GOTHENBURG MONOGRAPHS IN LINGUISTICS 24
Automatic Detection
of Grammar Errors
in Primary School Children’s Texts
A Finite State Approach
Sylvana Sofkova Hashemi
Doctoral Dissertation
Publicly defended in Lilla H ¨orsalen,
Humanisten, G ¨oteborg University,
on June 7, 2003, at 10.15
for the degree of Doctor of Philosophy
i
Abstract
This thesis concerns the analysis of grammar errors in Swedish texts written by primary school children and the development of a finite state system for finding such errors. Grammar errors are more frequent for this group of writers than for adults and the distribution of the error types is different in children’s texts. In addition, other writing errors above word-level are discussed here, including punc-tuation and spelling errors resulting in existing words.
The method used in the implemented tool FiniteCheck involves subtraction of finite state automata that represent grammars with varying degrees of detail, creating a machine that classifies phrases in a text containing certain kinds of errors. The current version of the system handles errors concerning agreement in noun phrases, and verb selection of finite and non-finite forms. At the lexical level, we attach all lexical tags to words and do not use a tagger which could eliminate information in incorrect text that might be needed later to find the error. At higher levels, structural ambiguity is treated by parsing order, grammar extension and some other heuristics.
The simple finite state technique of subtraction has the advantage that the gram-mars one needs to write to find errors are always positive, describing the valid rules of Swedish rather than grammars describing the structure of errors. The rule sets remain quite small and practically no prediction of errors is necessary.
The linguistic performance of the system is promising and shows comparable results for the error types implemented to other Swedish grammar checking tools, when tested on a small adult text not previously analyzed by the system. The per-formance of the other Swedish tools was also tested on the children’s data collected for this study, revealing quite low recall rates. This fact motivates the need for ad-aptation of grammar checking techniques to children, whose errors are different from those found in adult writers and pose more challenge to current grammar checkers, that are oriented towards texts written by adult writers.
The robustness and modularity of FiniteCheck makes it possible to perform both error detection and diagnostics. Moreover, the grammars can in principle be reused for other applications that do not necessarily have anything to do with error detection, such as extracting information in a given text or even parsing.
KEY WORDS: grammar errors, spelling errors, punctuation, children’s writing,
iii
Acknowledgements
Work on this thesis would not have been possible without contributions, support and encouragement from many people. The idea of developing a writing tool for supporting children in their text production and grammar emerged from a study on how primary school children write by hand in comparison to when they use a computer. Special thanks to my colleague Torbj ¨orn Lager, who inspired me to do this study and whose children attended the school where I gathered my data.
My main supervisor Robin Cooper awakened the idea of using finite state meth-ods for grammar checking and launched the collaboration with the Xerox research group. I want to express my greatest gratitude to him for inspiring discussions dur-ing project meetdur-ings and supervision sessions, and his patience with my writdur-ing, struggling to understand every bit of it, always raising questions and always full of new exciting ideas. I really enjoyed our discussions and look forward to more. I would also like to thank my assistant supervisor Elisabet Engdahl who carefully read my writing and made sure that I expressed myself more clearly.
Many thanks to all my colleagues at the Department of Linguistics for creating an inspiring research environment with interesting projects, seminars and confer-ences. I especially want to mention Leif Gr ¨onqvist for being the helping hand next door whenever, Robert Andersson for being my project colleague, Stina Ericsson for loan of LATEX-manual and for always being helpful, Ulla Veres for help with recruitment of new victims for writing experiments, Jens Allwood and Elisabeth Ahls´en for introducing me to the world of transcription and coding, Sally Boyd, Nataliya Berbyuk, Ulrika Ferm for support and encouragement, Shirley Nicholson for always available with books and also milk for coffee, Pia Cromberger always ready for a chat. A special thanks to Ylva H˚ard af Segerstad for fruitful discussions leading to future collaboration that I am looking forward to, and for being a friend. I also want to thank the children in my study and their teachers for providing me with their text creations, and Sven Str ¨omqvist and Victoria Johansson for sharing their data collection. A special thanks to Genie Perdin who carefully proofread this thesis and gave me some encouraging last minute ‘kicks’. I also want to thank all my friends, who reminded me now and then about life outside the university.
My deepest gratitude to my family for being there for me and for always believ-ing in me. My husband Ali - I know the way was long and there were times I could be distant, but I am back. My daughter Sarah for being the sunshine of my life, my inspiration, my everything. My mother, father, sister and my big little brother ...
Sylvana Sofkova Hashemi
v
Table of Contents
1 Introduction 1
1.1 Written Language in a Computer Literate Society . . . 1
1.2 Aim and Scope of the Study . . . 3
1.3 Outline of the Thesis . . . 5
I Writing 7 2 Writing and Grammar 9 2.1 Introduction . . . 9
2.2 Research on Writing in General . . . 10
2.3 Written Language and Computers . . . 11
2.3.1 Learning to Write . . . 11
2.3.2 The Influence of Computers on Writing . . . 12
2.4 Studies of Grammar Errors . . . 14
2.4.1 Introduction . . . 14
2.4.2 Primary and Secondary Level Writers . . . 14
2.4.3 Adult Writers . . . 15
2.5 Conclusion . . . 18
3 Data Collection and Analysis 21 3.1 Introduction . . . 21 3.2 Data Collection . . . 21 3.2.1 Introduction . . . 21 3.2.2 The Sub-Corpora . . . 23 3.3 Error Categories . . . 25 3.3.1 Introduction . . . 25 3.3.2 Spelling Errors . . . 26 3.3.3 Grammar Errors . . . 27
3.3.4 Spelling or Grammar Error? . . . 28
3.3.5 Punctuation . . . 31
3.4 Types of Analysis . . . 32
3.5 Error Coding and Tools . . . 34
3.5.1 Corpus Formats . . . 34
4 Error Profile of the Data 37
4.1 Introduction . . . 37
4.2 General Overview . . . 37
4.3 Grammar Errors . . . 41
4.3.1 Agreement in Noun Phrases . . . 41
4.3.2 Agreement in Predicative Complement . . . 50
4.3.3 Definiteness in Single Nouns . . . 52
4.3.4 Pronoun Case . . . 53
4.3.5 Verb Form . . . 55
4.3.6 Sentence Structure . . . 62
4.3.7 Word Choice . . . 67
4.3.8 Reference . . . 69
4.3.9 Other Grammar Errors . . . 71
4.3.10 Distribution of Grammar Errors . . . 72
4.3.11 Summary . . . 77
4.4 Child Data vs. Other Data . . . 77
4.4.1 Primary and Secondary Level Writers . . . 77
4.4.2 Evaluation Texts of Proof Reading Tools . . . 80
4.4.3 Scarrie’s Error Database . . . 85
4.4.4 Summary . . . 88
4.5 Real Word Spelling Errors . . . 89
4.5.1 Introduction . . . 89
