R E S E A R C H
Open Access
Strong consistency of estimators in partially linear
models for longitudinal data with
mixing-dependent structure
Xing-cai Zhou
1,2and Jin-guan Lin
1** Correspondence: [email protected]
1
Department of Mathematics, Southeast University, Nanjing 210096, People’s Republic of China Full list of author information is available at the end of the article
Abstract
For exhibiting dependence among the observations within the same subject, the paper considers the estimation problems of partially linear models for longitudinal data with the-mixing andr-mixing error structures, respectively. The strong consistency for least squares estimator of parametric component is studied. In addition, the strong consistency and uniform consistency for the estimator of nonparametric function are investigated under some mild conditions.
Keywords:partially linear model, longitudinal data, mixing dependent, strong consistency
1 Introduction
Longitudinal data (Diggle et al. [1]) are characterized by repeated observations over time on the same set of individuals. They are common in medical and epidemiological studies. Examples of such data can be easily found in clinical trials and follow-up studies for monitoring disease progression. Interest of the study is often focused on evaluating the effects of time and covariates on the outcome variables. Let tijbe the time of the jth measurement of theith subject, xij Î Rpand yij be theith subject’s observed covariate and outcome at timetijrespectively. We assume that the full data-set {(xij,yij,tij),i = 1,...,n, j= 1,...,mi}, wherenis the number of subjects andmiis the
number of repeated measurements of theith subject, is observed and can be modeled
as the following partially linear models
yij=xTijβ+g(tij) +eij, (1:1)
where bis ap ×1 vector of unknown parameter, g(⋅) is an unknown smooth func-tion,eijare random errors withE(eij) = 0. We assume without loss of generality thattij are all scaled into the intervalI= [0, 1]. Although the observations, and therefore the
eij, from the different subjects are independent, they can be dependent within each subject.
Partially linear models keep the flexibility of nonparametric models, while maintain-ing the explanatory power of parametric models (Fan and Li [2]). Many authors have studied the models in the form of (1.1) under some additional assumptions or restric-tions. If the nonparametric component g(⋅) is known or not present in the models,
they become the general linear models with repeated measurements, which were studied under Gaussian errors in a amount of literature. Some works have been inte-grated into PROC MIXED of the SAS Systems for estimation and inference for such models. Ifg(⋅) is unknown but there are no repeated measurements, that ism1 =⋅ ⋅ ⋅=
mn= 1, the models (1.1) are reduced to non-longitudinal partially linear regression models, which were firstly introduced by Engle et al. [3] to study the effect of weather on electricity demand, and further studied by Heckman [4], Speckman [5] and Robin-son [6], among others. A recent survey of the estimation and application of the models can be found in the monograph of Häardle et al. [7]. When the random errors of the models (1.1) are independent replicates of a zero mean stationary Gaussian process, Zeger and Diggle [8] obtained estimators of the unknown quantities and analyzed time-trend CD4 cell numbers among HIV sero-converters; Moyeed and Diggle [9] gave the rate of convergence for such estimators; Zhang et al. [10] proposed the maximum penalized Gaussian likelihood estimator. Introducing the counting process technique to the estimation scheme, Fan and Li [2] established asymptotic normality and rate of convergence of the resulting estimators. Under the models (1.1) for panel data with a one-way error structure, You and Zhou [11] and You et al. [12] developed the weighted semiparametric least square estimator and derived asymptotic properties of the estimators. In practice, a great deal of the data in econometrics, engineering and natural sciences occur in the form of time series in which observations are not inde-pendent and often exhibit evident dependence. Recently, the non-longitudinal partially linear regression models with complex error structure have attracted increasing atten-tion by statisticians. For example, see Schick [13] with AR(1) errors, Gao and Anh [14] with long-memory errors, Sun et al. [15] withMA(∞) errors, Baek and Liang [16] and Zhou et al. [17] with negatively associated (NA) errors, and Li and Liu [18], Chen and Cui [19] and Liang and Jing [20] with martingale difference sequence, among others.
For longitudinal data, an inherent characteristic is the dependence among the obser-vations within the same subject. Some authors have not considered the with-subject dependence to study the asymptotic behaviors of estimation in the semipara-metric models with assumption that themi are all bounded, see, for example, He et al. [21], Xue and Zhu [22] and the references therein. Li et al. [23] and Bai et al. [24] showed that ignoring the data dependence within each subject causes a loss of efficiency of sta-tistical inference on the parameters of interest. Hu et al. [25] and Wang et al. [26] took into consideration within-subject correlations for analyzing longitudinal data and
obtained some asymptotic results based on the assumption that max1≤i≤n mi is
bounded for all n. Chi and Reinsel [27] considered linear models for longitudinal data that contain both individual random effects components and with-individual errors that follow an (autoregressive) AR(1) time series process and gave some estimation procedures, but they did not investigate asymptotic properties of estimations. In fact, the observed responses within the same subject are correlated and may be represented by a sequence of responses {yij,j≥1} for thei-individual with an intrinsic dependence structure, such as mixing conditions. For example, in hydrology, many measures may be represented by a sequence of responses {yij,j ≥1} for the ith year at tij, where tij represents the time elapsed from the beginning of the ith year, and{eij,j≥1} are the measurements of the deviation from the mean{xT
ijβ+g(tij),j≥1}. It is not reasonable
such as mixing-dependent structure. In this paper, we consider the estimation
problems for the models (1.1) with the -mixing and r-mixing error structures for
exhibiting dependence among the observations within the same subject respectively and are mainly devoted to strong consistency of estimators.
Let {Xm, m ≥ 1} be a sequence of random variables defined on probability space
(,F,P),Fl
k=σ(Xi,k≤i≤l)be s-algebra generated by Xk, . . ., Xl, and denote
L2(Fl
k)be the set of allFklmeasurable random variables with second moments. A sequence of random variables {Xm,m≥1} is called to be-mixing if
ϕ(m) = sup k≥1,A∈Fk
1,P(A)=0,B∈Fk∞+m
|P(B|A)−P(B)| →0, asm→ ∞.
A sequence of random variables {Xm,m≥1} is called to ber-mixing if maximal correla-tion coefficient
ρ(m) = sup k≥1,X∈L2(Fk
1),Y∈L2(Fk∞+m)
|cov (X,Y)|
Var(X)·Var(Y) →0, asm→ ∞.
