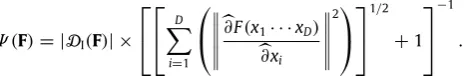Other uses, including reproduction and distribution, or selling or
licensing copies, or posting to personal, institutional or third party
websites are prohibited.
In most cases authors are permitted to post their version of the
article (e.g. in Word or Tex form) to their personal website or
institutional repository. Authors requiring further information
regarding Elsevier’s archiving and manuscript policies are
encouraged to visit:
Contents lists available atScienceDirect
Journal of Mathematical Psychology
journal homepage:www.elsevier.com/locate/jmp
Categorical invariance and structural complexity in human concept learning
Ronaldo Vigo
∗Cognitive Science Department, Indiana University at Bloomington, Bloomington, IN, 47401, USA Psychology Department, Ohio University, Athens, OH, 45701, USA
a r t i c l e i n f o
Article history:
Received 26 June 2007 Received in revised form 12 March 2009
Available online 10 June 2009
Keywords:
Concept learning Categorization Rule-based classification Logical manifold Categorical invariance Logical invariance Structural complexity Boolean complexity Invariance Complexity Concepts
a b s t r a c t
An alternative account of human concept learning based on an invariance measure of the categorical stimulus is proposed. The categorical invariance model (CIM) characterizes the degree of structural complexity of a Boolean category as a function of its inherent degree of invariance and its cardinality or size. To do this we introduce a mathematical framework based on the notion of a Boolean differential operator on Boolean categories that generates the degrees of invariance (i.e., logical manifold) of the category in respect to its dimensions. Using this framework, we propose that the structural complexity of a Boolean category is indirectly proportional to its degree of categorical invariance and directly proportional to its cardinality or size. Consequently, complexity and invariance notions are formally unified to account for concept learning difficulty. Beyond developing the above unifying mathematical framework, the CIM is significant in that: (1) it precisely predicts the key learning difficulty ordering of the SHJ [Shepard, R. N., Hovland, C. L., & Jenkins, H. M. (1961). Learning and memorization of classifications. Psychological Monographs: General and Applied, 75(13), 1–42] Boolean category types consisting of three binary dimensions and four positive examples; (2) it is, in general, a good quantitative predictor of the degree of learning difficulty of a large class of categories (in particular, the 41 category types studied by Feldman [Feldman, J. (2000). Minimization of Boolean complexity in human concept learning.Nature, 407, 630–633]); (3) it is, in general, a good quantitative predictor of parity effects for this large class of categories; (4) it does all of the above without free parameters; and (5) it is cognitively plausible (e.g., cognitively tractable).
©2009 Elsevier Inc. All rights reserved.
1. Introduction
1.1. Invariance
Invariance principles are ubiquitous in the physical sciences. A simple example of one such principle in physics involves the lines of magnetic force. These lines form closed loops that have the property that for any volume enclosing them the number of lines entering the volume is equal to the number of lines leaving the volume. This property is sometimes referred to as the property of incompressibility and it remains regardless of the way that we alter the space defined by the volume. That is, the property is invariant in respect to deformations of the space such as stretching, twisting, cutting, or bending.
Another example of invariance-based principles in physics involves both the theory of Special Relativity and General Relativity. Both theories aim to identify under what space–time coordinate transformations the laws of physics remain invariant. Lastly, topology, one of the most vital fields of mathematics, is roughly defined as the study of those properties of figures
∗Corresponding address: SCOPE Lab, 337 Porter Hall, Ohio University, Athens,
OH 45701, USA.
E-mail addresses:[email protected],[email protected].
that are invariant under continuous transformations that have a continuous inverse.
In a similar spirit, cognitive scientists have resorted to invariance principles in order to explain a variety of cognitive phenomena such as memory, perception, and concept learning. For example, in pioneering work,Garner (1963,1970)andGarner and
Felfoldy(1970) developed the idea that the degree of invariance
of a form determines how good a pattern is perceived to be. More specifically,Garner(1974) explores the relationship between what he calls ‘‘goodness of pattern’’ to the concept of information redundancy in the form of regularities in the stimulus structure.
Under this approach, structural regularities are characterized in terms of the size of mutually exclusive subsets of the set of visual stimuli. These subsets are generated by subjects asked to group together visual patterns under a similarity criterion. A good model of the generated subsets is to regard them as equivalence classes of patterns that can be generated from each other by a combination of rotations and reflections.Garner(1963) showed that the size of these equivalence classes is a good predictor of goodness of pattern judgments: for example, the smaller the size of a subset of visual patterns that are judged similar (i.e., the greater its redundancy and regularity), the higher the degree of pattern goodness that will be assigned to a visual pattern within the subset.
Like Garner,Leyton(1992) in his book ‘‘Symmetry, Causality, and Mind’’ uses invariance principles to explain cognitive
ena. However, this time the phenomena in question are memory processes. Leyton posits that the mind assigns to any shape a causal history explaining how the shape was formed. By examining shape in terms of its inherent symmetries, he argues that symmetry is a key component to cognitive processing. Thus, he is able to reduce aspects of visual perception to symmetry or invariance principles. In tune with this idea, Imai (1977) and more recently
Hahn, Chater, and Richardson (2003) proposed that similarity
judgments may be determined by transformational distance. More specifically, the degree of similarity between two objects is characterized by these researchers in terms of the number of transformations necessary to convert one into the other.
Hahn et al. (2003) give experimental evidence that seems to
show that transformational distance strongly influences similarity judgments. Interestingly, unlike the previously discussed theories of invariance, rather than ascertaining under what transformations an object’s structure remains invariant, Hahn and associates ask how many (and what type of) relevant transformations are necessary to achieve a kind of deterministic variance.
In our theory, we follow this tradition of using invariance as an explanatory principle for cognition, but we do so from an entirely different perspective and aim. We wish to introduce an elegant and natural mathematical framework for the study of invariance in human concept learning in terms of the languages of logic and analysis. This approach is rather natural since, as we shall see, the concepts we will focus on (i.e., Boolean concepts) are concepts learned from categories that are plainly definable in terms of logical rules or logical expressions from Boolean algebra in the first place. We focus on Boolean categories since these are the simplest nontrivial cases we can study. In fact, Boolean categories also play an important role in the landmark theories of human concept learning that we shall use as benchmarks for our own.
Two of these landmark theories, the exemplar theory (Medin
& Schaffer, 1978;Nosofsky,1986) and prototype theory (Rosch &
Mervis, 1975), may be characterized as mental process theories
based on similarity assessment representations. Under prototype accounts of human concept learning concepts are prototypical representations or central tendencies of the exemplars associated with the concept. A novel stimulus is then classified on the basis of its similarity to the prototype. On the other hand, under exemplar accounts of concept learning (Medin & Schaffer, 1978;Nosofsky, 1986), a novel stimulus is classified by determining how similar it is to the stored exemplars of a category and those of a contrasting category.
