SOURCE CODE OBFUSCATION BY MEAN
OF EVOLUTIONARY ALGORITHMS
Sébastien Martinez
2011
Tutor: Sébastien Varrette Advisor: Benoît Bertholon University of Luxembourg,
Faculty of Sciences, Technologies and Communications
Master Informatique Spécialité Recherche en Informatique
2 RELATED WORK
1
Introduction
Usually, when talking about security, the matter is about protecting a computer from intrusions or mali-cious software. Here, the matter will be about how to protect software from piracy. More precisely, how to make a program able to run without letting the user know its composition. To achieve this goal, distribut-ing binaries instead of source code is not enough since debuggers and decompilers can be used to help get the secret algorithm or data structure one does not want to be known by the user. The solution would be having code that is impossible to understand for the user, but since this goal cannot be reached, the code will have to be complicated enough so that users want-ing to get secret algorithms will either give up, either obtain the algorithm when it is obsolete (e.g. when a new, better version is available). The techniques used for this purpose are calledObfuscation techniques
There are several reasons why someone would want to obfuscate his or her code. The most common reason would be to hide an algorithm from eavesdrop-pers while executing the code on an unsecured plat-formi.e.a public cloud. Code obfuscation is not only used to keep some pieces of code secret, it can as well be used to introduce a fingerprint into the software for each user allowing the detection of the user of a spe-cific version of the code. For example, one would want to make special copy of his or her software for each person he or she distributes the software to. Hence, if illegal copies of the software are found it would be easy to trace the person who distributed the pirated copies.
Since there are no easy ways to find the best trans-formations for a given program, we will study the pos-sibility of using evolutionary algorithms to find the best obfuscated program accordingly to the criterion we give in this article.
On a first step, a short overview of evolutionary al-gorithms and of the source to source compiler PIPS will be given before listing several software complex-ity metrics that can be used to measure obfuscation transformations efficiency. Then, obfuscation tech-niques will be classified based on the parts of the pro-gram they affect. Before summarizing the obfuscation metrics, the matter of deobfuscators will be tackled. Eventually, we will detail how the use of evolutionary algorithm is planned for finding best obfuscated pro-grams.
2
Related Work
2.1
Evolutionnary Algorithm
Evolutionary Algorithm (EA) is a class of solving tech-niques based on the Darwinian theory of evolution [8] which involves the search of apopulation Xt of
lutions. Members of the population are feasible so-lutions and called individuals. Each iteration of an EA involves a competitive selection that weeds out poor solutions through theevaluationof a fitness value that indicates the quality of the individual as a solu-tion to the problem. The evolusolu-tionary process involves at each generation a set of stochastic operators that are applied on the individuals, typically recombina-tion (or cross-over) and mutarecombina-tion. There exists many useful models of Evolutionary Algorithms (EAs) yet a pseudo-code of a general execution scheme is pro-vided in the Algorithm 1.
Algorithm 1:General scheme of an EA in pseudo-code.
t:= 0;
Generation(Xt)// generate the initial population Evaluation(Xt)// evaluate population
whileStopping criteria not satisfieddo
ˆ
Xt= ParentsSelection(Xt);// select parents
Xt′= Modification(Xˆt);// cross-over + mutation Evaluation(Xt′)// evaluate offspring
Xt+1= Selection(Xt,Xt′)// select survivors for the
next generation
t:=t+ 1;
Execution of simple EA requires high computational resources in case of non-trivial problems. It might be encountered when dealing with large individuals (e.g. in case of Genetic Algorithm (GA) — long se-quences of genes, in case of Genetic Programming (GP) — large parse trees) and/or large populations. This influences time required to evaluate the popula-tion, which usually is the costliest operation in EAs. In such cases, time-to-solution on a single computer is prohibitively long for practitioners (especially with us-age of GP). Such example of highly expensive EA for a computer vision problem is described in [13], where more than 24h are required to execute the algorithm. Another instance of even bigger requirements was re-ported by Melabet al.in [12], where predictive math-ematical model for the concentration of sugar in beets was constructed using parallel GA — cumulative CPU
2.2 PIPS - source code compiler 3 TAXONOMY OF OBFUSCATION METHODS
time exceeded 27 days.
2.2
PIPS - source code compiler
PIPS (Parallélisation Interprocédurale de Pro-grammes Scientifiques) [9], [1] is an interprocedural source to source compiler analyzing C and Fortran programs and transforming them to optimize parallel executions of these programs. PIPS can apply transformations that can be used to obfuscate the input code like loop unrolling or variable renaming. Moreover, PIPS can use SIMD instructions to accel-erate a program by means of vectorial instructions. SIMD introduces calls to intrinsics that can be hard to understand for programmers who don’t know them.
Using PIPS as a tool for operating transformations on programs, we gain a powerful tool for code obfus-cation. The python frontendpyps allows the user to specify transformations to be applied or specific data structures to be used. In the list of transformations mentioned in this article, several are already available in PIPS.
