Measuring Semantic Coverage
Sergei Nirenburg, Kavi M a h e s h and S t e p h e n Beale
C o m p u t i n g R e s e a r c h L ~ b o r ~ t o r y N e w M e x i c o St~tte U n i v e r s i t y
bt~s C r u c e s , N M 8 8 0 0 3 - 0 0 0 1
USA
s e r g e i ; m ~ h e s h ; s b { ~ c r l . n m s u . e d u
A b s t r a c t
T h e developlnent of natural language processing systems is currently driven to a large extent by measures of knowledge- base size and coverage of individual phe- n o m e n a relative to a corpus. While these measures have led to significant advances for knowledge-lean applications, they do not adequately m o t i v a t e progress in c o m p u t a t i o n a l semantics leading to the development of large-scale, general pur- pose N L P systems. In this article, we argue t h a t depth of semantic represen- tation is essential for covering a broad range of p h e n o m e n a in the c o m p u t a - tional t r e a t m e n t of language and propose (lepth as an i m p o r t a n t additional dimen- sion for measuring the semantic cover-
age of N L P systems. We propose an
operationalization of this measure and show how to characterize an NLP system along the dimensions of size, corpus cov- erage, and depth. T h e proposed frame- work is illustrated using sever~fl promi- nent N L P systems. We hope the prelim- inary proposals m a d e in this article will lead to prolonged debates in the field and will continue to be refined.
1
M e a s u r e s of Size versus
M e a s u r e s of D e p t h
Evaluation of current and potential performance of' an N L P system or m e t h o d is of crucial impor- tance to researchers, developers and users. Cur- rent performance of systems is directly measured using a variety of tests and techniques. Often, as in the case of machine translation or information extraction, an entire "industry" of evaluation gets developed (see, for example, A R P A M T Evalua- tion; MUC-4 ). Measuring the performance of an N L P m e t h o d , approach or technique (and through it the promise of a s y s t e m based on it) is more dif- ficult, as j u d g m e n t s m u s t be m a d e about " b l a m e assigmnent" and the i m p a c t of improving a variety
of system components on the overall future per- formance. One of the widely accepted measures of potential performance i m p r o v e m e n t is the fea- sibility of scaling up the static knowledge sources of an NLP system its g r a m m a r s , lexicons, worht knowledge bases and other sets of language de- scriptions (the reasoning being that the larger the s y s t e m ' s g r a m m a r s and lexicons, the greater per- centage of input they would be able to m a t c h and, therefore, the better the performance of the systeml). As a result, a system would be con- sidered very promising if its knowledge sources could be significantly scaled up at a reasonable expense. Natm'ally, the expense is lowest if acqui- sition is performed automatically. This consider- ation and the recent resurgence of corpus-based methods heighten the interest in the a u t o m a t i o n
of knowledge acquisition, llowever, we believe
that such acquisition should not 1)e judged solely by the utility of acquired knowledge for ~ partic- ular application.
A preliminary to the sealability estimates is a j u d g m e n t of the current coverage of a s y s t e m ' s
static knowledge sources. Unfortunately, judg-
ments based purely on size ace often mislead- ing. While they m a y be sufficiently straightfor- ward for less km)wledgeAntensive methods used in such applications as information extraction and retrieval, part of speech tagging, bilingual corpus alignment, and so on, the saute is not true about more rule- and knowledge-based methods (such as syntactic parsers, semantic analyzers, seman- tic lexicons, ontological world models, etc.). It ix widely accepted, for instance, t h a t j u d g m e n t s of the coverage of a syntactic g r a m m a r in terms of the number of rules are tlawed. It is s o m e w h a t less self-evident, however, that the number of lex- icon entries or ontology concepts is not an ade- quate measure of the quality or coverage of NLP
a Incidentally, this consideration eontributes to evMuation of current perforntance as well. In the ab- sence of actual evaluation results, it is customary to c|aim the utility of the system by simply mention- ing tit(: size of its knowledge sources (e.g., "over 550 grammar rules, over 50,000 concepts in the ontology and over 100,00(I word senses in the dictionary").
