AN ADAPTIVE MEAN-SHIFT
ALGORITHM FOR
MRI BRAIN SEGMENTATION
M.C.Jobin Christ
* Department of Biomedical Engineering,
Adhiyamaan College of Engineering, Dr.MGR Nagar, Hosur, India
Dr.R.M.S.Parvathi
Sengunthar College of Engineering, Tiruchengode, India
[email protected] Abstract
An adaptive mean shift algorithm is an automatic method for magnetic resonance imaging (MRI) brain segmentation to classify brain voxels into three main tissue types like gray matter, white matter, and Cerebro-spinal fluid. In clinical practice, Magnetic Resonance Imaging is used to differentiate pathologic tissue from normal tissue, especially for brain related disorders. The MRI image space is symbolized by a high-dimensional feature space that comprises multimodal intensity features as well as spatial features. The main idea of an adaptive mean-shift algorithm is which clusters the joint spatial-intensity feature space, thus extracting a representative set of high-density points within the feature space, or also called as modes. In this paper we applied adaptive mean shift algorithm to real MRI data and its performance is compared with other clustering methods including K-Means clustering and Fuzzy C-Means clustering.
Keywords :MRI, Segmentation, Clustering, Adaptive Mean Shift.
1. Introduction
Medical imaging comprises locating tumors and other pathologies, measuring tissue volumes, etc. Segmentation has an important role in biomedical image processing. Segmentation is the basic step for other processes such as image registration, shape analysis, visualization and quantitative analysis. Segmentation of an image is the division or partition of the image into disjoint regions of similar attribute. Three main regions of brain are White Matter (WM), Gray Matter (GM) and Cerebrospinal Fluid (CSF). Manual segmentation by an operator is time consuming and it is very hard to do accurate segmentation. Hence automatic segmentation algorithms are preferred in diagnostic process. Image segmentation algorithms are mainly divided into two types, supervised and unsupervised. Unsupervised algorithms are fully automatic and partition the regions in feature space with high density. The different unsupervised algorithms are Feature-Space Based Techniques, Clustering Techniques (K-means algorithm, C-means algorithm, E-means algorithm, Adaptive Mean Shift Algorithm), Histogram thresholding, Image-Domain or Region Based Techniques (Region growing techniques, Neural-network based techniques, Split-and-merge techniques, Edge Detection Technique), Fuzzy Techniques, etc.
2. Clustering Methods
or divisive methods. In agglomerative methods the hierarchy is build up in a series of N-1 agglomerations, or Fusion, of pairs of objects, beginning with the un-clustered dataset. The less common divisive methods begin with all objects in a single cluster and at each of N-1 steps divide some clusters into two smaller clusters, until each object resides in its own cluster. Some of the important Data Clustering Methods are Partitioning Methods, Hierarchical Agglomerative methods, The Single Link Method (SLINK), The Complete Link Method (CLINK), The Group Average Method, etc. In this chapter we discussed about K-Means clustering and Fuzzy C-Means clustering.
2.1 K-means algorithm
K-means algorithm is under the category of Squared Error-Based Clustering (Vector Quantization) and it is also under the category of crisp clustering or hard clustering. K-means algorithm is very simple and can be easily implemented in solving many practical problems. Steps of the K-means algorithm are given below.
1. Choose k cluster centers to coincide with k randomly chosen patterns inside the hyper volume containing the pattern set.(C)
2. Assign each pattern to the closest cluster center.(Ci, i = 1,2,. . . . C)
3. Recompute the cluster centers using the current cluster memberships.(U)
(1)
4. If a convergence criterion is not met, go to step 2 with new cluster centers by the following equation, i.e., minimal decrease in squared error.
(2) Where, |Gi| is the size of Gi
or,
(3)
The performance of the K-means algorithm depends on the initial positions of the cluster centers. This is an inherently iterative algorithm. And also there is no guarantee about the convergence towards an optimum solution. The convergence centroids vary with different initial points. It is also sensitive to noise and outliers. It is only based on numerical variables.
2.2 Fuzzy C-Means algorithm
Fuzzy C-Means clustering (FCM), also called as ISODATA, is a data clustering method in which each data point belongs to a cluster to a degree specified by a membership value. FCM is used in many applications like pattern recognition, classification, image segmentation, etc. FCM divides a collection of n vectors c fuzzygroups, and finds a cluster center in each group such that a cost function of dissimilarity measure is minimized. FCM uses fuzzy partitioning such that a given data point can belong to several groups with the degree of belongingness specified by membership values between 0 and 1. This algorithm is simply an iterated procedure. The algorithm is given below.
