ContentslistsavailableatScienceDirect
International
Journal
of
Information
Management
j o ur n a l ho me p a g e :w w w . e l s e v i e r . c o m / l o c a t e / i j i n f o m g t
Beyond
the
hype:
Big
data
concepts,
methods,
and
analytics
Amir
Gandomi
∗,
Murtaza
Haider
TedRogersSchoolofManagement,RyersonUniversity,Toronto,OntarioM5B2K3,Canada
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Availableonline3December2014 Keywords:
Bigdataanalytics Bigdatadefinition Unstructureddataanalytics Predictiveanalytics
a
b
s
t
r
a
c
t
Sizeisthefirst,andattimes,theonlydimensionthatleapsoutatthementionofbigdata.Thispaper attemptstoofferabroaderdefinitionofbigdatathatcapturesitsotheruniqueanddefining character-istics.Therapidevolutionandadoptionofbigdatabyindustryhasleapfroggedthediscoursetopopular outlets,forcingtheacademicpresstocatchup.Academicjournalsinnumerousdisciplines,whichwill benefitfromarelevantdiscussionofbigdata,haveyettocoverthetopic.Thispaperpresentsa consol-idateddescriptionofbigdatabyintegratingdefinitionsfrompractitionersandacademics.Thepaper’s primaryfocusisontheanalyticmethodsusedforbigdata.Aparticulardistinguishingfeatureofthis paperisitsfocusonanalyticsrelatedtounstructureddata,whichconstitute95%ofbigdata.Thispaper highlightstheneedtodevelopappropriateandefficientanalyticalmethodstoleveragemassivevolumes ofheterogeneousdatainunstructuredtext,audio,andvideoformats.Thispaperalsoreinforcestheneed todevisenewtoolsforpredictiveanalyticsforstructuredbigdata.Thestatisticalmethodsinpractice weredevisedtoinferfromsampledata.Theheterogeneity,noise,andthemassivesizeofstructuredbig datacallsfordevelopingcomputationallyefficientalgorithmsthatmayavoidbigdatapitfalls,suchas spuriouscorrelation.
©2014TheAuthors.PublishedbyElsevierLtd.ThisisanopenaccessarticleundertheCCBY-NC-ND license(http://creativecommons.org/licenses/by-nc-nd/3.0/).
1. Introduction
Thispaperdocumentsthebasicconceptsrelatingtobigdata. Itattempts toconsolidatethehithertofragmenteddiscourse on whatconstitutesbigdata,whatmetricsdefinethesizeandother characteristicsofbigdata,andwhattoolsandtechnologiesexistto harnessthepotentialofbigdata.
Fromcorporateleaderstomunicipalplannersandacademics, bigdata arethe subjectof attention,and to someextent,fear. Thesuddenriseofbigdatahasleftmanyunprepared.Inthepast, newtechnologicaldevelopmentsfirstappearedintechnicaland academicpublications.Theknowledgeandsynthesislaterseeped intootheravenuesofknowledge mobilization,includingbooks. Thefastevolutionofbigdatatechnologiesandtheready accep-tanceoftheconceptbypublicandprivatesectorsleftlittletime forthediscoursetodevelopandmatureintheacademicdomain. Authorsandpractitionersleapfroggedtobooksandotherelectronic mediaforimmediateand widecirculation oftheirworkonbig data.Thus,onefindsseveralbooksonbigdata,includingBigData
∗Correspondingauthor.Tel.:+14169795000x6363. E-mailaddresses:[email protected](A.Gandomi), [email protected](M.Haider).
forDummies,butnotenoughfundamentaldiscourseinacademic publications.
Theleapfroggingofthediscourseonbigdatatomorepopular outletsimpliesthatacoherentunderstandingoftheconceptand itsnomenclatureisyettodevelop.Forinstance,thereislittle con-sensusaroundthefundamentalquestionofhowbigthedatahas tobetoqualifyas‘bigdata’.Thus,thereexiststheneedto docu-mentintheacademicpresstheevolutionofbigdataconceptsand technologies.
A key contribution of this paper is to bring forth the oft-neglecteddimensionsofbigdata.Thepopulardiscourseonbigdata, whichisdominatedandinfluencedbythemarketingeffortsoflarge softwareandhardwaredevelopers,focusesonpredictiveanalytics andstructureddata.Itignoresthelargestcomponentofbigdata, whichisunstructuredandisavailableasaudio,images,video,and unstructuredtext.Itisestimatedthattheanalytics-ready struc-tureddataformsonlyasmallsubsetofbigdata.Theunstructured data,especiallydatainvideoformat,isthelargestcomponentof bigdatathatisonlypartiallyarchived.
Thispaperisorganizedasfollows.Webeginthepaperby defin-ingbigdata.Wehighlightthefactthatsizeisonlyoneofseveral dimensionsofbigdata.Othercharacteristics,suchasthefrequency withwhichdataaregenerated,areequallyimportantindefining bigdata.Wethenexpandthediscussiononvarioustypesofbig data,namelytext,audio,video,and socialmedia.We applythe http://dx.doi.org/10.1016/j.ijinfomgt.2014.10.007
expecteddevelopmentstorealize inthenearfutureinbigdata analytics.
2. Definingbigdata
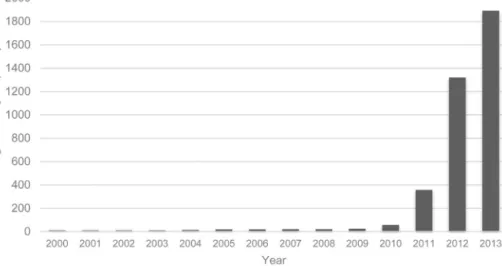
Whileitisubiquitoustoday,however,‘bigdata’asaconcept isnascentandhasuncertainorigins.Diebold(2012)arguesthat theterm“bigdata...probablyoriginatedinlunch-table conversa-tionsatSiliconGraphicsInc.(SGI)inthemid-1990s,inwhichJohn Masheyfiguredprominently”.Despitethereferencestothe mid-nineties,Fig.1showsthatthetermbecamewidespreadasrecently asin2011.Thecurrenthypecanbeattributedtothepromotional initiativesbyIBMandotherleadingtechnologycompanieswho investedinbuildingthenicheanalyticsmarket.