4.5.2 Spelling in Swedish . . . 89
4.5.3 Segmentation Errors . . . 91
4.5.4 Misspelled Words . . . 94
4.5.5 Distribution of Real Word Spelling Errors . . . 98
4.5.6 Summary . . . 100
4.6 Punctuation . . . 100
4.6.1 Introduction . . . 100
4.6.2 General Overview of Sentence Delimitation . . . 101
4.6.3 The Orthographic Sentence . . . 103
4.6.4 Punctuation Errors . . . 105
4.6.5 Summary . . . 107
vii
II Grammar Checking 111
5 Error Detection and Previous Systems 113
5.1 Introduction . . . 113
5.2 What Is a Grammar Checker? . . . 114
5.2.1 Spelling vs. Grammar Checking . . . 114
5.2.2 Functionality . . . 114
5.2.3 Performance Measures and Their Interpretation . . . 115
5.3 Possibilities for Error Detection . . . 117
5.3.1 Introduction . . . 117
5.3.2 The Means for Detection . . . 117
5.3.3 Summary and Conclusion . . . 125
5.4 Grammar Checking Systems . . . 128
5.4.1 Introduction . . . 128
5.4.2 Methods and Techniques in Some Previous Systems . . . 128
5.4.3 Current Swedish Systems . . . 130
5.4.4 Overview of The Swedish Systems . . . 134
5.4.5 Summary . . . 142
5.5 Performance on Child Data . . . 143
5.5.1 Introduction . . . 143
5.5.2 Evaluation Procedure . . . 143
5.5.3 The Systems’ Detection Procedures . . . 145
5.5.4 The Systems’ Detection Results . . . 146
5.5.5 Overall Detection Results . . . 168
5.6 Summary and Conclusion . . . 172
6 FiniteCheck: A Grammar Error Detector 173 6.1 Introduction . . . 173
6.2 Finite State Methods and Tools . . . 175
6.2.1 Finite State Methods in NLP . . . 175
6.2.2 Regular Grammars and Automata . . . 176
6.2.3 Xerox Finite State Tool . . . 177
6.2.4 Finite State Parsing . . . 180
6.3 System Architecture . . . 184
6.3.1 Introduction . . . 184
6.3.2 The System Flow . . . 186
6.3.3 Types of Automata . . . 189
6.4 The Lexicon . . . 191
6.4.1 Composition of The Lexicon . . . 191
6.4.3 Categories and Features . . . 194
6.5 Broad Grammar . . . 195
6.6 Parsing . . . 196
6.6.1 Parsing Procedure . . . 196
6.6.2 The Heuristics of Parsing Order . . . 198
6.6.3 Further Ambiguity Resolution . . . 201
6.6.4 Parsing Expansion and Adjustment . . . 203
6.7 Narrow Grammar . . . 205
6.7.1 Noun Phrase Grammar . . . 205
6.7.2 Verb Grammar . . . 210
6.8 Error Detection and Diagnosis . . . 214
6.8.1 Introduction . . . 214
6.8.2 Detection of Errors in Noun Phrases . . . 215
6.8.3 Detection of Errors in the Verbal Head . . . 216
6.9 Summary . . . 216
7 Performance Results 219 7.1 Introduction . . . 219
7.2 Initial Performance on Child Data . . . 219
7.2.1 Performance Results: Phase I . . . 219
7.2.2 Grammatical Coverage . . . 220
7.2.3 Flagging Accuracy . . . 223
7.3 Current Performance on Child Data . . . 228
7.3.1 Introduction . . . 228
7.3.2 Improving Flagging Accuracy . . . 229
7.3.3 Performance Results: Phase II . . . 232
7.4 Overview of Performance on Child Data . . . 233
7.5 Performance on Other Text . . . 237
7.5.1 Performance Results of FiniteCheck . . . 237
7.5.2 Performance Results of Other Tools . . . 240
7.5.3 Overview of Performance on Other Text . . . 243
7.6 Summary and Conclusion . . . 246
8 Summary and Conclusion 249 8.1 Introduction . . . 249
8.2 Summary . . . 249
8.2.1 Introduction . . . 249
8.2.2 Children’s Writing Errors . . . 250
8.2.3 Diagnosis and Possibilities for Detection . . . 251
ix
8.3 Conclusion . . . 255
8.4 Future Plans . . . 256
8.4.1 Introduction . . . 256
8.4.2 Improving the System . . . 256
8.4.3 Expanding Detection . . . 257
8.4.4 Generic Tool? . . . 258
8.4.5 Learning to Write in the Information Society . . . 258
Bibliography 260 Appendices 276 A Grammatical Feature Categories 279 B Error Corpora 281 B.1 Grammar Errors . . . 282 B.2 Misspelled Words . . . 293 B.3 Segmentation Errors . . . 306 C SUC Tagset 313 D Implementation 315 D.1 Broad Grammar . . . 315
D.2 Narrow Grammar: Noun Phrases . . . 315
D.3 Narrow Grammar: Verb Phrases . . . 318
D.4 Parser . . . 319
D.5 Filtering . . . 319
LIST OF TABLES xi
List of Tables
3.1 Child Data Overview . . . . 22
4.1 General Overview of Sub-Corpora . . . 38
4.2 General Overview by Age . . . 39
4.3 General Overview of Spelling Errors in Sub-Corpora . . . 40
4.4 General Overview of Spelling Errors by Age . . . 40
4.5 Number Agreement in Swedish . . . 42
4.6 Gender Agreement in Swedish . . . 42
4.7 Definiteness Agreement in Swedish . . . 42
4.8 Noun Phrases with Proper Nouns as Head . . . 44
4.9 Noun Phrases with Pronouns as Head . . . 44
4.10 Noun Phrases without (Nominal) Head . . . 45
4.11 Agreement in Partitive Noun Phrase in Swedish . . . 45
4.12 Gender and Number Agreement in Predicative Complement . . . 50
4.13 Personal Pronouns in Swedish . . . 54
4.14 Finite and Non-finite Verb Forms . . . 55
4.15 Tense Structure . . . 56
4.16 Fa-sentence Word Order . . . 63
4.17 Af-sentence Word Order . . . 63
4.18 Distribution of Grammar Errors in Sub-Corpora . . . 74
4.19 Distribution of Grammar Errors by Age . . . 74
4.20 Examples of Grammar Errors in Teleman’s Study . . . 78
4.21 Examples of Grammar Errors from the Skrivsyntax Project . . . . 79
4.22 Grammar Errors in the Evaluation Texts of Grammatifix . . . . 81
4.23 Grammar Errors in Granska’s Evaluation Corpus . . . . 82
4.24 General Error Ratio in Grammatifix, Granska and Child Data . . . 83
4.25 Three Error Types in Grammatifix, Granska and Child Data . . . 83
4.26 Grammar Errors in Scarrie’s ECD and Child Data . . . . 86
4.27 Examples of Spelling Error Categories . . . 90
4.28 Spelling Variants . . . 91
4.29 Distribution of Real Word Segmentation Errors . . . 91
4.30 Distribution of Real Word Spelling Errors in Sub-Corpora . . . . 99
4.31 Distribution of Real Word Spelling Errors by Age . . . 99
4.32 Sentence Delimitation in the Sub-Corpora . . . 103
4.33 Sentence Delimitation by Age . . . 103
4.34 Major Delimiter Errors in Sub-Corpora . . . 105
4.35 Major Delimiter Errors by Age . . . 105
4.37 Comma Errors by Age . . . 107
5.1 Summary of Detection Possibilities in Child Data . . . 126
5.2 Overview of the Grammar Error Types in Grammatifix (GF), Granska (GR) and Scarrie (SC) . . . 137
5.3 Overview of the Performance of Grammatifix, Granska and Scarrie 141 5.4 Performance Results of Grammatifix on Child Data . . . 169
5.5 Performance Results of Granska on Child Data . . . 169
5.6 Performance Results of Scarrie on Child Data . . . 170
5.7 Performance Results of Targeted Errors . . . 171
6.1 Some Expressions and Operators in XFST . . . 178
6.2 Types of Directed Replacement . . . 179
6.3 Noun Phrase Types . . . 206
7.1 Performance Results on Child Data: Phase I . . . 220
7.2 False Alarms in Noun Phrases: Phase I . . . 224
7.3 False Alarms in Finite Verbs: Phase I . . . 226
7.4 False Alarms in Verb Clusters: Phase I . . . 227
7.5 False Alarms in Noun Phrases: Phase II . . . 229
7.6 False Alarms in Finite Verbs: Phase II . . . 231
7.7 False Alarms in Verb Clusters: Phase II . . . 231
7.8 Performance Results on Child Data: Phase II . . . 232
7.9 Performance Results of FiniteCheck on Other Text . . . 237
7.10 Performance Results of Grammatifix on Other Text . . . 240
7.11 Performance Results of Granska on Other Text . . . 241
LIST OF FIGURES xiii
List of Figures
3.1 Principles for Error Categorization . . . 31
4.1 Grammar Error Distribution . . . 73
4.2 Error Density in Sub-Corpora . . . 76
4.3 Error Density in Age Groups . . . 76
4.4 Three Error Types in Grammatifix (black line), Granska (gray line) and Child Data (white line) . . . 84