systems. A.n adequate measure of these must ex- amine not only size and its scalability, but also depth of knowledge along with its scalability. In addition, these size and depth measures cannot be generalized over the whole system, but must be directly associated with individual areas t h a t cover the b r e a d t h of N L P problems (i.e. morphol- ogy, word-sense ambiguity, semantic dependency, coreference, discourse, semantic inference, etc.). And finally, the m o s t helpfld m e a s u r e m e n t s will not judge the s y s t e m solely as it stands, but must in some way reflect the u l t i m a t e potential of the system, along with a quantification of how far ad- ditional work aimed at size and depth will bring a b o u t a d v a n c e m e n t toward t h a t potential.
In this article, we a t t e m p t to formulate mea- sures of coverage i m p o r t a n t to the development and evaluation of semantic systems. We proceed h'om the a s s u m p t i o n t h a t coverage is a function of not only the n u m b e r of elements in (i.e., size of) a static knowledge source but also of the a m o u n t of information (i.e., d e p t h ) and the types of in- f o r m a t i o n (i.e., b r e a d t h ) contained in each such element. Static size is often emphasized in evalu- ations with no attention paid to the often very in- significant a m o u n t of information associated with each of the m a n y "labels" or primitive symbols. We snggest a starting framework for measuring size together with other significant dimensions of semantic coverage. In particular, the evalu- ation measures we propose reflect the necessary contribution of the depth and breadth of seman- tic descriptions. D e p t h and b r e a d t h of seman- tic description are essential for progress in com- p u t a t i o n a l semantics and, ultimately, for build- ing large-scale, general purpose N L P systems. Of course, for a n u m b e r of applications a very lim- ited semantic analysis (e.g., in t e r m s of, say, a dozen separate features) m a y be adequate for suf- ficiently high performance. However, in the long run, progress towards the u l t i m a t e goal of NLP is not possible without depth and breadth in seman- tic description and analysis.
There is a well-known belief t h a t it is not ap- propriate to measure success of N L P using field- internal criteria. Its adherents m a i n t a i n t h a t N L P should be evaluated exclusively through evaluating its applications: information retrieval, machine translation, robotic planning, h u m a n - c o m p u t e r interaction, etc. (see, for: example, the Proc. of the Active N L P Workshop; A R P A M T Evaluation). This m a y be true for N L P users, but developers m u s t have internal measures of success. This is because it is very difficult to assign blame for the success or failure of an application on spe- cific components of an N L P system. For exam- ple, in reporting on the MUC-3 evaluation efforts, Lehnert and Sundheim (1991) write:
A wide range of language processing strategies was employed by the top-
scoring systems, indicating t h a t m a n y natnral language-processing techniques provide a viable foundation for sophis- ticated text analysis. Further evaluation is needed to produce a more detailed as- sessment of the relative merits of specific technologies and establish true perfor- mance limits tbr a u t o m a t e d information extraction. [emphasis added.]
Thus,
evaluating the information extraction ap- plication did not provide constructive criticism on particular NLP techniques to enable advances in the state of the art. Also, evaluating an appli- cation does not directly contribute to progress in NLP as such. This is in part because a m a j o r i t y of current and exploratory NLP systems are not complete enough to fit an application but rather are devoted to one or more of a variety of com- ponents of a comprehensive NLP system (static e.g., lexicons, g r a m m a r s , etc.; or dynamic e.g., an algorithm for" treating m e t o n y m y in English).1.1 C u r r e n t M e a s u r e s o f C o v e r a g e
Success in NLP (including semantic analysis and related areas) is currently measured by the follow- ing criteria:
• Size of static knowledge sources: A mere
nmnber indicating the size of a knowledge source does not tell us much about the cover- age of the system, let alone its semantic capa- bilities. For example, m o s t machine readable dictionaries (MRI)) are larger t h a n compu- tational lexicons but they are not usable for: computational semantics.
