calculate the distance between two sentences, Sec 3.2 rank the reviews.
Distance of a Sentence
You need to preprocess the corpus before using it, remove stop words, invalid numbers, invalid punctuation, etc. Then divide the sentences into words. In this paper we use CBOW model to train. Each time a word is initialized to a vector of the same dimension, it converges to a stable vector through iterative training. After the training, we will get a vector table.
We crawled reviews from DianPing, removing stop words and punctuation. Then store it in units of sentences. Get the vector of each sentence by the vector table obtained from the vector table. For example, one review “The bed is very comfortable”. We use the model to calculate the vector of the vocabulary in the sentence and obtain the document vector of the sentence through algebraic operations. For example, bed represented as (𝑎1, 𝑎2, 𝑎3⋯ , 𝑎𝑛), comfortable represented as
(𝑏1, 𝑏2, 𝑏3⋯ , 𝑏𝑛) , 𝑛 is the dimension of the vector in our model. The vector corresponding to this sentence is (𝑎1+ 𝑏1, 𝑎2+ 𝑏2, 𝑎3+ 𝑏3⋯ , 𝑎𝑛+ 𝑏𝑛).
According to the above method, we can get the vector expression of each review. Next we can evaluate the distance between two sentences by calculating the inner product between the two vectors.
Review A:(𝐴1, 𝐴2, 𝐴3⋯ 𝐴𝑛); Review B:(𝐵1, 𝐵2, 𝐵3⋯ , 𝐵𝑛), which SenDis is the distance between two sentences.
SenDis = 𝐴⃗ ∙ 𝐵⃗⃗ = ∑𝑛 𝐴𝑖∗ 𝐵𝑖
𝑖=1 (4)
Through the Eq.4 we calculate the distance between the reviews as the parameters of the next stage.
Rank the Reviews
[image:3.595.223.376.514.635.2]In Section 3.1 we have got the distance between the sentences. Dis(AB) is distance between review A and review B. As shown in Figure 2, in this condition, the calculation method of SecA shown in Eq. 5, we set d = 0.85.
Figure 2. Distance of Sentence.
PR(SecA) = (1 − d) + d ∗ (Dis(AB) ∗RR(SecB)2 + Dis(AD) ∗ PR(SecD)) (5) After 10 iterations, we get the RP value of each review, and extract the core reviews after sorting.
Experiment
Evaluation Criteria
The reviews data for experiments have been tagged and classified. As shown in Table 1, the experimental data is labeled as 10 categories. The proportion of the number of reviews under the category which the review belongs to the total number of reviews as the impact factor of the review. Evaluation criteria is to get the top 10 reviews through WVP and TextRank, the sum of the influence factors of the ten reviews is 𝐼𝑚𝑝𝐴. 𝐼𝑚𝑝𝐵 is the impact factors of largest category. The largest category is Label_1, 𝐼𝑚𝑝𝐵 is 0.3583. Finally, 𝐼𝑚𝑝𝐴𝐼𝑚𝑝𝐵 as the final result.
Table 1. Review Data For Experiments.
Dataset Label Name Review Number Total Number
D19113275
Label_1 1452
4053 Label_2 579
Label_3 318 Label_4 204 Label_5 201 Label_6 114
Label_7 21
Label_8 588 Label_9 354 Label_10 222
Experimental Results and Analysis
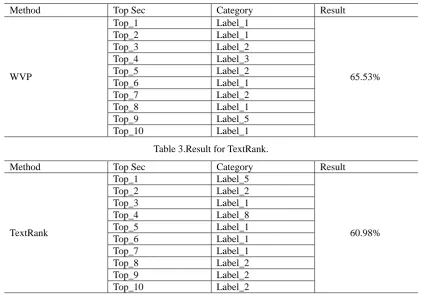
We extract the core reviews by WVP and PageRank, then organize the results of the experiment. As shown in Table 2, Top Sec is the rank of reviews, Category is the category which the review belongs. Table 2 is the result of WVP and Table 3 of TextRank.
Table 2. Result for WVP.
Method Top Sec Category Result
WVP
Top_1 Label_1
65.53% Top_2 Label_1
[image:4.595.86.508.436.730.2]Top_3 Label_2 Top_4 Label_3 Top_5 Label_2 Top_6 Label_1 Top_7 Label_2 Top_8 Label_1 Top_9 Label_5 Top_10 Label_1
Table 3.Result for TextRank.
Method Top Sec Category Result
TextRank
Top_1 Label_5
60.98% Top_2 Label_2
Top_3 Label_1 Top_4 Label_8 Top_5 Label_1 Top_6 Label_1 Top_7 Label_1 Top_8 Label_2 Top_9 Label_2 Top_10 Label_2
In this paper, we use the WVP (Word2Vec and PageRank) method to extract the core reviews. We use the word2vec training model to get the word vector table. Use the word vector table to calculate the document vector of the review. Iterate by using the distance between the vectors as the edge weight of PageRank. Settlement, and finally get the ranking information of the reviews. We conducted experimental comparisons of methods WVP and TextRank. The experimental results show that WVP is an effective method for review extraction. For future work, we plan to cluster reviews by word embeddings and combine some sentiment analysis methods to build product features.
Acknowledgement
We are thankful to all team members for their support and assistance on empirical studies, the handling editor and reviewers for their thoughtful and expert comments.
References
[1] Sun M. How Does the Variance of Product Ratings Matter?[J]. Management Science, 2012, 58(4):696-707.
[2] Tripathy A, Anand A, Rath S K. Document-level sentiment classification using hybrid machine learning approach[J]. Knowledge and Information Systems, 2017, 53(3):805-831.
[3] Paredes-Valverde Mario Andrés, Ricardo C P, Salas-Zárate María del Pilar, et al. Sentiment Analysis in Spanish for Improvement of Products and Services: A Deep Learning Approach[J]. Scientific Programming, 2017, 2017:1-6.
[4] Zhang Z B, Li H, Yu W D, et al. Fine-grained Opinion Mining: An Application of Online Review Analysis in the Express Industry [M]. 2017.
[5] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26:3111-3119.
[6] Rong X, 2014, “word2vec Parameter Learning Explained,” e-print arXiv: 1411. 2738
[7] Altszyler E, Ribeiro S, Sigman M, et al. The interpretation of dream meaning: Resolving ambiguity using Latent Semantic Analysis in a small corpus of text[J]. Consciousness and Cognition, 2017:S1053810017301034.
[8] Sangho A, Juyoung K, Sangun P. What makes the difference between popular games and unpopular games? Analysis of online game reviews from steam platform using Word2vec and bass model [J]. ICIC Express Letters, 2017, 11(12): 1729-1737.
[9] Xiong C, Li Y, Lv K . Multi-documents Summarization Based on the TextRank and Its Application in Argumentation System[J]. 2017.
[10] Aytuğ Onan, Serdar Korukoğlu, Bulut H. Ensemble of keyword extraction methods and classifiers in text classification[M]. Pergamon Press, Inc. 2016.
[11] Xiong C, Li Y, Lv K. Multi-documents Summarization Based on the TextRank and Its Application in Argumentation System[J]. 2017.
[13] Fiala D, Tutoky G. PageRank-based prediction of award-winning researchers and the impact of citations[J]. Journal of Informetrics, 2018, 11(4):1044-1068.
[14] Zhang, Fuli. Evaluating journal impact based on weighted citations[J]. Scientometrics, 2017.
![Figure 1. CBOW model Source [6].](https://thumb-us.123doks.com/thumbv2/123dok_us/249134.1024822/2.595.225.369.304.487/figure-cbow-model-source.webp)