Weighing the initial clusters in the ensemble with
the help of Heuristic
Mortaza Zolfpour-Arokhlo, Jaafar Partabian
Abstract—Data clustering means partitioning the samples in similar clusters, in a way that samples in each cluster have the maximum similarity to each other and have the maximum difference with those in other clusters. Due to unsupervised nature of clustering problems, choosing a specific algorithm for clustering an unknown dataset is risky and usually fails its objectives. Because of the complexity of this problem and poor performance of basic clustering methods, today the majority of studies in this field are focused on ensemble clustering methods. Diversity and quality of initial results are two of the most important factors that can affect the quality of final results obtained from ensemble clustering, and both factors have been significantly assessed in the recent studies regarding this field. In this paper, a new framework is proposed to improve the efficiency of ensemble clustering. This framework is based on using a subset of initial clusters and selection of this subset plays a crucial role in the performance of the ensemble, so the process of selection is carried out with the help of two intelligent methods. The main idea of the proposed method for the selection of a subset of clusters is to use the stable clusters with the help of intelligent search algorithms. The stability criterion based on mutual information is used to evaluate the clusters. In the end, the selected clusters are aggregated with the help of multiple final clustering techniques. Experimental results obtained from testing several standard datasets show that the proposed methods can effectively improve the full ensemble method.
Index Terms—
clustering ensemble, subset of initial results,
correlation matrix, cluster evaluation
1. Introduction
Data clustering is the process of separating samples from each other and putting them into similar groups, in a way that samples most similar to each other be placed in one group and have the maximum difference with those in other groups [1, 2]. In fact, data clustering is an indispensable tool for finding groups in unlabeled data [3]. The overall objective of clustering is to minimize the difference between samples in each cluster (compression) and maximize the difference between the samples in any cluster and other samples in other clusters (separation) or a combination of the two. Of course, the quality of clustering also depends on the similarity measurement method. On the other hand, clustering leads to a reduction in the volume the data, because information about a large number of items can be replaced by information about a
few homogeneous groups. Data clustering has numerous applications in many fields such as engineering (machine learning, artificial intelligence, pattern recognition, mechanical and electronic engineering), computer science (web mining, spatial database analysis, textual document collection, image segmentation), medical sciences (genetics, biology, microbiology , paleontology, psychiatry, pathology), earth sciences (geography, geology, cartography), social sciences (sociology, psychology, archeology, education) and economics (marketing, business). Clustering can also be referred to by using other terms such as numerical taxonomy, unsupervised learning, typological analysis and partitioning.
2. Related Work & Literature review
Ensemble clustering methods try to combine different partitions generated by basic clustering methods to produce a robust partition of data [3, 4, 5]. In most of the recent studies, all partitions and all clusters in all partitions have equal weight in the final combination [6]. Strehl & Ghosh [3] have proposed a measure for the selection from possible combinations based on the overall quality of a clustering. To do so, they have assessed the consistency between ensemble partitions and basic partitions and then have used a fixed combination rule, to apply a pairwise similarity measure on d-dimensional feature spaces.
intermediate datasets, respectively. In each dataset, the above method tries to find those results of initial clustering that cause the deviation of final results and discards them from the final combination, and thus letting the initial ensemble clusters with relatively good accuracies into the final combination.
Another method, which is close to our approach, is one proposed by Alizadeh [14]. This method first sorts all clusters in all datasets based on their stability, and then selects the 33% with highest stability. Compared with this article, our work is a deterministic algorithm.
In recent years, the cluster stability has become a popular measure for cluster evaluation [6][8-10] and several cluster validation methods operating based on the notion of stability has been suggested [11]. Inokuchi et al. [12] have proposed a kernelized cluster validity measure. In this method, kernel is the central function used in support vector machine. This method has taken two indices into consideration: Total value of fuzzy covariance in clusters, and Xie-Beni kernel-based index [13]. This method uses these two indices to evaluate the results of clustering and also to determine the number of clusters with non-linear boundaries. Fred and Jain [6] have proposed a ensemble clustering method that uses cluster stability measure to learn pairwise similarities. In this method, instead of using evaluation criteria based on the final partition, partitions resulted from basic algorithms in different parts of d-dimensional feature space are evaluated.
