A Framework for
O
utlier Detection Using Improved
Bisecting k-Means Clustering Algorithm
K.Swapna
1, Prof. M.S. Prasad Babu
21Research Scholar, Department of Computer Science and Systems Engineering, AU College of Engineering (A),
Visakhapatnam, INDIA. E-mail: [email protected]
2Professor, Department of Computer Science and Systems Engineering, AU College of Engineering (A), Andhra University,
Visakhapatnam, INDIA.E-mail: [email protected]
Abstract
—
The aim of this paper is to design an automatic liver diagnosis system to detect liver diseases early and accurately to help reduce the increasing deaths caused by liver diseases. With this automatic diagnosis system early diagnosis can be done and treatment can be made easy and immediately. Physical data considered for this study is collected from various pathological laboratories from southern India and annotated from expert Gastroenterologists. One of the dataset considered is from Indian liver patient dataset (ILPD) available in the UCI machine repository has 583 records and the physical data collected has 500 records which form a total of 1083 records. Automatic diagnosis tools may reduce burden on doctors. Since common attributes were found in both the datasets considered for the analysis, this paper evaluates the selected outlier algorithms and clustering algorithms using the proposed frame work for clustering liver patient datasets without outliers. These algorithms are evaluated based on four criteria: Accuracy, F-measure, Entropy and Purity. Our interest is to analyze these datasets which would contribute to better understand the system and help us develop an Automatic liver diagnosis system.Index Term--
Liver
datasets, Outlier detection, Cluster-based Bisecting k-Means, cluster validation.I. INTRODUCTION
Data mining techniques are very popular and they can be applied in diverse areas including information retrieval and medicine. Detecting outliers has many important applications in data preprocessing as well as in mining abnormal points among the data points. There are various outlier detection methods in data mining and they are classified into different classes such as model based, density based, connectedness, distance based, cluster based, k-Nearest neighbor etc. In the above methods, cluster based and distance based are familiar to user, simple, easy to implement and efficient. To produce better result with less computational time cluster based algorithm and the distance based algorithm are merged [12]. Clustering is one of the most important techniques used in data mining to find interesting patterns and structures from the hidden information in datasets. In clustering various methods such as hierarchical clustering, partitional clustering, density-based clustering etc. are used. In these methods hierarchical clustering is one of the best method for generating the clusters properly, which follows the dendrogram technique. In this technique all objects are arranged in a tree structure, split or merge operation produces required clusters. This method either my use top –down or bottom-up approach and measures proximity between clusters using either Singe
link(SLA) or complete link (CLA) or Average link (AvgLink) methods. One of the common measuring link used for clusters’ excellence is the group average method Unweighted Pair Group Method with Arithmetic Mean (UPGMA) or weighted Pair Group Method with Arithmetic Mean (WPGMA)[1]. Partitional clustering method is one of the simplest iterative method which uses many algorithms like k-Means, k-Mediods etc. The k-Means algorithm is used in the clustering is advantageous to hierarchical clustering, is often the better quality clustering approach, but is limited because of its quadratic time complexity. The standard k-Means algorithm takes initial centroids as data points, and finds out the mean value for every center every iteration until the desired number of clusters are obtained. The k-Means algorithm always produces results with less time complexity than hierarchical clustering algorithms [3]. Bisecting k-Means algorithm is one of the algorithm, which merges both hierarchical and partitional techniques. It is the bottom up approach in hierarchical and k-Means iterative method is used to get better clusters with less computational time. The k-Means its variants like bisecting k-k-Means have a time complexity that is linear in the number of items, but are thought to produce inferior clusters [10]. In this paper we designed a hybrid clustering approach which combines two or more widely used clustering algorithms like k-Means, bisecting k-Means and hierarchical clustering methods, so that it generates better quality clusters. The experimental results demonstrate that the proposed improved bisecting k-Means method out performs the standard k-k-Means and bisecting k-Means clustering methods. In this paper a framework that uses the proposed improved bisecting k-Means clustering algorithm and cluster based distance outlier detection algorithm. This new proposed frame work generates number of clusters initially and later eliminates the outliers by using threshold value for every clusters.