3
Taxonomy of Obfuscation
Methods
Obfuscation methods can take many forms, and can affect many parts of a program : the data structures used, the functions called or even the textual repre-sentation of the source code (e.g. Suppressing any indentation).
Colberg and Nagra proposed to use this fact to wa-termark or birthmark program [7], the mark being in-serted using some transformations applied to the pro-gram.
When obfuscating a program, some dead code is often inserted. If instead some special code making the program behave in an unwanted way by the user is inserted, we could tamperproof the program. Any re-verse engineer would face side effects if he executed these pieces of ”dead” code.
In this article, we will focus on the usage of transfor-mation to obfuscate the program. Although the trans-formations used for watermarking or tamperproofing are similar to the one that will be listed is this section. On a first step, the definition of a obfuscating trans-formation and of a transtrans-formation quality will be given. Then some complexity software metric will be enumer-ated before giving a non exhaustive list of obfuscation
transformations based on the work of Colberg et al. [7], [5]. Then, before summing up the transformation qualities, the subject of deobfuscator will be tackled.
3.1
Preliminary definitions
In order to classify and evaluate obfuscation transfor-mations, we will need to define several notions. Definition 1(Obfuscating Transformation). LetP −→τ P′ be a transformation of a source programP into a targetP′.
P −→τ P′is anobfuscation transformationifP and
P′ have the same observable behavior. More pre-cisely, the following conditions are respected :
• IfP fails to terminate or terminate with an error condition, thenP′may or may not terminate • Otherwise P′ must terminate and produce the
same output asP
Observable behavior can be defined as being the behavior experienced by the user. This means every-thing the user can notice at first sight. Hence, if P′
has side effects (new created files, network communi-cations ...) that are not noticed by the user, it can still have the same observable behavior (provided it has the same user experienced effects asP).
In order to evaluate the quality of obfuscation trans-formations, we need to define several transformation properties and metrics. The three main properties be-ingPotency,ResilienceandCost.
Potency can be considered as a measure of a trans-formation usefulness in its task of hiding the intent of the program coder. Potency can be seen as a mea-sure of an obfuscation transformation efficiency to-ward human readers. Resilience can be seen as a measure of an obfuscation transformation efficiency toward automatic deobfuscators (as an opposition to potency) Transformation cost measures the penalty introduced by the transformation : a transformation can make the program use more memory or more time. These three measures compose the quality of a transformation.
Definition 2 (Transformation Potency). Let τ be a behavior-conserving transformation, such that P −→τ P′ transforms a source programP into a target pro-gramP′. LetE(P)be the complexity ofP. τpot(P), thepotencyofτwith respect to a programPis a mea-sure of the extent to whichτ changes the complexity ofP. It is defined as
3.2 Metrics 3 TAXONOMY OF OBFUSCATION METHODS
τpot(P) =E(P′)/E(P)−1
We say τ is a potent obfuscating transformationif
τpot(P)>0.
In this definitionEa measure of complexity. Since there are many software complexity measures, one has to be chosen. Several metrics will be listed in the next subsection.
Software complexity metrics are often subjective and some transformation will increase the program complexity according to the metric in use while the de-obfuscation of these transformations are really simple for a machine though uneasy for a human reader as we will see further. Hence, potency can be pictured as a measure of a transformation usefulness toward human readers.
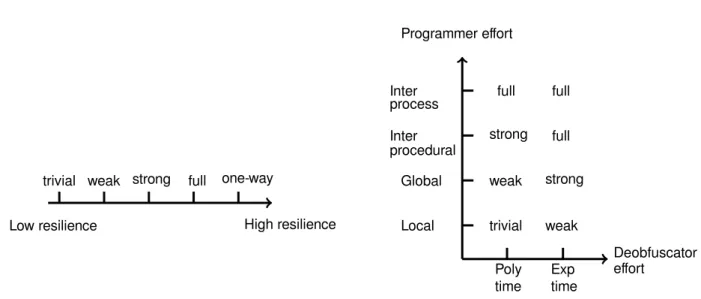
To measure a transformation usefulness toward automatic deobfuscators, resilience has to be intro-duced. Resilience takes two parameters in consider-ation : Programmer Effort (the amount of time taken to build an automatic deobfuscator that will efficiently reduce the potency ofτ) andDeobfuscator Effort(the execution time and the memory space required by the obfuscator to reduce efficiently the potency ofτ). Definition 3(Transformation Resilience). Letτ be a behavior-conserving transformation, such that P −→τ P′ transforms a source programP into a target pro-gramP′.τres(P)is theresilienceofτwith respect to a programP.
τres(P) =one-wayif information is removed from
P such thatP cannot be reconstructed fromP′. Oth-erwise,
τres =Res(τDeobf uscatoref f ort, τP rogrammeref f ort) WhereRes, the Resilience is the function defined by the matrix defined in the matrix in Figure 1
Transformations often introduce some loss in the program. The program can need more memory space or more time to terminate after the application of a transformation. Transformation cost introduces this notion.