The concept of mixing sequence is central in many areas of economics, finance and other sciences. A mixing time series can be viewed as a sequence of random variables for which the past and distant future are asymptotically independent. A number of
limit theorems for -mixing and r-mixing random variables have been studied by
many authors. For example, see Shao [28], Peligrad [29], Utev [30], Kiesel [31], Chen et al. [32] and Zhou [33] for-mixing; Peligrad [34], Peligrad and Shao [35,36], Shao
[37] and Bradley [38] for r-mixing. Some limit theories can be found in the
mono-graph of Lin and Lu [39]. Recently, the mixing-dependent error structure has also been used to study the nonparametric and semiparametric regression models, for instance, Roussas [40], Truong [41], Fraiman and Iribarren [42], Roussas and Tran [43], Masry and Fan [44], Aneiros and Quintela [45], and Fan and Yao [46].
The rest of this paper is organized as follows. In Section 2, we give least square esti-mator (LSE) βˆnof bbased on the nonparametric estimator ofg(·) under the mixing-dependent error structure and state some main results. Section 3 is devoted to sketches of several technical lemmas and corollaries. The proofs of main results are given in Section 4. We close with concluding remarks in the last section.
2 Estimators and main results
For models (1.1), ifbis known to be the true parameter, then byEeij= 0, we have
g(tij) =E(yij−xTijβ), 1≤i≤n, 1≤j≤mi.
Hence, a natural nonparametric estimator ofg(·) givenbis
g∗n(t,β) = n
i=1 mi
j=1
Wnij(t)(yij−xTijβ), (2:1)
whereWnij(t) =Wnij(t,t11,t12,. . .,tnmn)is the weight function defined on I. Now, in order to estimateb, we minimize
SS(β) = n
i=1 mi
j=1
yij−xTijβ−g∗n(tij,β) 2
The minimizer to the above equation is found to be
ˆ
βn= ⎛ ⎝n
i=1 mi
j=1 ˜ xijx˜Tij
⎞ ⎠
−1 n
i=1 mi
j=1 ˜
xij˜yij, (2:2)
wherex˜ij=xij−nk=1 mi
l=1Wnkl(tij)xklandy˜ij=yij− n
k=1 mi
l=1Wnkl(tij)ykl. So, a plug-in estimator of the nonparametric componentg(·) is given by
ˆ gn(t) =
n
i=1 mi
j=1
Wnij(t)(yij−xTijβˆn). (2:3)
In this paper, let {eij,1≤j≤mi} be-mixing orr-mixing withEeij= 0 for eachi(1≤i≤
n), and {ei, 1≤i≤n} be mutually independent, whereei= (ei1,. . .,eimi)
T. For eachi,
denotei(·) andri(·) be theith mixing coefficients of the sequence of-mixing andr
-mixing, respectively. DefineS2n=ni=1mi
j=1x˜ij˜xTij,g˜(t) =g(t)− n
k=1 mi
l=1Wnkl(t)g(tkl),
denote I(·) be the indicator function, || · || be the Euclidean norm, and set⌊z⌋≤z< ⌊z⌋+ 1 for the integer part ofz. In the sequence,Cand C1denote positive constants
whose values may vary at each occurrence.
For obtaining our main results, we list some assumptions: A1 (i) {eij, 1≤j≤mi} are-mixing withEeij= 0 for eachi;
(ii) {eij, 1≤j≤mi} arer-mixing withEeij= 0 for eachi.
A2 (i) max1≤i≤nmi=o(nδ) for some0< δ <
r−2
2r andr > 2;
(ii)limn→∞ 1
N(n)S 2
n=
, whereΣis a positive definite matrix andN(n) =ni=1mi
(iii)g(·) satisfies the first-order Lipschitz condition on [0, 1].
A3 For nlarge enough, the probability weight functionsWnij(·) satisfy
(i)ni=1 mi
j=1Wnij(t) = 1for eachtÎ [0, 1];
(ii)sup0≤t≤1max1≤i≤n,1≤j≤miWnij(t) =O ⎛ ⎝n−
1 2
⎞ ⎠;
(iii)sup0≤t≤1ni=1mi
j=1Wnij(t)I(|tij−t|> ε) =o(1)for any> 0;
(iv)max1≤k≤n,1≤l≤mi|| n
i=1 mi
j=1Wnij(tkl)xij||=O(1),
(v)sup0≤t≤1ni=1mi
j=1Wnij(t)xij=O(1),
(vi)max1≤i≤n,1≤j≤miWnij(s)−Wnij(t)≤C|s−t|uniformly fors, tÎ [0, 1].
Remark 2.1 For obtaining the asymptotic properties of estimators of the models (1.1),
mixing-dependent structure. The condition of {mi, 1 ≤ i ≤ n} being a bounded sequence is a special case of A2(i).
Remark 2.2 Assumption A2(ii) implies that
1 N(n)
n
i=1 mi
j=1
||˜xij||=O(1) and max 1≤i≤n,1≤j≤mi
||˜xij||=o ⎛ ⎝N(n)
1 2
⎞ ⎠.
Remark 2.3 As a matter of fact, there exist some weights satisfying assumption A3.
For example, under some regularity conditions, the following Nadaraya-Watson kernel weight satisfies assumption A3:
Wnij(t) =K
t−tij hn
n
k=1 mi
l=1 K
t−tkl
hn −1
,
whereK(·) is a kernel function andhnis a bandwidth parameter. Assumption A3 has also been used by Hardle et al. [7], Baek and Liang [16], Liang and Jing [20] and Chen and You [47].
Theorem 2.1Suppose that A1(i) or A1(ii), and A2 and A3(i)-(iii) hold. If
max 1≤i≤n,1≤j≤mi
E(|eij|p)≤C, a.s. (2:4)
for p> 3,then
ˆ
βn→β, a.s.. (2:5)
Theorem 2.2 Suppose that A1(i) or A1(ii), and A2, A3(i-iv) and (2.4) hold. For any tÎ[0, 1], we have
ˆ
gn(t)→g(t), a.s.. (2:6)
Theorem 2.3 Suppose that A1(i) or A1(ii), and A2, A3(i-iii), A3(v-vi) and (2.4) hold. We have
sup 0≤t≤1|ˆ
gn(t)−g(t)|=o(1), a.s.. (2:7)
3 Several technical lemmas and corollaries
In order to prove the main results, we first introduce some lemmas and corollaries. Let
Sj=jl=1Xlforj≥1, andSk(i) = k+i
j=k+1Xjfor i≥1 andk≥0. Lemma 3.1. (Shao [28])Let{Xm,m≥1}be a-mixing sequence.
(1) If EXi= 0,then
ES2k(i)≤8000iexp ⎧ ⎨ ⎩6
logi
j=1
ϕ1/2(2j) ⎫ ⎬
⎭k+1max≤j≤k+iEX 2 j.
