2082
A Fast And Energy Efficient Path Planning
Algorithm For Offline Navigation Using Svm
Classifier
Prabhu Ram Nagarajan, Vibin Mammen Vinod, Mekala V, Manimegalai M
Abstract: Nowadays finding a path comes in handy using navigation software like maps through GPS devices. In this setup, the visualizat ion of route in the maps requires path information from Google server for path and GPS position from GPS system (in-built) for locations. Hence there is a need of path information for visualization which is to be fetched from the internet. However the facility of fetching path information thr ough internet is not available in every region, especially at remote forest. In such cases, offline based navigation systems will be very helpful. Offline navigation system is designed by machine learning technique. Since it is very useful in predicting appropriate path in a deterministic manner without being explicitly programmed and also there is no need of path information to compute. Support Vector Machine (SVM) algorithm is implemented as a machine learning technique . A major classification and regression technique in Machine Learning is SVM. As the data sets of path information which is given as a training data sets are not linearly distributed, Radial Basis Function(RBF) is used as a kernel function of SVM algorithm. After trained by SVM algorit hm, it produces the hyper plane with enough margin to distinguish between the two datasets of human habitation path and the forest region. K mean clustering is used to find the centroid of human habitation path from the given datasets. The results of cluster datasets and model are saved for testing pu rpose. The trained SVM model is to be loaded to predict appropriate path with the input of current GPS position. The result of SVM output classifies whether the current GPS position is human habitation path or the forest region. The trained cluster of dataset is to be loaded which is used as for f inding direction. The shortest distance can be determined using cosine distance between the current GPS position and clusters of centroid datasets. The mini mum value is considered as the shortest distance and the direction is calculated between current GPS position and minimum valued cluster point.
Index Terms: Offline Navigation, GPS, SVM, Raspberry Pi.
—————————— ——————————
1 INTRODUCTION
With the development of mobile Internet, more people begin to get convenient service by mobile phones. Obtaining one's current location by GPS positioning or network positioning has become one of the important foundations in most applications of location based service. A navigation system is usually an electronic system that aids in navigation. Navigation systems may be capable of containing maps, which may be displayed in human readable format via text or in a graphical format. It helps to navigate in a correct path on their own. The navigation system uses the combination of GPS positioning and network positioning and the Google Map API to provide functions such as current location, navigation route, address query and viewing of historic location records. Nonetheless, for some regions, such as remote areas, the facility to access path information through the online navigation system is inadequate. Thus, offline navigation is useful for this purpose. Offline navigation system is designed using machine learning technique that handles programming where the system automatically learns and improves with experience without explicit programming. Since it is very useful in predicting appropriate path in a deterministic manner without being explicitly programmed and also there is no need of path information to compute. Support Vector Machine (SVM) algorithm is implemented as a machine learning technique. A major classification and regression technique in Machine Learning is SVM. K mean clustering is used to find the shortest distance.
2
MACHINE
LEARNING
Machine learning is a branch of science that deals with programming the systems in such a way that automatically learn and improve with experience without being explicitly programmed. The process of learning begins with observations or data, such as examples, direct experience, or instruction, in order to look for patterns in data. The primary aim is to allow the computers learn automatically without human intervention or assistance and adjust actions accordingly.
2.1 SUPERVISED LEARNING
Supervised learning is a type of machine learning algorithm that uses a labeled dataset called the training dataset. On training the dataset will generate a model of hypothesis prediction. The training dataset includes input data and response values. From it, the supervised learning algorithm seeks to build a model that can make predictions of the response values for a new dataset. A test dataset is often used to validate the model. The system is able to provide targets for any new input after sufficient training. The learning algorithm can also compare its output with the correct, intended output and find errors in order to modify the model accordingly
Supervised learning includes two categories of algorithms:
Classification is for categorical response values, where the data can be separated into specific classes
Regression is for continuous-response values
2.2 CLASSIFICATION
Throughout machine learning and statistics, classification is the question of defining to which group of categories a new observation belongs to, on the basis of a training set of data containing observations or instances. Classification is considered an instance of supervised learning, i.e. learning where a training set of correctly identified observations is available. An algorithm that implements classification, ————————————————
• Prabhu Ram Nagaragajan is currently working as Assistant Professor in Electronics and Communication Engineering in Kongu Engineering College, Erode. E-mail:[email protected] • Vibin Mammen Vinod, Mekala V and Manimegalai M are currently
2083
especially in a concrete implementation, is known as a classifier. The term classifier also refers to the mathematical function, implemented by a classification algorithm that maps input data to a category.