1. Initialize the membership matrix U with random values between 0 and 1. 2. Calculates c fuzzy cluster center ci, i = 1,…c., using the following equation,
(4)
3. Compute the cost by the following equation. Stop if either it is below a certain threshold value or its improvement over previous iteration.
4. Compute a new U by the equation. Go to step 2.
(6)
Like K-means clustering, there is no guarantee ensures that FCM converges to an optimum solution. The performance is based on the initial cluster centers. FCM also suffers from the presence of outliers and noise and it is difficult to identify the initial partitions.
3. Adaptive Mean Shift Algorithm
Adaptive Mean Shift algorithm is derived from Mean shift clustering algorithm. Basic mean shift clustering algorithms maintain a set of data points the same size as the input data set. Initially, this set is copied from the input set. Then this set is iteratively replaced by the mean of those points in the set that are within a given distance of that point. By contrast, K-means restricts this updated set to K points usually much less than the number of points in the input data set, and replaces each point in this set by the mean of all points in the input set that are closer to that point than any. A mean shift algorithm that is similar then to K-means, called likelihood mean shift, replaces the set of points undergoing replacement by the mean of all points in the input set that are within a given distance of the changing set. One of the advantages of mean shift over K-means is that there is no need to choose the number of clusters, because mean shift is likely to find only a few clusters if indeed only a small number exist. However, mean shift can be much slower than K-means. Mean shift has soft variants much as K-means does.
Let k(x) be a symmetric univariate kernel function, where x Є (-∞, +∞). We can construct a dD kernel function from k(x) as follows:
(7) Where,
The kernel density estimator is given by,
(8)
Suppose that k(x) is differentiable in [0, +∞], except for a finite number of points. Let g(x) = -k|(x)
where x Є [0,+∞], except for a finite number of points.Construct a kernel function from g(x) as follows:
(9) Then,
(11)
This is the difference between the weighted mean and x, known as mean shift vector. Since the gradient of the density estimator always points towards that direction in which the density rises most quickly, by Equation (11), the mean shift vector always points towards the direction in which the density rises most quickly. This is the main principle of mean shift-based clustering. This equation is generalized into
(12)
This is called the adaptive mean shift vector. The adaptive mean shift vector also always points towards the direction in which the density rises most quickly, which is called the mean shift property. This is the basic principle of adaptive mean shift-based clustering.
4. Execution
The above methods are implemented using MATLAB 7.9.0(R2008a). MRI brain images are taken for implementation.
5. Results
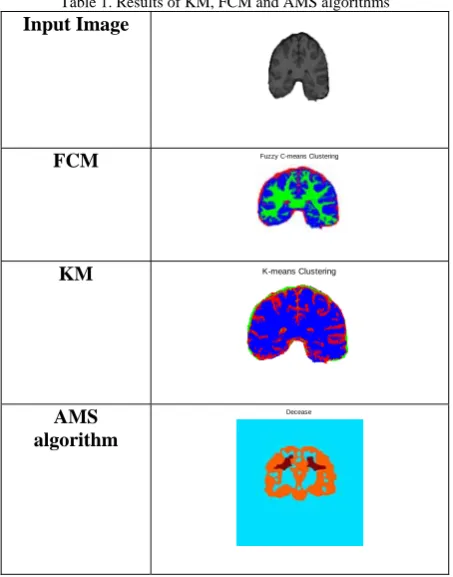
Table 1. Results of KM, FCM and AMS algorithms Input Image
FCM Fuzzy C-means Clustering
KM K-means Clustering
AMS algorithm
Decease
6. Conclusions
7. References
[1] A.K.Jain, et.al, 1999, "Data Clustering: A Review", ACM Computing Surveys, Vol. 31, No. 3.
[2] D. Comaniciu, V. Ramesh and P. Meer. The variable bandwidth mean shift and data-driven scale selection. In Proc. Intl. Conf. Computer Vision, volume I, pages 438-445, July 2001.
[3] D. L. Pham, C. Y. Xu, and J. L. Prince, “A survey of current methods in medical image segmentation,” Annu. Rev. Biomed. Eng., vol. 2, pp. 315–337, 2000.
[4] F. Camastra and A. Verri. A novel kernel method for clustering. IEEE Trans. Pattern Anal. Mach. Intell., 27:801-805, 2005.
[5] F. E. Clements. Use of cluster analysis with anthropological data . American anthropologist, New Series, Part 1, 56(2):180{199, April 1954.
[6] R. Cárdenes, S. K. Warfield, E. M. Macías, J. A. Santana, and J. Ruiz-Alzola, “An efficient algorithm for multiple sclerosis segmentation from brain MRI,” in Int. Workshop Comput. Aided Syst. Theory (EUROCAST), 2003, pp. 542–551.