For example, Nosofsky’s Generalized Context Model (GCM) (1984, 1986) is a formal generalization of the exemplar theory of
Medin and Schaffer(1978). The model owes a great deal to the
theory of multidimensional scaling (Shepard,1962,1974) and to Luce’s choice probability theory (1959). The GCM is based on three key ideas. The first of these is the characterization of subjective similarity as an inverse exponential function of the Euclidean distance between stimuli in some psychological space as described by Shepard’s universal law of generalization (Shepard, 1987).
The second is Luce’s classic Similarity Choice Model (SCM) for predicting identification responses (Luce, 1963). In Luce’s model, the probability that a stimulusielicits a responsejin an identification experiment is given by
p
(
rj|
si)
=
bjs
(
i,
j)
nP
k=1
bks
(
i,
k)
(1.1)
wherebjandbkare parameters indicating response biases,s
(
i,
j)
is a similarity measure between the stimuliiandj, and the indexkin the denominator ranges over the set of stimuli that are eligible as responses in the experiment.The third key idea in the GCM is the inclusion of a parameter
w
i representing the selective attention allocated to dimensioni. The distance between stimuli in some psychological space is then defined asd(
x,
y)
=
P
i
w
i· |
xi−
yi|
for separable (selectively attendable) dimensions. In the GCM the probability that category Cwill be selected given stimulusyisp
(
C|
y)
=
bC·
P
x∈C
FCx
·
s(
x,
y)
P
α bα·
P
k∈α
F
α
k·
s(
k,
y)
.
(1.2)This is the ratio between: (1) aggregate similarities of the stimulus
y to the exemplars in C, and (2) the sum of the aggregate similarities of the stimulusyto the members of the contrasting categories
α
. The parameterbαis the response bias for categoryα
andFα
kis a parameter indicating the frequency of occurrences of the exemplarkin categoryα
(Kruschke, 2006). Thus, the processes of similarity, attention, and choice are combined to explain and predict the likelihood of a correct categorization decision, making the GCM a probability-based process account of classification behavior.This and other exemplar accounts have great intuitive and parsimonious appeal and have led to connectionist models that have been successful at quantitatively predicting degrees of concept learning difficulty. One of the most successful of these models is ALCOVE (Kruschke, 1992)—a connectionist model of exemplar-based categorization inspired by Nosofsky’s Generalized Context Model (1986). The dynamic adaptive nature of these process theories stands in sharp contrast to the ‘‘static’’ structural accounts of human concept learning discussed above: these aim to determine the degree of concept learning difficulty based solely on the structural properties of the categorical stimulus (Garner, 1974) and do not make assumptions about what is possibly taking place in the human mind before categorical decisions are made and while concepts are being learned or formed.
Indeed, in ouranalytico–structuralaccount of Boolean concept learning, we will introduce a measure of the structural charac-teristics of the stimulus that are good predictors of the degree of learning difficulty experienced when learning it. As discussed, our stimulus-driven modeling paradigm is not very different from that of psychophysics, which examines whatGibson(1966) refers to as the energetic properties of the stimulus (its physical properties) as opposed to its informational properties as reflected in its structure.
1.2. Cognitive complexity
Most structural accounts do not have at their core invariance notions. Ever since the seminal work ofMiller(1956) which sought to identify the limits of human short-term memory capacity, there has been much interest on how the complexity of a task or of a stimulus may influence our ability to perceive it, memorize it, learn it, and make decisions and inferences about it. We refer to this property as the cognitive complexity of the stimulus. An example of this idea in applied domains is found in the work
ofWang and Shao(2003) on program design. These researchers
proposed a measure of software code complexity based on cognitive weights. Cognitive weights are numbers representing the degree of difficulty for comprehending particular types of basic control structures in programming code. These weights combine to give an overall sense of the clarity, effectiveness, and correctness of the software.
shortest propositional formula that is logically equivalent to the original full DNF formula describing the category type.
Under this approach lie the common suppositions that: (1) there are structural properties intrinsic to a stimulus that can be used to describe how complicated the stimulus is, and (2) that such properties are good predictors of the learning difficulty of the stimulus. Our own model will offer an alternative notion of complexity that we shall refer to as ‘‘structural complexity’’ and that will be based on invariance principles.
More specifically, in the theory we introduce in Sections3–5 the structural complexity of a categorical stimulus will be a function of both its inherent degree of invariance and its cardinality (size). This definition in turn will be used to predict the degree of learning difficulty associated with each categorical stimulus. In general, our approach may be viewed as a synthesis of invariance and complexity notions. Thus, on average, categories with the greatest degree of categorical invariance – and hence, a relative lowest degree of structural complexity – should be easiest to learn. This is because invariance tells us the way in which objects in a category are interrelated at a higher level.
We shall discuss Feldman’s m-complexity model (i.e., minimization-based complexity model) in detail in Section 3in order to bring to the fore some of the problems that our alterna-tive invariance-based model of complexity will be able to solve. We shall also discuss briefly a more recent structural account by
Feldman(2006) based on the idea of the spectral decompositions
of Boolean categories.
1.3. Invariance, complexity, and process
Although the structural properties of a Boolean category may help us predict its degree of learning difficulty, we are left with the question as to how these structural properties influence learnability. In other words, what is the connection between the concept learning process and the structural properties of the categorical stimulus? To answer this question we propose a companion computational theory hypothesis to our structural account. In Sections4and5, as we present our formal model, we shall fill in the missing details.
Under our hypothesis, it is invariance that determines the degree of perceived simplicity of the stimulus and it is excessive demands on working memory capacity during the invariance detection process that determine the degree of subjective learning difficulty. Intuitively, this makes sense. The more pattern perceived in a structure, the simpler it seems to be: the more tractable. Invariance plays the role of simplicity while category size plays the role of raw complexity in our model. However, these two properties act together in synergy to determine the overall structural complexity of a category.
In contrast, Garner(1974) believes that it is subset size (see the discussion above on Garner), rather than symmetry that is the pertinent factor in determining cognitive performance. He writes on page 17 (Garner, 1974): ‘‘If symmetry is so directly related to pattern goodness, why don’t we just say that symmetry is the pertinent factor, rather than subset size? The answer lies partly in the fact that symmetry is a sufficient but not necessary condition for producing small subset sizes, even with these simple stimuli. Symmetry is simply one way in which the stimulus may be manipulated to produce variations in subset size, but its mode of action is via subset size rather than by symmetry per se.’’
This conclusion by Garner may have been the result of the absence of a function in his formal framework that could meaningfully measure the degree of total invariance of each stimulus independent of the equivalence class or subset it is grouped in. With such a measure at our disposal, we believe that symmetry information is necessary to make predictions about
goodness of pattern judgments. Notwithstanding, it will be shown that in respect to concept learning, both the degree of symmetry and category size are intimately tied up and play an important and synergistic role in determining structural complexity and ultimately concept learning difficulty.