Definition 4 (Transformation Cost). Let τ be a behavior-conserving transformation, such that P −→τ P′ transforms a source programP into a target pro-gramP′. τcost(P)is the extra execution time/space ofP′compared toP.
τcost(P)is
dear if executingP′ requiresexponentiallymore re-sources thanP
costly if executingP′ requiresO(np), p > 1, more resources thanP
cheap if executingP′requiresO(n)more resources thanP
free if executing P′ requires O(1) more resources thanP
Potency, resilience and cost compose the quality metric of obfuscating transformations.
Definition 5 (Transformation quality). τqual(P), the quality of a transformation τ, is defined as the com-bination of the potency, resilience, and cost ofτ
τqual(P) = (τpot(P), τres(P), τcost(P))
Now that obfuscating transformations and transfor-mation quality have been defined, several software complexity metrics will be tackled. Combining these notions will enable the evaluation of the different ob-fuscation transformations that will be listed further in this article.
3.2
Metrics
Software complexity doesn’t have one metric, soft-ware complexity because the complexity of a program can have many aspects, many of them being sub-jective. Moreover, complexity metrics depend on the language we use, more precisely on its paradigm. Hence, we have to chose the most adapted metric to our context. Since we want to classify and compare obfuscation transformation, we will have to consider several metrics depending on the transformation and the elements it affects.
McCabe proposes a graph theory oriented metric [11] in which the control flow of programs is seen as graphs. Here, a program complexity is measured by the number of linearly independent paths which is equal toe−n+pin strongly connected graphs (e be-ing the number of edges,nthe number of vertices and
pthe number of connected components of the graph). Control flows of programs being assumed to have a strongly connected structure, we can see how adding more independent paths in a program can increase its complexity.
Chidamber and Kemerer listed several metrics for object oriented programs [4] like giving weight to classes, measuring coupling between classes (i.e. evaluating the interactions between classes) or the
3.3 Obfuscation Techniques 3 TAXONOMY OF OBFUSCATION METHODS .. Low resilience . High resilience . trivial . weak . strong . full . one-way . Poly . time . Exp . time . Inter . process . Inter . procedural . Global . Local . full . full . full . strong . strong . weak . weak . trivial . Programmer effort . Deobfuscator . effort
Figure 1: Resilience of obfuscating transformations : Scale of values (left) and resilience matrix (right)
lack of cohesion in methods (i.e. measure the similar-ity between two methods counting the instance vari-ables used in common). When not using object ori-ented program, some parallel lines can be drawn with data structures (e.g. Measuring global variable or data structures used by several functions, evaluation inter-actions between variables ...).
Colberg et al. referenced the most popular software complexity metrics [5]. Each of them will be writtenµn
in the following and will determine a specific metric applying on functions, data or the whole program.
µ1Program Length : The morePhas operators and operands, the more complex it gets.
µ2Cyclomatic Complexity : The complexity of a function is measured by the number of predicates it contains.
µ3Nesting Complexity : The more conditionals of a function are nested, the more complex that func-tion is.
µ4Data Flow Complexity : The complexity of a function increases with the number of variables references in inter-basic blocks.
µ5Fan-in/out Complexity : A function is more plex if it has more formal parameters, its com-plexity also increases with number of global data structures it reads or writes.
µ6Data Structure Complexity : The complexity of a program increases with the complexity of the static data structure it uses. Scalar variable have a constant complexity. Arrays complexity in-creases with their number of dimension and the complexity of their element type.
3.3
Obfuscation Techniques
Based on the metrics previously enumerated, a first way to obfuscate a program would be to increase the complexity of its data structures and of its functions. But in this section we will see that the best efficiency is accessible when combining theses types of trans-formation and when mixing variable and functions us-ages in order to make the control flow more complex. The notion of opaque construct will also be introduced. Obfuscation techniques can be classified in three categories based on the parts of the program it affects. The three main classes are layout obfuscation, data obfuscation and control obfuscation.
3.3.1 Data obfuscation
Data obfuscation gathers all the transformations that obscur the data structures used in a program. For ex-ample, splitting a vector in two vectors is a data ob-fuscation technique. We can distinguish three classes of transformations : transformations affecting the stor-age, the encoding, the ordering or the aggregation of the data.
3.3 Obfuscation Techniques 3 TAXONOMY OF OBFUSCATION METHODS
When choosing data structures, the most adapted way for storing or encoding the data is usually chosen. For example, when coding a 16 bit int, we represent the value 6 by0000000000000110, respecting con-ventions. We could decide not to respect conventions and decide that the previous bit pattern would code the value 4.