4.5 Error Distribution of Selected Error Types in Scarrie . . . . 87
4.6 Error Distribution of Selected Error Types in Child Data . . . . . 87
6.1 The System Architecture of FiniteCheck . . . 185
7.1 False Alarms: Phase I vs. Phase II . . . 233
7.2 Overview of Recall in Child Data . . . 234
7.3 Overview of Precision in Child Data . . . 235
7.4 Overview of Overall Performance in Child Data . . . 236
7.5 Overview of Recall in Other Text . . . 244
7.6 Overview of Precision in Other Text . . . 244
Chapter 1
Introduction
1.1
Written Language in a Computer Literate Society
Written language plays an important role in our society. A great deal of our com-munication occurs by means of writing, which besides the traditional paper and pen, is facilitated by the computer, the Internet and other applications such as for instance the mobile phone. Word processing and sending messages via email are among the most usual activities on computers. Other communicated media that enable written communication are also becoming popular such as webchat or in-stant messaging on the Internet or text messaging (Short-Message-Service, SMS) via the mobile phone.1
The present doctoral dissertation concerns word processing on computers, in particular the linguistic tools integrated in such authoring aids. The use of word processors for writing both in educational and professional settings modifies the process, practice and acquisition of writing. With a word processor, it is not only easy to produce a text with a neat layout, but it supports the writer throughout the whole writing process. Text may be restructured and revised at any time during text production without leaving any trace of the changes that have been made. Text may be reused and a new text composed by cutting and pasting passages. Iconic material such as pictures2(or even sounds) can be inserted, linguistic aids can be used for proofreading a text. Writing acquisition can be enhanced by use of a word processor. For instance, focus on somewhat more technical aspects such as phys-ically shaping letters with a pen shifts toward the more cognitive processes of text
1Studies of computer-mediated communication are provided by e.g. Severinson Eklundh (1994);
Crystal (2001); Herring (2001). A recent dissertation by H˚ard af Segerstad (2002) explores especially how written Swedish is used in email, webchat and SMS.
2
Smileys or emoticons (e.g. :-) “happy face”) are more used in computer-mediated communica-tion.
production enabling the writer to apply the whole language register. Writing on a computer enhances in general both the motivation to write, revise or completely change a text (cf. Wresch, 1984; Daiute, 1985; Severinson Eklundh, 1993; Ponte-corvo, 1997).
The status of written language in our modern information society has de-veloped. In contrast to ancient times, writing is no longer reserved for just a small minority of professional groups (e.g. priests and monks, bankers, import-ant merchimport-ants). In particular, the emergence of computers in writing has led to the involvement of new user groups besides today’s writing professionals like journal-ists, novelists and scientists. We write more nowadays in general, and the freedom of and control over one’s own writing has increased. Texts are produced rapidly and are more seldom proofread by a careful secretary with knowledge of language. This is sometimes reflected in the quality and correctness of the resulting text (cf. Severinson Eklundh, 1995).
Linguistic tools that check mechanics, grammar and style have taken over the secretarial function to some degree and are usually integrated in word processing software. Spelling checkers and hyphenators that check writing mechanics and identify violations on individual words have existed for some time now. Gram-mar checkers that recognize syntactic errors and often also violations of punc-tuation, word capitalization conventions, number and date formatting and other style-related issues, thus working above the word level, are a rather new techno-logy, especially for such minor small languages like Swedish. Grammar checking tools for languages such as English, French, Dutch, Spanish, and Greek were be-ing developed in the 1980’s, whereas research on Swedish writbe-ing aids aimed at grammatical deviance started quite recently. In addition to the present work, there are three research groups working in this area. The Department of Numerical Ana-lysis and Computer Science (NADA) at the Royal Institute of Technology (KTH), with a long tradition of research in writing and authoring aids, is responsible for
Granska. Development of this tool has occurred over a series of projects starting
in 1994 (Domeij et al., 1996, 1998; Carlberger et al., 2002). The Department of Linguistics, Uppsala University was involved in an EU-sponsored project,
Scar-rie, between 1996 and 1999. The goal of this project was development of language
tools for Danish, Norwegian and Swedish (S˚agvall Hein, 1998a; S˚agvall Hein et al., 1999). Finally, a Finnish language engineering company Lingsoft Inc. developed
Grammatifix. Initiated in 1997, and completed in 1999, this tool was released on
the market in November 1998, and has been part of the Swedish Microsoft Office
Package since 2000 (Arppe, 2000; Birn, 2000).
The three Swedish systems mainly use parsing techniques with some degree of feature relaxation and/or explicit error rules for detection of errors. Grammatifix and Granska are developed as generic tools and are tested on adult (mostly
pro-Introduction 3
fessional) texts. Scarrie’s end-users are professional writers from newspapers and publishing firms.
1.2
Aim and Scope of the Study
The primary purpose of the present work is to detect grammar errors by means of linguistic descriptions of correct language use rather than describing the structure of errors. The ideal would be to develop a generic method for detection of grammar errors in unrestricted text that could be applied to different writing populations displaying different error types without the need for rewriting the grammars of the system. That is, instead of describing the errors made by different groups of writers resulting in distinct sets of error rules, use the same grammar set for detection. This approach of identifying errors in text without explicit description of them contrasts with the other three Swedish grammar checkers. Using this method, we will hopefully cover many different cases of errors and minimize the possibility of overlooking some errors.
We chose primary school children as the targeted population as a new group of users not covered by the previous Swedish projects. Children as beginning writers, are in the process of acquiring written language, unlike adult writers, and will prob-ably produce relatively more errors and errors of a different kind than adult writers. Their writing errors have probably more to do with competence than performance. Grammar checkers for this group have to have different coverage and concentrate on different kinds of errors. Further, the positive impact of computers on children’s writing opens new opportunities for the application of language technology. The role of proofreading tools for educational purposes is a rather new application area and this work can be considered a first step in that direction.