l ' h e n o m e l)t~.'ired S l a t e
" C . r r e n t S t a t e
iiiii
, , -~ ~ : : . : i " K n o w l e d e Base
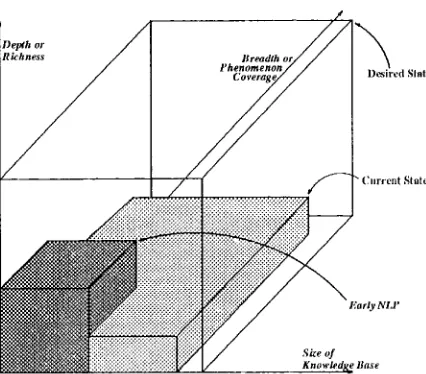
Figure 1: Dimensions of Semantic Coverage: (hlr- rent and Desired l)irections
processing became exponentially expensive as a result.
Figure 1 shows the dimensions of size and b r e a d t h (or phenomenon coverage) along tit(', hor- izontal plane. D e p t h (or richness) of a semantic s y s t e m is shown on the vertical axis. We believe t h a t recent progress in NLP with its emphasis on corpus linguistics and statistic~d m e t h o d s has re- suited in a significant spread akmg the horizontal plane but little been done to grow the Iield in the vertical dimension. Figure 1 also shows the de- sired state of c o m p u t a t i o n a l semantics advmlced alor|g each of the three dimensions shown. If
We proceed from the assumption that high- quality NLI ) systems require o p t i m u m coverage on all three scales, the|| apparently different roads (-an be taken to t h a t target. T h e s p e e t r m n of choices ranges f r o m developing all three dimen- sions more or less simultaneously to taking care
of t h e m in turn. As is often the case in king-
t e r m high-risk enterprises, inany researchers opt to start out with acquisition work which promises s h o r t - t e r m gains on one of the coverage dimen- sions, with little thought a b o u t further steps. Of_ ten the reason they cite can be s u m m a r i z e d by the phrase "Science is the art of the possible." This position is quite defensihle .... if no claims are m a d e a b o u t broad semantic (:overage. Indeed, it is quite legitimate to study a particular lan- guage p h e n o m e n o n exclusively or to cover large chunks of the lexis of a language in a shallow man-
ner. IIowever, for practical gains in large-scale
computational-selnantie applications one needs to achieve results on each of the three dimensions of coverage.
1 . 2 D e s i d e r a t a f o r L a r g e - S c a l e C o l n p u t a t i o n a l S e m a n t i c s
Once the initial knowledge acquisition canq)aign for a I)articular apt)lication has been concluded, the following crucial scalability issues 2 ira|st be addressed, if any t|nderstanding of the longer-term significance of the research is sought:
• domain independence: scalability to n e w (lo-
mains; general-purpose Nl,l )
• language independence: sealability across
languages
• phenolnenon coverage: sealability to new
phenomena; going beyond core semantic analysis; ease of integrating component pro- eesses and resources.
• application-independence: sealability to new applications; toolkit o[' NLP techniques ap- plicable to any t~sk.
We believe that coverage in terms of the det)th and breadth of the knowledge given to an NLI ) system is m a n d a t o r y for attaining the above goals in the long run. Such coverage is best esti(nated not in terms of raw sizes of lexicons or world mod- els but rather through the availability in t h e m of information necessary for the t r e a t m e n t of a w>
riety of l)henomena in natural language issues
related to semantic dependency bull(ling, lexical disambiguation, semantic constraint tracking and relaxation (for the cases of unexpected input, in- cluding non-li~eral language as well as t r e a t m e n t of unknown lexis), reference, p r a g m a t i c i m p a c t and discourse structure. The resolution of these issues is at the core of t)ost-syntactic text process- ing. We believe that one can treat the al)ove phe- n o m e n a only by acquiring a broad range of rele- vant knowledge elements for the system. One nse- flfl measure for sufficiency of infbrmation would be an analysis of kinds of knowledge necessary to gen- erate a text (or (liMog) meaning representation. For applications in which more procedural com- putational semantics is l)refl~'rable, a correspond ing measure of sutliciency should be developed.