Changing encoding
A typical example of encoding transformation would be to use more than one variable to encode one value. For instance, if we want to transform the variablekin
P, we can use constants and usec1∗k+c2instead ofkinP′. There is a trade-off between resilience and potency and between resilience and cost. The previ-ous example has a little impact on the execution time ofP′but common compiler analysis can deobfuscate such a transformation. P int k; for (k=1;k<100;k++) { ... vect[k] ... } P′(c1= 5c2= 2) int k; for (k=7;k<502;k++) { ... vect[(k-2)/5] ... k+=4; } Promoting variables
Promotinga variable means replacing a specialized storage structure by a more general one. For example, in a language such as Java, an integer typed variable can be replaced by an Integer class. Such transfor-mation usually has a low resilience and potency but can be more effective when used in conjunction with other transformations.
The variable promotion could also be an increasing of its lifetime, like making a local variable be global. Such a transformation increases the number of global variable used by the program functions.
P void foo() { int i; ... i ... } void bar() { int k; ... k ... } P′ int c; void foo() { ... c ... } void bar() { ... c ... } Splitting variables
Splittinga variableimeans replacing it by a set of
variables(i1, ...ik). Three pieces of information have
to be given : a function f(i1, ..., ik) that maps the
i1, ..., ik toi, a functiong(i)that mapsi to the
cor-respondingi1, ..., ikand operations oni1, ..., ik
corre-sponding to the operations available oni.
The potency and cost of such transformations in-creases with k, hence this transformation is usually applied fork= 2or3.
Converting static data to procedural data These transformations replace static data by a func-tion that returns this data. Many pieces of data can be replaced by a function taking one parameter and re-turning one of these pieces of data depending on the given parameter. Since storing all the static data in one function is not desirable at all, we can split this function into many functions spared in the program control flow. P ... ... "abc" ... ... ... "dfe" ... P′ string foo(int a) { if (a == 0) return "abc" elif (a == 1) return "dfe" } ... ... foo(0) ... ... ... foo(1) ... Aggregation Transformations
The same way splitting data obfuscate the code, aggregating data adds obscurity to the code. One could merge several variable in one. For example, a 64-bit integer could store two 32-bits integers. Or a k-size array could store k variables sharing the same type. These transformations have low resilience since a deobfuscator only needs to study the operations on the aggregated data. Still, we can insert fake opera-tions in blocks of dead code.
One would also restructure arrays : merging sev-eral arrays in one, splitting an array into sevsev-eral arrays, folding an array (increasing its dimension) or flattening an array (decreasing its dimension).
These transformations often have low potency be-cause complexity metrics cannot measure the fact that some of these transformations introduce new
struc-3.3 Obfuscation Techniques 3 TAXONOMY OF OBFUSCATION METHODS
tures. For example, a programmer manipulating an image would declare a 2 dimension array. Manipulat-ing a one dimension array or a 3 or more dimension array would increase the obscurity significantly of the program.
Ordering transformations
Randomizing the order of declarations is generally a good idea. That being the ordering of data in arrays or the order of function definition. In the example below we reordered the data inAusing a functionf.
P A[100]; for (i=1,i<100,i++) { ... A[i] ... } P′ A[100]; for (i=1,i<100,i++) { ... A[f(i)] ... } 3.3.2 Layout obfuscation
Layout obfuscation gathers all the transformations that change the information included in the code formating. For example, scrambling identifier names or the code indentation are layout obfuscation techniques.
Layout transformations often areone-wayandfree while their potency may vary depending on the trans-formation.
3.3.3 Control obfuscation
Control obfuscation obscures the program control-flow. Control transformation may affect the aggre-gation, ordering or computations of the control flow. Control aggregation transformation sparse tions that should stay grouped and groups computa-tions that have nothing in common. Control ordering transformations randomize the order of instructions and computations transformations insert new code or change the algorithms employed in the program.
Applying control obfuscation technique often im-plies slowing down the program. The programmer will have to chose between the highly efficient programP
he intends to distribute and its highly obfuscated, but slower alternativeP′.
Opaque predicates
Opaque constructs are predicates or variables that have priority known by the obfuscator but are hard for the deobfuscator to guess. There is a link between the resilience and the cost of an opaque construct and the cost and resilience of the transformation that uses it.
Resilience and cost of an opaque construct are mea-sured using the same scale as obfuscating transfor-mations.
Definition 6 (Opaque constructs). A variable V is opaqueat a pointpin a program ifV has a property
qatpthat is known at obfuscation time. We writeVq p A predicateP is opaque at a pointpin a program if its value (True or False) is known at obfuscation time. We writePpT ifP is True atp,PpF ifP is False atp
andPp?ifP is sometimes True and sometimes False atp.
An opaque construct is said to betrivial if a deob-fuscator can deduce its value by static local analysis and is said to be weak if a static global analysis is required to deduce its value.