Against this background, the main goal of the present thesis is handling chil-dren’s errors and experimenting with positive grammatical descriptions using finite state techniques. The work is divided into three subtasks, including first, an overall error analysis of the collected children’s texts, then exploring the nature and pos-sibilities for detection of errors and finally, implementation of detection of (some) grammatical error types. Here is a brief characterization of these three tasks: I. Investigation of children’s writing errors: The targeted data for a grammar
checker can be selected either by intuitions about errors that will probably occur, or by directly looking at errors that actually occur. In the present work, the second approach of empirical analysis will be applied. Texts from pupils at three primary schools were collected and analyzed for errors, focusing on errors above word-level including grammar errors, spelling errors resulting in existent words, and punctuation. The main focus lies on grammar errors
as the basis for implementation. The questions that arise are: What grammar
errors occur? How should the errors be categorized? What spelling errors result in lexicalized strings and are not captured by a spelling checker? What is the nature of these? How is punctuation used and what errors occur?
II. Investigation of the possibilities for detection of these writing errors: The nature of errors will be explored along with available technology that can be applied in order to detect them. An interesting point is how the errors that are found are handled by the current systems. The questions that arise are: What is the nature of the error? What is the diagnosis of the error?
What is needed to be able to detect the error? How are the grammar errors handled by the current Swedish grammar checkers, Grammatifix, Granska and Scarrie?
III. Implementation of the detection of (some) grammar errors: A subset of errors will be chosen for implementation and will concern grammar check-ing to the level of detectcheck-ing errors. Errors will obtain a description of the type of error detected. Implementation will not include any additional dia-gnosis or any suggestion of how to correct the error. The analysis will be shallow, using finite state techniques. The grammars will describe real syn-tactic relations rather than the structure of erroneous patterns. The difference between grammars of distinct accuracy will reveal the errors, that as finite state automata can be subtracted from each other. Karttunen et al. (1997a) use this technique to find instances of invalid dates and this is an attempt to apply their approach to a larger language domain. The work on this grammar error detector started at the Department of Linguistics at G ¨oteborg Univer-sity in 1998, in the project Finite State Grammar for Finding Grammatical
Errors in Swedish Text and was a collaboration with the NADA group at
KTH in the project Integrated Language Tools for Writing and Document
Handling.3 The present thesis describes both the initial development within this project and the continuation of it.
The main contributions of this thesis concern understanding of incorrect lan-guage use in primary school children’s writing and computational analysis of such incorrect text by means of correct language use, in particular:
• Collection of texts written by primary school children, written both by hand and on a computer.
3This project was sponsored by HSFR/NUTEK Language Technology Programme and has its
Introduction 5
• Analysis of grammar errors, spelling errors and punctuation in the texts of primary school writers.
• Comparison of errors found in the present data with errors found in other studies on grammar errors.
• Comparison of error types covered by the three Swedish grammar checkers. • Performance analysis of the three Swedish grammar checkers on the present
data.
• Implementation of a grammar error detector that derives/compiles error pat-terns rather than writing the error grammar by hand.
• Performance analysis of the detector on the collected data and some portion of other data.
1.3
Outline of the Thesis
The remaining chapters of the thesis fall into two parts.
Part I: The first part is devoted to a discussion of writing and an analysis of the collected data and consists of three chapters. Chapter 2 provides a brief introduction to research on writing in general, writing acquisition, how com-puters influence writing and descriptions of previous findings on grammar errors, concluding with what grammar errors are to be expected in written Swedish. Chapter 3 gives an overview of the data collected and a discussion of error classification. Chapter 4 presents the error profile of the data. The chapter concludes with discussion of the requirements for a grammar error detector for the particular subjects of this study.
Part II: The second part of the thesis concerns grammar checking and includes three chapters. Chapter 5 starts with a general overview of the requirements and functionalities of a grammar checker and what is required for the er-rors in the present data. Swedish grammar checkers are described and their performance is checked on the present data. Chapter 6 presents the imple-mentation of a grammar error detector that handles these errors, including description of finite state formalism. The techniques of finite state parsing are explained. Chapter 7 presents the performance of this tool.
The thesis ends with a concluding summary (Chapter 8). In addition, the thesis contains four appendices. Appendix A presents the grammatical feature categories
used in the examples of errors or when explaining the grammar of Swedish.
Ap-pendix B presents the error corpora consisting of the grammar errors found in the
present study (Appendix B.1), misspelled words (Appendix B.2) and segmenta-tion errors (Appendix B.3). The tagset used is presented in Appendix C and some listings from the implementation are listed in Appendix D.
Part I
Writing
Chapter 2
Writing and Grammar
2.1
Introduction
Learning to write does not imply acquiring a completely new language (new gram-mar), since often at this stage (i.e. beginning school) a child already knows the majority of the (general) grammar rules. Rather, learning to write is a process of learning the difference between written language and the already acquired spoken language. Consequently, errors that one will find in the writing of primary school children often are due to their lack of knowledge of written language and consist of attempts to reproduce spoken language norms as an alternative to the standard written norm or to errors due to the as yet not acquired part of written language. Further, even when the writer knows the standard norm, errors can occur either as the result of disturbances such as tiredness, stress, etc. or because the writer cannot manage to keep together complex content and meaning constructions (cf. Tele-man, 1991a). Another source of errors is the aids we use for writing, computers, which also impact on our writing and may give rise to errors.
The main purpose of the present chapter is to see if previous studies on writing can give some hint on what grammar errors are to be expected in the writing by Swedish children. It provides a survey of previous studies of grammar errors, as well as some background research on writing in general and some insights into what it means to learn to write and how computers influence our writing.
First, a short review of research on writing is presented (Section 2.2), followed by a short explanation of what acquisition of written language involves and how computers influence the way we write (Section 2.3). Previous findings on grammar errors in Swedish can be found in the following section, including studies of writing of children and adolescents, adults and the disabled (Section 2.4).
2.2
Research on Writing in General
For a long period of time many considered written language (beginning with e.g. de Saussure, 1922; Bloomfield, 1933) to be a transcription of spoken (oral) lan-guage and not that important as, or even inferior to, spoken lanlan-guage. A similar view is also reflected in the research on literacy, where studies on writing were very few in comparison to research on reading. A turning point at the end of 1970s, is described by many as “the writing crisis” (Scardamalia and Bereiter, 1986), when an expansion in research occurs in teaching native language writing. During this period, more naturalistic methods for writing are propagated, i.e. “learning to write by writing” (Moffett, 1968), examination of the writing situation in English schools (e.g. Britton, 1982; Emig, 1982) and changing the focus of study from judgments of products and more text-oriented research to the strategies involved in the process of writing (see Flower and Hayes, 1981).
In Sweden, writing skills were studied by focusing on the written product, often related to the social background of the child. Research has been devoted to spelling (e.g. Haage, 1954; Wallin, 1962, 1967; Dahlquist and Henrysson, 1963; Ahlstr¨om, 1964, 1966; Lindell, 1964) and writing of composition in connection to standardized tests (e.g. Bj ¨ornsson, 1957, 1977; Ljung, 1959). There are also studies concerning writing development in primary and upper secondary schools (e.g. Grundin, 1975; Bj ¨ornsson, 1977; Hultman and Westman, 1977; Lindell et al., 1978; Larsson, 1984).
During the later half of the 1980s, research in Sweden took a new direction to-wards studies of writing strategies concerning writing as a process (e.g. Bj ¨ork and Bj¨ork, 1983; Str ¨omquist, 1987, 1989) and development of writing abilities focusing on writing activities between children and parents (e.g. Liberg, 1990) and text ana-lysis (e.g. Garme, 1988; Wikborg and Bj ¨ork, 1989; Josephson et al., 1990). This turning point was reflected in education by the introduction of process-oriented writing, as well.
Some research concerned writing as a cognitive text-creating process using video-recordings of persons engaged in writing (e.g. Matsuhasi, 1982), or clinical experiments (e.g. Bereiter and Scardamalia, 1985).