Bigdatadefinitionshaveevolvedrapidly,whichhasraisedsome confusion.Thisisevident fromanonline surveyof 154C-suite globalexecutivesconductedbyHarrisInteractiveonbehalfofSAP inApril2012(“Smallandmidsizecompanieslooktomakebiggains withbigdata,”2012).Fig.2showshowexecutivesdifferedintheir understandingofbigdata,wheresomedefinitionsfocusedonwhat itis,whileotherstriedtoanswerwhatitdoes.
Clearly, size is the first characteristic that comes to mind consideringthequestion“whatisbigdata?”However,other char-acteristicsofbigdatahaveemergedrecently.Forinstance,Laney (2001)suggestedthatVolume,Variety,andVelocity(ortheThree V’s)arethethreedimensionsofchallengesindatamanagement. TheThreeV’shaveemergedasacommonframeworktodescribe bigdata(Chen,Chiang,&Storey,2012;Kwon,Lee,&Shin,2014). Forexample,Gartner,Inc.definesbigdatainsimilarterms:
“Bigdata ishigh-volume, high-velocityand high-variety infor-mation assets that demand cost-effective, innovative forms of informationprocessingforenhancedinsightanddecisionmaking.” (“GartnerITGlossary,n.d.”)
Similarly,TechAmericaFoundationdefinesbigdataasfollows: “Bigdataisatermthat describeslargevolumes of high veloc-ity,complexandvariabledatathatrequireadvancedtechniques and technologies to enable the capture, storage, distribution, management, and analysis of the information.” (TechAmerica Foundation’sFederalBigDataCommission,2012)
WedescribetheThreeV’sbelow.
Volume refers to the magnitude of data. Big data sizes are reportedinmultipleterabytesandpetabytes.Asurveyconducted by IBM in mid-2012 revealed that just over half of the 1144 respondentsconsidereddatasetsoveroneterabytetobebigdata (Schroeck,Shockley,Smart,Romero-Morales,&Tufano,2012).One terabytestoresasmuchdataaswouldfiton1500CDsor220DVDs, enoughtostorearound16millionFacebookphotographs.Beaver, Kumar,Li,Sobel,andVajgel(2010)reportthatFacebookprocesses uptoonemillionphotographspersecond.Onepetabyteequals 1024terabytes.EarlierestimatessuggestthatFacebookstored260 billionphotosusingstoragespaceofover20petabytes.
Varietyreferstothestructuralheterogeneityinadataset. Tech-nologicaladvancesallowfirmstousevarioustypesofstructured, semi-structured, and unstructureddata. Structureddata, which constitutesonly 5%of allexistingdata (Cukier, 2010), refersto thetabular data found in spreadsheetsor relational databases. Text, images, audio, and video are examples of unstructured data,whichsometimeslackthestructuralorganizationrequired by machinesfor analysis.Spanning a continuum betweenfully structuredandunstructureddata,theformatofsemi-structured data does not conform to strict standards. Extensible Markup Language (XML), a textual language for exchanging data on the Web, is a typical example of semi-structured data. XML documents contain user-defined data tags which make them machine-readable.
Ahighlevelofvariety,adefiningcharacteristicofbigdata,is notnecessarilynew.Organizationshavebeenhoarding unstruc-tureddatafrominternalsources(e.g.,sensordata)andexternal sources(e.g.,socialmedia).However,theemergenceofnewdata managementtechnologiesandanalytics,whichenable organiza-tionstoleveragedataintheirbusinessprocesses,istheinnovative aspect. For instance, facial recognition technologies empower thebrick-and-mortarretailerstoacquireintelligenceaboutstore traffic, the age or gender composition of their customers, and theirin-storemovementpatterns.Thisinvaluableinformationis leveragedindecisionsrelatedtoproductpromotions,placement, and staffing.Clickstreamdata providesawealthof information aboutcustomerbehaviorandbrowsingpatternstoonline retail-ers. Clickstream advises on the timing and sequence of pages viewedby acustomer.Usingbigdataanalytics,even smalland medium-sizedenterprises(SMEs)canminemassivevolumesof semi-structureddatatoimprovewebsitedesignsandimplement effectivecross-sellingandpersonalizedproductrecommendation systems.
Velocityreferstotherateatwhichdataaregeneratedandthe speedatwhichitshouldbeanalyzedandactedupon.The prolifera-tionofdigitaldevicessuchassmartphonesandsensorshasledtoan unprecedentedrateofdatacreationandisdrivingagrowingneed forreal-timeanalyticsandevidence-basedplanning.Even conven-tionalretailersaregeneratinghigh-frequencydata.Wal-Mart,for instance,processesmorethanonemilliontransactionsperhour (Cukier,2010).Thedataemanatingfrommobiledevicesand flow-ingthroughmobileappsproducestorrentsofinformationthatcan beusedtogeneratereal-time,personalizedoffersforeveryday cus-tomers. Thisdataprovidessoundinformation aboutcustomers, suchasgeospatiallocation,demographics,andpastbuying pat-terns,whichcanbeanalyzedinrealtimetocreaterealcustomer value.
Giventhesoaringpopularityofsmartphones,retailerswillsoon havetodealwithhundredsofthousandsofstreamingdatasources thatdemandreal-timeanalytics.Traditionaldatamanagement sys-temsarenotcapableofhandlinghugedatafeedsinstantaneously. Thisiswherebigdatatechnologiescomeintoplay.Theyenable firmstocreatereal-timeintelligencefromhighvolumesof ‘perish-able’data.
Fig.1. Frequencydistributionofdocumentscontainingtheterm“bigdata”inProQuestResearchLibrary.
InadditiontothethreeV’s,otherdimensionsofbigdatahave alsobeenmentioned.Theseinclude:
•Veracity.IBMcoinedVeracityasthefourthV,whichrepresentsthe unreliabilityinherentinsomesourcesofdata.Forexample, cus-tomersentimentsinsocialmediaareuncertaininnature,since theyentailhumanjudgment.Yettheycontainvaluable informa-tion.Thustheneedtodealwithimpreciseanduncertaindata isanotherfacetofbigdata,whichisaddressedusingtoolsand analyticsdevelopedfor managementand miningofuncertain data.
•Variability(andcomplexity).SASintroducedVariabilityand Com-plexityastwoadditionaldimensionsofbigdata.Variabilityrefers tothevariationinthedataflowrates.Often,bigdatavelocityis notconsistentandhasperiodicpeaksandtroughs.Complexity referstothefactthatbigdataaregeneratedthroughamyriad ofsources.Thisimposesacriticalchallenge:theneedto con-nect,match,cleanseandtransformdatareceivedfromdifferent sources.