Support vector machines (SVM)
Neural network
Naive Bays classifier
Decision trees
2.3 SUPPORT VECTOR MACHINE
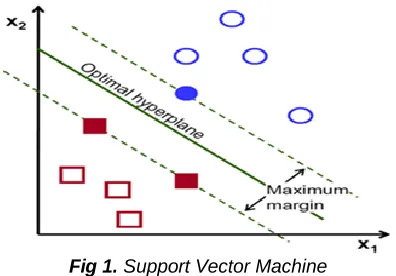
Classifying data has been one of the major parts in machine learning. The idea of support vector machine is to create a hyperplanes between data sets to indicate which class it
Fig 1. Support Vector Machine
belongs to. Support vector machines are supervised learning models with associated learning algorithms which analyze data used for the analysis of classification and regression. It is primarily a classifier method that performs classification tasks in a multidimensional space by constructing hyperplanes. Support vectors are the data points nearest to the hyperplane as in Fig 1., the points of a data set that, if removed, would alter the position of the dividing hyperplane. Because of this, the critical elements of a data set are considered. In SVM, there is the hyperplane line that linearly separates and classifies a set of data. If the data points lie away from the hyper plane, then the points are classified correctly. Therefore, hyperplane is to be trained based on data set. The distance between the hyper plane and the nearest data point from either set is known as the margin. The goal is to choose a hyper plane with the greatest possible margin between the hyperplane. An SVM is a mathematical entity, an algorithm for maximizing a particular mathematical function with respect to a given collection of data.
2.3 KERNEL FUNCTION
The kernel function is a mathematical trick that allows the SVM to perform a ‗two-dimensional‘ classification of a set of originally one-dimensional data. In general, a kernel function projects data from a low-dimensional space to a space of higher dimension.
( ) (1)
In (1) for all x1and x2 of the input space, with certain functions
K(X1,X2) can be expressed as an inner product in another
space.
2.3.1 LINEAR KERNEL FUNCTION
The Linear kernel is the simplest kernel function. It is given by the inner product (x,y) plus an optional constant c. Kernel
algorithms using a linear kernel are often equivalent to their non-kernel counterparts.
(2)
In (2) y is the training inputs and c is an optional constant.
2.3.2 POLYNOMIAL KERNEL FUNCTION
The polynomial kernel function is directional, i.e. the output depends on the direction of the two vectors in low-dimensional space.
𝑥 𝑦 𝑥 𝑦 𝑐 (3)
In (3) x and y are vectors in the input space, i.e. vectors of features computed from training datasets and c ≥ 0 is a free parameter trading off the influence of higher-order versus lower-order terms in the polynomial. When c = 0, the kernel is called homogeneous. The parameter d is the degree of polynomials of kernel function. If d= 1, then the kernel function behaves as like that of linear kernel functions.
2.3.3 RADIAL BASIS FUNCTION
Radial basis function is one of the most popular kernel functions. It adds a ―bump‖ around each data point.
e ‖ ‖
(4)
‖ − ‖
is the squared Euclidean distance between the two feature vectors, which is the standard Euclidean distance can be squared in order to place progressively greater weight on objects that are farther apart. Squared euclidean distance is not a metric as it does not satisfy the triangle in equality; however, it is frequently used in optimization problems in which distances only have to be compared. It is also referred to as quadrance within the field of rational trigonometry. σ is a free parameter. The parameter γ / σ2
. Since the value of the RBF kernel decreases with distance and ranges between zero and one.
3 RELATED
WORK
2084
Fig 2. Training Phase and Testing Phase
descriptive features that is more probable of contributing towards the improvement in effectiveness of the proposed algorithm. The collection of features are evaluated according to their fitness goodness. This technique is used, in the management of urban transport network networks. It was implemented first in a binary case and then generalized to the classifications of multiclasses. Hui Zhao et.al.,(2007)[3] proposed and developed a Non-linear SVM Decision Tree based Classification Method. In this paper, described the hybrid classifier of SVM algorithm and decision tree algorithm into one multi-class classifier to solve multi-class classification problems. SVM is extended to non-linear SVM by using kernel functions and a new method of NSVM decision tree is proposed based on traditional SVM decision tree. Ebha Koley, et.al.,(2017)[2] proposed and developed a scheme based on ANN and SVM for protection of power transmission lines, considering the role of non-linear loading condition. A Kalman filter processes the post-fault voltage signals to estimate the harmonic components which serve as feature vectors for performing SVM and zone identification fault detection and classification as well as ANN position. SVM-based discrimination of fault increases selectivity and precision. Dan Meng, Guitao Cao et.al.,(2016)[1] proposed and developed Automated Human Physical Function Measurement Using Constrained High Dispersal Network With SVM-Linear. This paper presents a novel feature extraction method based on using constrained high dispersal network for depth images and coped with Support Vector Machines (SVM) to measure human physical function. The proposed method can catch the most representative features of depth images belonging to different actions and statuses. We analyze the representation efficiency of hand-crafted features (HOG features, and LBP features), deep learning features (CNN features) and our proposed deep learning features separately in order to validate the efficiency and accuracy of our proposed method. The results show superior performance of 85.19% on 3840 samples (three actions, each with four different statuses, and
every status contains sixteen sequences) when the proposed deep features combined with SVM..