II. RELATED WORK
clustering algorithms namely k-Means, hierarchical, density-based algorithms applied with ILPD liver dataset, gave better performance. But hierarchical SLA /CLA and k-Means algorithms show equal performance, k-Means algorithms gave less computational time when compared to other algorithm [3].Various researchers suggested combination of hierarchical and partitional clustering algorithms to achieve better clustering .Hybrid hierarchical agglomerative algorithm which uses the (SLA) or (CLA) merge partition clustering technique and proposed new algorithm for cluster quality [11]. Bisect k-Means algorithm is a combination of divisive hierarchical and k-Means partitional algorithm. In this bisect k-Means gives better result of standard k-Means algorithm, Hybrid Bisect k-Means clustering algorithm uses bisect k-Means for divisive clustering algorithm and UPGMA for agglomerative clustering algorithm with document clustering to generate clusters better with less computational time when compared with standard k-Means and bisecting k-Means algorithm [10]. In this paper we would be using hybrid bisecting k-Means and other distance calculated method, WPGMA and proposed new improved bisectingk--Means clustering algorithm for better quality of clusters with less computation time. We also proposed a frame work for generation of clusters and thereby eliminating of outliers at the same instant in the liver data set. In frame work cluster- based and distance outlier detection algorithm is used to improve bisecting k-Means clustering algorithm by replacing k-Means for better results.
III. PROBLEM DEFINITION
The objective of the proposed frame work is to find clean data by preprocessing and to increase the accuracy of cluster analysis. In this study attention is placed on preprocessing, so that it removes the outliers and missing values so data set becomes clean and improves grouping of data, and consequently the clustering results. The proposed framework is shown in Fig.1.This frame work has cluster- based distance outlier algorithm, in that using Improved bisecting k-Means clustering algorithm. This framework initially groups the data into number of clusters, taking the threshold value to remove outliers. This phase generates number of clusters and eliminates outliers at the same instant Finally it compares the cluster result with the class labels in the dataset to get accuracy and justify by Purity ,Entropy, F-measure the cluster validation techniques. This frame work efficiently generates better clusters and finds out the outliers with less computational cost compared to other outlier and clustering algorithms.
IV. EXPERIMENTAL DATASET
This study uses two data sets totaling 1083 records of which 651 are liver patients and 432 are non-liver patients. The first being ILPD which is from UCI Machine Learning Repository data set [8] comprising 583 liver patient’s records with 10 attributes (obtained from eight blood tests). The second data set (Physically collected) of 500 records is collected from various pathological labs in south India, with 13attributes (obtained from ten blood tests). The common
attributes in these data sets are Age, Gender, TB, DB, ALB, SGPT, SGOT, TP, A/G ratio and Alkphos. Out of these attributes TB (Total Bilirubin), DB (Direct Bilirubin), TP (Total Proteins), ALB (albumin), A/G ratio, SGPT, SGOT and Alkphos are related to liver function tests, used to measure the levels of enzymes, proteins and bilirubin levels which helps for the diagnosis of liver disease. The description of ILPD Dataset Attributes and Normal values of attributes are shown in (Table. I)
TABLE I
ATTRIBUTES IN LIVER DATASET
Attributes Information(Normal Value)
Age Age of the patient
Gender Gender of the patient
TB (LFT) Total Bilirubin (0.22-1.0 mg/dl ) DB (LFT) Direct Bilirubin (0.0-0.2 mg/dl ) Alkphos (LFT) Alkaline Phosphotase (110-310U/L) SGPT (LFT) Alamine Aminotransferase (5-45U/L) SGOT (LFT) Aspartate Aminotransferase (5-40U/L)
TP (LFT) Total Protiens (5.5-8gm/dl)
ALB (LFT) Albumin(3.5-5 gm/dl )
A/G Ratio (LFT) Albumin and Globulin Ratio (>=1)
Fig. 1. Proposed Framework CADBOD
Classification Algorithms were considered for evaluating their classification performance in terms of Accuracy, Precision, Sensitivity and Specificity in classifying liver patient’s dataset as ILPD [18]. In classification of dataset the class label is needed, in clustering class label is not needed to classify the data. Every time labeling the data is very challenging, therefore an attempt is made to develop a framework to automate this process based on cluster analysis.