To derive an invariance measure of the stimulus we introduce a mathematical framework based in part on what is known in Boolean circuit theory as the Boolean differential operator. The framework introduces the notion of the logical manifold
operator of a Boolean category in order to: (1) generate the degrees of invariance or symmetry of a category in respect to its dimensions, and (2) generate the space of degrees of symmetry of a Boolean category family (we shall describe these ideas in detail in Section3). Consequently, it is proposed that the category types within a category family can be naturally ordered by both the maximal invariance value and the frequency of the maximal invariance value of their logical manifolds. This ordering points the way toward a method for meaningfully measuring degrees of ‘‘global’’ invariance.
The method involves measuring the Euclidean distance of the logical manifolds of the category types from a zero origin. This is significant since distance metrics have proven unsuccessful in making concept learning predictions in discrete feature domains. For example,Lee and Navarro(2002) found that ALCOVE
(Kruschke, 1992), perhaps the most successful exemplar model,
could not fit discrete-feature categories well without a metric sensitive to the featural structure of the space: as will be seen, in our approach, invariance is defined in terms of an ordinary metric that, by virtue of being applied to points in invariance space, is sensitive to feature structure.
Although our model is structural in nature, we can reasonably speculate whether the mathematical operators that compute the invariance of the categorical stimulus may also be construed as functional descriptions of an information processing system, and therefore as the basis for a theory of computation. To understand this point, it is helpful to consider Marr’s three levels of description of an information processing system (Marr,1982;Poggio,1981): the computational or behavioral level of description (e.g., the functional description or the description of what the device does), the algorithmic and representational level of description (e.g., the description of the representation of acquired information and of the algorithms defined over such representation), and the physical implementation level of description (i.e., the description of the physical device that is capable of actualizing what is described by the first two levels).
More specifically, in Marr’s work on vision, the computational level of description specifies the mathematical operations that facilitate the goal of a theory of vision: namely, to construct a three-dimensional representation of distal stimuli on the basis of inputs to the retina. For example, Marr introduces a differential operator (i.e., the Laplacian) capable of detecting intensity changes in light energy at an initial stage of processing as the basis of his computational level of description (Poggio, 1981).
On a different note, another significant and unique aspect of our logico–analytic structural model will be that it does not depend on choice probabilities nor on multiple parameters as is the case with the mental process models discussed in the previous section. This is significant since most cognitive models are of the statistical and probabilistic variety. Our successful excursion into non-probabilistic domains can only help expand the cognitive modeling horizon.
The outline for the remainder of this treatise is as follows. First, we will give a brief introduction to Boolean categories, the classification of these in terms of typed families, and Feldman’s two models of Boolean complexity. We then shall discuss some of the challenges facing the minimization-based complexity model as a prelude to our theory. In Section 3, we will introduce our mathematical framework for economically characterizing and identifying degrees of invariances or symmetries in Boolean categories. This will be followed by our characterization of structural complexity in terms of degrees of invariance.
The core idea underlying our discussion will be that an
invariance-basedmeasure of structural complexity is a good pre-dictor of Boolean concept learning difficulty; and more impor-tantly, that invariance, and not complexity, is the fundamental principle underlying human concept learning. In other words, since invariance determines structural complexity, it also determines and explains why some concepts are more difficult to learn than others. This assumption will be referred to as the categorical invari-ance theory of concept learning or ‘‘CIT’’ and its formal description will be referred to as the categorical invariance model of concept learning or ‘‘CIM’’.
Lastly, in Section 5 we will examine how well the CIM, without free parameters, predicts the difficulty ordering of sets of categories of the type studied byShepard, Hovland, and Jenkins (1961) consisting of three binary dimensions and four positive examples (i.e., 3(4) type categories), and more generally for the set of 41 category types studied byFeldman(2000). This is followed by a discussion of parity effects and the predictions made by our model when the 35 additional category types in down parity are included in our original set of 41 (76 category types in total). The paper ends in Section 6 where we summarize our results and discuss a list of open problems and research directions.
2. Boolean categories and complexity
2.1. Formal representation and notational preliminaries
Since we shall define Boolean categories using the language of Boolean algebra, we begin with a definition of a Boolean algebra and a Boolean expression (or formula). What follows should be regarded as a semiformal introduction to a few key concepts from Boolean algebra that are useful in the development of our categorical invariance model. For a more rigorous and detailed introduction to Boolean algebra, including its model theoretic details, the reader is referred toMendelson (1970,1979).
Definition 2.1. A Boolean Algebra is a sextuple
h
B,
0,
1,
+
,
·
,
0i
consisting of an arbitrary (carrier) set B together with two (distinct) elements 0 and 1, a negation operator0, and two binary operations+
and·
such that for all elementsx,
y, andzofB, the following axioms hold: Commutativity: (1a)x+
y=
y+
x, (1b)x
·
y=
y·
x; Associativity: (2a)x+
(
y+
z)
=
(
x+
y)
+
z, (2b)x
·
(
y·
z)
=
(
x·
y)
·
z; Distributivity: (3a)(
x+
y)
·
z=
(
x·
z)
+
(
y·
z)
, (3b)(
x·
y)
+
z=
(
x+
z)(
y+
z)
; Indempotency: (4a)x+
x=
x, (4b)x·
x=
x; Identity: (5a)x+
0=
x, (5b)x+
1=
1, (5c)x·
0=
0, (5d)x·
1=
1; Negation: (6a)(
x0)
0=
x, (6b) 00=
1, (6c) 10=
0; and De Morgan: (7a)(
x+
y)
0=
x0·
y0, (7b)(
x·
y)
0=
x0+
y0.We now define recursively the class of Boolean expressions. This is important since Boolean expressions (or Boolean formulae) will be used to define Boolean categories.
Definition 2.2. The classF of Boolean expressions (or Boolean formulae) is defined recursively as follows (wherenis an arbitrary positive integer):
(1) The Boolean variablesa
,
b,
c,
d,w,
x,
y,
z, A,
B,
C,
D,
W,
X,
Y
,
Z,x1, . . . ,
xn,y1, . . . ,
yn,z1, . . . ,
zn, and the constants 0 and 1 are elements ofF.(2) If
ϕ
∈
F andψ
∈
F then(ϕ
+
ψ)
∈
F,(ϕ
·
ψ)
∈
F, andϕ
0∈
F.(3) Nothing else is an element ofF.