•Value.OracleintroducedValueasadefiningattributeofbigdata. BasedonOracle’sdefinition,bigdataareoftencharacterizedby relatively“lowvaluedensity”.Thatis,thedatareceivedinthe originalformusuallyhasalowvaluerelativetoitsvolume. How-ever,ahighvaluecanbeobtainedbyanalyzinglargevolumesof suchdata.
Therelativityofbigdatavolumesdiscussedearlierappliesto alldimensions.Thus,universalbenchmarksdonotexistfor vol-ume,variety,andvelocitythatdefinebigdata.Thedefininglimits dependuponthesize,sector,andlocationofthefirmandthese limitsevolveovertime.Alsoimportantisthefactthatthese dimen-sionsarenotindependentofeachother.Asonedimensionchanges, thelikelihoodincreasesthatanotherdimensionwillalsochangeas aresult.However,a ‘three-Vtippingpoint’existsforeveryfirm beyond which traditional data management and analysis tech-nologiesbecomeinadequateforderivingtimelyintelligence.The Three-Vtippingpointisthethresholdbeyondwhichfirmsstart dealingwithbigdata.Thefirmsshouldthentrade-offthefuture
28% 24% 19% 18% 11% Explosion of new data sources (social media, mobile device, and machine-generated devices)
Requirement to store and archive data for regulatory and compliance
New technologies designed to address the volume, variety, and velocity challenges of Big Data
Massive growth of transaction data, including data from customers and the supply chain Some other definition
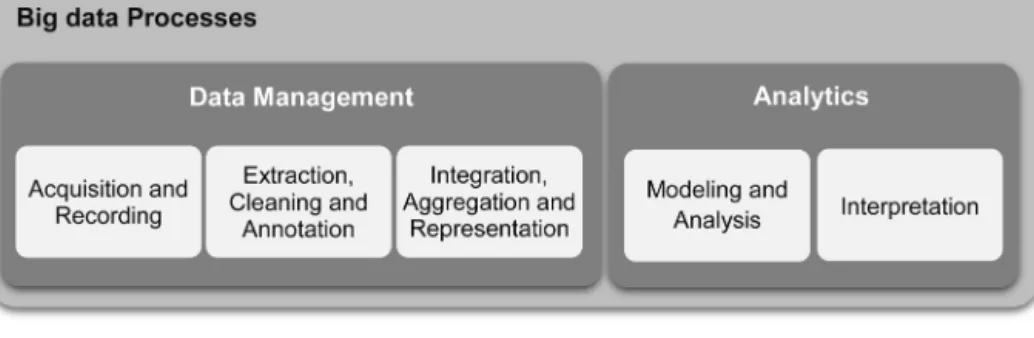
frombigdatacanbebrokendownintofivestages(Labrinidis& Jagadish,2012),showninFig.3.Thesefivestages formthetwo mainsub-processes:datamanagementandanalytics.Data man-agementinvolvesprocessesandsupportingtechnologiestoacquire andstoredataandtoprepareandretrieveitforanalysis.Analytics, ontheotherhand,referstotechniquesusedtoanalyzeandacquire intelligencefrombigdata.Thus,bigdataanalyticscanbeviewed asasub-processintheoverallprocessof‘insightextraction’from bigdata.
Inthefollowing sections, we brieflyreview bigdata analyt-icaltechniquesforstructured andunstructureddata. Giventhe breadth of the techniques, an exhaustive list of techniques is beyondthe scope of a single paper. Thus, the following tech-niquesrepresentarelevantsubsetofthetoolsavailableforbigdata analytics.
3.1. Textanalytics
Textanalytics(text mining)referstotechniquesthat extract informationfromtextualdata.Socialnetworkfeeds,emails,blogs, onlineforums,surveyresponses,corporatedocuments,news,and callcenterlogsareexamplesoftextualdataheldbyorganizations. Textanalyticsinvolvestatisticalanalysis,computational linguis-tics,and machine learning. Text analyticsenable businesses to convertlargevolumesofhumangeneratedtextintomeaningful summaries,whichsupportevidence-baseddecision-making.For instance,textanalyticscanbeusedtopredictstockmarketbased oninformationextractedfromfinancialnews(Chung,2014).We presentabriefreviewoftextanalyticsmethodsbelow.
Informationextraction (IE)techniquesextractstructureddata fromunstructured text.For example, IEalgorithms can extract structuredinformationsuchasdrugname,dosage,andfrequency frommedicalprescriptions.Twosub-tasksinIEareEntity Recogni-tion(ER)andRelationExtraction(RE)(Jiang,2012).ERfindsnames intextandclassifiesthemintopredefinedcategoriessuchas per-son,date,location,andorganization.REfindsandextractssemantic relationshipsbetweenentities(e.g.,persons,organizations,drugs, genes,etc.)inthetext.Forexample,giventhesentence“SteveJobs co-foundedAppleInc.in1976”,anREsystemcanextractrelations
suchasFounderOf[SteveJobs,AppleInc.]orFoundedIn[Apple
Inc.,1976].
Textsummarization techniquesautomatically produce a suc-cinctsummary ofasingleormultipledocuments.Theresulting summary conveys the key information in the original text(s). Applicationsincludescientificandnewsarticles,advertisements, emails,andblogs.Broadlyspeaking,summarizationfollowstwo approaches:theextractiveapproachandtheabstractiveapproach. In extractive summarization, a summary is created from the originaltextunits(usuallysentences).Theresultingsummaryisa subsetoftheoriginaldocument.Basedontheextractiveapproach, formulatingasummaryinvolvesdeterminingthesalientunitsof atext andstringing them together.Theimportance ofthetext unitsis evaluated byanalyzing theirlocation and frequency in thetext.Extractivesummarizationtechniquesdonotrequirean ‘understanding’ofthetext.Incontrast,abstractivesummarization
implemented in healthcare, finance, marketing, and education. Similartoabstractivesummarization,QA systemsrely on com-plex NLP techniques. QA techniques are further classified into three categories:theinformation retrieval(IR)-based approach, theknowledge-basedapproach,andthehybridapproach.IR-based QAsystemsoftenhavethreesub-components.Firstisthequestion processing,usedtodeterminedetails,suchasthequestiontype, questionfocus,andtheanswertype,whichareusedtocreatea query. Secondis documentprocessing which is used toretrieve relevantpre-written passagesfroma setofexisting documents usingthequeryformulatedinquestionprocessing.Thirdisanswer processing,usedtoextractcandidateanswersfromtheoutputof thepreviouscomponent,rankthem,andreturnthehighest-ranked candidateastheoutputoftheQAsystem.Knowledge-basedQA sys-temsgenerateasemanticdescriptionofthequestion,whichisthen usedtoquerystructuredresources.TheKnowledge-basedQA sys-temsareparticularlyusefulforrestricteddomains,suchastourism, medicine,andtransportation,wherelargevolumesofpre-written documentsdonotexist.Suchdomainslackdataredundancy,which isrequiredforIR-basedQAsystems.Apple’sSiriisanexampleofa QAsystemthatexploitstheknowledge-basedapproach.Inhybrid QAsystems,likeIBM’sWatson,whilethequestionissemantically analyzed,candidateanswersaregeneratedusingtheIRmethods.
