International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)
521
Optimization of Hidden Markov Model using Minimum
Message Length Estimator
Murugesan N
1, Suguna P
21,2
Department of Mathematics, Government Arts College (Autonomous), Coimbatore, India
Abstract -- Pattern recognition is considered as one of the machine learning problems. It is also viewed as a classification problem in applied sciences, engineering and biology. To make the terminology more clear we consider the problem of analyzing patterns that occur imperfectly in a set of many sequences, finding an optimal model for the sequence without any prior assumption of the nature of the answer is a difficult one. In general Hidden Markov Model is the mathematical method that solves this problem. This paper describes a technique Minimum message length estimator to obtain a most appropriate Hidden Markov Model with optimized number of states. For a given sequence it is shown that the technique ensures optimal Hidden Markov Model with maximum probability. We have identified that the model could be applied to a biological sequence analysis problem.
Keywords – Hidden Markov Model, Minimum Message
Length Estimator, 5 Splice Site.
I. INTRODUCTION
Observing the environment and recognizing patterns for the purpose of decision making is fundamental to any scientific enquiry. Pattern recognition is a scientific discipline that enables perception in machines and it has applications in diverse technology areas – speech recognition, character recognition, image processing, bioinformatics, failure prediction, industrial automation, internet searches, medical diagnostics, target recognition, space science, remote sensing, data mining, biometric identification – to name a few. Pattern recognition can be defined as the classification of data based on knowledge already gained or on statistical information extracted from patterns and /or their representations. The data may be a combination of text, audio and video data. The text data may be alpha-numerical characters corresponding to one or more natural languages. The audio data could be in the form of speech or music. The video data could be a single image or a sequence of images. For example face of a criminal, his fingerprint and signature could come in the form of a single image. It is also possible to have a sequence of images of the same individual moving in an airport in the form of a video clip.
In a typical pattern recognition application, the raw data is processed and converted into a form that is amenable for a machine use. Pattern recognition, assigning labels to patterns, involves classification and clustering of patterns. In classification, an appropriate class label is assigned to a pattern based on an abstraction that is generated using a set of training patterns or domain knowledge. Clustering techniques of classification provides a deeper insight of the data. There are several paradigms which have been used to solve the pattern recognition challenges. The two main ones are
1. Statistical pattern recognition 2. Syntactic pattern recognition
Of the two, statistical pattern recognition has received considerable attention in literature. The main reason for this is that most practical problems in pattern recognition deal with uncertainty and therefore statistics and probability are good tools to deal with such vital issues. The statistical pattern recognition challenges are approached by Hidden Markov Models. A Hidden Markov model (HMM) is a statistical model, successfully used in such modeling, initially developed for speech recognition [6], and has subsequently been used in numerous sequence analysis applications. Current applications of HMMs include: speech recognition [6], genetic sequence analysis applications [2, 10], the detection of intrusion into computer systems and network traffic modeling [11]. HMM is also used for failure prediction in a computer system [4, 8].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)
522 II. ELEMENTS OF HIDDEN MARKOV MODEL
Hidden Markov Models are beautiful mathematical objects, well fitted to capture the information buried in sequence analysis. We provide an example before formally defining the Hidden Markov Model.
Suppose a person is inside a room behind a curtain, through which he cannot see what is happening. On the other side of the curtain is another person who is performing a coin tossing experiment. The other person will not tell anything about what he is doing exactly; he will only tell the result of each coin flip. Thus a sequence of hidden coin tossing experiments is performed, with observation sequence consisting of a series of heads and tails. An observation sequence for example will be of the form
T
O
O
O
O
O
1 2 3...
=HHTTTHTTH
...
H
Where
H
stands for head andT
stands for tail. We now formally define elements of an HMM.A discrete HMM is a 5 tuple
M
,
Q
,
A
,
B
,
i
, where
is an alphabet consisting of finite set of symbols,}
,...
,
{
q
1q
2q
nQ
is a set of finite states,
]
1
,
0
[
:
Q
Q
A
is a mapping defining theprobability of each transition,
]
1
,
0
[
:
Q
B
is a mapping defining the emissionprobability of each alphabet on each state,
]
1
,
0
[
:
Q
i
is a mapping defining the initial probability of each state,With the conditions
Q
q
(
,
)
1
Q q
q
q
A
Q
q
(
,
)
1
a
a
q
B
1
)
(
Q q
q
i
,In general, given an HMM there are three basic problems:
i. calculating the probability of the string generated by HMM
ii. finding the most probable path
iii. estimating the parameters to maximize the probability There are a number of variations on HMM problems. Few examples are listed below.
