International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
632
An Iterative Probabilistic Approach Towards Data
Anonymization
J. Jesmitha
1, R. Ranjana
21
PG Student, M.E Computer and Communication, Sri Sairam Engineering College, Chennai-44.
2Assistant Professor, Department of IT, Sri Sairam Engineering College, Chennai-44.
Abstract— Data mining is the process by which useful knowledge is discovered from database. Publishing various databases for research and analytic purposes may put individual privacy at risk especially if it is possible to uniquely identify the personal details of an individual. Such risks have increased considerably in today’s technology-driven world. To overcome such risks and ensure privacy, various anonymization techniques were developed. The objective of my project is to develop a system which safeguards and enhances the privacy of people while still allowing data miners to discover useful information. Thus the privacy as well as utility of the database is balanced efficiently using iterative probabilistic approach towards data anonymization. Once the quasi fields are identified, an iterative anonymization technique is applied based on the probability of quasi fields. For case study, I have taken the judicial system wherein the details of clients have to be published for research and survey purposes. This method ensures both knowledge preservation and privacy preservation of judicial database.
Keywords— Anonymization, Quasi Identifier, Probabilistic Anonymity, Iterative Anonymization.
I. INTRODUCTION
The objective of the project is to design a system which enhances the preservation of users’ privacy when databases are published. A recent study reveals approximately 87% of the population of the United States can be uniquely identified on the basis of Gender, Date of Birth, and 5-digit Zip code. This revelation has questioned the privacy of people when databases are published but it is a must that medical and other databases be published for research and survey purposes. So this paper attempts to achieve an efficient balance between utility and privacy of data. In legal field, data must be published for survey purposes to find out the frequency of accidents at a particular location, to find out the major causes of crimes in a country and to find the effect of age, gender, occupation and location on criminal activities. The privacy of individuals is a must in this case. The Iterative anonymization method which
provides both privacy protection and knowledge
preservation is explained here. We anonymize data to protect and enhance privacy; at the same time miners should discover useful knowledge from anonymized data.
II. RELATED WORKS
Method [2] is a novel approach towards sharing patient-specific longitudinal data offering privacy and data utility based on alignment and clustering. It addresses the problem of re-identification in longitudinal data publishing and grouping of records to achieve high data utility. It does not limit the information loss incurred by generalization and suppression and released data is not guided by specific utility. The method [3] relaxes indistinguishability requirement and the probability of re-identification is same
as k-anonymity. Information loss is reduced considerably
and data quality preservation Privacy is same as k-anonymity so attribute disclosure is possible. In [5], the real meaning of sensitive attributes is taken to avoid background knowledge attack. A restriction is placed on the maximum number of dissimilar values to be present in a block of sensitive attributes. This makes it easy to implement when the diversity of sensitive attributes is less. In this method privacy has received more attention than utility.
In [6], a novel and powerful privacy criterion called l
-diversity that can defend against such attacks is explained. Sensitive attributes are made l-diverse so that there is at least l different value thus preventing homogeneity attack. It is practical to implement and handles multiple sensitive attributes. The privacy and utility are duals of each other; privacy has been given importance than the utility of a published table. As a result, the concept of utility is not well understood. Therefore knowledge discoverers cannot use the data for inferring useful knowledge from them. To preserve the identity of individuals [9] makes a record similar to k-1 other records. This is achieved by releasing
records that adhere to k anonymity, which means each
released record has at least k-1 other records indistinct from
each other. The Preferred Minimal Generalization Algorithm (MinGen) which combines generalization and
suppression techniques to provide k-anonymity is used.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
633
III. PROPOSED SYSTEM
From the literature survey, it is clear that there are several drawbacks in the system. To overcome most of the problems in existing systems, we propose a method which iteratively anonymizes data by randomly breaking links among attribute values in record. This is based on probabilistic determination of attributes and threshold probabilistic determination. In this method, the privacy of the individual as well as the knowledge is preserved. An enhanced algorithm is proposed to tackle situation where user’s prior knowledge may cause privacy leakage. The anonymization is done in such a way that the utility of the data published is preserved.