(2) Suppose that there exists an array {ckm} of positive numbers such that
max1≤i≤mES2k(i)≤ckmfor every k ≥0,m≥1.Then, for any q≥2,there exists a positive
Emax 1≤i≤m|Sk(i)|
q≤C
cqkm/2+E max k<i≤k+m|Xi|
q
.
Lemma 3.2. (Shao[37])Let{Xm,m≥1}be ar-mixing sequence with EYi= 0.Then,
for any q ≥2,there exists a positive constant C=C(q,r(·))such that
Emax
1≤j≤m|Sj|
q≤C
⎛
⎝mq/2exp ⎧ ⎨ ⎩C
logm
j=1
ρ(2j) ⎫ ⎬
⎭1max≤j≤m(E|Xj| 2)q/2
+mexp
⎧ ⎨ ⎩C
logm
j=1
ρ2/q(2j) ⎫ ⎬
⎭1max≤j≤mE|Yj| qθ
⎞ ⎠.
Lemma 3.3.Suppose that A1(i) or A1(ii) holds. Leta> 1,0 <r<aand
eij=eijI ⎛ ⎝|eij| ≤εi
1 r mi
⎞
⎠, (3:1)
eij=eij−eij=eijI ⎛ ⎝eij> εi
1 r mi
⎞ ⎠+eijI
⎛
⎝eij<−εi 1 r mi
⎞
⎠ (3:2)
for any ε> 0.If
max 1≤i≤n1max≤j≤mi
E(|eij|α)≤C, a.s., (3:3)
we have
∞
i=1 mi
j=1
|eij|<∞, a.s..
Proof Note that |eij|=|eij|I ⎛
⎝|eij|> εi 1 rmi
⎞
⎠. Let
ξi=
mi j=1|eij|,ξ
i=
mi j=1|eij| ·I
⎛ ⎝mi
j=1|eij| ≤εi
1 r mi
⎞ ⎠,ξ
i=ξi−ξi=
mi j=1|eij|I
⎛ ⎝mi
j=1|eij|> εi
1 r mi
⎞
⎠, and
|ξ
i|d=|ξi|I(|ξi| ≤d)for fixedd> 0. First, we prove
∞
i=1
|ξi|<∞, a.s.. (3:4)
Note that
{|ξ
i|>d}= ⎧ ⎨ ⎩
mi
j=1 |eij|I
⎛ ⎝mi
j=1
|eij|> εi 1 r mi
⎞ ⎠>d
⎫ ⎬ ⎭=
⎧ ⎨ ⎩
mi
j=1
|eij|> εi 1 r mi
⎫ ⎬
for ilarge enough. By Markov’s inequality,Cr-inequality, and (3.3), we have
∞
i=1
P(ξid)≤C
∞
i=1 P
⎛ ⎝mi
j=1
eij> εi 1 r mi
⎞ ⎠
≤C
∞
i=1 i−
α
r m−iαE
mi
j=1 eij
α
≤C
∞
i=1 i−
α
r m−1
i mi
j=1 Eeijα
≤Clim
n→∞
n
i=1 i−
α
r max
1≤i≤n1max≤j≤mi
Eeijα
≤C
∞
i=1 i−
α
r <∞,
(3:6)
From (3.5),{|ξi| ≤d}= ⎧ ⎨ ⎩
mi
j=1|eij| ≤εi 1 r mi
⎫ ⎬
⎭forilarge enough. One gets
E(|ξi|d) =E(|ξi|I(|ξi| ≤d))
=E
⎛ ⎝mi
j=1 |eij|I
⎛ ⎝mi
j=1
|eij|> εi 1
r mi ⎞ ⎠I
⎛ ⎝mi
j=1
|eij| ≤εi 1 r mi
⎞ ⎠ ⎞ ⎠= 0
and
Var(|ξi|d)≤E(|ξi|2d) =E(|ξi|I(|ξi| ≤d))2
=E|ξi|2I(|ξi| ≤d)≤dE(|ξi|I(|ξi| ≤d)) = 0
for ilarge enough. Therefore, ∞
i=1
E(|ξi|d)<∞,
∞
i=1
Var(|ξi|d)<∞. (3:7)
Since{ξi, 1≤i≤n}is a sequence of independent random variables, (3.4) holds from (3.6) and (3.7) by Three Series Theorem. Then,
∞
i=1 mi
j=1 |eij|=
∞
i=1 mi
j=1 |eij|I
⎛
⎝|eij|> εi 1 r mi
⎞ ⎠
≤
∞
i=1 mi
j=1 |eij|I
⎛ ⎝mi
j=1
|eij|> εi 1 r mi
⎞ ⎠=
∞
i=1
|ξi|<∞, a.s..
Thus, we complete the proof of Lemma 3.3.
Lemma 3.4.Let {eij, 1≤j≤ mi}be the-mixing with Eeij= 0 for each i(1≤ i≤n).
Assume that {anij(·), 1≤i≤n,1≤j≤mi}is a function array defined on[0, 1],satisfying
max1≤i≤n,1≤j≤mi|anij(t)|=O ⎛ ⎝n−
1 2
⎞
⎠andmax1≤i≤n,1≤j≤mi|anij(t)|=O ⎛ ⎝n−
1 2
⎞
⎠for any t Î
[0, 1], and A2(i) and (2.4) hold. Then, for any tÎ[0, 1] we have n
i=1 mi
j=1
Proof Based on (3.1) and (3.2), we denoteζnij=eij−E(eij),ηnij =eij−E(eij)and take r satisfying 2 <r<p- 1. Sinceeij=ζnij+hnij, we have
n i=1 mi j=1
anij(t)eij= n i=1 mi j=1
anij(t)ζnij+ n i=1 mi j=1
anij(t)eij− n i=1 mi j=1
anij(t)E(eij)
=:A1n+A2n−A3n.
(3:9)
First, we prove
A1n→0, a.s.. (3:10)
Denotingζ˜ni =mj=1i anij(t)ζnij, we know that{˜ζni,1≤i≤n}is a sequence of independent
random variables with Eζ˜ni= 0. By Markov’s inequality, and Rosenthal’s inequality, for any ε> 0 andq ≥2, one gets
P n i=1 ˜ ζni > ε
≤ε−qE n i=1 ˜ ζni q ≤C ⎛ ⎜ ⎜ ⎝ n i=1
E|˜ζni|q+ n
i=1 Eζ˜ni2
q 2 ⎞ ⎟ ⎟ ⎠
=:A11n+A12n.
(3:11)
Note that i(m) ® 0 as m ® ∞, hence logmi
k=1 ϕ
1/2
i (2k) =o(logmi). Further,
expλlogmi
k=1 ϕ
1/2 i (2k)
=o(mτi)for any l> 0 and τ> 0.