1. The number of states and transition probabilities are known, but optimum position of the change points are unknown.
2. The number of states is known, but the transition probabilities are not.
3. The number of states and the architecture are unknown, but sequences of state transitions are known.
When the number of states and its architecture are unknown, a HMM which models the data well is found. In third kind of model, for estimating the parameters to maximize the probability, finding a HMM which models ‘data’ well is a general issue. In this attempt, a HMM with variation of third type is considered and basic problems i) and iii) are addressed.
III. HIDDEN MARKOV MODELS IN BIOLOGICAL SEQUENCE ANALYSIS
Often, biological sequence analysis is an issue of assigning right label on each residue. In gene identification, nucleotides are labeled as exons, introns, or intergenic sequence. In sequence alignment the challenge is to associate residue in a query sequence with homologous residues in a target database sequence. One of the challenges is to determine the topology of the HMM that best fits a sequence of events. The other main principle of the approach presented in this paper is modeling the deoxyribonucleic acid (DNA) sequence and identifying optimality. Computing similarity between sequences is one of the key tasks in biological sequence analysis. Various sequence alignment algorithms have been developed such as the Needleman-Wunsch algorithm [5], Smith-Waterman algorithm [9] or the BLAST algorithm [1]. The outcome of such algorithms is usually a score evaluating the alignment of two sequences. If used as a similarity measure between the sequence under investigation and known failure sequences, failure prediction can be accomplished. One of the advantages of sequence alignment algorithms is that they build on a substitution matrix providing scores for the substitution of symbols.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)
523 IV. MINIMUM MESSAGE LENGTH ESTIMATOR FOR HIDDEN
MARKOV MODEL
An evaluation procedure is used to find the optimal HMM. The method is that of estimating the length of the message or sequence used to construct a best PFA model [7]. The same Minimum message length (MML) procedure is extended to identify best HMM. The expression of MML is given by
)! 1 ( log log log
! )! 1 ( )! (
)! 1 ( !
log 2 2
1
2
1
2
N N M V M
n m m t
t t t
m N
j
m
i ij j j j
j j j
j
j
Where
N
is the number of states in the automata,V
is the number of tokens in the alphabet of arc labels,t
j is the total of the frequencies on the arcs into thej
th state,n
ij the frequency on thei
th arc from thej
th state,m
j is the number of different arcs from thej
th state, andM
is the total number of arcs in the automata.m
j is the number of different arcs on non-delimiter symbols from thej
th state.M
is the total number of arcs on non-delimiter symbols in the automata. Since the logarithms are taken to base 2, the MML is in bits.As an application of the above model MML, a biological sequence is considered for assigning right label on each residue. The main principle of the approach presented here is modeling the deoxyribonucleic acid (DNA) sequence and identifying optimality. The following section provides an insight about the DNA sequence and its modeling.
V. 5SPLICE SITE RECOGNITION
Consider a simple example of imagining the following caricature of a
5
splice site recognition problem. Assume a DNA sequence that begins in an exon, contains5
splice site and ends in an intron. The challenge is to identify where the switch from exon to intron occurred – where the5
splice site is. In general the5
splice site consensus nucleotide is almost always a G. In this attempt a HMM is aimed to fit the DNA sequence and to find the probability of the sequence in that model. The HMM invokes three states, one for each of the three labels assigned to a nucleotide: E (exon), 5 (5
splice site) and I (intron).First, the best automaton governing the above data well is constructed. In this regard a model is designed for the
DNA sequence
CTTCATGTGAAAGCAGACGTAAGTCA...
1
B
M
2
B
M
3
B
M
4
B
M
5
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)
524
6
B
M
The algorithmic technique suggested by Georgeff and Wallace [3], Minimum message length (MML) is here designed to optimize the DNA sequence through the HMM in the following section.