The use of computers in writing prompted studies on the influence of computers in writing (e.g. Severinson Eklundh and Sj ¨oholm, 1989; Severin-son Eklundh, 1993; Wikborg, 1990), resulting in the development of computer programs that register and record writing activities (e.g. Flower and Hayes, 1981; Severinson Eklundh, 1990; Kollberg, 1996; Str ¨omqvist, 1996).
Writing and Grammar 11
2.3
Written Language and Computers
2.3.1 Learning to Write
Writing, like speaking, is primarily aimed at expressing meaning. The most evid-ent difference between written and spoken language lies in the physical channel. Written language is a single-channelled monologue, using only the visual chan-nel (eye) with the addressee not present at the same time. It is a more relaxed, rather slow process affording longer time for consideration and the possibility to edit/correct the end product. Speech as a dialogue is simultaneous and involves participants present at the same time, where all the senses can be used to receive information. It is a fast process with little time for consideration and difficulty in correcting the end product. The rules and conventions of written language are more restrictive than the rules of spoken language in the sense that there are construc-tions in spoken language regarded as “incorrect” in written language. Writing is, in general, standardized with less (dialectal) variation in contrast to spoken language, which is dialectal and varied. Further, acquisition of written and spoken language occurs under different conditions and in different ways. Writing is taught in school by teachers with certain training, whereas speaking is learned privately (in a fam-ily, from peers, etc.), without any planning of the process. When learning to speak, we learn the language. When learning to write we already know the language (in the spoken form) (cf. Linell, 1982; Teleman, 1991b; Liberg, 1990).1
Learning a written language means not only acquiring its more or less explicit norms and rules, but also learning to handle the overall writing system, including the more technical aspects, such as how to shape the letters, the boundaries between words, how a sentence is formed, as well as acquiring the grammatical, discursive, and strategic competence to convey a thought or message to the reader. In other words, writing entails being able to handle the means of writing, i.e. letters and grammar rules, and arranging them to form words and sentences and being able to use them in a variety of different contexts and for different purposes. During this development, children may compose text of different genre, but not necessarily ap-ply the conventions of the writing system correctly. Children are quite creative and they often use conventions in their own ways, for instance using periods between words to separate them instead of blank spaces (cf. Mattingly, 1972; Chall, 1979; Lundberg, 1989; Liberg, 1990; Pontecorvo, 1997; H˚akansson, 1998).
1
For further, more extensive definitions of differences between written and spoken language see e.g. Chafe (1985); Halliday (1985); Biber (1988).
The above discussion leads to a view of learning to write as being the acquis-ition of a complex system of communication with several components. Following Hultman (1989, p.73), we can identify three aspects of writing:
1. the motor aspect: the movement of the hand when forming the letters or typing on the keyboard
2. the grammar aspect: the rules for spelling and punctuation, morphology and syntax on clause, sentence and text level
3. the pragmatic aspect: use of writing for a purpose, to argue, tell, describe, discuss, inform, refer, etc. The text has to be readable, reflecting the meaning of words and the effect they have.
This thesis focuses on the grammar aspect, in particular on the syntactic re-lationships between words. Also some aspects of spelling and punctuation are covered. The text level is not analyzed here.
2.3.2 The Influence of Computers on Writing
The view on writing has changed, it is no longer interpreted as a linear activity consisting of independent and temporally sequenced phases, but rather considered to be a dynamic, problem solving activity. According to Hayes and Flower (1980), as a cognitive process, writing is influenced by the task environment (the external social conditions) and the writer’s long term memory, including cognitive processes of planning (generating and organizing ideas, setting goals, and decision-making of what to include, what to concentrate on), translation (the actual production) and revision (evaluation of what has been written, proof-reading, writing out and publishing).
This process-based approach with the phases also referred to as prewriting,
writing and rewriting has been adopted in writing instruction in school (e.g. Graves,
1983; Calkins, 1986; Str ¨omquist, 1993) and is also considered to be well-suited to computer-assisted composition (Wresch, 1984; Montague, 1990).
Writing on a computer makes text easy to structure, rearrange and rewrite. Many studies report writers’ decreased resistance to writing. They experience that it is easier to start to write and there is a possibility to revise under the whole process of writing, leave the text and then come back to it again and update and reuse old texts (e.g. Wresch, 1984; Severinson Eklundh, 1993). Also, studies of children’s use of computers show that children who use a word-processor in school enjoy writing and editing activities more, considering writing on a computer to be much easier and more fun. They are more willing to revise and even completely
Writing and Grammar 13
change their texts and they write more in general (e.g. Daiute, 1985; Pontecorvo, 1997).
The word processor affects the way we write in general. We usually plan less in the beginning when writing on a computer and revise more during writing. Thus, editing occurs during the whole process of writing and is not left solely to the final phase. In an investigation by Severinson Eklundh (1995) of twenty adult writers with academic backgrounds more than 80% of all editing was performed during writing and not after. The main disadvantage reported is that it is hard to get an overall perspective of a text on the screen, which then makes planning and revision more difficult and can in turn lead to texts being of worse quality (e.g. Hansen and Haas, 1988; Severinson Eklundh, 1993). Rewriting and rearranging of a text is easy to do on a word processor, for instance by copy and paste utilities that may easily give rise to errors that are hard to discover afterwards, especially in a brief perusal. Words and phrases can be repeated, omitted, transposed. Sentences can be too long (Pontecorvo, 1997) and errors that normally are not found in native speakers’ writing occur. The common claim is that writing in one’s mother tongue normally results in the types of errors that are different from the public language norm, since most of the mother tongue’s grammar is present before we begin school (Teleman, 1979). There are studies that clearly show that the use of word processors leads to completely new error types including some errors that were considered charac-teristic for second language writers. For instance, morpho-syntactic (agreement) errors have been found to be quite usual among native speakers in the studies of Bustamente and Le ´on (1996) and Domeij et al. (1996). The errors are connected to how we use the functions in a word processor and that revision is more local due to limitations in view on the screen (cf. Domeij et al., 1996; Domeij, 2003).
Concerning text quality, there are studies that point out that the use of a word processor results in longer texts, both among children and adults. Some researchers claim that the quality of compositions improved when word processors were used (see e.g. Haas, 1989; Sofkova Hashemi, 1998). However, no reliable quality en-hancement besides the length of a text is evident in any study. The effects of using a computer for revision are regarded by some as being positive both on the mech-anics and the content of writing while others feel it promotes only surface level revision, not enhancing content or meaning (see the surveys in Hawisher, 1986; Pontecorvo, 1997; Domeij, 2003).
2.4
Studies of Grammar Errors
2.4.1 Introduction
There are not many studies of grammar errors in written Swedish. Studies of adult writing are few, while research on children’s writing development mostly concerns the early age of three to six years and development of spelling and use of the period and/or other punctuation marks and conventions (e.g. Allard and Sundblad, 1991). Recent expansion of development of grammar checking tools contributes to this field, however.
Below, studies are presented of grammar errors found in the writing of primary and upper secondary school children, adults, error types covered by current proof reading tools and analysis of grammar errors in texts of adult writers used for eval-uation of these tools. Some of these studies are described further in detail and are compared to the analysis of the children’s texts gathered for the present thesis in Chapter 4 (Section 4.4).