The Boolean variables above are variables with 1, 0, and elements of the carrier setBas their possible values. To simplify our exposition, we shall adopt certain notational conventions regarding the classF of Boolean expressions defined above. First, whenever there is no ambiguity, we shall drop parentheses from Boolean expressions. Also, following the notational conventions of the Boolean algebra of propositional logic, we will use the symbol ‘‘
∼
’’ interchangeably with ‘‘0’’, the symbol ‘‘∨
’’ interchangeably with the symbol ‘‘+
’’, and the symbol ‘‘∧
’’ interchangeably with the symbol ‘‘·
’’. Finally, ifϕ
andψ
are Boolean expressions, we shall abbreviateϕ
∧
ψ
andϕ
·
ψ
withϕψ
. Boolean expressions and Boolean functions are intimately connected as may be seen from the following.Definition 2.3. LetBbe the carrier set of a Boolean algebraBand letB
=
B∪ {
0,
1}
. Ann-vary Boolean functionFnofBis a mapping from the cross product
Qn
i=1Bi toB(whereiandnare positive integers and for anyi,Bi=
B∪ {
0,
1}
). The value of the variablen is referred to as the degree of the function.It is well known that every Boolean expression determines a Boolean function (for details see Church, 1956; Mendelson, 1979). Given a Boolean algebra B
=
h
B,
0,
1,
+
,
·
,
0i
and a Boolean expressionµ
(v
1, . . . , v
n)
with variablesv
1, . . . , v
n, we can determine a corresponding Boolean functionµ
nB(v
1, . . . , v
n)
such that for everyn-tuple(
b1, . . . ,
bn)
∈
B,µ
nB(
b1, . . . ,
bn)
is the element ofBobtained by assigning the valuesb1, . . . ,
bntov
1, . . . , v
nrespectively, and interpreting the symbols ‘‘+
’’, ‘‘·
’’, and ‘‘0’’ to stand for the corresponding operations inB.
For example, according to the standard truth-table definitions of the Boolean operators ‘‘or’’ (written as ‘‘
∨
’’ or ‘‘+
’’ in our notation) and ‘‘not’’ (written as ‘‘0’’ or ‘‘∼
’’ in our notation) the Boolean expressiona0+
b0determines the Boolean functionf2(
a,
b)
which, in respect to the two-element Boolean algebra containing the carrier set B
=
{
0,
1}
, maps the set of ordered pairs{h
0,
0i
,
h
0,
1i
,
h
1,
0i
,
h
1,
1i}
, corresponding to the possible values of the variablesaandbin the expression to the set{
0,
1}
as follows:f2
:
(
0,
0)
→
1,f2:
(
0,
1)
→
1, f2:
(
1,
0)
→
1, andf2
:
(
1,
1)
→
0.Henceforth, we shall use the following superscripted lower-case letters of the Latin alphabet to stand for particular Boolean functions: fn
,
gn,
hn; and the upper-case letters Fn,
Gn,
Hn to stand for arbitrary Boolean functions (where n is the degree of the function as defined in Definition 2.3). Also, whenever the arguments of the function are specified, we shall drop the superscriptn. Finally, we shall refer to Boolean functions applied to their arguments also as ‘‘Boolean functions’’, even though they are technically not functions. For example, although the expressionf2
(
a,
b)
refers to the result of applying a particular functionf2tothe variablesaandb, we nonetheless shall, as is common practice, refer to the entire expression as a ‘‘Boolean function’’.
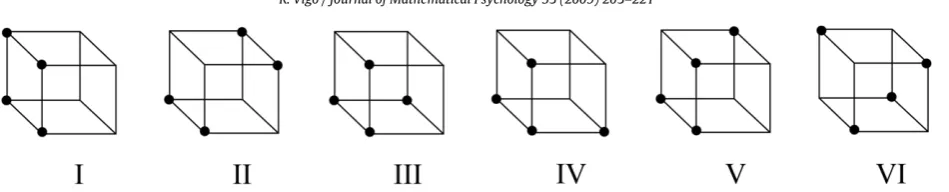
Fig. 2.1. Family of categories with three binary dimensions and four positive examples graphed in Boolean space. These are known as the Shepard, Hovland, and Jenkins (SHJ) category types.
objects defined by Boolean expressions. Thus, they are what some logicians refer to as the extension of a Boolean function (see
Church, 1956for a discussion of thenotion of extensionality). These
expressions define sets of objects when each of their distinct variables is interpreted as a distinct dimension. The values of the variables (i.e., 0 or 1) can then be interpreted as one of two possible features. For example, if we let the variablexstand for the binary dimension of color (binary because we restrict its range to two possible values) andyfor the binary dimension of shape, then, by lettingx
=
red,
x0=
black,
y=
round,
andy0=
square, we can define the Boolean set or category consisting of a black round object and a red square object with the Boolean expressionx0y+
xy0. Boolean expressions or formulae thatcompletelydefine Boolean categories are, like the expression in our previous example, indisjunctive normal form(DNF). Before defining what it means for a formula to be in disjunctive normal form, we define afundamental conjunction as either (1) a literal (i.e., a negated or unnegated variable), or (2) a conjunction of two or more literals no two of which involve the same variable (where by a conjunction we mean a product of Boolean expressions and by a disjunction we mean a sum of Boolean expressions). For example, whilexyz(abbreviation forx
∧
y∧
z) is a fundamental conjunction,xyx0is not a fundamental conjunction since the literalsxandx0involve the same variablex.A Boolean formula
ϕ
is said to be in DNF if either (1)ϕ
is a fundamental conjunction, or (2)ϕ
is a disjunction of two or more fundamental conjunctions (as long as not all of the literals of any fundamental conjunction inϕ
occur in any other fundamental conjunction inϕ
). Furthermore, there is a special type of DNF, known as afullDNF, which we will be particularly interested in since the types of categories inShepard et al.(1961) and inFeldman(2000,2003a)assume this form.
A Boolean expression
ϕ
in DNF is said to be infull DNF in respect to its variablesx1, . . . ,
xnif (1) any variable inϕ
is one of the variablesx1, . . . ,
xn(i.e.,ϕ
is closed under the set of variables{
x1, . . . ,
xn}
), and (2) each disjunct inϕ
contains all the variables x1, . . . ,
xn. An important theorem in the Boolean algebra states that any Boolean function that is not a self-contradiction (i.e., equal to zero under all possible truth-value assignments to its variables) is logically equivalent to a DNF expression.Categories defined by full DNF formulae have been studied extensively by investigators such asShepard et al.(1961),Bourne (1966), and more recently byNosofsky, Gluck, Palmeri, McKinley,
and Glauthier(1994) andFeldman(2000). Of particular interest
are the Boolean categories investigated byShepard et al.(1961) consisting of three binary features or dimensions and four examples (four positives) and four non-examples (four negatives) for a total of eight stimuli. (Later,Feldman(2000) refers to these types of categories as the 3(4) family of ‘‘concepts’’ where the numeral 3 denotes the number of binary dimensions or features and the numeral 4 denotes the number of positive stimuli1). For example, suppose that the dimensions involved are those of shape,
1 Although the terms ‘‘concept’’ and ‘‘category’’ are often used interchangeably in the literature, we advice against such practice. Accordingly, in this paper, we reserve the term ‘‘concept’’ to refer to the mental object, mental event, or mental
size, and color; if we letxstand for triangular,x0stand for round,
ystand for small,y0stand for large,zstand for white, andz0stand for black, then one of the categories studied by Shepard et al. can be expressed by the Boolean formulax0y0z0
+
x0y0z+
x0yz0+
x0yz, where the symbol ‘‘+
’’ stands for the logical operatoror.In other words, the formula perfectly defines the category associated with objects that are either round, large, and black, or round, large, and white, or round, small, and black, or round, small, and white. Note that each of the four conjunctionsx0y0z0,
x0y0z,x0yz0, andx0yz in the formula above represents a positive example of the category, while the remaining four out of eight (23)
possible conjunctions or logical products represent non-examples or negative examples of the category. Since in this paper we shall use Boolean formulae exclusively to define Boolean categories, then each Boolean formula in full DNF should be understood as denoting a Boolean category. That is, in our discussion, all Boolean formulae are mathematical representations of well-defined categories.