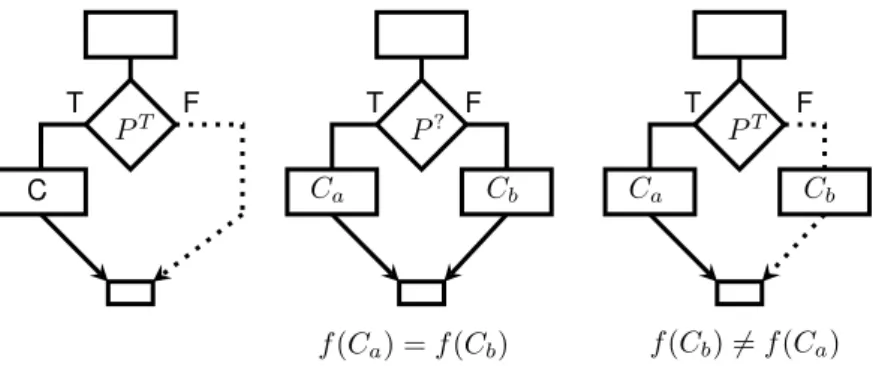
Inserting dead code
Using opaque predicates enables the insertion of irrelevant code, A block of instructions can be put in anif condition of an opaque predicatePT and some
dead code (ie : code with no actual effect but still hard to understand) could be inserted in theelse case of that condition. Another usage of dead code insertion is using aP?opaque predicate and insert two version of the same code in theif and theelsecondition. Then, the version of the code that is run is determined at runtime, and the deobfuscator could take some time to understand the two versions actually have the same effect. We could also use aPT opaque construct and
two versions of the same codeSaif true andSbif false,
but theSbversion would have some bugs in it (see 2).
Extending loop conditions
We can use opaque predicate to make loop termi-nation conditions more complex without changing the number of iteration. For example, we could replace a conditionCbyC&&PT.
Converting a reducible flow graph to a non-reducible one
Usinggotoscombined with opaque predicates, we can make unused skips in the programm that will make the flow graph unreducible and force the deob-fuscator to make an equivalent of the program which flow graph it can reduce. Since gotos introduce rup-tures in a program’s control flow, deobfuscators canot easily reduce control flow that use many of them.
Adding Redundant Operands
Provided result accuracy is not of high impor-tance, we can use opaque variables to add redundant
3.3 Obfuscation Techniques 3 TAXONOMY OF OBFUSCATION METHODS . ... PT . T . F . . P? . T . F . PT . T . F .. C . Ca . Cb . Ca . Cb . f(Ca) =f(Cb) . f(Cb)̸=f(Ca) ..
Figure 2: Dead code insertion and opaque predicates
operands, increasing the program potency.
P x=x+y; z=w+1; P′withR=1, P=2Q, Q=P/2 x=x+y*R; z=w+(P/Q)/2; Parallelizing code
Parallel programs are not as easy to understand as non parallel ones. Since there is nowadays plenty of tools for parallelism, we can use them to obscure the program control flow. We could create useless threads that would appear to do real work or we could run several independent tasks of the control flow at the same time. Of course, if the computer that runs the program cannot run more than one process at a time, theses transformation will slow down the program. But our goal here is to obfuscate our program, any actual acceleration of our program would be a side effect.
When coding, a programmer would group some pieces of code that have common points, write func-tions ... Making the code more understandable and easier to maintain. The next transformation will be ag-gregation transformations that inline or outline code, unroll loops or interleave functions.
Inlining or outlining functions
Inlining a function implies replacing calls to a func-tion by the funcfunc-tion code. Inlining is a one-way re-silient transformation, it remove every abstraction set by the presence of the function.
Outlining instructions in a function means making a functions that runs theses instructions. One use of outlining for obfuscation is to outline parts of seman-tically different procedures in a same function. (see 3). P l1; l2; ... lk; m1; m2; ... mk; P′ <typeA> foo(<args>){ lk-1; lk; m1; m2; } l1; ... lk-2; foo(<args>) m3; ... mk; Interleaving functions
Interleaving functions means merging two (or more) functions in one, merging body, arguments and re-turned results. The resulted function would take an-other argument that tells the instructions whose initial functions has to be run.
Detecting function interleaving is really difficult for reverse engineers since it scrambles the semantics of the functions that were interleaved.
Cloning functions
For a given function, one writes several functions that have the exact same role and obfuscate each one a different way. Then, each time the function is to be called, the programmer would call one of its clones instead.
Since the context of function calls are used to un-derstand the function purpose and since the body of the function is obfuscated, this transformation makes the understanding of the function more difficult.
3.4 Deobfuscation 3 TAXONOMY OF OBFUSCATION METHODS
Loop transformations
Three loop transformations can be enumerated : loop blocking, loop unrolling and loop fission. For each of these transformations, an example is given in figure 3.
Loop blocking means partitioning the loop iteration space in smaller loops. This transformation is usually used to make sure the data used in the loop are kept in the CPU cache.
Loop unrolling means replicating a loop body sev-eral times in order to reduce the number of iterations of the loop. This transformation is often used as a pre-liminary to the parallelization of the loop.