Sentiment analysis(opinionmining)techniquesanalyze opin-ionated text, which contains people’s opinions toward entities such as products, organizations, individuals, and events. Busi-nessesareincreasinglycapturingmoredataabouttheircustomers’ sentimentsthat has ledto theproliferation of sentiment anal-ysis(Liu, 2012).Marketing, finance,andthepolitical and social sciences are the majorapplication areas of sentiment analysis. Sentimentanalysistechniquesarefurtherdividedintothree sub-groups,namelydocument-level,sentence-level,andaspect-based. Document-leveltechniquesdeterminewhetherthewhole docu-mentexpressesanegativeorapositivesentiment.Theassumption isthat thedocument containssentimentsaboutasingleentity. Whilecertaintechniquescategorizeadocumentintotwoclasses, negativeandpositive,othersincorporatemoresentimentclasses (liketheAmazon’sfive-starsystem)(Feldman,2013). Sentence-level techniques attempt to determine thepolarity of a single sentimentaboutaknownentityexpressedin asinglesentence. Sentence-leveltechniquesmust firstdistinguishsubjective sen-tencesfromobjectiveones.Hence,sentence-leveltechniquestend to be more complex compared to document-level techniques. Aspect-basedtechniquesrecognizeallsentimentswithina docu-mentandidentifytheaspectsoftheentitytowhicheachsentiment refers. For instance, customer product reviews usually contain opinionsaboutdifferentaspects(orfeatures)ofaproduct.Using aspect-basedtechniques,thevendorcanobtainvaluable informa-tionaboutdifferentfeaturesoftheproductthatwouldbemissed ifthesentimentisonlyclassifiedintermsofpolarity.
3.2. Audioanalytics
Audioanalyticsanalyzeandextractinformationfrom unstruc-turedaudiodata.Whenappliedtohumanspokenlanguage,audio
Fig.3. Processesforextractinginsightsfrombigdata.
analyticsisalsoreferredtoasspeechanalytics.Sincethese tech-niqueshavemostlybeenappliedtospokenaudio,thetermsaudio analytics and speech analytics are often used interchangeably. Currently,customercallcentersandhealthcarearetheprimary applicationareasofaudioanalytics.
Call centers use audio analytics for efficient analysis of thousands or even millions of hours of recorded calls. These techniqueshelpimprovecustomerexperience,evaluateagent per-formance,enhancesalesturnoverrates,monitorcompliancewith differentpolicies(e.g.,privacyandsecuritypolicies),gaininsight into customerbehavior, and identifyproduct or service issues, amongmanyothertasks.Audioanalyticssystemscanbedesigned toanalyzealivecall,formulatecross/up-sellingrecommendations basedonthecustomer’spastandpresentinteractions,andprovide feedbacktoagentsinrealtime.Inaddition,automatedcallcenters usetheInteractiveVoiceResponse(IVR)platformstoidentifyand handlefrustratedcallers.
Inhealthcare,audioanalyticssupportdiagnosisandtreatment of certain medical conditions that affect the patient’s commu-nication patterns (e.g., depression, schizophrenia, and cancer) (Hirschberg, Hjalmarsson,&Elhadad,2010).Also, audio analyt-icscanhelpanalyzeaninfant’scries,whichcontaininformation abouttheinfant’shealthandemotionalstatus(Patil,2010).Thevast amountofdatarecordedthroughspeech-drivenclinical documen-tationsystemsisanotherdriverfortheadoptionofaudioanalytics inhealthcare.
Speech analytics follows two common technological approaches: the transcript-based approach (widely known as large-vocabularycontinuousspeechrecognition,LVCSR)andthe phonetic-basedapproach.Theseareexplainedbelow.
•LVCSRsystemsfollowatwo-phaseprocess:indexingand search-ing.In the first phase, theyattemptto transcribethe speech contentoftheaudio.Thisisperformedusingautomaticspeech recognition(ASR)algorithmsthatmatchsoundstowords.The wordsareidentifiedbasedonapredefineddictionary.Ifthe sys-temfailstofindtheexactwordinthedictionary,itreturnsthe mostsimilarone.Theoutputofthesystemisasearchableindex filethatcontainsinformationaboutthesequenceofthewords spokeninthespeech.Inthesecondphase,standardtext-based methodsareusedtofindthesearchtermintheindexfile. •Phonetic-basedsystemsworkwithsoundsorphonemes.Phonemes
are the perceptually distinct units of sound in a specified language that distinguish one word from another (e.g., the phonemes/k/and/b/differentiatethemeaningsof“cat”and“bat”). Phonetic-based systems also consist of two phases: phonetic indexingandsearching.Inthefirstphase,thesystemtranslates theinputspeechintoasequenceofphonemes.Thisisincontrast toLVCSRsystemswherethespeechisconvertedintoasequence ofwords.Inthesecondphase,thesystemsearchestheoutput ofthefirstphaseforthephoneticrepresentationofthesearch terms.
3.3. Videoanalytics
Videoanalytics,alsoknownasvideocontentanalysis(VCA), involvesavarietyoftechniquestomonitor,analyze,andextract meaningfulinformationfromvideostreams.Althoughvideo ana-lytics is still in its infancy compared to other types of data mining (Panigrahi, Abraham, & Das, 2010), various techniques havealreadybeendevelopedforprocessingreal-timeaswellas pre-recordedvideos.The increasingprevalenceof closed-circuit television(CCTV)camerasandtheboomingpopularityof video-sharingwebsitesarethetwoleadingcontributorstothegrowth ofcomputerizedvideoanalysis.Akeychallenge,however,isthe sheersizeofvideodata.Toputthisintoperspective,onesecondof ahigh-definitionvideo,intermsofsize,isequivalenttoover2000 pagesoftext(Manyikaetal.,2011).Nowconsiderthat100hoursof videoareuploadedtoYouTubeeveryminute(YouTubeStatistics, n.d.).