3. The proposed method
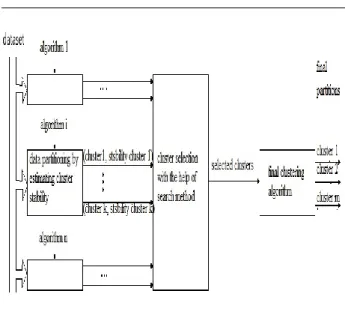
The main idea behind this method is using a subset of initial clusters instead of all clusters for ensemble clustering. An overview of general framework of proposed process is shown in Figure 1.
Figure 1: the process of proposed algorithm for ensemble clustering
This method first uses the diversity method to generate B number of initial clusters. Here the K-means algorithm is used to produce initial results. In the next step, we calculate the NMI of each obtained cluster with all obtained clusters and place them in a square matrix. After calculating the stability of each cluster with respect to other clusters, clusters selection will be performed in two steps. In the first step, genetic algorithm will be used to select a subset of clusters in a way that selected clusters will have the highest level of stability together. In the second step, to generate diversity in the selected clusters, genetic algorithm will be used to select the clusters that have the lowest stability together. In the next step the selected clusters will be combined and the final clusters will be obtained. There are various ways to combine initial clusters to obtain the final clusters. Here, two methods proposed by Alizadeh [14] are used to combine the results. After the construction of correlation matrix, we can use a hierarchical algorithm to obtain the final clusters.
3.1. Evaluation of clusters
Here, clusters will be evaluated based on stability criterion and normalized mutual information (NMI). NMI relationship between P1 and P2 clusters is calculated by (1).
( 1 2, )
( 1 2, ) (1)
1 1
1 . .
( .log . log )
2 0 0
MI P P NMI P P
p
pi j
pi pj
m i m j m
Overall stability is the average of all stabilities as shown in (2).
1
1
(
)
(2)
M
i i
i
Stability C
NMI
M
where M is the number of clusterings in the reference set. This method in fact introduces the clusters most frequent in different types of clustering as the most stable clusters.
3.2. Selection of a subset from initial clusters
the difference of average stability of selected clusters from the value of one (maximum average stability of selected cluster) must be calculated.
( , )
1 (3)
2
.( )
, ,
Similarity C Ci j FitnessFunction
i j Card SelectedClusters
i j SelectedClusters
Where
Similarity
(
C
i,
C
j)
is calculated by (4). ( , ) ( ( , / ), ( , / )) (4)Similarity C Ci j NMI P C D Ci i P Cj D Cj
In (5),
P
(
C
i,
D
/
C
i)
is a clustering that contains twoclusters of
C
i andD
/
C
i (cluster that contains all dataexcept those in
C
i). In phase 2, to ensure more diversityin final selected clusters, a subset of clusters with the lowest stability will be selected by evolutionary algorithm. Like before, the evolutionary algorithm has a chromosome bit with the length equal to total number of clusters. As can be seen in (5), fitness function of evolutionary algorithm is the average stability of selected clusters.
( , )
(5) 2
.( )
, ,
Similarity C Ci j FitnessFunction
i j Card SelectedClusters
i j SelectedClusters
Evolutionary algorithms used in this paper are genetic algorithm and simulated annealing algorithm. In our genetic algorithm, population size is equal to 1000, number of generations is 500, the chromosome length is 120 times the actual number of clusters plus 180, and mutation probability is 0.01, and uniform crossover operator and rank selection operator are used.
In simulated annealing algorithm, parameter T is considered as 0.9. The error of two successive answers of simulated annealing algorithm must not be less than 0.001 (ε=0.001). This algorithm also uses the same chromosomes and fitness function used by genetic algorithm.