Probabilistic anonymity: Let a data set D be anonymized to
D0. Let r be a record in D and r0 belong to D0 be its
anonymized form. Denote r(QI) as the value combination of the quasi-identifier in r. The probabilistic anonymity of
data set D0 is defined by 1/P(r(QI)/ r0 (QI)), where P(r(QI)/
r0 (QI)) is the probability that r(QI) (for all r belongs to D)
may be inferred given r0(QI).The probabilistic anonymity
gives a measurement of how unlikely the user can infer original associations. The greater the probabilistic anonymity, the less probable the user can guess the original data.
Quasi identifier:Given a data set D(A1, A2; . . . , Am) and
an external table DE. For all records ri belongs to D, if the
value combination ri(Aj, . . . ,Ak), j, k < m,{ Aj, . . . ,Ak}
contains no identifiers, can be uniquely located in DE, we
call the set of attributes {Aj, . . . ,Ak} as quasi-identifier.
For example, in the data set the external table DE would
consist of Name, Age, Job, and Country and a quasi-identifier would be {Age, Job, Country}.
Threshold probability: Depending upon the number of quasi fields (n), number of threshold probabilities is
determined: P1, P2, Pn. For a QI, the probability must be
above the threshold probability for the data to be anonymous.
Iterative anonymization: The n quasi identifiers are anonymized for probability values less than threshold
probability P1.then (n-1) quasi fields are anonymized for
values less than P2 leaving the weaker QI among n.
Similarly it is repeated for (n-2), (n-3)….1. Thus for the last iteration involving the strongest QI, anonymization is
done for values with probability less than Pn.
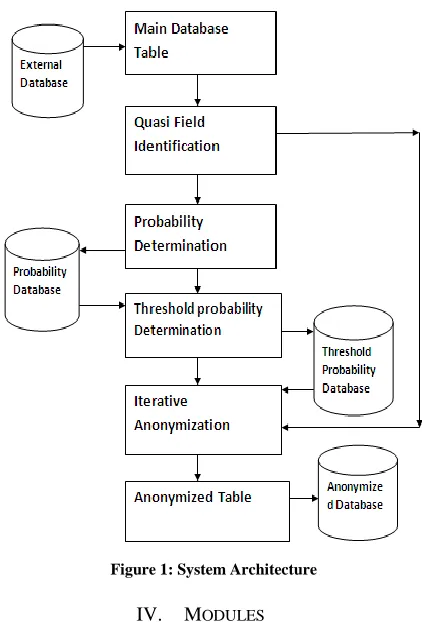
3.1 System Architechture
[image:2.612.337.548.203.514.2]The System architecture diagram provides a top-down description of the structure of the system. The diagram (Fig: 1) shown below describes the architecture of the system developed.
Figure 1: System Architecture
IV. MODULES
A module is a self-contained component of a system which has a well-defined interface to other components of the system.
4.1 QUASI Field Identification
From the information provided by client, the fields which act as quasi are identified. Combination of two or more field may reveal the sensitive data; those combinations of fields are called quasi identifiers. They are the combination of identity-leaking attributes. Attributes acting as strong quasi identifiers are identified.
In the first test set we will take Gender, Date of Birth
and Zip code
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
634
The number of distinct values of column Date of Birth (C2) is d2=60*365=2*(10^4)
The number of distinct values for Zip code (C3) is d3=10^5
D=d1*d2*d3
=2*(2*(10^4))*10^5
=4*(10^9)
In the second test set we will take Occupation, Date of
Birth and Zip code
The number of distinct value for Occupation (C1) is roughly d1=100
The number of distinct values of column Date of Birth (C2) is d2=60*365=2*(10^4)
The number of distinct values for Zip code (C3) is d3=10^5
D=d1*d2*d3
=100*(2*(10^4))*10^5
=4*(50(10^9))
Table 1 Quasi Identifiers
Date Of Birth Job Pin code
05/05/1975 Teacher 600040
08/05/1989 Engineer 600030
05/05/1975 Teacher 600040
05/04/1989 Teacher 600116
08/07/1982 Vendor 566857
Table 1 contains a sample of quasi identifiers Date of Birth, Job, Pin code and their corresponding values.