Although there are 70
C48
=
( 8!8−4)!4!
possible ways of select-ing four positive examples out of a total of eight possible objects, subsets of these 70 are structurally isomorphic or structurally re-ducible to each other. This is apparent when considering that in a Boolean expression defining a Boolean category, the choice of la-bels (i.e., literals) for the various features as well as their negation is arbitrary, so that any Boolean expression generated from another as the result of a consistent reassignment of labels and their nega-tion defines the same category structure as the original. For exam-ple, the category consisting of a black circle and a white square is structurally equivalent to the category consisting of a black square and a white circle, and both are defined byxy
+
x0y0or byxy0+
x0y. Structural equivalence can also be illustrated geometrically using a Boolean cube (see Fig. 2.1). The relationship between the four points representing the four disjuncts in the Boolean expression is invariant in respect to rigid rotations of the cube. It turns out that there are exactly six such structural relationships that partition the set of all possible Boolean categories 3(4) (three dimensions and four positive examples) into six subsets or equivalent classes (for an in depth combinatorial discussion seeAiken (1951) or Higonnet and Grea(1958)). These six category
types combined are referred to as the 3(4) family of Boolean categories. More generally, aD(p)family of Boolean categories is a set consisting of all the category types withDdimensions andp
positive examples.
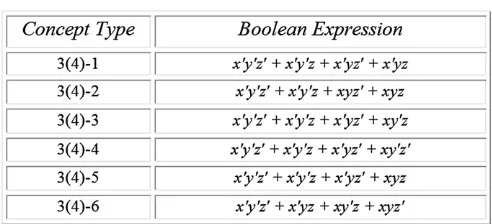
Members of the 3(4) category family are represented inFig. 2.1 as points in Boolean Space and in Fig. 2.2as Boolean functions in full DNF. Whenever convenient, we use Roman numerals as abbreviations for the longer Arabic numeral descriptions of category types involving the number of dimensions and positive examples: e.g., type I is a shorthand for 3(4)-1.
Fig. 2.2. Boolean expressions corresponding to the Shepard, Hovland, and Jenkins category types.
These six types were studied by Shepard et al.(1961) who measured the degree of learning difficulty by the number of errors that subjects made until reaching a criterion for correct classifications. It was found that the six category types listed in
Figs. 2.1and2.2followed the following order of learning difficulty:
I
<
II<
III,
IV,
V<
VI. Thus type I problems involving the simplest concept or category structure yielded the least number of errors, followed by type II, followed by types III,
IV,
V which yielded approximately the same number or errors, and finally type VI. This ordering, known as the SHJ ordering, has served as a fundamental benchmark for models of human concept learning (for a discussion seeNosofsky et al.(1994)).2.2. Minimization–complexity hypothesis
Feldman(2000), motivated by theShepard et al.(1961) study,
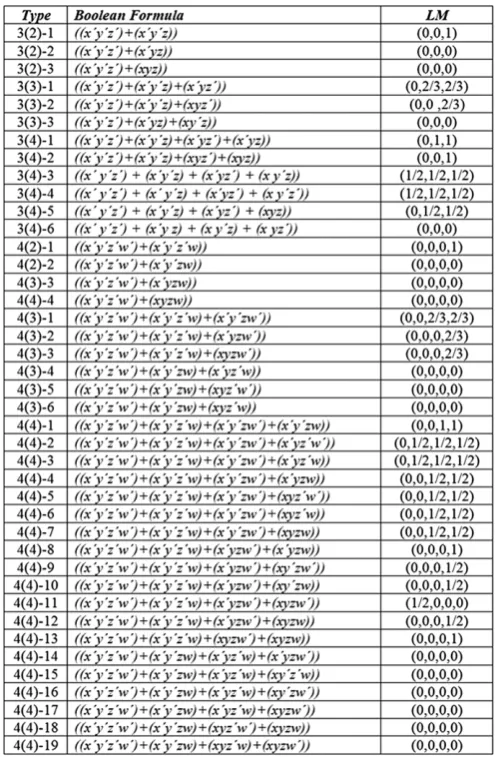
sought to find a connection between the degree of learning difficulty of a Boolean category and what he defines as its Boolean complexity. As defined byFeldman(2000,p.630): ‘‘The Boolean complexity of a propositional concept is the length of the shortest Boolean formula logically equivalent to the concept, usually expressed in terms of the number of literals (positive or negative variables)’’. Feldman’s study examines an unprecedentedly large number of Boolean category families including the SHJ family: these included the 3(2), 3(3), 3(4), 4(2), 4(3), and 4(4) families for a total of 41 Boolean category types.
In addition, Feldman pays close attention to families where the number of positive and negative examples differ. For example, 3(2) categories each have two positives and six negatives and their mirror image has six positives and two negatives. Feldman refers to this distinction as a distinction in the parity of the Boolean category, where the category is in up parity when the number of positive examples is smaller than the negative examples and in down parity when the positives examples are swapped for the negatives.
Taking complexity (and parity) as his independent variables and proportion of correct responses as his dependent variable, he concludes from the data that, in general, subjective difficulty is well predicted by Boolean complexity and category parity. Clearly, since parity cannot be tested for the SHJ types, Boolean complexity is then the sole independent variable in regards to the SHJ types. Moreover,Feldman(2000,p. 630) claims: ‘‘When the SHJ types are considered from the perspective of mathematical logic, however, a simple explanation of the difficulty ordering emerges: the difficulty of the six types is precisely predicted by their Boolean complexity.’’ He adds later in page 631 that: ‘‘These Boolean complexity values predict the order of empirical difficulty precisely. This exact correspondence has not previously been noted, though Shepard et al. speculated about it in their original paper, and the relation between Boolean complexity and human learning has never been comprehensively tested.’’