The proposed method is tested on Indian Liver Patient Dataset (ILPD), a real world dataset available in UCI Machine Learning Repository. But, it has only 583 records and with 10 dimensions those records are not sufficient do the experiment for clustering. Forman (1984) recommends a minimum sample size 2m , where m equals the number of clustering dimensions[17].
V. METHODOLOGY
A. Proposed Improved bisecting k-Means clustering Algorithm
Bisecting k-Means algorithm is a combination of divisive and agglomerative clustering algorithms. Our method uses bisecting k-Means algorithm for divisive clustering algorithm and WPGMA for agglomerative clustering algorithm. WPGMA is a good choice when there is a reason to eliminate size differences between the resulting groups [15]. The proposed bisecting k-Means clustering algorithm is a combination of two or more algorithms, so its accuracy would be better than individual algorithms. Initially cluster the data elements by using bisecting k-Means clustering algorithm and later obtain cluster centroids. After forming the cluster centroids apply WPGMA method on those obtained cluster centroids. If two centroids ended up in same cluster, then they are said to belong to same cluster. In the proposed algorithm we used WPGMA method for distance calculation of centroids and the method is not as complex as UPGMA.WPGMA also works with inconsistency values. The procedure for both methods is different but final output results are same. So WPGMA is used in proposed clustering algorithm for easy implementation and less computational time.
Algorithm:
Input: cluster with
n
data items andk
(number of clusters) Output:n
individual data items ink
clusters.Steps:
1. Starts with all cluster points in one single cluster. 2. Find 2 sub-clusters using the basic kMeans
algorithm
3. Find distance between those 2 sub clusters 4. If (
sub_cluste
r_1
>
sub_cluste
r_2
)split divide sub_cluster_1 into 2 clusters else
Divide sub_cluster_2 into 2 clusters.
5. Repeat step 2, 3, 4, the bisecting step, for no .of iteration time and take the split that produces the clustering with the highest overall similarity.
6. we use WPGMA and getting
k
centroid clusters. 7. In finally we use the refinement in the step forcentroids of clusters until getting k-clusters.
Fig. 2. Proposed IBKM clustering algorithm
B. Outlier Detection:
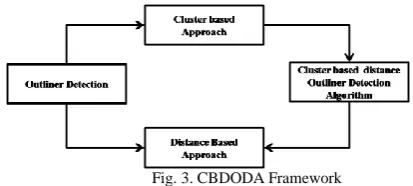
The data typically consists of patient records which may have several different types of features such as patient age, blood group, weight have temporal as well as spatial aspect to it. The data can have outliers due to several reasons such as patient's abnormal condition or instrumentation errors or recording error. Outlier is a pattern which is dissimilar with respect to the rest of the patterns in the dataset .This study uses cluster based distance outlier detection algorithm [12] which merges the distance based and cluster based outlier detection method
Fig. 3. CBDODA Framework
Cluster Based Approach:
Clustering is a popular technique, used to group similar data points or objects into groups or clusters. Clustering is an important tool for outlier analysis. Cluster- based approach is primarily group data having similar characteristics and calculate the centroids for each group.
Distance-Based Approach
Distance based approach is used to calculate maximum distance value for whole data. This approach gives only one value as most expected outlier. To find the distance between points with its neighbor, different dissimilarity measures are used such as Euclidean distance, cosine distance, city block distance, etc. This does not require any a priori of data distributions as the statistical methods. But in this approach it is needed to define the threshold parameter.
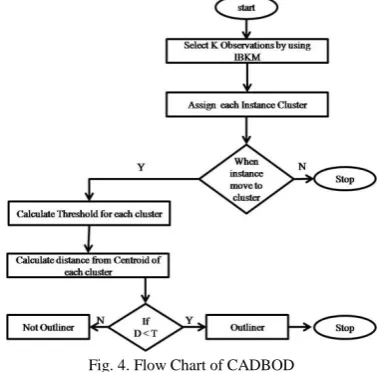
Framework based on cluster analysis for distance based outlier detection (CADBOD)
This outlier detection algorithm uses Hybrid Approach combining two techniques. This method performs by applying proposed improved bisecting k-Means clustering algorithm, replacing existing k-Means algorithm for better efficiency, which partition the dataset into number of clusters and then for each cluster finds out outliers from the given dataset using threshold value.[12]
Algorithm:
Input: The set of points
n
, number of clustersk
Output: O, clustering with outlier result set Steps:1. Generate clusters using IBKM clustering algorithm 2. Calculate Threshold % for each cluster.
i. Find the minimum and, maximum for each cluster. ii. Find the maximum distance (D) from the centroid. iii. Take threshold value T from the user.