ForA11n, by Lemma 3.1, A2(i) and (2.4), and takingq>p, we have
A11n=C n i=1 E mi j=1
anij(t)ζnij
q ≤C n i=1 ⎡ ⎢ ⎣ ⎛ ⎝miexp
⎧ ⎨ ⎩6
logmi
k=1 ϕ1/2 i (2 k) ⎫ ⎬ ⎭1max≤k≤mi
E|anik(t)ζnik|2
⎞ ⎠ q/2 + mi j=1
E|anijζnij|q
⎤ ⎥ ⎦ ≤C n i=1 ⎡
⎣m1+i τn−1q/2+
mi
j=1
n− q
2E|ζnij|p|ζnij|q−p
⎤ ⎦
≤Cn− q 2 n i=1 mi (τ+ 1)q
2 +Cn−
q 2 n i=1 mi j=1
(i1rmi)
q−p
≤Cn −
⎛ ⎝q
2−
(τ+ 1)δq
2 −1
⎞ ⎠
+Cn− q
2− q r+
p
r−(q−p+1)δ−1
Take q>max
%
2r(2 +δ)
r−2rδ−2,
4 1−δ,p
&
. We have q
2 −
δq
2 >2 and
q
2 −
q
r +
p
r −(q−p+ 1)δ >2.
Next, takeτ> 0 small enough such thatq
2−
(τ + 1)δq
2 >2. Thus, we have
∞
n=1
ForA12n, by Lemma 3.1 and (2.4), we have
A12n=C
⎧ ⎨ ⎩ n i=1 E mi j=1
anij(t)ζnij 2⎫ ⎬ ⎭ q 2 ≤C ⎧ ⎨ ⎩ n i=1
miexp
⎧ ⎨ ⎩6
logmi
k=1
ϕ1/2 i (2k)
⎫ ⎬ ⎭1max≤j≤mi
E|anij(t)ζnij|2 ⎫ ⎬ ⎭ q 2 ≤C ⎧ ⎨ ⎩ n i=1 mτi+1
mi
j=1
E|anij(t)ζnij|2 ⎫ ⎬ ⎭ q 2 ≤Cn − ⎛ ⎝q 4−
(τ+ 1)δq 2
⎞ ⎠
Note that δ < r−2 2r <
1
2. Takingq> 4
1−2δ, we have q
4−
δq
2 >1. Next, takeτ > 0
small enough such that q
2−
(τ+ 1)δq
2 >1. Thus, we have
∞
n=1
A12n<∞. (3:13)
Combining (3.11)-(3.13), we obtain (3.10).
By Lemma 3.3 andmax1≤i≤n,1≤j≤mi|anij(t)|=O ⎛ ⎝n−
1 2
⎞
⎠for any tÎ [0, 1], we have
|A2n| ≤ max i≤i≤n,1≤j≤mi
|anij(t)| n i=1 mi j=1
|eij|=O ⎛ ⎝n−
1 2
⎞
⎠. (3:14)
Note thatp−1
r >1and δ> 0. From (2.4), we have
|A3n|= n i=1 mi j=1
anij(t)E(eij)
≤n− 1 2 n i=1 mi j=1 E ⎛
⎝|eij|I(|eij|> εi 1 r mi)
⎞ ⎠
=n− 1 2 n i=1 mi j=1 E ⎛
⎝|eij|p|eij|1−pI ⎛
⎝|eij|> εi 1 r mi
⎞ ⎠ ⎞ ⎠
≤Cn− 1 2 n i=1 mi j=1 ⎛ ⎝i 1 r mi
⎞ ⎠
1−p
≤Cn− 1 2 n i=1 i−
p−1
r m2i−p
≤Cn−
(p−2)δ+1 2
=o(1).
(3:15)
From (3.9), (3.10), (3.14) and (3.15), we have (3.8).
Corollary 3.1.In Lemma 3.4, if{eij, 1≤j≤ mi}arer-mixing with Eeij= 0for each i
Proof From the proof of Lemma 3.4, it is enough to prove that∞n=1A11n<∞and ∞
n=1A12n<∞.
Note that ri(m) ® 0 as m ® ∞, hence k=1logmiρi2/q(2k) =o(logmi). Further,
exp %
λlogmi
k=1 ρ
2/q
i (2
k) &
=o(mτi)for anyl> 0 andτ > 0.
ForA11n, by Lemma 3.2 and (2.4), and takingq>p, weget
A11n=C
n i=1 E mi j=1
anij(t)ζnij q ≤C n i=1 ⎛ ⎜ ⎝m q 2 i exp ⎧ ⎨ ⎩C1
logmi
k=1
ρ1(2k) ⎫ ⎬ ⎭1max≤k≤mi
(E|anikζnik|2) q 2
+miexp ⎧ ⎨ ⎩C1
logmi
k=1
ρ2/q
i (2
k) ⎫ ⎬ ⎭1max≤k≤mi
E|anikζnik|q ⎞ ⎠ ≤C n i=1 ⎛ ⎜ ⎝m
τ+q 2
i n
−q
2 +mτi+1n− q 2
⎛ ⎝i
1 r mi
⎞ ⎠
q−p⎞ ⎟ ⎠
≤Cn− q
2−
r+q 2
δ−1
+Cn−
q
2− q r+
p
r−(q+p+r+1)δ−1
Take q>max
%
2r(2 +δ)
r−2rδ−2,
4 1−δ,p
&
. We have q
2 −
qδ
2 >2 and
q
2 −
q
r +
p
r −(q−p+ 1)δ >2.
Next, take τ > 0 small enough such that q
2 −
τ+ q 2
δ >2 and q
2 −
q
r +
p
r −(q+p+τ + 1)δ >2. Thus, ∞
n=1A11n<∞.
ForA12n, by Lemma 3.2 and (2.4), we have
A12n=C
⎧ ⎨ ⎩ n i=1 E mi j=1
anij(t)ζnij 2⎫ ⎬ ⎭ q 2 ≤C ⎛ ⎝n
i=1
miexp
⎧ ⎨ ⎩C1
logmi
k=1
ρ1(2k) ⎫ ⎬ ⎭1max≤j≤mi
E|anikζnik|2 ⎞ ⎠ q 2 ≤C ⎛ ⎝n
i=1 mτi+1
mi
j=1
E|anijζnij|2 ⎞ ⎠ q 2 ≤Cn − ⎛ ⎝q 4−
(τ + 1)δq 2
⎞ ⎠
Note thatδ < 1
2from A2(i). Takingq> 4
1−2δ, we have q
4−
δq
2 >1. Next, takeτ>
0 small enough such that q
2−
(τ+ 1)δq
2 >1. Thus, ∞
So, we complete the proof of Lemma 3.4.