2.4.2 Primary and Secondary Level Writers
During the 1980s, several projects investigated the language of Swedish school children as a contribution to discussion of language development and language in-struction (see e.g. the surveys in ¨Ostlund-Stj¨arneg˚ardh, 2002; Nystr ¨om, 2000). The writing of children in primary and upper secondary school was analyzed mostly with focus on lexical measures of productivity and language use, in terms of analysis of vocabulary, parts-of-speech distribution, length of words, word vari-ation and also content, relvari-ation to gender, social background and the grades as-signed to the texts (e.g. Hersvall et al., 1974; Hultman and Westman, 1977; Lindell et al., 1978; Pettersson, 1980; Larsson, 1984). Then, when the traditional product-oriented view on writing switched to the new process-product-oriented paradigm, studies on writing concerned the text as a whole and as a communicative act (e.g. Chrystal and Ekvall, 1996, 1999; Liberg, 1999) and became more devoted to analysis of genre and referential issues (e.g. ¨Oberg, 1997; Nystr ¨om, 2000) and relation to the grades assigned (e.g. ¨Ostlund-Stj¨arneg˚ardh, 2002) and modality (speech or writ-ing) (e.g. Str¨omqvist et al., 2002). Quantitative analysis in this field still concerns lexical measures of variation, length, coherence, word order and sentence struc-ture; very few studies note errors other than spelling or punctuation (e.g. Olevard, 1997; Hallencreutz, 2002).
A study by Teleman (1979) shows examples (no quantitative measures) of both lexical and syntactic errors observed in the writing of children from the seventh year of primary school (among others). He reports on errors in function words,
Writing and Grammar 15
inflection with dialectal endings in nouns, dropping of the tense-endings on verbs
and on use of nominative form of pronouns in place of accusative forms as is often the case in spoken Swedish. Also, errors in definiteness agreement, missing
con-stituents, reference problems, word order and tense shift are exemplified as well as
observation of erroneous use of or missing prepositions in idiomatic expressions. Another study of Hultman and Westman (1977), concerns analysis of national tests from third year students from upper secondary school. The aim of the pro-ject Skrivsyntax “Written Syntax” was to study writing practice in school from a linguistic point of view. The material included 151 compositions (88 757 words in total) with the subject Familjen och ¨aktenskapet ¨an en g˚ang ‘Family and mar-riage once more’. Vocabulary, distribution of word categories, syntax and spelling were studied and compared to adult texts, between the marks assigned to the texts and between boys and girls. The study also included error analysis of punctu-ation, orthography, grammar, lexicon, semantics, stylistics and functionality of the text. Among grammar errors, gender agreement errors were reported being usual, and relatively many errors in pronoun case after preposition occurred. Errors in
agreement between subject and predicative complement are also reported as rather
frequent. Word order errors are also reported, mostly in the placement of adverbi-als. Other examples include verb form errors, subject related errors, reference,
preposition use in idiomatic expressions and clauses with odd structure.
2.4.3 Adult Writers
There are few studies of adult writing in Swedish. Those that exist are mostly de-voted to the writing process as a whole or to social aspects of it with very little attention being paid to the mechanics of writing. However, the recent expansion in the development of Swedish computational grammar checking tools that require understanding of what error types should be treated by such tools, has made contri-butions to this field. The realization of what types of errors occur and should thus be included in such an authoring aid may be based on intuitive presuppositions of what rules could be violated, in addition to empirical analysis of text. More empir-ical evidence of grammar violations also comes from the evaluation of such tools, where the system is tested against a text corpus with hand-coded analysis of errors. There are three available grammar checkers for Swedish: Granska (Knutsson, 2001), Grammatifix (Birn, 2000) and Scarrie (S˚agvall Hein et al., 1999).2 Scarrie
is explicitly devoted to professional writers of newspaper articles. The other two systems are not explicitly aimed at any special user groups, although their perform-ance tests were provided mainly on newspaper texts.
Below, a survey of studies is presented of professional and non-professional writers, adult disabled writers, the grammar errors that are covered by the three Swedish grammar checkers, and grammar errors that occurred in the evaluation texts the performance of these systems was tested upon.
Professional and Non-professional Writers
Studies focusing on adult non-professional writing concern analysis of crime re-ports (Leijonhielm, 1989), post-school writing development (Hammarb ¨ack, 1989), a socio-linguistic study concerning writing attitudes, i.e. what is written and who writes what at a local government office regardless of writing conventions (Gun-narsson, 1992) and some “typical features in non-proof-read adult prose” at a gov-ernment authority are reported in G ¨oransson (1998), the only investigation that addresses (to some extent) grammatical structure.
G¨oransson (1998) describes her immediate impression when proof-reading texts written by her colleagues at a government authority, showing some typical features in this unedited adult prose. She examined reports, instructional texts, newspaper articles, formal letters, etc. The analysis distinguishes between high and low level errors. High level includes comprehensibility of the text, coherence and style, relevance for the context, ability to see one’s own text with the eyes of others, choice of words, etc. Low level errors cover grammar and spelling errors. Among the grammar errors she only reports reference problems, choice of
prepos-ition and agreement errors.
Among studies of professional writers, the language consultant Gabriella Sand-str¨om (1996) analyzed editing at the Swedish newspaper Svenska Dagbladet that included 29 articles written by 15 reporters. The original script, the edited version and the final version of the articles were analyzed. The analysis involved spelling, errors at lexical and syntactic level, formation errors, punctuation and graphical errors. The result showed that the journalists made most errors in punctuation, graphical errors and lexical errors and most of them disappeared during the edit-ing process. Among the lexical errors, Sandstr ¨om mentions errors in idiomatic
expressions and in the choice of prepositions. Syntax errors also seem to be quite
common, but the article does not give an analysis of the different kinds of syntax errors.
Writing and Grammar 17
Adults with Writing Disabilities
Studies on writing strategies of disabled groups were conducted within the project
Reading and Writing strategies of Disabled Groups,3 including analysis of gram-mar for the dyslexic and deaf (Wengelin, 2002). The analysis of the writing of deaf adults included no frequency data and is not that important for the present study since it tends to reflect more strategies found in second language acquisition.
Adult dyslexics mostly show problems with formation of sentences and fre-quent omission of constituents. Especially frefre-quent were missing or erroneous
conjunctions. Other errors concern agreement in noun phrase or the form of noun phrases, verb form, tense shift within sentences and incorrect choice of prepos-itions. Marking of sentence boundaries and punctuation is the main problem of
these writers.
Error Types in Proof Reading Tools
The error types covered by a grammar checker should, in general, include the cent-ral constructions of the language and, in particular, those which give rise to errors. These constructions should allow precise descriptions so that false alarms can be avoided. The selection of what error types to include is then also dependent on the available technology and the possibility of detecting and correcting the error types (cf. Arppe, 2000; Birn, 2000).
In the development of Grammatifix, the pre-analysis of existing error types in Swedish was based on linguistic intuition, personal observation and reference lit-erature of Swedish grammar and writing conventions (Arppe, 2000). In the case of
Granska, the pre-analysis involved analysis of empirical data such as newspaper
texts and student compositions (Domeij et al., 1996; Domeij, 2003). In the
Scar-rie project, where journalists are the end-users, the stage of pre-analysis consisted
of gathering corrections made by professional proof-readers at the newspapers in-volved. These corrections were stored in a database (The Swedish Error Corpora
Database, ECD), that contains nearly 9,000 error entries, including spelling,
gram-mar, punctuation, graphic and style, meaning and reference errors.