There exist other, broader desiderata which are applicable to any All systetn. T h e y include con- cerns about system robustness, correctness, and efficiency which are orthogonal to the above is- sues. EquMly i m p o r t a n t but more broadly appli- cable are considerations of economy and ease of
acquisition of knowledge sources for example,
reducing the size of knowledge bases and sharing knowledge across applications.
2At present, se~dability is considered in the field ahnost exclusively ~ts propagation o[ the nulnber of entries in the NLP knowledge bases, not the quantity and quality of information inside each such entry.
[image:3.596.58.271.111.298.2]2 H o w t o R e a s o n a b o u t D e p t h , B r e a d t h a n d S i z e
A useful measure of semantic coverage must in- volve m e a s u r e m e n t along each of the three dimen- sions with respect to correctness (or success rate) and efficiency (or speed). In this first a t t e m p t at a qualitative metric, we list questions relevant for assigning qualitative ("tendency") scores to an N L P s y s t e m to measure its semantic coverage. Our experience over the years has led us to the following sets of criteria for measuring semantic coverage. Itowever, we understand t h a t the fol- lowing are not complete or unique; they are rep- resentative of the types of issues t h a t are relevant to measuring semantic coverage.
2.1 L e x i c a l C o v e r a g e
• ' l b w h a t extent do entries share semantic primitives (or concepts) to represent word meanings? W h a t is the relation between the n u m b e r of semantic primitives defined and the n u m b e r of word senses covered?
• W h a t is the size of the semantic zones of the entry? tlow m a n y semantic features are cov- ered?
• How m a n y word senses from standard h u m a n - o r i e n t e d dictionaries are covered in the NLP-oriented lexicon entry?
• W h a t types of information are included?
- seleetional restrictions
- constraint relaxation information
syntax-semantics linking - collocations
- procedural a t t a c h m e n t s for contextual processing
-- stylistic p a r a m e t e r s
- aspectual, temporal, m o d a l and attitu- dinal meanings
- o t h e r idiosyncratic information about
the word
• and, finally, the total n u m b e r of entries in the lexicon.
2.2 O n t o l o g i c a l C o v e r a g e
T h e total n u m b e r of primitive labels in a world model is not a useful measure of the semantic cov- erage of a system. At least the following consid- erations m u s t be factored in:
• T h e n u m b e r of properties and links defined for an individual concept
• N u m b e r of types of non-taxonomic relation- ships a m o n g concepts
• Average n u m b e r of links per concept: "con- nectivity"
• T y p e s of knowledge included: defaults, selec- tional constraints, complex events, etc.
• Ratio of number of entries in a lexicon to number of concepts in the ontology
• and, finally, total number of concepts in the ontology.
2.3 M e a s u r i n g B r e a d t h o f M e a n i n g
R e p r e s e n t a t i o n s
A p a r t from lexical and ontological coverage, the depth and breadth of the meaning representations constructed by a system are good indicators of the overall semantic coverage of the system. Tile number of different types of meaning elements in- cluded fl'om the following set provides a reason- able measure of coverage:
• A r g u m e n t structure only
• T e m p l a t e filling only
• Events and participants
• T h e m a t i c role assignments
• T i m e and t e m p o r a l relations
• Aspect
• Properties: attributes of events and objects; relations between events and objects.
• R,eference and coreference
• Attitude, modality, stylistics
• Quantitative, comparative, and other m a t h e - matical relations
* Textual relations and other discourse rela- tions
• Multiple ambiguous interpretations
* Propositional and story/dialog structure
3 M e a s u r i n g S e m a n t i c C o v e r a g e : E x a m p l e s
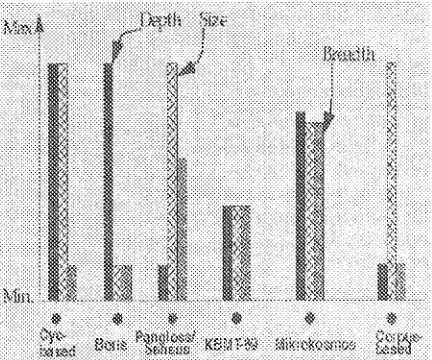
Figure 2 shows the a p p r o x i m a t e position of several well-known approaches and systems (in- cluding a possible Cyc-based system) in the 3- dimensional space of semantic coverage. We have chosen representative systems fl'om the different approaches for lack of precise terms to n a m e tlle approaches.