Bigdatatechnologiesturnthischallengeintoopportunity. Obvi-atingtheneedforcost-intensiveandrisk-pronemanualprocessing, bigdatatechnologiescanbeleveragedtoautomaticallysiftthrough anddrawintelligencefromthousandsofhoursofvideo.Asaresult, thebigdatatechnologyisthethirdfactorthathascontributedto thedevelopmentofvideoanalytics.
Theprimaryapplicationofvideoanalyticsinrecentyearshas beeninautomatedsecurityandsurveillancesystems.Inaddition totheirhighcost,labor-basedsurveillancesystemstendtobeless effectivethanautomaticsystems(e.g.,Hakeemetal.,2012report that security personnel cannot remain focused onsurveillance tasks formore than 20minutes). Videoanalytics canefficiently andeffectively performsurveillancefunctionssuchasdetecting breachesofrestrictedzones,identifyingobjectsremovedorleft unattended,detectingloiteringinaspecificarea,recognizing sus-piciousactivities,anddetectingcameratampering,tonameafew. Upondetectionofathreat,thesurveillancesystemmaynotify secu-ritypersonnelinrealtimeortriggeranautomaticaction(e.g.,sound alarm,lockdoors,orturnonlights).
ThedatageneratedbyCCTVcamerasinretailoutletscanbe extractedforbusinessintelligence.Marketingandoperations man-agement arethe primaryapplication areas. For instance,smart algorithmscancollectdemographicinformationaboutcustomers, suchasage,gender,and ethnicity.Similarly,retailerscancount thenumberofcustomers,measurethetimetheystayinthestore, detecttheirmovementpatterns,measuretheirdwelltimein dif-ferentareas,and monitorqueuesinrealtime.Valuableinsights can beobtained bycorrelating this information with customer demographics to drive decisions for product placement, price, assortmentoptimization,promotiondesign,cross-selling,layout optimization,andstaffing.
Anotherpotentialapplicationofvideoanalyticsinretailliesin thestudyofbuying behaviorofgroups.Amongfamilymembers whoshoptogether,onlyoneinteractswiththestoreatthecash register,causingthetraditionalsystemstomissdataonbuying
approach,relationaldatabasemanagementsystems(RDBMS)are usedforvideosearchandretrieval.Audioanalyticsandtext ana-lyticstechniques canbeappliedtoindex a video basedonthe associatedsoundtracks and transcripts,respectively.A compre-hensivereviewofapproachesandtechniquesforvideoindexing ispresentedinHu,Xie,Li,Zeng,andMaybank(2011).
Intermsofthesystemarchitecture,thereexisttwoapproaches tovideoanalytics,namelyserver-basedandedge-based:
•Server-basedarchitecture.Inthisconfiguration,thevideocaptured througheachcameraisroutedbacktoacentralizedanddedicated serverthatperformsthevideoanalytics.Duetobandwidth lim-its,thevideogeneratedbythesourceisusuallycompressedby reducingtheframeratesand/ortheimageresolution.The result-inglossofinformationcanaffecttheaccuracyoftheanalysis. However,theserver-basedapproachprovideseconomiesofscale andfacilitateseasiermaintenance.
•Edge-basedarchitecture.Inthisapproach,analyticsareappliedat the‘edge’ofthesystem.Thatis,thevideoanalyticsisperformed locallyandontherawdatacapturedbythecamera.Asaresult, theentirecontentofthevideostreamisavailablefortheanalysis, enablingamoreeffectivecontentanalysis.Edge-basedsystems, however,aremorecostlytomaintainandhavealowerprocessing powercomparedtotheserver-basedsystems.
3.4. Socialmediaanalytics
Socialmediaanalyticsrefertotheanalysisofstructuredand unstructureddatafromsocialmediachannels.Socialmediais a broadtermencompassingavarietyofonlineplatformsthatallow userstocreateandexchangecontent.Socialmediacanbe cate-gorizedintothefollowingtypes:Socialnetworks(e.g.,Facebook andLinkedIn),blogs(e.g.,BloggerandWordPress),microblogs(e.g., Twitterand Tumblr), social news (e.g.,Digg and Reddit), social bookmarking (e.g.,Delicious and StumbleUpon), mediasharing (e.g.,InstagramandYouTube),wikis(e.g.,WikipediaandWikihow), question-and-answersites(e.g.,Yahoo!AnswersandAsk.com)and reviewsites(e.g.,Yelp,TripAdvisor)(Barbier&Liu,2011;Gundecha &Liu, 2012).Also, many mobileapps,suchas FindMy Friend, provideaplatformforsocialinteractionsand,hence,serveassocial mediachannels.
Althoughtheresearchonsocialnetworksdatesbacktoearly 1920s,nevertheless,socialmediaanalyticsisanascentfieldthat hasemergedaftertheadventofWeb2.0intheearly2000s.The keycharacteristicofthemodernsocialmediaanalyticsisits data-centricnature.Theresearchonsocialmediaanalyticsspansacross severaldisciplines,includingpsychology,sociology,anthropology, computerscience,mathematics,physics,andeconomics. Market-inghasbeentheprimaryapplicationofsocialmediaanalyticsin recentyears.Thiscanbeattributedtothewidespreadand grow-ingadoptionofsocial mediabyconsumersworldwide(He,Zha, &Li,2013), totheextentthatForrester Research,Inc., projects socialmediatobethesecond-fastestgrowingmarketingchannelin theUSbetween2011and2016(VanBoskirk,Overby,&Takvorian, 2011).
dynamic.Text,audio,andvideoanalytics,asdiscussedearlier, canbeappliedtoderiveinsightfromsuchdata.Also,bigdata technologiescanbeadoptedtoaddressthedataprocessing chal-lenges.