Under this approach lie the suppositions (1) that there are structural properties intrinsic to a stimulus that can be used to describe how complicated the stimulus is, and (2) that such properties are good predictors of the learning difficulty of the stimulus. Unfortunately, Feldman’s minimization-complexity hypothesis has faced strong challenges. For one, Feldman himself has acknowledged that the simplification (i.e., minimization) heuristic ofFeldman(2000) based on factorization alone may not be cognitively plausible (Feldman, 2003b).
Secondly, the complexity values reported byFeldman(2000) are not in fact the minimal values for 9 of the 41 category types
(Vigo, 2006). Of particular concern is the fact that the actual
minimal expressions corresponding to the SHJ types do not reflect the SHJ ordering (see Vigo, 2006, for a discussion) and make the overall complexity predictions less significant. Henceforth, we refer to the complexity model that is based on the actual minimal expressions as the ‘‘strongm-complexity model’’, and likewise, we refer to the model implemented byFeldman(2000) in his Nature paper as the ‘‘weakm-complexity model’’.
Feldman (2006), aware of these difficulties, has recently
introduced his spectral decomposition model. LikeGarner(1970) the basic idea is that learning from examples involves the extractions of patterns and regularities. The formal model describes how a pattern (expressed in terms of a Boolean rule) may be decomposed algebraically into a ‘‘spectrum’’ of component patterns, each of which is a simpler or more ‘‘atomic’’ regularity. Regularities of higher degree represent more idiosyncratic patterns while regularities of lower degree represent simpler patterns in the original decomposed pattern. The full spectral breakdown of the component patterns of a Boolean category in terms of minimal component regularities is known as the power series of the pattern. These are expressed in terms of what he calls implication polynomials.
An implication polynomialΦK of degreeKis an expression of the form
σ
1· · ·
σ
K→
σ
0 (where eachσ
i stands for a Boolean variable and each Boolean variable stands in turn for a particular dimension). These types of expressions are structurally equivalent or congruent to¬
(σ
1· · ·
σ
K+1)
(see the discussion above onstructural equivalence). It turns out that the union of categories of arbitrary degree can be expressed completely as the conjunction of the implication polynomials that each category satisfies. Given this fact, a natural measure of complexity would be to determine the number of rules of each degree (i.e., number of dimensions) that a given Boolean category satisfies. An obstacle to this is the fact that there are many possible structurally equivalent or redundant rules for each degree considered.
To address this problem, Feldman shows that in fact there is a minimal irredundant set of implication polynomialsP
(
x)
, wherexis a set of objects belonging to the category that is defined by the Boolean expression in question (for details seeFeldman, 2006). Based on this proposition he defines a measure of complexity for Boolean categories in terms of their power spectrum. LettingΦK
x denote the set of implication polynomials inP
(
x)
having degreeK, the power spectrum ofxat degreeKis denoted by
λ
K x and is simply the size or cardinality of the setΦxK (i.e.,λ
Kx= |
ΦxK|
). The algebraic complexity of a Boolean category is then defined by the weighted sum of its power spectrum:λ
T=
D−1X
K=0
w
Kλ
Kxwhere the weights
w
K are linear increasing inKand sum to zero (wherew
K∝
K,P
w
K=
0, andP
|
w
K| =
1). Thus, the model requires a weight per level of decomposition.As discussed, our ultimate goal is to devise a structural Boolean algebraic and analytic account of human concept learning that predicts and explains human concept learning difficulty based on invariance principles. As it turns out, this can be achieved without free parameters within the model. With this aim in mind, we proceed to answer the following question: what is it about the intrinsic structure of some Boolean categories that makes them more difficult to learn than others?
We suggest that the answer lies on a radically different notion of complexity which henceforth we shall call ‘‘structural complexity or invariance-based complexity (i-complexity)’’. Unlike the min-imization notion of complexity examined above (m-complexity),
i-complexity is based on both the inherent degree of invariance of the Boolean category and its size (i.e., cardinality). This synthesis of invariance and complexity notions may be regarded as a first step toward the conceptual unification of the various structural ac-counts of concept learning discussed above. Since the key quantity in our definition of structural complexity is the degree of categor-ical invariance, we lay the foundations for it next.
3. Logical manifold theory
3.1. The derivative of a Boolean category
In the previous sections we discussed how the structural properties of invariance and complexity, independently, have played a key role in the development of structural models. Also, we characterized our modeling approach (to be introduced in the next few sections) as unique in that it unifies these two fundamental structural properties in a simple and direct manner. Indeed, in our model, complexity and invariance may be understood as inverses of each other! However, although complexity will play an important role in our model, it is invariance that is the crux of the model, since it is invariance (along with cardinality) that will determine the degree of structural complexity of a stimulus in the first place.
In view of this, the key to our model is to find a way of characterizing in an economical, intuitive, and natural way, the degree of invariance inherent to a Boolean category, and how it bears on its structural complexity. We accomplish this by introducing next a mathematical framework that is a rudimentary hybrid of Boolean algebra, discrete topology, and analysis. The framework is based in part on a concept that is analogous to some extent to the derivative in calculus.
The Boolean derivative was introduced by Reed (1954) in a discussion of error-correcting codes in electrical circuits. The basic concept has been mainly relegated to this very specialized domain of applied Boolean algebra. A more comprehensive study and generalization of the concept can be found in Thayse (1981). Unfortunately, the notation found in the aforementioned papers is somewhat clumsy and counterintuitive in respect to our goals; hence, we have devised a different notation using the hatted partial derivative operator suggestive of (two) discrete states.
In addition, the concepts that we are about to define, including the logical manifoldof a category, the logical norm, invariance signatures, and the rest of our mathematical framework (in short, ‘‘logical manifold theory’’), including the derivations of our invariance order, measures of invariance, and the invariance ‘‘laws’’ based on these, are all original contributions to the field. In fact, as far as we know, this is the first time that simple core concepts from analysis, discrete topology, and Boolean algebra have been integrated in this fashion with the goal of measuring degrees of categorical invariance. Next, we proceed with a discussion of the Boolean derivative.
The Boolean derivative is an effective formalism for revealing the invariance information intrinsic to Boolean categories. The derivative of a Boolean expression is defined as follows.
Table 3.1
Definition of the ‘‘exclusive-or’’ connective.
x 1 0 1 0
y 1 1 0 0
(x⊕y) 0 1 1 0
Definition 3.1. LetF be a Boolean function ofn
≥
1 variablesx1
· · ·
xn, then its Boolean partial derivative in respect toxi(where 1≤
i≤
n) is defined asb
∂
F(
x1· · ·
xn)
b
∂
xi=
F(
x1· · ·
xi· · ·
xn)
⊕
F(
x1· · · ∼
xi· · ·
xn).