Loop fission is a transformation that expands a loop with a compounded body into several loops with the same iteration space.
Independently, these transformations have a fairly good potency but have a very low resilience since in most cases, static analysis can counter these trans-formations. But when these transformations are used together, the program resilience skyrockets.
Programmer’s preference is to increase their code locality, making them more understandable. When obfuscating a program, we will want to mix pieces of the code (e.g. declarations of functions, of vari-ables). Such transformations have low potency since they don’t obscure the code that much. However, their resilience is one-way in most cases since once the transformation is applied, there is no information about the original order of the mixed pieces.
When applying aggregation transformation, one would pay attention to the order according to which the transformations are applied. For example inlining several functions and outlining a block of the resulting code (making sure the outlined block includes instruc-tions from the inlined funcinstruc-tions) will be more efficient than outlining a block of code with the same monolithic semantic.
building high resilience opaque constructs Predicate such as23̸= 42havetrivialorweak re-silience. Since the resilience of an opaque construct influences the quality of the transformation that uses it, one would like to have high resilience opaque con-structs. There are severals methods for building re-silient and cheap opaque constructs ([6]).
One first method is to use aliasing. Trying to deduce
properties from pointers is difficult since they refer to different memory spaces during the program execu-tion. An example of opaque predicate based on alias-ing could be*i==*j(the pointers i and j are referring to the same memory space).
Another method would be to take advantage of par-allel processing of variable. A variable (or a pointer) modified by many threads would make a highly re-silient opaque variable as it would be very difficult and time consuming to analyse statically. For example, there isn!way to executenparallel instructions.
3.4
Deobfuscation
A deobfusactor takes a program P and simplifies it, removing useless control and data flow. The three main actions are : eliminating dead code determin-ing whether a block of code will be reached or not, eliminating irrelevant variables determining whether the value of a variable is relevant further in the code from a given point and removing aliasing. If in theory, code obfuscation seems inefficient, there is nowadays no actual easy way to deobfuscate a program.
Appel ([2]) tackled the matter of a white box obfus-cation of a programP. This means that the obfuscat-ing programF is perfectly known to the public, but it uses a key K, kept secret, to obfuscateP, thus we have : P′ =F(P, K).
KnowingFthe task of the deobfuscator is NP-easy : the deobfuscator would run the following steps :
• Guess a source programS
• Guess a keyK
• ComputeP′=F(S, K) • CheckP =P′
Therefore white box deobfuscation is NP-easy, but this doesn’t lead to really useful deobfuscation pro-grams. As we saw previously, some transformations areone-way and many deobfuscators don’t take the risk to invert such transformations. And when they do, failure is very usual.
Barak et al. tackled the matter of black box obfusca-tion ([3]). Thevirtual black boxproperty stipulates that ”Anything that can be efficiently computed formO(P) can be efficiently computed given oracle access toP. Building a special set of unobfuscable functions, Barak et al. proved that black box obfuscation is not
3.4 Deobfuscation 3 TAXONOMY OF OBFUSCATION METHODS P for (i=1,i<=n,i++); for(j=1,j<=n,j++) a[i,j]=b[j,i]; P′(loop blocking) for (I=1,I<=n,I+=64) for(J=1,J<=n,J+=64) for(i=I,i<=min(I+63,n),i++) for(j=J,j<=min(J+63,n),j++) a[i,j]=b[j,i]; P for (i=2,i<(n-1),i++) a[i] += a[i-1]*a[i+1]; P′(loop unrolling) for(i=2,i<(n-2),i+=2){ a[i] += a[i-1]*a[i+1]; a[i+1] += a[i]*a[i+2]; } if (((n-2) % 2) == 1) a[n-1]+= a[n-2]*a[n]; P for(i=1,i<n,i++){ a[i] += c; x[i+i]=d+x[i+1]*a[i]; } P′(loop fission) for(i=1,i<n,i++) a[i] += c; for(i=1,i<n,i++) x[i+i]=d+x[i+1]*a[i];
Figure 3: Loop transformations (from top to bottom): Loop blocking, loop unrolling and loop fission
possible, even when using approximate obfuscators (meaning thatP′ has a certain probability to give the same result asP).
A major function of a deobfuscator is to eliminate bogus code that were inserted using opaque predi-cates. It is easier for a deobfuscator to identify and evaluate local opaque construct rather than global ones. Colberg et al. [5] listed several techniques to boost a code’s resilience towards automatic deobfus-cators.
If a transformation can be easily reversed by a de-obfuscator, we can introduce bogus code based on that transformation, making reversing less obvious. Since some deobfuscators use pattern matching to identify opaque predicate, one can use the same syn-tax used for the real code for opaque constructs. One could also exploit the flaw in slicing techniques for
deobfuscation like introducing aliasing or adding use-less variable dependencies, making it harder to iden-tify sliceable blocks.