•Structure-basedanalytics.Alsoreferredtoassocialnetwork ana-lytics,thistypeofanalyticsareconcernedwithsynthesizingthe structuralattributesofasocialnetworkand extracting intelli-gencefromtherelationshipsamongtheparticipatingentities. Thestructureofa socialnetwork ismodeledthroughasetof nodes and edges,representing participants and relationships, respectively.Themodelcanbevisualizedasagraphcomposed ofthenodesandtheedges.We reviewtwo typesofnetwork graphs,namely socialgraphs and activity graphs (Heidemann, Klier,&Probst,2012).Insocialgraphs,anedgebetweenapair ofnodesonlysignifiestheexistenceofalink(e.g.,friendship) betweenthecorrespondingentities.Suchgraphscanbemined toidentifycommunitiesordeterminehubs(i.e.,theuserswith arelativelylargenumberofdirectandindirectsociallinks).In activitynetworks, however, theedgesrepresent actual inter-actions between any pair of nodes. The interactions involve exchangesof information (e.g., likes and comments). Activity graphsare preferabletosocialgraphs,becauseanactive rela-tionshipismorerelevanttoanalysisthanamereconnection.
Varioustechniqueshaverecentlyemergedtoextract informa-tionfromthestructureofsocialnetworks.Webrieflydiscussthese below.
Community detection, also referred to as community discov-ery,extractsimplicit communitieswithinanetwork. Foronline socialnetworks,acommunityreferstoasub-networkofuserswho interactmoreextensively witheachotherthanwiththerestof thenetwork.Oftencontainingmillionsofnodesandedges,online social networks tend to be colossal in size. Community detec-tion helpstosummarize huge networks, which then facilitates uncoveringexistingbehavioralpatternsandpredictingemergent propertiesofthenetwork.Inthisregard,communitydetectionis similartoclustering(Aggarwal,2011), a dataminingtechnique used topartition a data setinto disjoint subsets based onthe similarityofdatapoints.Communitydetectionhasfoundseveral applicationareas,includingmarketingandtheWorldWideWeb (Parthasarathy,Ruan,&Satuluri,2011).Forexample,community detectionenablesfirmstodevelopmoreeffectiveproduct recom-mendationsystems.
Socialinfluenceanalysisreferstotechniquesthatareconcerned withmodelingandevaluatingtheinfluenceofactorsand connec-tionsinasocialnetwork.Naturally,thebehaviorofanactorina socialnetworkisaffectedbyothers.Thus,itisdesirabletoevaluate theparticipants’influence,quantifythestrengthofconnections, anduncoverthepatternsofinfluencediffusioninanetwork.Social influenceanalysistechniquescanbeleveragedinviralmarketing toefficientlyenhancebrandawarenessandadoption.
Asalientaspectofsocial influenceanalysisistoquantifythe importanceof thenetworknodes. Variousmeasureshavebeen developedforthispurpose,includingdegreecentrality, between-nesscentrality,closenesscentrality,andeigenvectorcentrality(for
moredetailsrefertoTang&Liu,2010).Othermeasuresevaluate thestrengthof connectionsrepresentedby edgesormodelthe spreadofinfluenceinsocialnetworks.TheLinearThresholdModel (LTM)andIndependentCascadeModel(ICM)aretwowell-known examplesofsuchframeworks(Sun&Tang,2011).
Linkpredictionspecificallyaddressestheproblemofpredicting futurelinkagesbetweentheexistingnodesintheunderlying net-work.Typically,thestructureofsocialnetworksisnotstaticand continuouslygrowsthroughthecreationofnewnodesandedges. Therefore,anaturalgoalistounderstandandpredictthedynamics of the network. Link prediction techniques predict the occur-renceofinteraction,collaboration,orinfluenceamongentitiesof anetworkinaspecifictimeinterval.Linkpredictiontechniques outperformpurechancebyfactorsof40–50,suggestingthatthe currentstructureofthenetworksurelycontainslatentinformation aboutfuturelinks(Liben-Nowell&Kleinberg,2003).
Inbiology,linkpredictiontechniquesareusedtodiscoverlinks orassociationsinbiologicalnetworks(e.g.,protein–protein inter-actionnetworks),eliminatingtheneedforexpensiveexperiments (Hasan&Zaki,2011).Insecurity,linkpredictionhelpstouncover potentialcollaborationsin terroristorcriminalnetworks.Inthe context of online social media,the primary application of link prediction is in the development of recommendation systems, such as Facebook’s “People You May Know”, YouTube’s “Rec-ommendedfor You”, and Netflix’sand Amazon’s recommender engines.
3.5. Predictiveanalytics
Predictiveanalyticscompriseavarietyoftechniquesthat pre-dict future outcomes based on historical and current data. In practice,predictiveanalyticscanbeappliedtoalmostalldisciplines –frompredictingthefailureofjetenginesbasedonthestreamof datafromseveralthousandsensors,topredictingcustomers’next movesbasedonwhattheybuy,whentheybuy,andevenwhatthey sayonsocialmedia.
Atitscore,predictiveanalyticsseektouncoverpatternsand capturerelationshipsindata.Predictiveanalyticstechniquesare subdividedintotwogroups.Sometechniques,suchasmoving aver-ages,attempttodiscoverthehistorical patternsintheoutcome variable(s)andextrapolatethemtothefuture.Others,suchaslinear regression,aimtocapturetheinterdependenciesbetweenoutcome variable(s)andexplanatoryvariables,andexploitthemtomake predictions.Basedontheunderlyingmethodology,techniquescan alsobecategorizedintotwogroups:regressiontechniques(e.g., multinomiallogitmodels)andmachinelearningtechniques(e.g., neuralnetworks).Anotherclassificationis basedonthetype of outcomevariables:techniquessuchaslinearregressionaddress continuousoutcome variables (e.g.,sale priceofhouses), while otherssuchasRandomForestsareappliedtodiscrete outcome variables(e.g.,creditstatus).
Predictiveanalyticstechniquesareprimarilybasedon statis-ticalmethods.Severalfactorscallfordevelopingnewstatistical methodsforbigdata.First,conventionalstatisticalmethodsare rootedinstatisticalsignificance:asmallsampleisobtainedfrom thepopulationandtheresultiscomparedwithchancetoexamine thesignificanceofaparticularrelationship.Theconclusionisthen generalizedtotheentirepopulation.Incontrast,bigdatasamples aremassiveandrepresentthemajorityof,ifnottheentire, popu-lation.Asaresult,thenotionofstatisticalsignificanceisnotthat relevanttobigdata.Secondly,intermsofcomputationalefficiency, manyconventionalmethodsforsmallsamplesdonotscaleupto bigdata.Thethirdfactorcorrespondstothedistinctivefeatures inherentinbigdata:heterogeneity,noiseaccumulation,spurious correlations,andincidentalendogeneity(Fan,Han,&Liu,2014). Wedescribethesebelow.