The symbol ‘‘
⊕
’’ stands for the ‘‘exclusive-or’’ operator defined by the truth-table inTable 3.1.Note that the Boolean partial derivative is analogous to the partial derivative in Calculus since in both we evaluate how the dependent variableF
(
x1· · ·
xi· · ·
xn)
changes in respect to a change in the independent variablexi. As in differential calculus, we define thenth-order Boolean partial derivative of a Boolean function as the result of taking the Boolean partial derivative of the Boolean partial derivative of the Boolean partial derivative etc. of the function a total ofntimes as illustrated below (note that b∂1F(x1···xi···xn)b∂xi1
below is the same thing asb∂F(x1...xn)
b∂xi ):
b
∂
nF(
x1· · ·
xi· · ·
xn)
b
∂
xni=
b
∂
nb
∂
xnib
∂
n−1b
∂
xn−1
i
· · ·
b
∂
1F
(
x1
· · ·
xi· · ·
xn)
b
∂
xi1
!!
.
Henceforth, we shall use the following shorthand for the partial Boolean derivative of a Boolean function:
b
∂
F(
x1· · ·
xn)
b
∂
xi=
b
∂
xiF(
x1· · ·
xn).
Although higher-order Boolean partial derivatives (i.e., of order greater than one) are all equal to zero, they are nonetheless useful in generating equivalent but distinct Boolean expressions. The partial Boolean derivative of a Boolean expression acts as a test for logical equivalence in that it determines whether or not the Boolean expression obtained by replacingxiwithx0iis equivalent to the original.
For example, if we letF
(
x,
y)
=
xy, then the resulting Boolean derivative ofF(
x,
y)
in respect toxisxy⊕
x0y. If we construct a truth table for this new expression we obtain the value true or 1 whenyis true and the value false or 0 whenyis false. Thus, for this expression, the value of its Boolean derivative can be predicted by the value of the variabley. The key idea to remember here is that the derivative of this function iscontingentupon the value ofy.To facilitate our analysis, we evaluate the Boolean derivatives of Boolean expressions using truth tables. Truth table analysis allows us to identify under which truth-value assignments to its variables the Boolean derivative is true. If it is true under all possible truth-value assignments to its variables, then we say that the Boolean derivative is a tautology; on the other hand, if it is false under all its possible truth-value assignments then we say that it is a self-contradiction. When the Boolean derivative is neither a tautology nor a self-contradiction, it is called a contingency.
Fig. 3.1. Boolean partial derivatives of the category types studied byShepard et al.(1961).
same figure, contingencies are represented by expressions in full DNF.
But how do these truth-value invariances translate into the degree of qualitative invariance of a Boolean categorical stimulus? Recall that category types are defined by Boolean expressions whose variables represent binary dimensions. Thus, the application of the partial Boolean derivative to an expression that defines a particular category first transforms the objects of the category along one dimension, and then logically ‘‘subtracts’’ the newly obtained category from the original category.
For example, take the Boolean expressionx
+
y(i.e., ‘‘xory’’) whose DNF isxy0+
x0y+
xy. In this latter expression, if we assign the valueblackto the variablexrepresenting the color dimension and assign the valuecircularto the variableyrepresenting the shape dimension, then we say thatxy0+
x0y+
xydefines the category consisting of three objects, namely, a black triangle, a white circle, and a black circle, as illustrated inFig. 3.4. Accordingly, the expressionxy0+
x0y+
xyevaluates to true or 1 under only three out of four possible truth-value assignments: namely, the assignments (1, 0), (0, 1), and (1, 1). These three pairs of values correspond to (black, triangular), (white, circular), and (black, circular) under our interpretation, and the fact that they satisfy (i.e., make true) the expressionxy0+
x0y+
xyindicates that they are members of the category that the expression defines.Now, the Boolean derivative ofxy0
+
x0y+
xyin respect tox (the variable standing for the dimension of color) is the logical difference (as defined by the exclusive-or operator⊕
) betweenxy0
+
x0y+
xy(the expression that defines the original category described above), andx0y0+
xy+
x0y(the expression that defines its correspondingperturbedcategory). In our example, this perturbed category consists of awhite triangle, ablack circle, and awhite circle, as illustrated inFig. 3.4, and like in the original category defined byxy0+
x0y+
xy, those truth-value assignments that satisfy the expressionx0y0+
xy+
x0yrepresent the objects or exemplars in the perturbed category.The logical difference between the expressions that define the two categories simply tells us which objects in the original category are also in the perturbed category. This can be verified by examiningFig. 3.4. The basic idea is that, of the truth-value assignments that satisfy (i.e., make true)xy0
+
x0y+
xy, those thatdo notsatisfy its Boolean derivative are precisely those that are equivalent tox0y0
+
xy+
x0yand hence, those with corresponding exemplars or objects in the perturbed category defined byx0y0+
xy+
x0y. The reason is that the logical difference between two Boolean expressions evaluates to 0 only when the two expressions are equivalent (i.e., are satisfied or made true by the same truth-value assignments).3.2. The logical norm
In Section3.1, we showed that, with an appropriate measure of the Boolean derivative, it might be possible to express quantitatively the degree of partial invariance inherent to a Boolean category. In this section we introduce such a measure.
The goal is to measure the degree of qualitative invariance that is revealed by an application of the Boolean partial derivative operator on a Boolean category (or more precisely, on the Boolean expression that defines it).
The intuition behind such a measure is that it must be a count of the number of items from the original category that are preserved in the derived (or perturbed) category. This is achieved by finding out for each possible truth-value assignment that satisfies (i.e., makes true) the Boolean expression that defines the category, whether or not it alsodoes not satisfy the Boolean derivative of the Boolean expression that defines the category. The idea is that, if false, that particular conjunction representing an item in the category has been preserved in the perturbed category. If, on the other hand, the particular conjunction evaluates to true then it has not been preserved in the perturbed category.
For the remainder of this paper, a category family type will be denoted byD
(
p)
, whereDis the number of binary dimensions andpis the number of given positive examples. When referring to a specific category type, sometimes we shall use the notationD
(
p)
−
t, wheret is a number used inFeldman’s catalogue of categories (2003a) to denote the particular members within a family. Boolean expressions that we shall use to define Boolean categories are assumed to be in full disjunctive normal form. Such expressions provide a full description of the dimensional structure of a category. Finally, we use the capital bold letters of the Latin alphabetF,G, and Hto stand for arbitrary Boolean expressions intended to define Boolean categories and we shall use the lettersF
,
G,
H for the Boolean functions determined by these Boolean expressions. Likewise, we shall abbreviate the Boolean expression corresponding toF(
x1· · ·
xi· · ·
xn)
withFxiandF(
x1· · · ∼
xi· · ·
xn)
withFx0 i.