How do the approaches illustrated in Figure 2 rate with respect to the metrics suggested above'? When estimating their profiles, we thought either about some representative systems belonging to an approach or thought of the properties of a pro- totypical system in a particular p a r a d i g m if no examples presented themselves readily. In the in- terests of space, we consider the above criteria for measuring semantic coverage but only provide brief summaries of how each system or approach is located along the dimensions of depth, b r e a d t h and size.
+
+++++++++{
!!}:
i +
:-+:::+ ::+.
++++++5++ i+~i++++++
+
[image:5.596.57.273.108.288.2]++++++++5+i+i+?+++++++++++5+++++i+++ +++5+i+ ++i +++ ++++++++++i~ + + +ii+i{5++++++51+5~+++++++ ~!:+:: :, +77:+}+ }+++ ++
... ~'ii ... , ... Ix.~,tA ...
i{ {! ii
ii',
:: :: ¢ {
iii{i{5~!{iii!!5 ~:i! 5{ 5! 7!!5 ~ ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: ~ i i { {i{i:!Si{ i
:~:s~;ii~:::::!:!~:!i ~ ~/:i
! ! !i!::?!: !:::::~ :: = :: ~ : ::: :::::::::::::::::: :::::::::::::::::::::::::::::::::::: ~ 5~!:: !:!: ~ :~ ~:! ~s : ~ ~::: ?~:!i.'.,~-: :::: ... :":~ ::: :: ,:
{!~i{~i: ::::: :~::::::::: ::::::::::::~::~:. :::::::::::::::::::::::::::::: ~ ::::::::::::::::::::::::::: 2: :::::!:!::!!!:i: ::::::::::::::::::::::::::::::::::::::::::: ::::::::::::::::::::::::::::::::::::::::::::::::: :, :. :::i:2: ::::!:: ::f? ::::i: :
... I "2; ": ... .~*~ ... : ~ ... ~ ...
?!:5!ii!i!iii!:ili ~iiiiliiii:i:i :i:i:i:i:i:5:!:i:?i:!~ '!!!!!ii . ~ ::::: :::: ::£,~. :::::::::::::::::::::::::
:{::{!{:::i:i::{!;:i:i ~:~:i:i::::i{i:: ii:~!~:i~[::i .::::::::: t,,:xx::::::::::: :::::::::::::::::::::::::
::::::::::~:: :,"~::::::hl :::::::::::::::% :::::::::++::~:::i:i:::::!!: z.. :::::::::::::::::::::::::::
i~ili~}iii::iil)+::i: ~ti{i::~:ii::;:i: ~}:!}i}:.~}!!~i!ii~i} ~ .ilili~ii~iii~i #. ~:i:~:}ii~ v+} } if<
::::::::::::5::::: ;{:::::::::::::::::: ::::::::::::::::::::::: :::::::::: :~::::::::::: qX :::::::::::::::::::::::
a
{ {
+++++++++++++++++++{++t++++++++++++++++~+-:+ +~++++++i~}+++++++i~2~+++;++g~i +++++++++~++i)+ +~;~+i++ii++++)Y + +++ +++ :+~++
:: ::: :::::: ;;.;~ ;;~a::::: ~,<E'I:~ :::: N~i~++:i/~i~: :: :~ 'a::+" *~::i:i:i :;+JlKI ~ +p-'~' ~:~:~9.:~ : :: ~i<~. +.~.~t : :::::
Figure 2: l)imensions of Semantic Coverage: Cur-+ rent att(t l)esired l)ireetions
domain- and task-del)endent, AI-style, schema- based N L P systc'm. It m a y I>e considered an ex- treme e x a m p l e of a system with deep, rich knowl edge of its, rather narrow, worhl in which cowwing language p h e n o m e n a is nee(ted only inasmuch as it supports general reasoning. Boris was able to pro- cess a very smMl n u m b e r of texts sutticiently for
its goMs. T h e coverage of
phenomena was
strictlyutilitarian (which, we believe, is quite appropri- ate). lilt was not demoimtratext t h a t Boris can be scaled up to (:over a signiticant part of the English lexicon.