Remark 3.1If the real function array {anij(t),1≤i≤n, 1 ≤j<mi} is replaced with the
real constant array {anij, 1≤i≤ n, 1≤j≤mi}, the results of Lemma 3.4 and Corollary 3.1 hold obviously.
Lemma 3.5.Let{eij, 1≤j≤mi} be the-mixing with Eeij = 0for each i(1≤ i≤n).
Assume that {anij(·), 1≤i≤ n, 1≤ j≤mi}is a function array defined on[0, 1],
satisfy-ing ni=1
mi
j=1|anij(t)|=O(1)andmax1≤i≤n,1≤j≤mi|anij(t)|=O ⎛ ⎝n−
1 2
⎞
⎠uniformly for t Î
[0, 1], andmax1≤i≤n,1≤j≤mi|anij(s)−anij(t)| ≤C|s−t|uniformly for s,tÎ [0, 1],where C
is a constant. If A2(i) and (2.4) hold, then
sup 0≤t≤1
n i=1 mi j=1
anij(t)eij
=o(1), a.s.. (3:16)
ProofBased on (3.1) and (3.2), we denoteζnij=eij−Eeijand takersatisfying 2 <r <p
- 1. Using the finite covering theorem, [0, 1] is covered byO ⎛ ⎝n2+
1 r
⎞
⎠’s neighborhoods
Dnwith centersnand radius
n − 2+1 r
, and for eachtÎ[0, 1], there exists some
neigh-borhood Dn(sn(t)) with centersn(t) and radius
n−
2+1
r
such thattÎDn(sn(t)). SinceE
(eij) = 0, we have n i=1 mi j=1
anij(t)eij ≤ n i=1 mi j=1
anij(t)eij + n i=1 mi j=1
(anij(t)−anij(sn(t)))eij + n i=1 mi j=1
anij(sn(t))ζnij + n i=1 mi j=1
(anij(t)−anij(sn(t)))E(eij) + n i=1 mi j=1
anij(t)E(eij) .
=:B1n(t) +B2n(t) +B3n(t) +B4n(t) +B5n(t).
Denote sup maxt,i,j= sup0≤t≤1max1≤i≤n,1≤j≤mi. By Lemma 3.3 and the proof of (3.15),
noting thatδ < 1
2, we have
sup
0≤t≤1
B1n(t)≤sup max t,i,j
anij(t) n i=1 mi j=1 eij=O
⎛ ⎝n−
1 2
⎞ ⎠, a.s.,
sup
0≤t≤1
B2n(t)≤sup max t,i,j
anij(t)−anij(sn(t))n
i=1
mi
j=1
eij≤Cn
−
2+1 r
n2δn1+
1
r =o(1),
sup
0≤t≤1
B4n(t)≤sup max t,i,j
anij(t)−anij(sn(t))n
i=1
mi
j=1
E(eij) =o(1),
sup
0≤t≤1
B5n(t)≤sup max t,i,j
anij(t) n i=1 mi j=1 E ⎛ ⎝eijI
⎛ ⎝eij> εi
1
Now, it is enough to show sup0≤t≤1 B3n(t) =o(1), a.s..
From (3.11),A11nandA12n, for the giventÎ[0, 1] anduÎ Dn(sn(t)), we have
P ⎛ ⎝ n i=1 mi j=1
anij(u)ζnij
> ε
⎞ ⎠≤C
⎛ ⎜ ⎜ ⎝n−
q
2− q r+
p r−(q−p+1)δ−1
+n − ⎛ ⎝q 2− (r+ 1)δq
2 −1
⎞ ⎠ +n − ⎛ ⎝q 4− (r+ 1)δq
2 ⎞ ⎠ ⎞ ⎟ ⎟ ⎠.
Then, we obtain
P
sup
0≤t≤1
B3n(t)> ε
≤P ⎛ ⎝sup
0≤t≤1
sup
u∈Dn(sn(t)) n i=1 mi j=1
anij(u)ζnij
> ε
⎞ ⎠
≤Cn2+ 1 r ⎛ ⎜ ⎜ ⎝n − q 2− q r+ p r−(q−p+1)δ−1
+n − ⎛ ⎝q 2− (r+ 1)δq
2 −1
⎞ ⎠ +n − ⎛ ⎝q 4− (r+ 1)δq
2 ⎞ ⎠ ⎞ ⎟ ⎟ ⎠ ≤C ⎛ ⎜ ⎜ ⎝n − q 2− q r−δd−δ−4
+n − ⎛ ⎝q 2− (r+ 1)δq
2 −4
⎞ ⎠ +n − ⎛ ⎝q 4− (r+ 1)δq
2 −3
⎞ ⎠ ⎞ ⎟ ⎟ ⎠.
Take q>max %
2r(5 +δ)
r−2rδ−2,
16 1−2δ,p
&
. We have q
2−
q
r −δq−δ >5, q
2−
δq 2 >5
and q
4−
δq
2 >4. Next, take τ > 0 small enough such that q
2−
(r+ 1)δq
2 >5and
q
4 −
(r+ 1)δq
2 >4. Thus, we have
∞ n=1P
sup0≤t≤1B3n(t)> ε<∞. Thus, sup0≤t≤1 B3n(t) =o(1),a.s.. Therefore, (3.16 ) holds.
Corollary 3.2. In Lemma 3.5, if{eij, 1≤j≤ mi}arer-mixing with Eeij= 0for each i
(1≤i≤n),then (3.16) holds.
Proof By Corollary 3.1, with arguments similar to the proof of Lemma 3.5, we have (3.16).
4 Proof of Theorems
Proof of Theorem 2.1 From (1.1) and (2.2), we have
ˆ βn−β=
⎛ ⎝n
i=1 mi
j=1 ˜
xijx˜Tij
⎞ ⎠ −1 n i=1 mi j=1 ˜
xij(˜yij− ˜xTijβ)
=S−2 n n i=1 mi j=1 ˜ xij
(yij−xTijβ)− n k=1 mi l=1
Wnkl(tij)(ykl−xTklβ)
=S−n2
n i=1 mi j=1 ˜ xij
(g(tij) +eij)− n k=1 mi l=1
Wnkl(tij)(g(tkl) +ekl)
=S−n2
n i=1 mi j=1 ˜ xij eij−
n k=1 mi l=1
Wnkl(tij)ekl+g˜(tij)
=S−2 n
⎡ ⎣n
i=1 mi
j=1 ˜
xijeij− n i=1 mi j=1 ˜ xij n k=1 mi l=1
Wnkl(tij)ekl
+ n i=1 mi j=1 ˜
xijg˜(tij)
⎤ ⎦ = S2 n
N(n) −1⎡
⎣n
i=1 mi j=1 ˜ xij
N(n)eij−
n i=1 mi j=1 ˜ xij
N(n) n k=1 mi l=1
Wnkl(tij)ekl
+ n i=1 mi j=1 ˜ xij
N(n)g˜(tij) ⎤ ⎦
=:D1n+D2n+D3n.