Several deobfuscators use program slicing [14] to reduce the deobfuscation problem into several smaller problems. Usually, adding aliasing of extending vari-able dependencies make it harder to slice a program. When using static analysis, a deobfuscator can as-sume a construct to be opaque. But to prove it, the reverse engineer will have to make a mutant version
P1of the programPwhere the assumed opaque con-struct is set to its assumed value. IfPandP1give the same outputs for the same inputs then the assumption was right. Since choosing the correct input values set will be long and difficult (all the paths in the program have to be covered), we would prefer to useP? pred-icate or use interleaved predpred-icate that would have to be solved together at the same time.
6 CONCLUSION
force the deobfuscator to prove complex theorem in order to crack an opaque predicate. In theory, code obfuscation is impossible as it was proved, since its deobfuscation is possible. In reality, exploiting flaws of automatic obfuscators can make a program obfus-cation be hard enough to crack so that a new version of the program can be computed and obfuscated.
4
Summary of the
obfusca-tion metrics
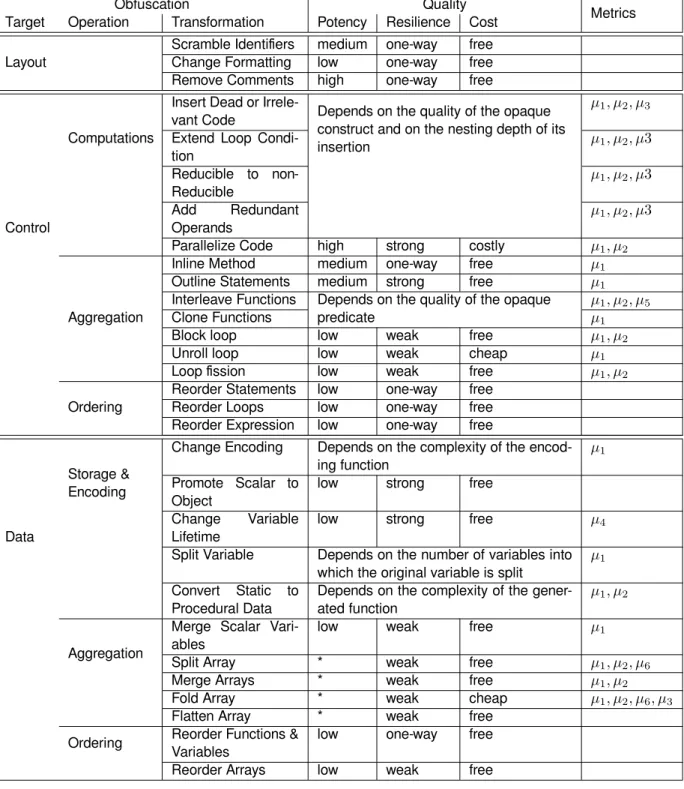
The obfuscation transformation previously listed have been classified by quality by Colberg in his paper [5]. The table 1 summarizes his work.
Transformations are classified by target and oper-ation. The quality of each transformation is exposed and the metric(s) used to measure the transformations potency is(are) enumerated according to the notations used sooner in this article.
As seen previously, layout transformations offer high resilience for a free cost whereas their potency may vary. Loop transformations have a very low cost but also have a low potency and resilience. Paral-lelizing code offers strong potency and resilience but is also costly. On several cases, the transformation quality depends on the quality of opaque constructs or complexity of a data structure or function.
5
Planned use of EA for
ob-fuscation
As in a compiler, choosing transformations to apply and ordering them is a complex task that can take a long time. In common compilers the transformations and their order are fixed according to an average of good performance.
Guelton and Varrette combined the source to source compiler PIPS with evolutionary algorithms ([10]) to seek the best combination of optimization transformations for a given program. Since PIPS uses configuration files to specify the nature, order and lo-calization of the transformations it applies, the EA can manipulate text based files instead of binaries. Each individual being represented by a set of configuration files that leads to a binary that will be compared to other individuals’ binary.
Comparing the results brought by the evolutionary approach (compared to a complete approach and a glutton approach), they found that the evolutionary proach gave an optimal result like the complete ap-proach in times comparable to the glutton apap-proach that was unable to give an optimal result.
Since code obfuscation is a matter of transforma-tions applied in a particular order, we can think of a use of evolutionary algorithm to find the optimal sequence of transformations to apply on a program. Moreover, we could use distributed Evolutionary Al-gorithm (dEA) to deal with obfuscation problem that would be particular long to solve.
6
Conclusion
Software obfuscation have many applications, not only being that of protecting a program’s secrets (pow-erful algorithm, extremely efficient data structure ...) but also, birthmarking, watermarking or even tamper-proofing.
Like software compilation, program obfuscation is a matter of transformation that have to be applied in a correct order to provide an optimal result, transforma-tions having different potency and resilience depend-ing on the other transformations they are combined with. Trying each combination, though guaranteeing the finding of an optimal configuration, can take a very long time. That’s why the use of evolutionary algo-rithms and dEA can be a good idea for this matter.