Cluster validation
Entropy,
F
-measure, and Purity are the most frequently used external quality measures in addition to the interpretability of the result.Entropy: Entropy provides a measure of ring randomness. It specifies whether the particular data is constantly falling into same cluster or not. The Entropy of a clustering is
H(Ω) =∑ H(w) ( N_w/N)
Where Ω= {w1, w2…..wk.} is the set of clusters, H (w) is a single clusters Entropy Nw is the number of points in cluster
N is the total number of points.
F-measure: F-measure provides a measure of Accuracy. It is based on recall and precision measures used in evaluation of an information retrieval system.
) (TP FP
TP precision
) (TP FN
TP recall
Purity: Purity measures the quality of the clusters.
FN FP TN TP
TP Purity
TP=Tue positive, TN=True negative FP=False positive, FN=False negative
VI. EXPERIMENTAL RESULT
The proposed clustering algorithm and the outlier detection framework are implemented using Java , and the these algorithms are applied to the selected experimental dataset. The results are interpreted and validated based on the indices Accuracy, Entropy, F-measure and Purity.
TABLE II
PERFORMANCE OF CLUSTERING ALGORITHMS
Algorithms Accuracy Entropy F-Measure Purity
k-Means 64.2 0.2821 0.5642 0.7423
Bisecting KM 75.2 0.3614 0.6723 0.8214 Improved BKM 81.5 0.4331 0.7372 0.8923
From the results, it is found that the proposed clustering algorithm IBKM produces high quality clusters in terms of accuracy, entropy, F-Measure and purity than that of k-Means and Bisect k-k-Means . The IBKM algorithm takes less computational time to process the given dataset to generate good clusters.
Fig. 5. Performance Evaluation of Clustering Algorithms
The proposed outlier detection framework has been implemented and tested on experimental dataset. The results are compared with the results of Distance based outlier algorithm (DBOA), proposed IBKM.
TABLE III
ELAPSED TIME COMPARISON OF OUTLIER AND CLUSTERING ALGORITHMS
Algorithm Elapsed Time
Distance based Outlier algorithm (DBOA) 0.412453 s
Improved Bisecting k-Means (IBKM) 0.21353 s
CADBOD Framework 0.2975 s
Comparing above three algorithms, IBKM algorithm took less computation time and compared with the DBOA and CADBOD algorithm. But CADBOD can cluster and eliminate outlier at the same instant as one algorithm, DBOA can operate on whole data but cannot cluster the data, so that computational time increases. When comparing the total computational time of DBOA and IBKM is greater than that of CADBOD. So then CADBOD is proved to individually run the outlier algorithm, clustering algorithm take more time complexity. We can use the hybrid approach CADBOD in Fig. 4. Flow Chart of CADBOD
) (
) * (
* 2
recall precision
recall precision Measure
F
single instant gives the complete result with comparatively less time than individual algorithms.
VII. CONCLUSIONS
In this paper an improved version of bisecting k-Means algorithm known as Improved Bisecting k-Means Algorithm (IBKM) is proposed. The proposed algorithm generates better clusters which cannot be achieved if we run them individually. Clusters generated by the IBKM algorithm are compared with the clusters generated by the k-Means, bisecting KM algorithm with respect to the parameters Accuracy and three evaluation metrics Entropy, F-measure and Purity of clusters. It is found that the proposed IBKM algorithm outperforms the both k-Means algorithm and bisecting K-means algorithm and produces better clusters. In addition to IBKM, a framework based on cluster analysis for distance based outlier detection (CADBOD) is proposed. In the proposed framework, IBKM is used for clustering the dataset. The result of this phase gives efficient clusters without outliers, in a single instant with less computational time. The proposed frame work is very help full for developing software based automatic liver diagnose system.