4 METHODOLOGY
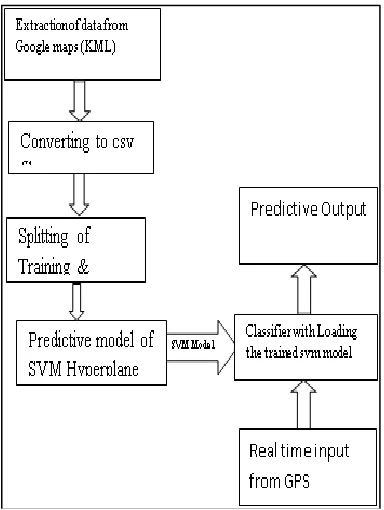
The data sets (latitude and longitude co-ordinates) are extracted from the Google maps, by placing a layer of path over Google maps. The layers are exported in the form of KML file as dataset. The minidom method is employed to parse the dataset using xml.dom package in python script. The dataset as string of text information is further preprocessed by removing tags, splitters like ―\n‖, ― ‖etc., Finally cleaned dataset are reformed into numpy array using numpy package for numerical computation in SVM. The dataset are packed with data called co-ordinates and label as terrain path, forest path. The dataset contains of about 600 points of latitude and longitude co ordinates About 100 co ordinates are path co ordinates and 500 are terrain coordinates. The path co ordinates are labeled as 1 and terrain co ordinates are labeled as 0The SVM model is trained by loading the dataset and optimizing the parameters. In Support Vector Machine is trained with Radial Basis Function as kernel function because the dataset is non linear in nature and it classifies the dataset based on the weights of the labels. If the optimized parameters are found then an hyperplane with RBF kernel is generated. The hyperplane is used to classify the dataset. The SVM model is stored using pickle called SVM model. The saved SVM model is then loaded to the testing phase. The real time co ordinates are obtained using the GPS. SVM prediction is used ,if it is 1 then the clusters of the hyperplane is isolated. The isolated clusters are used as end point for the prediction path. The Real time data is then compared with all the isolated cluster centers and the nearest node is chosen and its direction and path is displayed.
4.1 RASPBERRY PI
The Raspberry Pi is a series of small single-board computers developed in the United Kingdom by the Raspberry Pi Foundation. The Raspberry Pi is slower than a modern laptop or desktop but is still a complete Linux computer and can provide all the expected abilities that implies, at a low-power consumption level. The Raspberry Pi is open hardware, with the exception of the primary chip on the Raspberry Pi, the Broadcomm SoC (System on a Chip), which runs many of the main components of the board–CPU, graphics, memory, the USB controller, etc. Processor speed ranges from 700 MHz to 1.2 GHz for the Pi 3 in Figure 5.1 on-board memory ranges from 256 MB to 1 GB RAM. Secure Digital (SD) cards are used to store the operating system and program memory in either SDHC or Micro SDHC sizes. The Raspberry Pi 3 is a version of the Raspberry Pi which was. It contains a 1.2 GHz ARM Cortex-A53 CPU and hence is the first version of the Raspberry Pi to support the arm 64 architecture
4.1.1INTERFACING OF RASPBERRYPI AND GPS
2085
The Raspberry pi operates efficiently at a voltage of 5V and a minimum of 2Amps supply is needed. In Fig.3 The GPS module operates at a voltage of 5V.It consumes about 400mah.The Tx and Rx pins of raspberry pi is connected to Rx and Tx pins of GPS module respectively. The Vin and ground pins of GPS Module are connected to 5v and ground of raspberry pi.
5 RESULT
The data set is plotted with respect to the latitude and longitude coordinates. In Fig 4..The path area is highlighted in green colour and the forest area is highlighted in red colour. The latitude are in x axis and longitude are in y axis. The data set is plotted in python using the matplot library. The matplot library is an plug-in file from mat lab which is used to scatter and plot the datasets. The colour of the dataset is differentiated by using different labeling for the data.