From A2(ii), %
S2 n N(n)
&−1
=O(1). By Remark 2.2, we have
n i=1 mi j=1
||˜xij||
N(n) =O(1) and 1≤i≤maxn,1≤j≤mi
||˜xij||
N(n) =o
⎛ ⎝n
1 2
⎞
⎠. (4:2)
According to (4.2) and Remark 3.1, we have
||D1n|| ≤C n i=1 mi j=1 ||˜xij|| N(n)eij
=o(1), a.s.. (4:3)
By A3(i-ii), (4.2), Lemma 3.4 or Corollary 3.1, we have
||D2n|| ≤C max
1≤i≤n,1≤j≤mi n k=1 mi l=1
Wnkl(tij)ekl · n i=1 mi j=1 ||˜xij||
N(n) =o(1). a.s.. (4:4)
From A2(iii) and A3(iii), we obtain
max
1≤i≤n,1≤j≤mi
˜g(tij)= max
1≤i≤n,1≤j≤mi g(tij)−
n k=1 mi l=1
Wnkl(tij)g(tkl)
≤ max
1≤i≤n,1≤j≤mi n k=1 mi l=1
Wnkl(tij)(g(tij)−g(tkl))I(|tij−tkl|> ε)
+ max
1≤i≤n,1≤j≤mi n k=1 mi l=1
Wnkl(tij)(g(tij)−g(tkl))I(|tij−tkl| ≤ε)
=o(1).
(4:5)
Together with (4.2), one gets
||D3n|| ≤C max
1≤i≤n,1≤j≤mi
|˜g(tij)| · n i=1 mi j=1 ||˜xij||
N(n) =o(1). (4:6)
By (4.1), (4.3), (4.4) and (4.6), (2.5) holds.
Proof of Theorem 2.2 From (1.1) and (2.3), we have
ˆ
gn(t)−g(t) = n i=1 mi j=1
Wnij(t)(yij−xTijβˆn)−g(t)
= n i=1 mi j=1
Wnij(t)
(yij−xTijβˆn)−(yij−xTijβ)
+ n i=1 mi j=1
Wnij(t)(yij−xTijβ)−g(t)
= n i=1 mi j=1
Wnij(t)xTij(β− ˆβn) + n i=1 mi j=1
Wnij(t)(g(tij) +eij)−g(t)
= n i=1 mi j=1
Wnij(t)xTij(β− ˆβn) + n i=1 mi j=1
Wnij(t)eij− ˜g(t)
=:E1n+E2n+E3n.
(4:7)
By A3(iv) and (2.5), one gets
|E1n| ≤ n i=1 mi j=1
Wnij(t)xij
||β− ˆβn||=o(1), a.s.. (4:8)
Proof of Theorem 2.3 Here, we still use (4.7), butEinin (4.7) are replaced byEin(t) for i= 1,2 and 3. By A3(v) and (2.5), we get
sup 0≤t≤1|
E1n(t)| ≤ sup
0≤t≤1
n
i=1 mi
j=1
Wnij(t)xij
||β− ˆβn||=o(1), a.s..
By Lemma 3.5 or Corollary 3.2, sup0≤t≤1|E2n(t)| =o(1), a.s.; Similar to the arguments in (4.5), we have sup0≤t≤1|E2n(t)|=o(1). Hence, (2.7) is proved.
5 Simulation study
To evaluate the finite-sample performance of the least squares estimatorβˆnand the nonparametric estimator ˆgn(t), we respectively take two forms of functions for g(·):
I. g(t) = exp(3t); II. g(t) = cos
3π
2 t
,
consider the case where p= 1 and mi =m= 12, and take the design pointstij= ((i -1)m+j)/(nm),xij~N(1, 1) and the errorseij= 0.2ei, j-1+ij, where ij are i.i.d.N(0,1) random variables, andei,0~N(0,1) for eachi.
The kernel function is taken as the Epanechnikov kernel K(t) = 3 4(1−t
2)I(|t| ≤1),
and the weight function is given by Nadaraya-Watson kernel weight
Wij(t) =K
t−tij hn
/ni=1mi
j=1K
t−tij hn
. The bandwidthh is selected by a
“leave-one-subject-out” cross validation method. In the simulations, we drawB= 1000 ran-dom samples of sizes 150,200,300 and 500 forb= 2, respectively. We obtain the esti-matorsβˆnand gˆn(t)from (2.2) and (2.3), respectively. Let βˆ(b)
n bebth least squares estimator ofbunder the sizen. Some numerical results forβˆnare computed by
¯
βn= 1 B
B
b=1 ˆ
β(b)
n , SD(' βˆn) =
1
B−1
B
b=1
(βˆn(b)− ¯β) 2
1/2 ,
(
Bias(βˆn) =β¯−β, MSE(( βˆn) = 1
B−1
B
b=1
(βˆn(b)−β) 2
,
which are listed in Table 1.
In addition, for assessing estimator of the nonparametric component g(·), we study the square root of mean-squared errors (RMSE) based on 1000 repetitions. Denote
ˆ
gn(b)(t)be thebth estimator ofg(t) under the size n, andg¯ˆn(t) = B
b=1gˆ (b)
n (t)/Bbe the
average estimator of g(t). We compute
RMSEn=
1 M
M
s=1
(g¯ˆn(ts)−g(ts)) 2
1/2 ,
and
RMSE(nb)=
1 M
M
s=1
(gˆ(nb)(ts)−g(ts)) 2
1/2
where {ts, s= 1,...,M} is a sequence of regular grid points on [0, 1]. Figures 1 and 2 respectively provide the average estimators of the nonparametric function g(·) and
RMSEn values for Cases I and II, respectively. The boxplots for
RMSE(nb)(b= 1, 2,. . .,B)values for Cases I and II are presented in Figure 3.