4.2 Probability Determination
From Quasi identification module, we find the fields: Date of Birth, Zip code and Occupation act as strong quasi identifiers. Then we find the probability of each field identified.
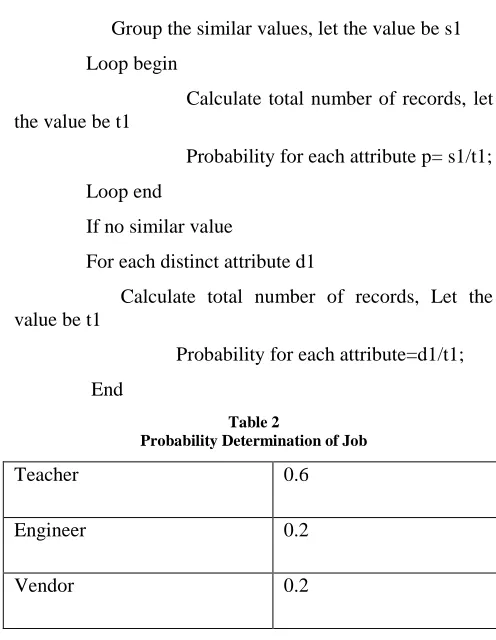
Algorithm
For each column do
Group the similar values, let the value be s1
Loop begin
Calculate total number of records, let the value be t1
Probability for each attribute p= s1/t1;
Loop end
If no similar value
For each distinct attribute d1
Calculate total number of records, Let the value be t1
Probability for each attribute=d1/t1;
[image:3.612.317.565.162.482.2]End
Table 2
Probability Determination of Job
Teacher 0.6
Engineer 0.2
Vendor 0.2
Table 2 contains the probability value of quasi identifier job. Similarly probability value is calculated for all quasi fields.
4.3 Threshold Probability Determination
After finding the probabilistic distribution, threshold probabilities must be determined for a given database. The total number of threshold probabilities is equal to the total number of quasi fields chosen.
Algorithm
Step1: Count the number of quasi identifiers in the given database. Let it b equal to n.
Step 2: The number of threshold probabilities= n and let the
threshold probabilities be P1, P2, P3… Pn.
Step 3: Let minimum probability be MinProb=0;
Let maximum probability be MaxProb=1;
Step 4: Calculate the threshold probability P1 as follows:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
635
Step 5: Calculate the threshold probability P2 as follows:
P2= [P1 + MaxProb]/2
Step 6: Similarly calculate the threshold probability Pn as
follows:
Pn= [Pn-1+ MaxProb]/2
Thus threshold probabilities are determined by the above algorithm. Now anonymization is done only for certain values of QI based on the iterative approach.
4.4 Anonymization
Only certain values of fields selected as quasi identifiers
are anonymized based on iterative approach.
anonymization of values should be done in such a way miners can discover useful knowledge from the data. So permuting the data or removing the values does not hold good. The data should be given to the miners as well the individual’s identity should be preserved. So we anonymize values depending on threshold probability values. The attributes with probability less than threshold probability should be anonymized, other values can be presented as such. The principle used here is, if an attribute has high probability of occurrence, the attribute cannot be used to identify an individual among the crowd because of the large search space. On the other hand if an attribute occur as singleton or if it has lesser probability, the value should be anonymized otherwise it may cause privacy leakage.
[image:4.612.61.274.575.729.2]Generalization and Suppression are applied for achieving anonymization. For example in a certain data set of 1000 records, if there are 50 teachers in quasi field occupation, the value can be left as it is because the search space is large. It is difficult to locate a single doctor. On the other hand in the same data set if there is 1 chartered account the individual can be easily identified by using other unanonymized values.