Since software complexity doesn’t have one single metric, the evaluation of the quality of an obfuscation transformation is not simple. Some transformations can be me more or less efficient on different programs and on different programming languages. Moreover, some transformations may not be available (or just be useless) in some languages.
Although it has been proved that, in theory, program obfuscation is impossible and inefficient, whether a black box obfuscator or a white box obfuscator is used, today’s deobfuscator have many flaws than can be exploited and deobfuscating a program is still long enough to slow down reverse engineers. Hence, it is possible to protect a program secret by obfuscating it while developing a new version, making the crack-ing of the last program pointless when the new one is available.
6 CONCLUSION
Obfuscation Quality
Metrics Target Operation Transformation Potency Resilience Cost
Layout
Scramble Identifiers medium one-way free Change Formatting low one-way free Remove Comments high one-way free
Control
Computations
Insert Dead or
Irrele-vant Code Depends on the quality of the opaque construct and on the nesting depth of its insertion
µ1, µ2, µ3 Extend Loop
Condi-tion µ1, µ2, µ3 Reducible to non-Reducible µ1, µ2, µ3 Add Redundant Operands µ1, µ2, µ3 Parallelize Code high strong costly µ1, µ2
Aggregation
Inline Method medium one-way free µ1
Outline Statements medium strong free µ1 Interleave Functions Depends on the quality of the opaque
predicate
µ1, µ2, µ5
Clone Functions µ1
Block loop low weak free µ1, µ2
Unroll loop low weak cheap µ1
Loop fission low weak free µ1, µ2
Ordering
Reorder Statements low one-way free Reorder Loops low one-way free Reorder Expression low one-way free
Data
Storage & Encoding
Change Encoding Depends on the complexity of the encod-ing function
µ1 Promote Scalar to
Object
low strong free
Change Variable Lifetime
low strong free µ4
Split Variable Depends on the number of variables into which the original variable is split
µ1 Convert Static to
Procedural Data
Depends on the complexity of the gener-ated function
µ1, µ2
Aggregation
Merge Scalar Vari-ables
low weak free µ1
Split Array * weak free µ1, µ2, µ6
Merge Arrays * weak free µ1, µ2
Fold Array * weak cheap µ1, µ2, µ6, µ3
Flatten Array * weak free
Ordering Reorder Functions & Variables
low one-way free
Reorder Arrays low weak free
Table 1: Obfuscation transformations and their qualities (Courtesy Colberg et Al). A * in the quality columns indicates that the measure depends on circumstances discussed previously in this article
REFERENCES B NOTATIONS
References
[1] Parallélisation interprocédurale de programmes scientifiques (pips). http://pips4u.org. [2] Andrew Appel. Deobfuscation is in NP. 2002.
[3] Boaz Barak, Oded Goldreich, Russel Impagliazzo, Steven Rudich, Amit Sahai, Salil Vadhan, and Ke Yang. On the (im)possibility of obfuscating programs. 2001.
[4] Shyam R. Chidamber and Chris F. Kemerer. A metrics suite for object oriented design. 1994.
[5] Clark Thomborson Christian Collberg and Douglas Low. A taxonomy of obfuscating transformations. 1997. [6] Douglas Low Christian Collberg, Clark Thomborson. Manufacturing cheap, resilient, ans stealthy opaque
constructs. 1998.
[7] Christian Collberg and Jasvir Nagra. Surreptitious Software: Obfuscation, Watermarking, and Tamper-proofing for Software Protection. Addison-Wesley Professional, 2009.
[8] C. Darwin. The Origin of Species. John Murray, 1859.
[9] Rémi Triolet François Irigoin, Pierre Jouvelot. Semantical interprocedural parallelization. 1991.
[10] Serge Guelton and Sébastien Varrette. Une approche génétique et source à source de l’optimisation de code. 2009.
[11] Thomas McCabe. A complexity measure. 1976.
[12] N Melab, S Cahon, and E Talbi. Grid computing for parallel bioinspired algorithms. Journal of Parallel and Distributed Computing, 66(8):1052–1061, August 2006.
[13] Leonardo Trujillo and Gustavo Olague. Automated design of image operators that detect interest points. Evolutionary computation, 16(4):483–507, January 2008.
[14] Mark Weiser. Program slicing. 1984.
A
Acronym used
dEA distributed Evolutionary Algorithm EA Evolutionary Algorithm
EAs Evolutionary Algorithms GA Genetic Algorithm GP Genetic Programming
B
Notations
Do a table of notations Ex: • P = Program • P’= Program obfuscateB NOTATIONS
• τpot(P)= potency of the transformation from P to P’
• τres(P)= resilience of the transformation from P to P’
• τcost(P)= cost of the transformation from P to P’
• τqual(P)= quality of the transformation from P to P’