freq. ref. recall R-prec. MAP P@1 P@5 P@10 P@100
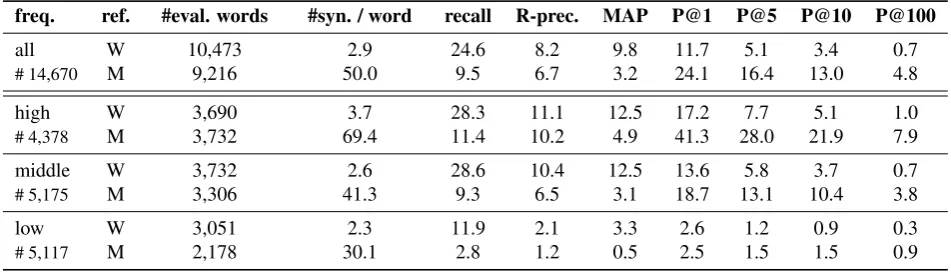
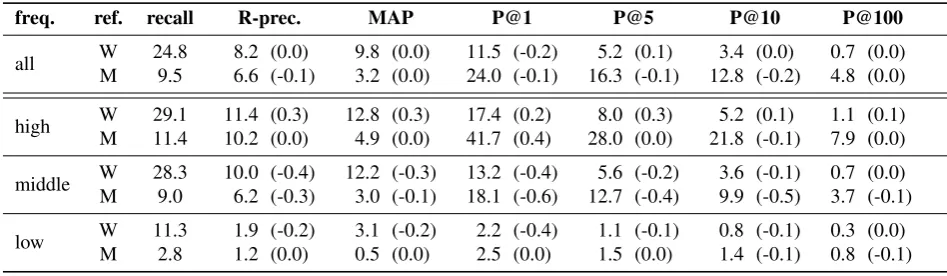
all W 21.0 7.1 (-1.1) 8.4 (-1.4) 10.6 (-1.1) 4.7 (-0.4) 3.1 (-0.3) 0.6 (-0.1)
M 7.8 5.5 (-1.2) 2.5 (-0.7) 21.3 (-2.8) 14.5 (-1.9) 11.3 (-1.7) 4.1 (-0.7)
high W 25.2 10.1 (-1.0) 11.2 (-1.3) 16.4 (-0.8) 7.7 (0.0) 5.0 (-0.1) 1.0 (0.0)
M 10.0 9.0 (-1.2) 4.1 (-0.8) 38.4 (-2.9) 26.1 (-1.9) 20.4 (-1.5) 7.3 (-0.6)
middle W 23.9 8.7 (-1.7) 10.8 (-1.7) 12.1 (-1.5) 5.1 (-0.7) 3.2 (-0.5) 0.6 (-0.1) M 6.6 4.7 (-1.8) 2.1 (-1.0) 14.9 (-3.8) 10.2 (-2.9) 8.0 (-2.4) 2.9 (-0.9)
low W 8.2 1.6 (-0.5) 2.3 (-1.0) 1.9 (-0.7) 0.9 (-0.3) 0.6 (-0.3) 0.2 (-0.1)
M 1.6 0.7 (-0.5) 0.3 (-0.2) 1.5 (-1.0) 1.1 (-0.4) 0.9 (-0.6) 0.5 (-0.4)
Table 3: Evaluation of thesaurus building for single term entries and single/multi-term features and neighbors
nuclear reactor reactor[0.47], nuclear plant[0.35], nuclear power[0.29], research reactor[0.28], nuclear fuel[0.27], atomic reactor[0.24], weapons-grade[0.23], plutonium[0.22], enriched uranium[0.22]. . .
stock exchange stock market[0.32], index [0.30], share price[0.28], bourse[0.28], blue chip[0.27], new york stock ex-change[0.27], share[0.25], trading[0.24], stock[0.24], stock index[0.23]. . .
religious belief religion[0.25], faith[0.22], belief[0.20], religious faith[0.18], freedom of religion[0.17], religious freedom [0.15], viewpoint[0.15], christianity[0.15], constitutional right[0.14]. . .
academic program low density [0.17], step aerobics [0.17], urban studies [0.17], miles-per-gallon [0.16], palisade [0.16], retirement-plan[0.16], alicia alonso[0.16], mutant gene[0.15], graduate program[0.15]. . .