•Heterogeneity.Bigdataareoftenobtainedfromdifferentsources andrepresentinformationfromdifferentsub-populations.Asa result,bigdataare highlyheterogeneous.The sub-population datainsmallsamplesaredeemedoutliersbecauseoftheir insuf-ficientfrequency.However,thesheersizeofbigdatasetscreates theuniqueopportunitytomodeltheheterogeneityarisingfrom sub-populationdata,whichwouldrequiresophisticated statisti-caltechniques.
•Noiseaccumulation. Estimatingpredictivemodelsfor bigdata ofteninvolvesthesimultaneousestimationofseveral parame-ters.Theaccumulatedestimationerror(ornoise)for different parameterscoulddominatethemagnitudesofvariablesthathave trueeffectswithinthemodel.Inotherwords,somevariableswith significantexplanatorypowermightbeoverlookedasaresultof noiseaccumulation.
•Spuriouscorrelation.Forbigdata,spuriouscorrelationrefersto uncorrelatedvariablesbeingfalselyfoundtobecorrelateddueto themassivesizeofthedataset.FanandLv(2008)showthis phe-nomenonthroughasimulationexample,wherethecorrelation coefficientbetweenindependentrandomvariablesisshownto increasewiththesizeofthedataset.Asaresult,somevariables thatarescientificallyunrelated(duetotheirindependence)are erroneouslyproventobecorrelatedasaresultofhigh dimen-sionality.
•Incidentalendogeneity.Acommonassumptioninregression anal-ysisistheexogeneityassumption:theexplanatoryvariables,or predictors,areindependentoftheresidualterm.Thevalidityof moststatisticalmethodsusedinregressionanalysisdependson thisassumption.Inotherwords,theexistenceofincidental endo-geneity(i.e.,thedependenceoftheresidualtermonsomeofthe predictors)undermines thevalidityof thestatisticalmethods usedforregressionanalysis.Althoughtheexogeneity assump-tionisusuallymetinsmallsamples,incidentalendogeneityis commonlypresentinbigdata.Itisworthwhiletomentionthat, incontrasttospuriouscorrelation,incidentalendogeneityrefers toagenuinerelationshipbetweenvariablesandtheerrorterm.
Theirrelevanceofstatisticalsignificance,thechallengesof com-putational efficiency,and theuniquecharacteristics ofbigdata discussedabovehighlighttheneedtodevelopnewstatistical tech-niquestogaininsightsfrompredictivemodels.
4. Concludingremarks
Theobjectiveofthispaperistodescribe,review,andreflecton bigdata.Thepaperfirstdefinedwhatismeantbybigdatato consol-idatethedivergentdiscourseonbigdata.Wepresentedvarious def-initionsofbigdata,highlightingthefactthatsizeisonlyone dimen-sionofbigdata.Otherdimensions,suchasvelocityandvarietyare equallyimportant.Thepaper’sprimaryfocushasbeenonanalytics togainvalidandvaluableinsightsfrombigdata.Wehighlightthe pointthatpredictiveanalytics,whichdealsmostlywithstructured data,overshadowsotherformsofanalyticsappliedtounstructured data,which constitutes 95%of bigdata.We reviewed analytics techniquesfortext,audio,video,andsocialmediadata,aswellas predictiveanalytics.Thepapermakesthecasefornewstatistical techniquesforbigdatatoaddressthepeculiaritiesthatdifferentiate bigdatafromsmallerdatasets.Moststatisticalmethodsinpractice havebeendevisedforsmallerdatasetscomprisingsamples.
Technological advances in storage and computations have enabled cost-effectivecaptureof theinformationalvalueof big datainatimelymanner.Consequently,oneobservesa prolifera-tioninreal-worldadoptionofanalyticsthatwerenoteconomically feasibleforlarge-scaleapplicationspriortothebigdataera.For example,sentimentanalysis(opinionmining)havebeenknown
growthinlocation-awaresocialmediaandmobileapps.Sincebig dataarenoisy,highlyinterrelated,andunreliable,itwilllikelylead tothedevelopmentofstatisticaltechniquesmorereadilyaptfor miningbigdatawhileremainingsensitivetotheunique character-istics.Goingbeyondsamples,additionalvaluableinsightscouldbe obtainedfromthemassivevolumesofless‘trustworthy’data.
Acknowledgment
Theauthorswould liketoacknowledgeresearchand editing supportprovidedbyMs.IoanaMoca.
References
Aggarwal,C.C.(2011).Anintroductiontosocialnetworkdataanalytics.InC.C. Aggarwal(Ed.),Socialnetworkdataanalytics(pp.1–15).UnitedStates:Springer. Barbier,G.,&Liu,H.(2011).Datamininginsocialmedia.InC.C.Aggarwal(Ed.),
Socialnetworkdataanalytics(pp.327–352).UnitedStates:Springer.
Beaver,D.,Kumar,S.,Li,H.C.,Sobel,J.,&Vajgel,P.(2010).Findinganeedlein haystack:Facebook’sphotostorage.InProceedingsoftheninethUSENIX con-ferenceonoperatingsystemsdesignandimplementation(pp.1–8).Berkeley,CA, USA:USENIXAssociation.
Chen,H.,Chiang,R.H.L.,&Storey,V.C.(2012).Businessintelligenceandanalytics: Frombigdatatobigimpact.MISQuarterly,36(4),1165–1188.
Chung,W.(2014).BizPro:Extractingandcategorizingbusinessintelligence fac-torsfromtextualnewsarticles.InternationalJournalofInformationManagement, 34(2),272–284.
CukierK.,TheEconomist,Data, dataeverywhere:Aspecial reporton manag-inginformation,2010,February25,Retrievedfromhttp://www.economist. com/node/15557443
Diebold, F. X. (2012). A personal perspective on the origin(s) and develop-mentof “bigdata”:Thephenomenon, theterm,andthediscipline(Scholarly Paper No.ID 2202843). Social Science Research Network. Retrieved from http://papers.ssrn.com/sol3/papers.cfm?abstractid=2202843
Fan,J.,Han,F.,&Liu,H.(2014).Challengesofbigdataanalysis.NationalScience Review,1(2),293–314.