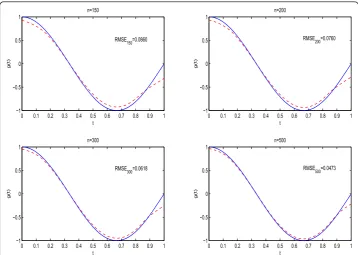
[image:15.595.117.478.111.232.2]From Table 1, we see that (i)|Bias(( βˆn)|,SD(' βˆn)and MSE(( βˆn)do decrease with increasing the sample size n; (ii) the larger the sample sizenis, the closer theβ¯nis to the true value 2. From Figures 1, 2 and 3, we observe that the biases of estimators of the nonparametric component g(·) decrease as the sample sizenincreases. These show that, for semiparametric partially linear regression models for longitudinal data based on mixing error’s structure, the least squares estimator of parametric component b and the estimator of nonparametric componentg(·) work well.
Table 1 The estimators ofband some indices of their accuracy for the different sample size n and nonparametric functiong(·)
g(·) n β¯n Bias(( βˆn) SD(' βˆn) MSE(( βˆn)
exp(3t) 150 1.99938 -0.00062 0.0257 0.00066
200 1.99960 -0.00040 0.0221 0.00049
300 1.99965 -0.00035 0.0172 0.00030
500 1.99963 -0.00037 0.0133 0.00018
cos
3π
2 t
150 1.99908 -0.00092 0.0238 0.00056
200 1.99945 -0.00055 0.0206 0.00043
300 1.99950 -0.00050 0.0168 0.00028
500 1.99969 -0.00031 0.0131 0.00017
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
5 10 15 20
t
g(t)
n=150
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
5 10 15 20
t
g(t)
n=200
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
5 10 15 20
t
g(t)
n=300
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
5 10 15 20
t
g(t)
n=500
RMSE
500=0.4580
RMSE300=0.5676
RMSE150=0.7530 RMSE200=0.6698
Figure 1Estimators of the nonparametric componentg(·) for the case I:gˆn(·)(dashed curve) and g
[image:15.595.118.478.446.707.2]6 Concluding remarks
An inherent characteristic of longitudinal data is the dependence among the observa-tions within the same subject. For exhibiting dependence among the observaobserva-tions within the same subject, we consider the estimation problems of partially linear models for longitudinal data with the -mixing andr-mixing error structures, respectively. The strong consistency for least squares estimator βˆnof parametric componentb is
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
−1 −0.5 0 0.5 1
t
g(t)
n=150
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
−1 −0.5 0 0.5 1
t
g(t)
n=200
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
−1 −0.5 0 0.5 1
t
g(t)
n=300
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
−1 −0.5 0 0.5 1
t
g(t)
n=500 RMSE150=0.0860
RMSE300=0.0618 RMSE500=0.0473
[image:16.595.118.477.88.343.2]RMSE200=0.0760
Figure 2Estimators of the nonparametric componentg(·) for the case II:gˆn(·)(dashed curve) and
g(·) (solid curve).
n=150 n=200 n=300 n=500
0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8
RMSE
g(t)=exp(3t)
n=150 n=200 n=300 n=500
0.04 0.06 0.08 0.1 0.12 0.14 0.16
RMSE
g(t)=cos(3πt/2)
(b)
studied. In addition, the strong consistency and uniform consistency for the estimator ˆ
gn(·)of nonparametric functiong(·) are investigated under some mild conditions. In the paper, we only consider(xT
ij,tij)are known and nonrandom design points, as
Baek and Liang [16], and Liang and Jing [20]. In the monograph of Hardle et al. [7], they respectively considered the two cases: the fixed design and the random design, to study non-longitudinal partially linear regression models. Our results can also be extended to the case of(xTij,tij)being random. The interested readers can consider the work. In addition, we consider partially linear models for longitudinal data with only
-mixing and r-mixing. In fact, our results with other mixing-dependent structures,
such as a-mixing, *-mixing and r*-mixing, can also be obtained by the same
argu-ments in our paper. At present, we have not given the asymptotic normality of estima-tors, since some details need further discussion. We will devote to establish the asymptotic normality ofβˆnand gˆn(·)in our future work.
Acknowledgements
The authors are grateful to an Associate Editor and two anonymous referees for their constructive suggestions that have greatly improved this paper. This work is partially supported by NSFC (no. 11171065), Anhui Provincial Natural Science Foundation (no. 11040606M04), NSFJS (no. BK2011058) and Youth Foundation for Humanities and Social Sciences Project from Ministry of Education of China (no. 11YJC790311).
Author details
1
Department of Mathematics, Southeast University, Nanjing 210096, People’s Republic of China2Department of Mathematics and Computer Science, Tongling University, Tongling 244000, Anhui, People’s Republic of China
Authors’contributions
The two authors contributed equally to this work. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Received: 26 July 2011 Accepted: 17 November 2011 Published: 17 November 2011
References
1. Diggle, LD, Heagerty, P, Liang, K, Zeger, S: Analysis of Longitudinal Data. Oxford University Press, New York, 2 (2002) 2. Fan, J, Li, R: New estimation and model selection procedure for semiparametric modeling in longitudinal data analysis.