Arppe (2000) provides an overview of the types of errors covered by the Swedish tools and reports, in short, that all the tools treat errors in noun phrase
agreement and verb forms in verb chains. Scarrie and Granska also treat errors
in compounds, whereas Grammatifix has the widest coverage in punctuation and number formatting errors. He points out that the error classification in these tools is similar, but not exactly the same. The depth and breadth of included error
categor-3
More information about this project may be found at: http://www.ling.gu.se/ ˜wengelin/projects/r&r.
ies differs in the subsets of phrases, level of syntactic complexity or in the position of detection in the sentence. They may, for instance, detect errors in syntactic-ally simple fragments, but fail with syntacticsyntactic-ally more complex structures. These factors are further explained and exemplified in Chapter 5, where I also compare the error types covered by the individual tools.
Among the grammar errors presented in Scarrie’s ECD, errors in noun phrase
agreement, predicative complement agreement, definiteness in single nouns, verb subcategorization and choice of preposition are the most frequent error types.
Evaluation Texts of Proof Reading Tools
Other empirical evidence of grammar errors can be observed in the evaluation of the three grammar checkers (Birn, 2000; Knutsson, 2001; S˚agvall Hein et al., 1999). The performance of all the tools was tested on newspaper text, written by professional writers. Only the evaluation corpus of Granska included texts written by non-professionals as well, represented by student compositions. In general, the corpora analyzed are dominated by errors in verb form, agreement in noun phrases,
prepositions and missing constituents.
2.5
Conclusion
The main purpose of the present chapter was to investigate if previous research reveals which grammar errors to expect in the writing of primary school children. Apparently, grammar in general has a very low priority in the research on writing in Swedish. Grammar errors in children’s writing have been analyzed at the upper level in primary school and in the upper secondary school and exist only as reports with some examples, without any particular reference to frequency. Some analyses have been performed on the writing of professional adult writers and in the research on the writing of adult dyslexic and deaf adults, with quantitative data for the dys-lexic group. The only area that directly approaches grammar errors concerns the development of proofreading tools aiming particularly at grammar. These studies report on grammar errors in the writing of adults.
Previous research presents no general characterization of grammar errors in children’s writing. There are, however, few indications that children as beginning writers make errors different from adult writers. Teleman’s observations indicate use of spoken forms that were not reported in the other studies. Some examples of errors in the Skrivsyntax project are evidently more related to the fact that the children have not yet mastered writing conventions (e.g. errors in the accusative
Writing and Grammar 19
case of plural pronouns) rather than making errors related to “slip of the pen” (e.g. due to lack of attention).
In general, all the studies report errors in agreement (both in non phrase and
predicative complement), verb form and the choice of prepositions in idiomatic expressions. Are these the central constructions in Swedish that give rise to
gram-mar errors? It may be true for adult writers, but it is unclear regarding beginning writers. Analysis of grammar errors in the children data collected for the present study is presented in Chapter 4, together with a comparison of the findings of the previous studies of grammar errors presented above.
Chapter 3
Data Collection and Analysis
3.1
Introduction
In this chapter we report on data that has been gathered for this study and the types of analysis provided on them. First, the data collection is presented and the different sub-corpora are described (Section 3.2). Then, a discussion follows of the kinds of errors analyzed and how they are classified (Section 3.3). The types of analyses in the present study are provided in the subsequent section (Section 3.4) and a description of error coding and tools that were used for that purpose end this chapter (Section 3.5).
3.2
Data Collection
3.2.1 Introduction
The main goal of this thesis is to detect automatically grammar errors in texts writ-ten by children. In order to explore what errors actually occur, texts with different topics written by different subjects were collected to build an underlying corpus for analysis, hereafter referred to as the Child Data corpus.
The material was collected on three separate occasions and has served as basis for other (previous) studies. The first collection of the data consists of both hand written and computer written compositions on set topics by 18 children between 9 and 11 years old - The Hand versus Computer Collection. The second collection involves the same subjects, this time, the children participate in an experiment and tell a story about a series of pictures, both orally and in writing on a computer
development of literacy and includes eighty computer written compositions of 10 and 13 year old children on set topics in two genres - The Spencer Collection.1
Table 3.1 gives an overview of the whole Child Data corpus, including the three collections mentioned above, divided into five sub-corpora by the writing topics the subjects were given: Deserted Village, Climbing Fireman, Frog Story,
Spencer Narrative, Spencer Expository. Further information concerns the age of
the subjects involved, the number of compositions, number of words, if the children wrote by hand or on computer and what writing aid was then used.
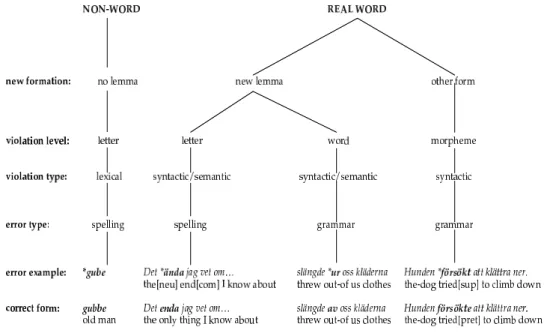
Table 3.1: Child Data Overview
AGE COMP WORDS TOPIC WRITING AID
HAND VS. COMPUTERCOLLECTION:
Deserted Village 9-11 18 7 586 ”They arrived in a deserted village”
paper and pen
Climbing Fireman 9-11 18 4 505 Shown: a picture of a fireman climbing on a ladder
Claris Works 3.0
FROGSTORYCOLLECTION:
Frog Story 9-11 18 4 907 Story-retelling: ”Frog where are you?”
ScriptLog SPENCERCOLLECTION:
Spencer Narrative 10 & 13 40 5 487 Narrative: Tell about a predicament you had rescued somebody from, or you had been rescued from
ScriptLog
Spencer Expository 10 & 13 40 7 327 Expository: Discuss the problems seen in the video
ScriptLog
TOTAL 134 29 812
Altogether 58 children between 9 and 13 years old wrote 134 papers, compris-ing a corpus of 29,812 words. Most of the papers are written on the computer. Only the first sub-corpus (Deserted Village) consists of 18 hand written compositions. The editor Claris Works 3.0 was used for 18 computer written texts. ScriptLog, a tool for experimental research on the on-line process of writing, was used for the remaining (98) computer written compositions. ScriptLog looks just like an
ordin-1Many thanks to Victoria Johansson and Sven Str ¨omqvist, Department of Linguistics, Lund
Data Collection and Analysis 23
ary word processor to the user, but in addition to producing the written text, it also logs information of all events on the keyboard, the screen position of these events and their temporal distribution.2
This section proceeds with detailed descriptions of the three collections that form the corpus, with information about when and for what purpose the material was collected, the subjects involved, the tasks they were given and the experiments they took part in.
3.2.2 The Sub-Corpora
The Hand vs. Computer Collection
The first collection originates from a study on the computer’s influence on chil-dren’s writing, gathered in autumn, 1996. The writing performance in hand writ-ten and computer writwrit-ten compositions on the same subjects was compared (see Sofkova, 1997). Results from this study showed both great individual variation among the subjects and similarities between the two modes, e.g. the distribution of spelling and segmentation errors, as well as improved performance in the es-says written on the computer especially in the use of punctuation, capitals and the number of spelling errors.
The subjects included a group of eighteen children, twelve girls and six boys, between the age of 9 and 11, all pupils at the intermediate level at a primary school. This school was picked because the children had some experience with writing on computers. Computers had already been introduced in their instruction and pupils were free to choose to write on a computer or by hand. If they chose to write on a computer, they wrote directly on the computer, using the Claris Works 3.0 word-processor. Other requirements were that the subjects should be monolingual and not have any reading or writing disabilities.