Fig 4 Plotting of dataset
5.1. HyperPlane Based on Dataset
A hyperplane is created using a SVM model to increase the margin of the path. The margin helps to isolate the path area and forest area efficiently. In Fig.5 RBF kernel is used in the SVM model because it is suitable for the dataset when compared to other SVM kernels. Since the dataset is non linear in nature and for better isolation RBF kernel is chosen. The SVM model is generated by passing the datasets and optimizing the gamma and c parameters. The SVM model is saved so that it can be used in the testing phase.
5.2. TESTING AND INTERPRETATION
Fig 5 SVM Hyperplane based on training dataset
The stored SVM model is loaded into raspberry pi python script. The shortest path is calculated between the current GPS input coordinate and all the cluster centers which is calibrated by using k means clustering algorithm. In figure 6, the model of k-Means Cluster is displayed. In Figure 7, the nearest cluster center is stored and an line is plotted between the GPS and nearest point.
Fig 6 K-Means Clustered Model
Fig 7 Testing and Interpretation
The direction for navigation is found by calculating the angle between the current GPS location and the nearest cluster center. The nearest cluster center is calculated by finding the difference between two points. The nearest point is chosen which has smallest difference. The nearest node is then displayed . The shortest path and the distance to travel and direction is displayed
2086
Table 1: Confusion Matrix
Actual Positive Actual Negative
Predictive Positive 27 4
Predictive Negative 0 29
Based on confusion matrix describe the behavior of the trained SVM model. It shows the model has been trained properly for true positive labeled dataset but not for true negative labeled dataset. The parameters of SVM model of hyperplane are fit along less counted dataset.
6 CONCLUSION
AND
FUTURE
SCOPE
The proposed system was aimed to create a system which could find a human habitation path. The system completely runs on offline mode and doesn‘t need any internet connectivity. The work has been implemented using RBF kernel in Support Vector Machine. The F1 score has been calculated for an analysis. The proposed system can be enhanced by using different kernels to increase the accuracy. It can be implemented using a graphical user interface for easy usage. The F1 score can be increased by optimizing the kernel function. The system can be implemented in a cost efficient way by using low cost integrated circuits.
7
REFERENCES
[1] Prathilothamai. M, Prashant R.Nair, R. Alakh, P. Singh, Aditya.R.N.S "Offline Navigation: GPS based Location Assisting system‖ Indian Journal of Science and Technology, Vol 9, pp 45., Dec 2016.
[2] Asmita Singh , Devendra Sowwanshi, "Offline Location Search using Reverse K-Means Clustering & GSM Communication" International Conference on Green Computing and Internet of Things,pp 1359-1364,Oct 2015.
[3] P. Pharpatara, B. Herisse, R.Pepy ,Y. Bestaoui, "Shortest Path for aerial vehicles in heterogeneous environment using RRT",IEEE International Conference on Robotics and Automation,pp 6388-6393,May 2015.
[4] Dan Meng, Guitao Cao "Automated human physical function measurement using constrained high dispersal network with SVM-linear", IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2016.
[5] Ebha Koley, Sunil K. Shukla,‖ Protection scheme for power transmission lines based on SVM and ANN considering the presence of non-linear loads‖, IET Gener. Transm. Distrib., 2017, Vol. 11 Iss. 9, pp. 2333-2341 © The Institution of Engineering and Technology 2017.
[6] Hui Zhao, Yong Yao,‖ A Classification Method Based on Non-linear SVM Decision Tree‖, Fourth international conference on fuzzy system and knowledge discovery, pp. 335-853,2007.
[7] Jaiswal.A, Chiang.Y, Knoblock.C.A, Lan.L, "Location Prediction with Sparse GPS Data", Proceedings of the 8th International Conference on Geographic Information Science, pp. 315-219, 2014.
[8] Matsuo.J, Kitayama.J, Sumiya.K, "Extracting degrees of emphasis of geographical objects for searching of
maps", Soft Computing and Intelligent Systems (SCIS) and 13th International Symposium on Advanced Intelligent Systems (ISIS) 2012 Joint 6th International Conference, pp. 1708-1712, 20–24 Nov. 2012.
[9] Nai chunchen,jennyxie, "Comprehensive Predictions of Tourists' Next Visit Location Based on Call Detail Records Using Machine Learning and Deep Learning Methods‖, Big Data (BigData Congress), 2017 IEEE International Congress on 25-30 June 2017.
[10]Prithumit Deb, Nitin Singh, Saket Kumar, Nitish Rai,
―Offline navigation system for mobile
devices", International Journal of Software Engineering & Applications (IJSEA), vol. 1, no. 2, April 2010.
[11] https://gis.stackexchange.com/questions/25494/how-
accurate-is-approximating-the-earth-as-a-sphere#25580
[12]https://www.google.com/maps/d/ [13]http://www.enetplanet.com/