3.3. Creation of final partitions
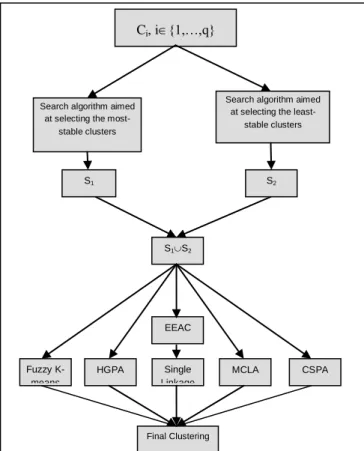
At this stage, the selected clusters are combined and the final clusters are created. Figure 2 shows the manner of selecting a subset of initial clusters with the help of search methods and also the manner of obtaining the final partition from the selected clusters.
Figure 2: The proposed method for selecting a subset of initial clusters and creating the final partition 4. Experimental results
The proposed method was tested on two datasets of iris and wine.
Table 1: Characteristics of used datasets
Dataset Number
of classes
Number of attributes
Number of samples
wine 3 13 178
iris 3 4 150
Results of a number of tests on the normalized attributes of these datasets are reported. Each attribute of these datasets was normalized with a mean of zero and a variance of 1; i.e. N(0,1). For all these datasets, the number of clusters and actual labels of samples are previously determined and already available. Therefore, the percentage of properly identified samples was used as a measure to evaluate the performance of clustering method. The proposed method was implemented and tested in the MATLAB (ver 7.1). The results are the averaged values obtained from 10 independent runs of application. The performance of different methods of clustering was calculated with respect to three criteria of accuracy, NMI and F-Measure.
In all methods, the K-means algorithm was used as the basic algorithm. We used sampling without replacement at the rate of 50% to create greater fragmentation in the
Ci, i{1,…,q}
Search algorithm aimed at selecting the most-
stable clusters
Search algorithm aimed at selecting the least-
stable clusters
S2 S1
S1S2
EEAC
Fuzzy K-means
HGPA Single Linkage
MCLA CSPA
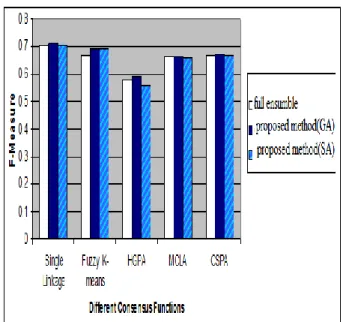
initial results. For the final partitioning, we used single linkage method [15] on the correlation matrix, Fuzzy K-means method [16] and graph-based HGPA, MCLA and CSPA methods [3]. To facilitate the analysis, the average results on dataset are presented in figures (3), (4) and (5).
Figure 3: the average accuracy resulted from using different methods to partition iris and wine datasets
Figure 4: the average normalized mutual information (NMI) resulted from using different methods to partition iris and wine datasets
Figure 5: the average Fisher measure resulted from using different methods to partition iris and wine datasets
As can be seen in these figures, in most cases average values indicate an increase in performance; therefore, we conclude that not only reducing the selected clusters has not decreased the performance but in most cases has led to an increase in the performance.
The result of this paper was also compared with the works of Alizadeh & Minyi [14] and Azimi [7]:
Table 2: the comparison of accuracy of proposed method with the full ensemble and other methods
Datas et
full ensemb
le
Propos ed method
(GA)
Propos ed method
(SA)
Alizad eh method
Azimi metho
d
wine 96.74 96.63 96.63 96.63 96.63
iris 89.60 89.33 89.33 89.33 89.33
5. Conclusion
The proposed framework for ensemble clustering has two main steps. The first step is the evaluation of initial clusters. Normalized mutual information criterion which in recent years has been the most popular criteria for comparing two different partitioning, was used to evaluate the quality (stability) of clusters.