The children wrote two essays - one by hand and one on the computer. At the beginning of this study, the children were already busy writing a composition, which now is part of the hand written material. They were given a heading for the hand written task: De kom till en ¨overgiven by ‘They arrived in a deserted village’. For the computer written task, pupils were shown a picture of a fireman climbing
on a ladder. They were also told not to use the spelling checker when writing in
order to make the two tasks as comparable as possible.
2
A first prototype was developed in the project Reading and writing in a Linguistic and a didactic perspective (Str¨omqvist and Hellstrand, 1994). An early version of ScriptLog developed for Macin-tosh computers was used for collecting the data in this thesis (Str ¨omqvist and Malmsten, 1998). There is now also a Windows version (Str ¨omqvist and Karlsson, 2002).
The Frog Story Collection
The second collection is a story-telling experiment and involves the same subjects as in the Hand vs. Computer Collection. In April 1997, we invited the children to the Department of Linguistics at G ¨oteborg University to take part in the exper-iment. They played a role as control group in the research project Reading and
Writing Strategies of Disabled Groups, that aims at developing a unified research
environment for contrastive studies of reading and writing processes in language users with different types of functional disabilities.3
The experiment included a production task and the data were elicited both in written and spoken form (video-taped). A wordless picture story booklet Frog,
where are you? by Mercer Mayer (1969) was used, a cartoon like series of 24
pictures about a boy, his dog and a frog that disappears. Each subject was asked to tell the story, picture by picture.
At the beginning of the experiment the children were invited to look through the book to get an idea of the content. Then, the instruction was literally Kan du
ber¨atta vad som h¨ander p˚a de h¨ar bilderna? ‘Can you tell what is happening in
these pictures?’ Half of the children started with writing and then telling the story and half of them did the opposite. For the written task, the on-line process editor
ScriptLog was used, storing all the writing activities.
The SPENCER Collection
The Spencer Project on Developing Literacy across Genres, Modalities and Lan-guages4 lasted between July 1997, and June 2000. The aim was to investigate the development of literacy in both speech and writing. Four age groups (grade school students, junior high school students, high school students and university students), and seven languages (Dutch, English, French, Hebrew, Icelandic, Span-ish and SwedSpan-ish) were studied.
Schools were picked from areas where one could expect few immigrants in the classes, and also where the children had some experience with computers. The subjects came from middle class, monolingual families and they had no reading or writing disabilities. Another criterion was that at least one of the subject’s parents had education beyond high school.
3The project’s directors are Sven Str ¨omqvist and Elisabeth Ahls´en from the Department of
Linguistics, G¨oteborg University. More information about this project may be found at: http: //www.ling.gu.se/˜wengelin/projects/r&r.
4
The project was funded by the Spencer Foundation Major Grant for the Study of Developing Literacy to Ruth Berman, Tel Aviv University, who was the coordinator of this project. Each lan-guage/country involved has had its own contact person, for Swedish it was Sven Str ¨omqvist from the Department of Linguistics at Lund University.
Data Collection and Analysis 25
All subjects had to create two spoken and two written texts, in two genres,
ex-pository and narrative. Each subject saw a short video (3 minutes long), containing
scenes from a school day. After the video, the procedure varied depending on the order of genre and modality.5
The topic for the narratives was to tell about an event when the subject had rescued somebody, or had been rescued by somebody from a predicament. They were asked to tell how it started, how it went on and how it ended. The topic for the expository text was to discuss the problems they had seen in the video, and possibly give some solutions. They were explicitly asked not to describe the video. Written material for two age groups from the Swedish part of the study is in-cluded in the present Child Data: the grade school students (10 year olds) and ju-nior high school students (13 year olds). In total, 20 subjects from each age group were recruited. The texts the subjects wrote were logged in the on-line process editor ScriptLog.
3.3
Error Categories
3.3.1 Introduction
The texts under analysis contain a wide variety of violations against written lan-guage norms, on all levels: lexical, syntactic, semantic and discourse. The main focus of this thesis is to analyze and detect grammar errors, but first we need to establish what a grammar error is and what distinguishes a grammar error from, for instance, a spelling error. Punctuation is another category of interest, important for deciding how to syntactically handle a text by a grammar error detector.
The following section discusses categorization of the errors found in the data and explains what errors are classified as spelling errors as well as where the boundary lies between spelling and grammar errors. The error examples provided are glossed literally and translated into English. Grammatical features are placed within brackets following the word in the English gloss (e.g. klockan ‘watch [def]’) (the different feature categories are listed in Appendix A). Occurrences of spelling violations are followed by the correct form within parentheses and preceded by ‘⇒’, both in the Swedish example and the English gloss (e.g. var (⇒vad) ‘was (⇒what)’).
5
There were four different orders in the experiment:
Order A: Narrative spoken, Narrative written, Expository spoken, Expository written. Order B: Narrative written, Narrative spoken, Expository written, Expository spoken. Order C: Expository spoken, Expository written, Narrative spoken, Narrative written. Order D: Expository written, Expository spoken, Narrative written, Narrative spoken.
3.3.2 Spelling Errors
Spelling errors are violations of the orthographic norms of a language, such as
insertion (e.g. errour instead of error), omission (e.g. eror), substitution (e.g. errer) or transposition (e.g. erorr) of one or more letters within the boundaries of
a word or omission of space between words (i.e. when words are written together) or insertion of space within a word (i.e. splitting a word into parts).
Spelling errors may occur due to the subject’s lack of linguistic knowledge of a particular rule (competence errors) or as a typographical mistake, when the subject knows the spelling, but makes a motor coordination slip (performance errors).
The difference between a competence and a performance error is not always so easy to see in a given text. For example, the (nonsense) string gube deviates from the intended correct word gubbe ‘old man’ by missing doubling of ‘b’ and violates thus the consonant gemination rule for this particular word. The text where the error comes from, shows that this subject is (to some degree) familiar with this rule applying consonant gemination on other words, indicating that the error is likely to be a typo (i.e. a performance error) and that it occurred by mistake. On the other hand, the subject may not be aware that this rule applies to this particular word.6 It is then more a question of insufficient knowledge and thus, a competence error.
Spelling errors often give rise to non-existent words (a non-word error) as in the example above, but they can also lead to an already lexicalized string (a real
word error).7 For example, in the sentence in (3.1), the string damen also violates the consonant doubling rule and deviates from the intended correct word dammen ‘dam [def]’ by omission of ‘m’. However, in this case the resultant string coincides with an existent word damen ‘lady [def]’.8 The error still concerns the single word, but differs from non-word errors in that the realization now influences not only the erroneously spelled string but also the surrounding context. The newly-formed word completely changes the meaning of the sentence and gives rise to a sentence with a very peculiar meaning, where a particular lady is not deep.
(3.1) Men but
∗damen (⇒dammen)
lady [def] (⇒dam [def])
¨ar is inte not s˚a that djup. deep – But the dam is not so deep.
Homophones, words that sound alike but are spelled differently, are another example of a spelling error realized as a real word. The classical examples are the
6The word gubbe ‘old man’ was used only once in the text. 7
Usually around 40% of all misspellings result in lexicalized strings (e.g. Kukich, 1992). The notion of non-word vs. real word spelling errors is a terminology used in research on spelling (cf. Kukich, 1992; Ingels, 1996).
8