As an e x a m p l e of an early knowletlge-basetl MT
system (thai, is,
unlike the above, a system whose goals were mainly computational-lit|guistic) we chose the K B M T - 8 9 system ( G o o d m a n and Niren- burg, 1991). It covered its small corpus relatively completely and described the necessary phenom- ena relatively fldly, lilt was a p r i m a r y goal of this line of research to b e g i n m e e t i n g the a b o v e criteria for semantic coverage.A p n t a t i v e NIA ) system based on the
(~yc
project has been selected as a prototyl)e for sys- t e m s not devised h)r a particular application. The Cyc large-scMe knowledge base ]|as significant a m o u n t s of deep knowledge, llowever, it is not clear whether the knowledge is apl>licM)le in a straightff)rward m a n n e r to deal with a range of linguistic phenomena. T h e big question for this kind of s y s t e m is whether it is, in fact, possible, to acquire knowledge without a reference to an intended application.
A purely corpus--based, statisticM approach to N L P , on the other hand, has an extremely nar- row range of knowledge, but, m a y haw; a large
size. For example, snch a system m a y have a
large lexicon with only word frequency and col- location i n f o r m a t i o n in each entry. A l t h o u g h sta- tistical m e t h o d s h a v e been s h o w n to work o n s o m e
problenm and applications, they are typically ap- plied to one or two phenomena at a time. It is not rlear that statistical information acquired tbr one probleln (such as sense disambiguation) is of use in hmtdling other problems (such as processing non-literal expressions).
Mixed-strategy NI,I ~ systems are epitomized by I'angloss (199d), a multi-engine translation sys- t e m in which semantic processing is only one of the possible translation engines. The semantics engine of this system is equipped with a large-size ontology of over 50,000 entries (Knight and link, t99d) which is nsed essentially as an am:hot for mapl)ing lexicM traits front the 8otlrce to the tar.- gel, language. As shown in I,'igure 2, Pangloss has a large size and covers a good range of l)het,)m. em~ as well. llowew',r, there is little information (only taxonomic and partonolnie relationships) in each concept in its Sensus ontology. T h e limited depth constrains the ultimate potentia.1 of the sys- tetn as a sentatd,ic and pragmatic processor. I"or exatnple, there is no hfl'ortnal;ion in its knowledge sources to make judgements about constr~fint re-
laxal,ion
to process non-literal expressions snch as metonymies and metal~hors.The Mikrokosntos
system (e.g.,
Onyshkevychan(t Nirenburg, 1994), has a t t e m p t e d to cover each dimension equally well. Its knowledge bases and text meaning representations are rather deep and of nontrivial sizes. It has been designed froln the start to deal with a comprehensiw; range ot'seman-. tic p h e n o m e n a including the linldng of syntax attd semantics, (-ore semantic analysis, sense disam- l)iguation, I)rocessing non-literM expressions, SLIt({ so on, althongh not all of them have yet been im plemented.
Front the abow'~ examples, it is clea.r t h a t hav- ing good coverage along one or two of the three dimensions is not good enough for meeting the long-term goMs of NI,P. Poor coverage of language p h e n o m e n a (i.e., poor brea, dth) indicates t h a t the acquired knowh;dge, even when it is deep and large in size, m a y not be applicable to other phenom- ena and m a y not transfer to other applications. Poor depth suggests t h a t knowledge and process- ing techniques are either application- or language- specific and limits the ultimate potential of the system in solving semantic problems. Depth and breadth are of course of little use if the system cmmot bc scaled up to a signilicant size. More- over, as already noted, cow;rage in depth, breadth, and size must all be achievetl in conjnnction with maintaining good me, asnres of correctness, et[i- ciency, and robustness.