The second step of the proposed ensemble clustering framework is the process of selecting a subset of clusters with respect to the stability of each cluster. To implement this process, evolutionary algorithm was used in two following sub-stages: In the first sub-stage a stable subset of clusters was selected and in the second sub-stage the least stable clusters were selected to produce the necessary diversity. The adjustment of diversity and quality is another suggested method for the selection of clusters. In this paper, we have tried to consider both factors of diversity and quality of initial results. So here the processes are not totally focused on quality.
The experimental results obtained from testing 2 standard datasets indicate the good performance of the proposed methods in comparison with other ensemble clustering methods. The results also show that even though the proposed method uses only a small amount of initial results in the final combination, it performs better than the full ensemble method.
6. References
1. Jain A., Murty M. N., and Flynn P. (1999), Data clustering: A review. ACM Computing Surveys, 31(3):264–323.
2. Faceli K., Marcilio C.P. Souto d. (2006), Multi-objective Clustering Ensemble, Proceedings of the Sixth International Conference on Hybrid Intelligent Systems (HIS'06).
3. Strehl A. and Ghosh J. (2002), Cluster ensembles - a knowledge reuse framework for combining multiple partitions. Journal of Machine Learning Research, 3(Dec):583–617.
4. Fred A.L. and Jain A.K. (2005). Combining Multiple Clusterings Using Evidence Accumulation. IEEE Trans. on Pattern Analysis and Machine Intelligence, 27(6):835–850.
5. Kuncheva L.I. and Hadjitodorov S. (2004). Using diversity in cluster ensembles. In Proc. of IEEE Intl. Conference on Systems, Man and Cybernetics, pages 1214–1219.
6. Fred A. and Jain A.K. (2006), Learning Pairwise Similarity for Data Clustering, In Proc. of the 18th Int. Conf. on Pattern Recognition (ICPR'06). 7. Azimi J., (2007), a study on the diversity of the ensemble clustering, Master's thesis, Iran’s University of Science and Technology.
8.Law M.H.C., Topchy A.P., and Jain A.K. (2004). Multiobjective data clustering. In Proc. of IEEE Conference on Computer Vision and Pattern Recognition, volume 2, pages 424–430, Washington D.C.
9. Shamiry O., Tishby N. (2007), Cluster Stability for Finite Samples, 21st Annual Conference on Neural Information Processing Systems (NIPS07).
10. Lange T., Braun M.L., Roth V., and Buhmann J.M. (2003).Stability-based model selection. In Advances in Neural InformationProcessing Systems 15. MIT Press.
11. Lange T., Roth V., Braun M.L., and Buhmann J.M. (2004). Stability-based validation of clustering solutions. Neural Computation, 16(6):1299–1323. 12. Inokuchi R., Nakamura T. and Miyamoto S. (2006), Kernelized Cluster Validity Measures and Application to Evaluation of Different Clustering Algorithms, in proc. of the IEEE Int. Conf. on Fuzzy Systems, Canada, July 16-21.
13. Xie X.L., Beni G. (1991), A Validity measure for Fuzzy Clustering, IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.13, No.4, pp. 841– 846.
14. Alizadeh H., (2008), ensemble clustering based on a subset of initial results, Master's thesis, Department of Computer Engineering, Iran’s University of Science and Technology.
15. Duda R.O., Hart P.E., and Stork D.G. (2001), Pattern Classification, second ed. Wiley.
16. Man Y. and Gath I. (1994), Detection and Separation of Ring-Shaped Clusters Using Fuzzy Clusters, IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 16, no. 8, pp. 855-861.
Mortaza Zolfpour-Arokhlo, Member of faculty in Department of Computer Engineering, Sepidan Branch , Islamic Azad University, Sepidan,Iran.
Jaafar Partabian*, Member of faculty in Department of Computer Engineering. Lamerd Branch, Islamic Azad University, Lamerd, Iran.
*