J Am Stat Assoc.99, 710–723 (2004). doi:10.1198/016214504000001060
3. Engle, R, Granger, C, Rice, J, Weiss, A: Nonparametric estimates of the relation between weather and electricity sales. J Am Stat Assoc.81, 310–320 (1986). doi:10.2307/2289218
4. Heckman, N: Spline smoothing in a partly linear models. J R Stat Soc B.48, 244–248 (1986) 5. Speckman, P: Kernel smoothing in partial linear models. J R Stat Soc B.50, 413–436 (1988)
6. Robinson, PM: Root-n-consistent semiparametric regression. Econometrica.56, 931–954 (1988). doi:10.2307/1912705 7. Härdle, W, Liang, H, Gao, JT: Partial Linear Models. Physica-Verlag, Heidelberg (2000)
8. Zeger, SL, Diggle, PL: Semiparametric models for longitudinal data with application to CD4 cell numbers in HIV seroconverters. Biometrics.50, 689–699 (1994). doi:10.2307/2532783
9. Moyeed, RA, Diggle, PJ: Rate of convergence in semiparametric modeling of longitudinal data. Aust J Stat.36, 75–93 (1994). doi:10.1111/j.1467-842X.1994.tb00640.x
10. Zhang, D, Lin, X, Raz, J, Sowerm, MF: Semiparametric stochastic mixed models for longitudinal data. J Am Stat Assoc. 93, 710–719 (1998). doi:10.2307/2670121
11. You, JH, Zhou, X: Partially linear models and polynomial spline approximations for the analysis of unbalanced panel data. J Stat Plan Inference.139, 679–695 (2009). doi:10.1016/j.jspi.2007.04.037
12. You, JH, Zhou, X, Zhou, Y: Statistical inference for panel data semiparametric partially linear regression models with heteroscedastic errors. J Multivar Anal.101, 1079–1101 (2010). doi:10.1016/j.jmva.2010.01.003
13. Schick, A: An adaptive estimator of the autocorrelation coefficient in regression models with autocoregressive errors. J Time Ser Anal.19, 575–589 (1998). doi:10.1111/1467-9892.00109
14. Gao, JT, Anh, VV: Semiparametric regression under long-range dependent errors. J Stat Plan Inference.80, 37–57 (1999). doi:10.1016/S0378-3758(98)00241-9
15. Sun, XQ, You, JH, Chen, GM, Zhou, X: Convergence rates of estimators in partial linear regression models with MA(∞) error process. Commun Stat Theory Methods.31, 2251–2273 (2002). doi:10.1081/STA-120017224
16. Baek, J, Liang, HY: Asymptotics of estimators in semi-parametric model under NA samples. J Stat Plan Inference.136, 3362–3382 (2006). doi:10.1016/j.jspi.2005.01.008
18. Li, GL, Liu, LQ: Strong consistency of a class estimators in partial linear model under martingale difference sequence. Acta Math Sci (Ser A).27, 788–801 (2007)
19. Chen, X, Cui, HJ: Empirical likelihood inference for partial linear models under martingale difference sequence. Stat Probab Lett.78, 2895–2910 (2008). doi:10.1016/j.spl.2008.04.012
20. Liang, HY, Jing, BY: Asymptotic normality in partial linear models based on dependent errors. J Stat Plan Inference.139, 1357–1371 (2009). doi:10.1016/j.jspi.2008.08.005
21. He, X, Zhu, ZY, Fung, WK: Estimation in a semiparametric model for longitudinal data with unspecified dependence structure. Biometrika.89, 579–590 (2002). doi:10.1093/biomet/89.3.579
22. Xue, LG, Zhu, LX: Empirical likelihood-based inference in a partially linear model for longitudinal data. Sci China (Ser A). 51, 115–130 (2008). doi:10.1007/s11425-008-0020-4
23. Li, GR, Tian, P, Xue, LG: Generalized empirical likelihood inference in semipara-metric regression model for longitudinal data. Acta Math Sin (Engl Ser).24, 2029–2040 (2008). doi:10.1007/s10114-008-6434-7
24. Bai, Y, Fung, WK, Zhu, ZY: Weighted empirical likelihood for generalized linear models with longitudinal data. J Multivar Anal.140, 3445–3456 (2010)
25. Hu, Z, Wang, N, Carroll, RJ: Profile-kernel versus backfitting in the partially linear models for longitudinal/clustered data. Biometrika.91, 251–262 (2004). doi:10.1093/biomet/91.2.251
26. Wang, S, Qian, L, Carroll, RJ: Generalized empirical likelihood methods for analyzing longitudinal data. Biometrika.97, 79–93 (2010). doi:10.1093/biomet/asp073
27. Chi, EM, Reinsel, GC: Models for longitudinal data with random effects and AR(1) errors. J Am Stat Assoc.84, 452–459 (1989). doi:10.2307/2289929
28. Shao, QM: A moment inequality and its application. Acta Math Sin.31, 736–747 (1988)
29. Peligrad, M: Ther-quick version of the strong law for stationaryφ-mixing sequences. Proceedings of the International Conference on Almost Everywere Convergence in Probability and Statistics. pp. 335–348.Academic Press, New York (1989)
30. Utev, SA: Sums of random variables withφ-mixing. Sib Adv Math.1, 124–155 (1991)
31. Kiesel, R: Summability and strong laws forφ-mixing random variables. J Theor Probab.11, 209–224 (1998). doi:10.1023/ A:1021655227120
32. Chen, PY, Hu, TC, Volodin, A: Limiting behaviour of moving average processes underφ-mixing assumption. Stat Probab Lett.79, 105–111 (2009). doi:10.1016/j.spl.2008.07.026
33. Zhou, XC: Complete moment convergence of moving average processes underφ-mixing assumptions. Statist Probab Lett.80, 285–292 (2010). doi:10.1016/j.spl.2009.10.018
34. Peligrad, M: On the central limit theorem for p-mixing sequences of random variables. Ann Probab.15, 1387–1394 (1987). doi:10.1214/aop/1176991983
35. Peligrad, M, Shao, QM: Estimation of variance for p-mixing sequences. J Multivar Anal.52, 140–157 (1995). doi:10.1006/ jmva.1995.1008
36. Peligrad, M, Shao, QM: A note on estimation of the variance of partial sums for p-mixing random variables. Stat Probab Lett.28, 141–145 (1996)
37. Shao, QM: Maximal inequalities for partial sums of p-mixing sequences. Ann Probab.23, 948–965 (1995). doi:10.1214/ aop/1176988297
38. Bradley, R: A stationary rho-mixing Markov chain which is not“interlaced”rho-mixing. J Theor Probab.14, 717–727 (2001). doi:10.1023/A:1017545123473
39. Lin, ZY, Lu, CR: Limit Theory for Mixing Dependent Random Variables. Science Press/Kluwer Academic Publishers, Beijing/London (1996)
40. Roussas, GG: Nonparametric regression estimation under mixing conditions. Stoch Process Appl.36, 107–116 (1990). doi:10.1016/0304-4149(90)90045-T
41. Truong, YK: Nonparametric curve estimation with time series errors. J Stat Plan Inference.28, 167–183 (1991). doi:10.1016/0378-3758(91)90024-9
42. Fraiman, R, Iribarren, GP: Nonparametric regression estimation in models with weak error’s structure. J Multivar Anal.37, 180–196 (1991). doi:10.1016/0047-259X(91)90079-H
43. Roussas, GG, Tran, LT: Asymptotic normality of the recursive kernel regression estimate under dependence conditions. Ann Stat.20, 98–120 (1992). doi:10.1214/aos/1176348514
44. Masry, E, Fan, JQ: Local polynomial estimation of regression functions for mixing processes. Scand J Stat.24, 165–179 (1997). doi:10.1111/1467-9469.00056
45. Aneiros, G, Quintela, A: Asymptotic properties in partial linear models under dependence. Test.10, 333–355 (2001). doi:10.1007/BF02595701
46. Fan, JQ, Yao, QW: Nonlinear Time Series–Nonparametric and Parametric methods. Springer, New York (2003) 47. Chen, GM, You, JH: An asymptotic theory for semiparametric generalized least squares estimation in partially linear
regression models. Stat Pap.46, 173–193 (2005). doi:10.1007/BF02762967 doi:10.1186/1029-242X-2011-112