4
D i s c u s s i o n a n d C o n c l u s i o n s
All oft-quoted objection to having deep semantic (:overage is the dilliculty in scMing up such a sys- t e m along the dimension of size. This is a valid
concern, llowever, the situation (:an be amelio-
rated to a large extent by developing a method- ology (see, e.g., Mahesh and Nirenburg, 1995) for constraining knowledge acquisition to minimally
meet semantic processing needs. Such concen-
tration of effort will allow knowledge acquirers to have spend a fraction of the effort that must go into building a general machine-tractable en- cyclopedia of knowledge and yet to attain signifi- cant coverage of language phenomena. Significant scale-up can be accomplished under such a con- straint without jeopardizing the high values on the depth and breadth scales.
Size is important in NLP. But size alone is not a sufficient metric for evaluating semantic cover- age. Focusing on size to the exclusion of other criteria has biased the field away from semantic solutions to NLP problems. We have made a first step in formulating a more appropriate and com- plete set of measures of semantic coverage. Depth and breadth of knowledge necessary to cover a wide range language phenomena are at least as important to NLP as size. The discussion of pe- culiarities of the various approaches should be ex- panded in at least two directions - greater detail of description and analysis of the relative ditficulty of reaching the set goal of attaining an optimum value on each of the three measurement scales. We hope that this paper will elicit interest in contin- ned discussion of the issues of coverage measure- ment, which, in turn, will lead to better -- quanti- tative as well as qualitative- measures, including a methodology for comparing lexicons and ontolo- gies.
Acknowledgments
Many thanks to Yorick Wilks for his constructive criticism.
R e f e r e n c e s
Active NLP Workshop: Working Notes from the AAAI Spring Symposium "Active NLP: Natural Language Understanding in Integrated Systems" March 21-23, 1994, Stanford University, Califor- nia (Also available as a Technical Report from the American Association for Artificial Intelligence).
AI{PA MT Evaluation: Report of the Advanced Research Projects Agency, Machine Translation Program System Evaluation, May-August 1993.
Goodman, K. and S. Nirenburg (eds.) (1991).
The K B M T Project: A Case Study in Knowledge- Based Machine Translation. San Marco, CA: Morgan Kaufmann.
Knight, K. and Luk, S. K. (1994). Building a Large-Scale Knowledge Base for Machine Trans- lation. In Proc. Twelfth National Conf. on Arti- ficial Intelligence, (AAAI-94).
Leant, D. B. and Guha, R. V. (1990). Building
Large Knowledge-Based Sysiems. Reading, MA: Addison-Wesley.
Lehnert, W. G., Dyer, M. G., Johnson, P. N., Yang, C. J., and Harley, S. (1983). BORIS - An Experiment in In-I)epth Understanding of Narra-
tives. Artificial Intelligence, 20(1):15-62.
Lehnert, W. G. and Sundheim, B. (1991). A performance evaluation of text-analysis technolo-
gies. AI Magazine, 12(3):81-94.
Mahesh, K. and Nirenburg, S. (1995). A situ- ated ontology for practical NLP. In Proceedings of the Workshop on Basic Ontological Issues in Knowledge Sharing, International Joint Confer- ence on Artificial Intelligence (IJCAI-95), Mon- treal, Canada, August 1995.
MUC-4: Proc. Fourth Message Understanding Conference (MUC-4), June 1992. Defense Ad- vanced Research Projects Agency.Morgan Kanf- mann Publishers.
Onyshkevych, B. and Nirenburg, S. (1994). The lexicon in the scheme of KBMT things. Technical Report MCCS-94-277, Computing Research Lab- oratory, New Mexico State University. Also to appear in Machine rlh'anslation.
Pangloss. (1994). The PANGLOSS Mark Ill Machine Translation System. A Joint Technical Report by NMSU CRL, USC ISI and CMU CMT, Jan. 1994.