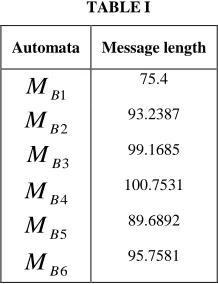
VI. OPTIMIZATION OF HIDDEN MARKOV MODEL Experimental results of the HMM constructed in section V for given sequence are tabulated in Table 1. Minimum message length estimator yields a consistent result in optimization. MML starts with the value and increases gradually for the subsequent data, except for
M
B5. So5
B
M
is the optimum HMM as far as the given data isconsidered
TABLEI
The sequences of exons, splice site and introns have different statistical properties. Consider some simple differences: say that exons have a uniform base composition on average (25%) each base, introns are A/T rich (say, 40% each for A/T, 10% each for C/G), and the
5
splice site consensus nucleotide is almost always a G (say, 95% G and 5% A). Each state of the HMM designed has its own emission probabilities, which model the base composition of exons, introns and the consensus G at the [image:4.612.109.218.408.550.2]5
splice site. Each state also has transition probabilities, the probabilities moving from this state to a new state. The transition probabilities describe the linear order in which the states occur: one or more E’s, one 5, one or more I’s.Fig. 1 Transition and Emission probabilities
M
B5For the above 26-nucleotide sequence, there are 14 possible paths that have non-zero probability, since the
5
splice site must fall on one 14 internal A’s or G’s [10]. As the highest probability of change occurs in case of G, the HMM is modeled based on the same. It can be found that(
)
1
w
P
B
M = 8.6218 х 10
-20
P
MB2(
w
)
= 1.3472 х 10-19
P
MB3(
w
)
= 8.2224 х 10-20
(
)
4
w
P
B
M = 3.2118 х 10
-19
(
)
5
w
P
B
M = 1.2546 х 10
-18
(
)
6
w
P
B
M = 7.6577 х 10
-19
The probability of
w
that is generated byM
B5 is given by 1.2546 х 10-18. The probability of the sequence)
(
w
P
M throughM
B5is observed to be highest. Hence application of this model search technique shows effective result in selecting an optimal model, sayM
B5 as the best optimal HMM.VII. CONCLUSION AND FUTURE WORK
In this paper a new Hidden Markov Model based on MML technique is developed for a DNA sequence. The new HMM identifies optimal number of states for the biological sequence and its probability. Further, the MML estimator presented for optimizing the HMM provides highest probability. It can be studied in future whether this new HMM identified through MML technique could be associated in predicting the failure of anomalous system behavior. In future an investigation can be done to find whether the new HMM suits another sequence of the same family using a pair wise sequence alignment algorithm and score matrix.
Automata Message length
1
B
M
2
B
M
3
B
M
4
B
M
5
B
M
6
B
M
75.4
93.2387
99.1685
100.7531
89.6892
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 8, August 2013)
525 REFERENCES
[1] Altschul, S., Gish, W., Miller, W., Myers, E. and Lipman , D. Basic local alignment search tool, Journal of Molecular Biology, 215 (3), (1990), 403 - 410.
[2] Durbin,R., Eddy, S.R., Krogh, A. and Mitchison, G. Biological sequence analysis: probabilistic models of proteins and nucleic acids, Cambridge University Press, Cambridge, UK, 1998.
[3] Georgeff, M. P. and Wallace, C. S. A General selection criterion for inductive inference, Advances in Artificial Intelligence, North Holland, (1984), 219 - 228.
[4] Murugesan, N., Suguna, P., Muthumani, N. and Antony Selvadoss Thanamani, Hidden Markov Model for System Trend Analysis, Advances in Computational Sciences and Technology, 1(1), (2009), 1 – 10.
[5] Needleman, S.B. and Wunsch, C.D. A general method applicable to the search for similarities in the amino acid sequence of two proteins, Journal of Molecular Biology, 48 (3), (1970), 443 - 453.
[6] Rabiner, L. A tutorial on hidden markov models and selected applications in speech recognition, Proc. IEEE. 77, (1989), 257-286. [7] Raman , A., Andrese, P. and Patrick, J. A Beam Search Algorithm
for PFSA inference, Pattern Analysis and Applications, 1, (1998), 121-129.
[8] Salfner, F. Predicting Failures with Hidden Markov Models, In Proceedings of 5th European Dependable Computing Conference (EDCC-5), Budapest, Hungary, student forum volume, (2005),41– 46.
[9] Smith, T. and Waterman, M. Identification of Common Molecular Subsequences, Journal of Molecular Biology, 147, (1981), 195 - 197. [10] Sean R Eddy, What is a hidden Markov model? Computational
Biology, 22 (10), (October 2004), 1315-1316.