ACKNOWLEDGMENTS
We sincerely thank the expert Gastroenterologists Dr. Srinivas Rao and Dr. Srinivas Baba for their highly valuable contribution and cooperation.
REFERENCES
[1] A. K. Jain and R. C. Dubes, Algorithms for Clustering in Data. Prentice Hall, 1988.
[2] M. Steinbach, G. Karypis, and V. Kumar, “A comparison of document clustering techniques,” in KDD workshop on text mining, vol. 400, Department of Computer Science and Engineering University of Minnesota. Cite seer, 2000, pp. 525– 526.
[3] K.Swapna, Prof. M.S.PrasadBabu and B. Jogeswara Rao “Clustering of ILPD Dataset with k-Means, hierarchical and DBSCAN Algorithms” paper was presented in 102nd Indian
Science Congress Association., Mumbai 2015.
[4] B. Larsen and C. A one, “Fast and effective text mining using linear-time document clustering,” in Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining KDD 99, vol. 5. ACM Press, 1999, pp. 16–22. [5] Han, J., Kamber, M. and Tung, A. 2001. Spatial clustering
methods in data mining: A survey. In Miller, H., and Han, J., eds., Geographic Data Mining and Knowledge Discovery. Taylor & Francis
[6] Hartigan, J., A. and Wong, M., A. 1979, “ A k-Means Clustering Algorithm”, Applied Statistics, Vol. 28, No. 1, pp. 100-108. [7] B. S. Everitt, S. Landau, and M. Leese, Cluster Analysis, ser.
Social Science Research Council Reviews of Current Research. Arnold, 2001, vol. 33, no. 1.
[8] Y. Zhao, G. Karypis, and U. Fayyad, “Hierarchical clustering algorithms for document datasets,” Data Mining and Knowledge Discovery, vol. 10, no. 2, pp. 141–168, Mar. 2005.
[9] R. Chitta and M. NarasimhaMurty, “Two-level k-Means clustering algorithm for k–_ relationship establishment and linear-time classification,” Pattern Recognition, vol. 43, no. 3,pp. 796– 804, Mar. 2010. 71
[10] KeerthiramMurugesan and Jun Zhang “HYBRID BISECT k-MEANS CLUSTERING ALGORITHM”2011 International conference on business computing and Global information.
[11] P. Vijaya, M. NarasimhaMurty, and D. Subramanian, “An efficient hybrid hierarchical agglomerative clustering (HHAC) Technique for partitioning large data sets,” in PReMI, ser.Lecture Notes in Computer Science. Berlin, Heidelberg: Springer Berlin Heidelberg, 2005, pp. 583–588.
[12] Ms. S. D. Pachgade, Ms. S. S. Dhande “Outlier Detection over Data Set Using Cluster-Based and Distance-Based Approach “Volume 2, Issue 6, June 2012, IJARCSSE,ISSN: 2277 128X. [13] The Indian liver patient dataset (ILPD)is from UCI machine
repository in the area of life science. The ILPD data set is available
in following hyper
linkhttp://archive.ics.uci.edu/datasets/ILPD+(indian+liver+patient+ Dataset )
[14] Prof. M.S.PrasadBabu, prof.M.Ramjee, someshKatta, k.swapna “Implementation of Partitional Clustering on ILPD Dataset to Predict Liver Disorders” ” paper was presented in IEEE 7th
international conference on software engineering and service science. Beijing, china.
[15] Fionn Muztagh School of Computer Science The Queen's University of Belfast Belfast BT7 1NN, Northern Ireland [email protected] “Clustering in Massive Data Sets” July 10, 2000
[16] M. J. Dallwitz “A flexible clustering method based on UPGMA and ISS”1988.
[17] M. Sarstedt and E. Mooi, A Concise Guide to Market Research, Springer Texts in Business and Economics, DOI 10.1007/978-3-642-53965-7_9, # Springer-Overflag Berlin Heidelberg 2014. [18] Bendi Venkata Ramana, Prof. M.Surendra Prasad Babu2 Prof. N.