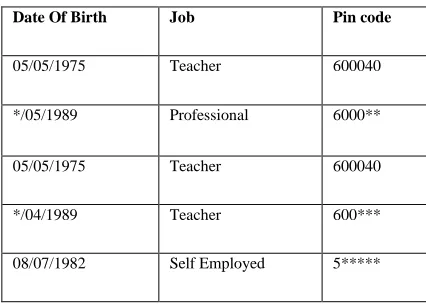
Table 3:
Anonymized Table after Iteration 1
Date Of Birth Job Pin code
05/05/1975 Teacher 600040
*/05/1989 Professional 6000**
05/05/1975 Teacher 600040
*/04/1989 Teacher 600***
08/07/1982 Self Employed 5*****
Table 3 contains the anonymized value of quasi identifier. The Anonymization is done based on the above algorithm. In date of birth with lesser probability, date is replaced by a *, which increases the search space. For Job specific values are replaced by more generic value. For example engineer having less probability is replaced by Professional. In Pin code 600030, if 30 is discarded it has higher probability. Pin code 566857 being a unique number all the digits following 5 should be replaced.
4.5 Iterative Anonymization
Anonymization process is done repetitively depending on the number of threshold probabilities based on the algorithm given below.
Algorithm
Step 1: Iteration 1
Anonymize all the n number of QI whose values have probability < P1.
Step 2: Iteration 2
Eliminate one of the weakest quasi identifiers and anonymize the rest (n-1) QI whose values have probability < P2.
Step 3: Iteration n
Similarly the iterations are continued till n becomes equal to 1. Anonymize the final strongest QI whose values have
probability< Pn. Thus iterative approach increases the
privacy factor than when just one time anonymization was done.
V. RESULTS AND DISCUSSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
[image:5.612.69.272.129.665.2]636
Figure 2: Main Table
Figure 3: Quasi Field Identification
Figure 4: Table after Iterative anonymization
In this method even if the data is published, privacy breach does not occur because the data is published only after anonymizing using the algorithm. In this project, a novel data anonymization method called Iterative anonymization is introduced. Different from the methods such as the k-anonymization methods, the data privacy is regarded as the links between the QI and sensitive values. Thus data anonymization is a popular direction in the research of privacy-preserving data mining.
REFERENCES
[1] Jesmitha.J and Seethalakshmi.R, “Privacy preservation of confidential database using anonymization”, International Journal of Emerging Technology and Advanced Engineering, January 2013. [2] Acar Tamersoy, Grigorios Loukides, Mehmet Ercan Nergiz, Yucel
Saygin, and Bradley Malin, “Anonymization of Longitudinal Electronic Medical Records”, IEEE transactions on information technology in biomedicine, may 2012.
[3] Jordi Soria-Comas and Josep Domingo Ferrer, “Probabilistic k-anonymity through micro-aggregation and data swapping”, Fuzzy Systems (FUZZ-IEEE), 2012 IEEE International Conference on computational intelligence, 2012.
[4] Weijia Yang, Sanzheng Qiao, “A novel anonymization algorithm: Privacy protection and knowledge preservation”, expert systems with applications, 2010.
[image:5.612.343.543.133.371.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 10, October 2013)
637
[6] Ashwin Machaavajjhalal, Daniel Kifer ,”l-Diversity: Privacy Beyond k-Anonymity”, ACM Transactions on Knowledge Discovery from Data, 2007.
[7] B.C.M.Fung, K.Wang, and P.S. Yu, “Top-Down Specialization for Information and Privacy Preservation,” Proc. 21st International Conference on Data Eng, 2005.
[8] K. Wang, P. Yu, and S.Chakraborty, “Bottom-Up Generalization: A Data Mining Solution to Privacy Protection,” Proc. Fourth IEEE International Conference on Data Mining, 2004.