Table 4: First neighbors of some entries of the distributional thesaurus with compounds as entries
6.
Compounds as thesaurus entries
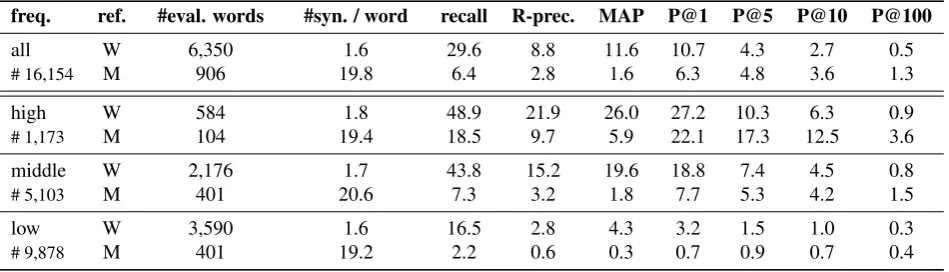
The last part of our study does not take the results for sin-gle terms as reference but focuses specifically on nominal compounds as thesaurus entries. As a consequence, the sets of reference synonyms and similar words are different. Table 5 shows more specifically that WordNet is a signifi-cantly richer reference for nominal compounds than Moby (3rdand 4thcolumns). It also illustrates the fact that nomi-nal compounds have less synonyms and similar words than single terms, probably because they are semantically less ambiguous.
Table 4 provides a qualitative view of this distributional the-saurus of nominal compounds by giving the first neighbors of some of its entries with their similarity value with their entry. The first three rows are illustrative of entries with rather good neighbors while the last row illustrates the fact that results are of course far from being perfect for a
signif-icant number of entries2. Table 4 also shows that the neigh-bors of the compound entries are rather balanced between single terms and compounds.
From a more quantitative viewpoint, although our three ranges of frequencies do not split our vocabulary of nomi-nal compounds into well-balanced sets as for single terms, the results of Table 5 can be soundly compared to those of Table 1 and show two main trends. First, the synonyms of compounds are far easier to find than the synonyms of single terms. This is true in terms of both recall and mea-sures such as R-precision and MAP, which means that these findings are not only explained by the small number of ref-erence synonyms. They probably result from the nature of nominal compounds as lexical units with limited semantic ambiguity. Second, similar words are more difficult to find
2This is not the worst case as the first relevant neighbor,
grad-uate program, appears at the9thposition.
freq. ref. #eval. words #syn. / word recall R-prec. MAP P@1 P@5 P@10 P@100
all W 6,350 1.6 29.6 8.8 11.6 10.7 4.3 2.7 0.5
# 16,154 M 906 19.8 6.4 2.8 1.6 6.3 4.8 3.6 1.3
high W 584 1.8 48.9 21.9 26.0 27.2 10.3 6.3 0.9
# 1,173 M 104 19.4 18.5 9.7 5.9 22.1 17.3 12.5 3.6
middle W 2,176 1.7 43.8 15.2 19.6 18.8 7.4 4.5 0.8
# 5,103 M 401 20.6 7.3 3.2 1.8 7.7 5.3 4.2 1.5
low W 3,590 1.6 16.5 2.8 4.3 3.2 1.5 1.0 0.3
# 9,878 M 401 19.2 2.2 0.6 0.3 0.7 0.9 0.7 0.4
dif-Joint Conference on Lexical and Computational Seman-tics, pages 255–265, Atlanta, GA.
Silberztein, M. (1999). Les groupes nominaux productions et les noms composés lexicalisés. Linguisticæ Investiga-tiones, 27(2):405–426.
van der Plas, L. (2008). Automatic lexico-semantic acqui-sition for question answering. Ph.D. thesis, University of Groningen.