Moreover, we define an instantiated fundamental conjunction (see Section 2 for a definition of a fundamental conjunction) as a vector of truth values that is the result of replacing each literal in the fundamental conjunction for a truth value depending on whether the variable is negated or not. Formally, we define the instantiation function
γ
as a mapping from a set of literalsL
= {
t1, . . . ,
tn}
to a set of truth valuesV= {
0,
1}
such that∀
ti∈
L, γ (
ti)
=
0 whenever ti is negated andγ (
ti)
=
1 wheneverti is not negated (whereiandnare positive integers). Then, the instantiated fundamental conjunction consisting ofnliterals t1
. . .
ti. . .
tn is the vector of truth values defined byI
(
t1. . .
ti. . .
tn)
=
γ (
t1) . . . γ (
ti) . . . γ (
tn)
. For example,I(
xyz0)
=
110 andI(
xy0z0w)
=
1001. Throughout our discussion, and as previously alluded to, we assume that these vectors of truth values (or strings) correspond to stimuli in categories whenever each of their components is systematically and consistently interpreted as a value of the particular relevant dimension across all categories in question.In addition, we define the setA0
(
F)
as the set of truth-valueassignments represented also as vectors of zeros and ones (as above) for which the Boolean expression F (not necessarily in DNF) is false. Likewise,A1
(
F)
is the set of truth-value assignmentsFig. 3.2. Boolean partial derivative in respect toxof the 3(4)-3 category type. The exclusive-or operation (in the middle of the Boolean expression) is represented by ‘‘⊕’’ while ‘‘or’’ is represented by ‘‘+’’ and ‘‘and’’ is represented by ‘‘ˆ’’.
the Boolean expressionF(not necessarily in DNF) is true. Also, we defineD
(
F)
as the set of fundamental conjunctions of a Boolean expression in full DNF andDI(
F)
= {
I(
c)
|
c∈
D(
F)
}
as the setof instantiated fundamental conjunctions ofFin full DNF. This set can also be interpreted as the set of truth-value assignments that satisfy (i.e., assign a value of 1 to)F. Clearly,
|
D(
F)
| = |
DI(
F)
| =
pandDI
(
F)
=
A1(
F)
(seeMendelson(1979,for a proof of the latter).We can now justify why it is that the Boolean partial derivative is indeed a qualitative indicator of invariance between the original Boolean category or category of items and the derived category.
To achieve this goal let us examine the intuitive way of measuring the invariance expressed by the Boolean partial derivative. First, consider that the Boolean partial derivative
F
(
x1· · ·
xi· · ·
xn)
⊕
F(
x1· · · ∼
xi· · ·
xn)
compares two Boolean expressionsF(
x1· · ·
xi· · ·
xn)
and F(
x1· · · ∼
xi· · ·
xn)
that define two categories respectively. We shall refer to the category defined by F(
x1· · ·
xi· · ·
xn)
as the original category FO and tothe category defined by F
(
x1· · · ∼
xi· · ·
xn)
as the ‘‘perturbed’’ category FP. If we represent the stimuli (i.e., objects) of the categories by the instantiated conjunctions of the DNF expressions that define them, then FO=
DI(
F(
x1· · ·
xi· · ·
xn))
and FP=
DI
(
F(
x1· · · ∼
xi· · ·
xn))
.Then, the simplest way of measuring the invariance expressed by a partial Boolean derivative is by taking the ratio between the number of exemplars that the original category and the perturbed category have in common and the number of exemplars in the
original category. More formally,
|
FO∩FP|
|
FO|
. The problem with this
expression is that it has been formulated in terms of categories and not in terms of the formal properties of the logical description of such categories. Of course, since what we wish to build is a model of invariance in Boolean algebraic terms, we then use the following definition instead.
Definition 3.2. Let F be a Boolean expression that defines a Boolean category. The logical norm orL-norm ofFin respect toxi is defined as
b
∂
Fb
∂
xi=
DI(
F)
∩
A0(
b
∂
xiF)
|
DI(
F)
|
.
The basic idea behind this measure is that the number of truth-value assignments that satisfyFand that are in the set of truth assignments that do not satisfy the derivative ofFare precisely the truth-value assignments representing the preserved objects in the perturbed categoryFP. For a proof that this logical measure of qualitative invariance is equal to the intuitive measure
|
FO∩FP|
|
FO|
, seeProposition A.1in theAppendix, which states that|DI(F)∩A0(b∂xiF)|
|DI(F)|
=
|FO∩FP|
|FO| .
Example 3.3. From this definition it is clear that the L-norm of a function whose Boolean derivative is a tautology is 0 since
|
DI(F)∩A0(b∂xiF)|
|DI(F)|=
|DI(F)∩∅|
|DI(F)|
=
0
|DI(F)|
=
0
p
=
0, theL-norm of afunction whose Boolean derivative is a self-contradiction is 1 since
|
DI(F)∩A0(b∂xiF)|
|DI(F)|
=
|DI(F)∩{000,001,010,011,100,101,110,111}|
|DI(F)|
=
|DI(F)|
|DI(F)|
=
1, and the L-norm in respect toxof the Boolean category F
=
x0y0z0+
x0y0z+
x0yz0+
xy0zcomputes to 12 since by truth table
analysis (seeFig. 3.2)A0
(
b
∂
xF)
= {
001,
011,
101,
111}
andDI(
F)
=
{
000,
001,
010,
101}
making|
DI(F)∩A0(b∂xF)|
|DI(F)|
=
2 4
=
1 2.
Again, it is important to recognize that, from a qualitative standpoint, the Boolean derivative may be construed as a relationship between two categories. As such, theL-norm is a direct measure of this relationship between the original Boolean category and the perturbed one with its changed dimensional value or feature (e.g., the color white to the color black). This is evident when considering the case of maximal logical identity between the two Boolean functions representing the two categories: that is, when every truth-value assignment to the Boolean derivative evaluates to 0 (i.e., a self-contradiction).
In this case, the two categories are identical since the Boolean expressions that define them are equivalent under every possible truth-value assignment to the Boolean derivative. More specifically, if the Boolean derivative of the Boolean expression that defines category FO evaluates to 0 or false (in respect to dimensiond) for any of its truth-value assignments, then each of the exemplars or objects that is inFOis also in the perturbed
categoryFP. Likewise, if the Boolean derivative of the function that defines categoryFOevaluates to 1 or true for all its possible truth-value assignments (i.e., is a tautology), this indicates that every object in categoryFOwill not be inFP.
Although the Boolean derivative along with itsL-norm gives us a means for measuring the degree of partial categorical invariance inherent to a Boolean category in respect to single dimensions, we still need a way of considering and combining invariances across theDdimensions of the Boolean category. To achieve this we introduce the notion of alogical manifold. Logical manifolds characterize the degree of invariance or symmetry of a Boolean category as a whole.
3.3. Logical manifolds
Thus far we have introduced the Boolean partial derivative as an operator on Boolean expressions capable of producing a Boolean expression that can potentially describe how much qualitative change a category undergoes as a whole when a featural change takes place along one dimension. Furthermore, we introduced the
L-norm of a Boolean partial derivative as a simple quantitative measure of the degree of invariance between a category and its corresponding perturbed category.