Fan,J.,&Lv,J.(2008).Sureindependencescreeningforultrahighdimensionalfeature space.JournaloftheRoyalStatisticalSociety:SeriesB(StatisticalMethodology), 70(5),849–911.
Feldman,R.(2013).Techniquesandapplicationsforsentimentanalysis. Communi-cationsoftheACM,56(4),82–89.
GartnerITGlossary(n.d.).Retrievedfrom http://www.gartner.com/it-glossary/big-data/
Gundecha,P.,&Liu,H.(2012).Miningsocialmedia:Abriefintroduction.Tutorialsin OperationsResearch,1(4)
Hahn,U.,&Mani,I.(2000).Thechallengesofautomaticsummarization.Computer, 33(11),29–36.
Hakeem,A.,Gupta,H.,Kanaujia,A.,Choe,T.E.,Gunda,K.,Scanlon,A.,etal.(2012). Videoanalyticsforbusinessintelligence.InC.Shan,F.Porikli,T.Xiang,&S.Gong (Eds.),Videoanalyticsforbusinessintelligence(pp.309–354).Berlin,Heidelberg: Springer.
Hasan,M.A.,&Zaki,M.J.(2011).Asurveyoflinkpredictioninsocialnetworks.In C.C.Aggarwal(Ed.),Socialnetworkdataanalytics(pp.243–275).UnitedStates: Springer.
Heidemann,J.,Klier,M.,&Probst,F.(2012).Onlinesocialnetworks:Asurveyofa globalphenomenon.ComputerNetworks,56(18),3866–3878.
He,W.,Zha,S.,&Li,L.(2013).Socialmediacompetitiveanalysisandtextmining:A casestudyinthepizzaindustry.InternationalJournalofInformationManagement, 33(3),464–472.
Laney,D.(2001,February6).3-Ddatamanagement:Controllingdatavolume,velocity andvariety. ApplicationDeliveryStrategies byMETAGroupInc.Retrieved from http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf
Liben-Nowell,D.,&Kleinberg,J.(2003).Thelinkpredictionproblemforsocial networks.InProceedingsofthetwelfthinternationalconferenceoninformation andknowledgemanagement(pp.556–559).NewYork,NY,USA:ACM. Liu,B.(2012).Sentimentanalysisandopinionmining.SynthesisLecturesonHuman
LanguageTechnologies,5(1),1–167.
Manyika, J., Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., et al. (2011).Bigdata:Thenext frontierfor innovation,competition, and produc-tivity. McKinseyGlobalInstitute. Retrieved from http://www.citeulike.org/ group/18242/article/9341321
Pang,B.,&Lee,L.(2008).Opinionminingandsentimentanalysis.Foundationsand TrendsinInformationRetrieval,2(1–2),1–135.
Panigrahi,B.K.,Abraham,A.,&Das,S.(2010).Computationalintelligenceinpower engineering.Springer.
Parthasarathy,S.,Ruan,Y.,&Satuluri,V.(2011).Communitydiscoveryinsocial networks:Applications,methodsandemergingtrends.InC.C.Aggarwal(Ed.), Socialnetworkdataanalytics(pp.79–113).UnitedStates:Springer.
Patil,H.A.(2010).“Crybaby”:Usingspectrographicanalysistoassessneonatal healthstatusfromaninfant’scry.InA.Neustein(Ed.),Advancesinspeech recog-nition(pp.323–348).UnitedStates:Springer.
Schroeck,M.,Shockley,R.,Smart,J.,Romero-Morales, D.,&Tufano,P.(2012). Analytics:Thereal-worlduseofbig data.Howinnovative enterprisesextract value from uncertain data. IBM Institute for Business Value. Retrieved from http://www-03.ibm.com/systems/hu/resources/therealworduseof bigdata.pdf
(2012,June26).Smallandmidsizecompanieslook tomakebig gainswith“big data,”according torecent poll conducted on behalfof SAP. Retrieved from http://global.sap.com/corporate-en/news.epx?PressID=19188
Sun,J.,&Tang,J.(2011).Asurveyofmodelsandalgorithmsforsocialinfluence analysis.InC.C.Aggarwal(Ed.),Socialnetworkdataanalytics(pp.177–214). UnitedStates:Springer.
Tang,L.,&Liu,H.(2010).Communitydetectionandmininginsocialmedia.Synthesis LecturesonDataMiningandKnowledgeDiscovery,2(1),1–137.
TechAmericaFoundation’sFederalBigDataCommission.(2012).Demystifyingbig data:ApracticalguidetotransformingthebusinessofGovernment.Retrieved from http://www.techamerica.org/Docs/fileManager.cfm?f=techamerica-bigdatareport-final.pdf
VanBoskirk, S., Overby, C. S., & Takvorian, S. (2011). US interactive mar-keting forecast 2011 to 2016. Forrester Research, Inc. Retrieved from https://www.forrester.com/US+Interactive+Marketing+Forecast+2011+To+ 2016/fulltext/-/E-RES59379
YouTube Statistics (n.d.). Retrieved from http://www.youtube.com/yt/press/ statistics.html
AmirGandomiisanassistantprofessorattheTedRogersSchoolofInformation TechnologyManagement,RyersonUniversity.Hisresearchliesattheintersectionof marketing,operationsresearchandIT.Heisspecificallyfocusedonbigdataanalytics asitrelatestomarketing.HisresearchhasappearedinjournalssuchasOMEGA -TheInternationalJournalofManagementScience,TheInternationalJournalof InformationManagement,andComputers&IndustrialEngineering.
MurtazaHaiderisanassociateprofessorattheTedRogersSchoolofManagement, RyersonUniversity,inToronto.MurtazaisalsotheDirectorofaconsultingfirm RegionomicsInc.Hespecializesinapplyingstatisticalmethodstoforecastdemand and/orsales.HisresearchinterestsincludehumandevelopmentinCanadaandSouth Asia,forecastinghousingmarketdynamics,transportandinfrastructureplanning anddevelopment.MurtazaHaiderisworkingonabook,GettingStartedwithData Science:MakingSenseofDatawithAnalytics(ISBN9780133991024),whichwill bepublishedbyPearson/IBMPressinSpring2015.Heisanavidbloggerandblogs weeklyaboutsocio-economicsinSouthAsiafortheDawnnewspaperandforthe HuffingtonPost.