2016 International Conference on Wireless Communication and Network Engineering (WCNE 2016) ISBN: 978-1-60595-403-5
An Efficient Method for Dynamic Recommendation
Ben-jie FAN
1, Ling CHEN
1,2and Chen XU
21Department of Computer Science, Yangzhou University, Yangzhou, 225009, China
2State Key Lab of Novel Software Tech, Nanjing University, Nanjing, 210093, China
Keywords: Recommendation algorithms, Collaborative filtering, Similarity between users.
Abstract. Most of the traditional collaborative filtering recommendation algorithms do not take into account the factor the time the users evaluate the items, they calculate the similarity between the users only using the static data. In many real world applications, the user's interest may change with the time. In this paper, we present an efficient method for such dynamic recommendation. The method calculates the similarity between the users based on their evaluation scores and times on the items. A fading factor is defined to emphasis of the recent ratings. The experimental results show
that the accuracy of the recommendation results by our method (UBCFT) is improved compared
with the existing collaborative filtering algorithms.
Introduction
It is the age of information deficiency. Everyday, people receive information from the newspapers, web sites, mobile applications and countless advertisements. Amidst all the noise, important and valuable information is being submerged. People need a valid information filter to help them find out the useful knowledge from enormous information networks such as social
networks [1], e-commerce[2], stream-media networks[3]. Recommender systems seek to provide the
information that may be interested by a particular user. The research of efficient recommendation methods has attracted much attention because of the abundance of practical applications that help
users to deal with information overload[4] and provide the personalized recommendations[5]. Many
recommend methods are proposed to model the user’s interest pattern and recommend the information user will be interested in based on his historical behavior. Examples of such applications include recommending products at Amazon.com, movies by MovieLens, and friends by Facebook, etc.
Based on how recommendations are made, recommend methods are usually classified into three
categories: Collaborative filtering[6], content-based method, graph based method[7]and hybrid
method[8]. In the collaborative filtering, the user will be recommended items that people with
similar preferences and tastes liked in the past. In the content-based method, the user will be recommended items similar to the ones she preferred in the past. The graph based method
constructs a bipartite graph based on the user-item matrix [10,11], and gets the recommendation
results by analyzing the bipartite graph. The hybrid method combines content-based and collaborative filtering methods to make recommendations.
Collaborative filtering is the most broadly adopted technique used to predict future item ratings
based on the user’s past behavior as well as ratings of other similar users[9]. It has been shown that
incorporating social network relationships and respective opinions/ratings improves the prediction, and consequently the recommendation process.
Although collaborative filtering is easy to implement, it cannot get high precision
recommendation results. To improve the quality of recommendation, Adomavicius et al.[12]
proposed a multidimensional recommend model integrating multidimensional information in
recommendation. Tso-Sutter et al.[13] presented a collaborative filtering method based on label
information of the items. Kukar [14] uses kernal based learning to detect the drifting concepts as
hidden factors of the users’ interests in recommendation.
directly be applied to dynamic recommendation. In many real world applications, the user's interest may change with the time. For instance, in a movie recommender system, a user may change her preference on certain genre of movies, or a user got a new point on an actor or a director. In addition, in many real-world systems, it is difficult to split different family members who use the same account. Different family members use the same account in different time, which leads to the apparent “interests drifting.”There were already some works devoted to temporal dynamic
recommender systems. Cao et al.[15] proposed four types of interest patterns and they use rating
graph and rating chain to detect those patterns. However, their work is limited by the specific
general interest patterns that are limited to only four types. Koren [16] proposed models tracking the
time changing behavior throughout the life span of data. It is proposed to revamp two leading CF approaches by introducing the time changing factors into neighborhood model and SVD, respectively. Koren’s model focuses on capturing both global time changing pattern and individual patterns. This ambition makes the model quite complicated. Many variables latent in the model represent specific meanings, and all those variables need to be tuned to get the best result when changing to another dataset. But the above framework is not able to deal with implicit data, and the explicit rating data is not always available.
In this paper, we present an efficient method for such dynamic recommendation. The method calculates the similarity between the users based on their evaluation scores and times on the items. The experimental results show that the accuracy of the recommendation results by our method is improved compared with the existing collaborative filtering algorithms.
Dynamic Recommendation Method
Problem Definition
Let U={u1, u2, …, un }be the set of n users, I={i1, i2, i3, …, im } be the set of m items. The users
evaluate the items by giving it a rating score. The input of a recommending problem can be treated
as a user-item matrix R=[rij] is an n*m matrix, where each element is a tuple rij=(pij,t). Here pij is the
rating score user ui assigns to item ij, t is the time ui assigns the score ,t=1,...T-1. The value of pij
reflects the preference of user ui on item ij at time t.
The value of pijcan be any real number, or integer as a rating score. If user ui has no rating on
item ij, then we set Pij=Ø,t=0, and call item ij is unknown for user ui. The task of recommendation is
as follows: Given a user ui and an integer k, estimate the rating for ui on the unknown items at time
T, and output the k unknown items with the highest ratings.
If user ui assigns rating score to item ij at time t, we denote T(pij)=t as the latest time ui rates item
ij.
Similarity between Users
We adopt the collaborative filtering approach based on user’s similarity. First we define the set of
items on which user ui has assigned rating score
( ) { |i k ik , and ( ik) [1, ]}
I u i p T p T . (1)
Then the set of items both users ui and uj have assigned rating score is denoted as
( ,i j) ( )i ( )j
I u u I u I u
(2)
Then similarity between users ui and uj at time T be defined as
, , 2
, ,
, , 1 | ( ) ( ) |
( , ) , ,
( ) [1, 1] ( ) [1, 1]
| |
1
( , , )
| ( , ) | max{ , }
i j ui k uj k
k i j i j
ui k uj k
u k u k T p T p
i j
i I u u
i j u k u k
T p T
T p T
p p
sim u u T e
I u u p p
Here, ( , ) ( , ) 2
i j
u k u k
T P T P is the difference of the times when users ui and uj assign rating score
on item ik. Lager time difference may reduce the similarity between the users ui and uj.
, , 2
, ,
max ,
i j
i j
u k u k
u k u k
P P
P P
is the difference ratio of the rating scores users ui and uj assign to item ik.
Smaller difference ratio may increase the similarity between the users. Δ1 and Δ2 are two adjusting
parameters, we set their values as 0.1 in our experiments.
The Recommendation Score
Suppose user ui assigns rating score puk on item ik at time T(puk), we evaluate the rating score users
ui on item ik at current time T as:
( )
. T T puk
uk uk
r p (4)
Here, δ∈(0, 1) is a fading factor, which is used to reduce the importance of the old rating scores. We
believe that the new rating scores are more reliable than the old ones, and shoul have larger influence on the recommendation results.
We use u(j)
u ui| iU and pij
to denote the set of users who have assigned rating scoreto itemij , and use rj to denote the average score of itemij at time T:
( )
1 ( )
j uj
u u j
r r
u j
(5)
We define the set of k users with the largest similarity with user ui as N(u). Then the final rating
score for recommending an unknown item ij to the target user ui at time T is:
, ( ) , ( ) ( , ) ( ) ( , ) k i k i j
i k kj
u N u j
ij
i k u N u
sim u u T r r
p r
sim u u T
(6)The k unknown items with the highest ratings scores are output as the recommendation results for
target user ui .
Experiment Results and Analysis
Testing Data
Here we conduct several experiments to test our algorithm and compare the quality of recommending results with other similar methods. We adopt MovieLens data set as our testing data. MovieLens consists of 100,000 ratings on an integer scale from 1 to 5 given to 1682 movies by 943 users, where each user has rated at least 20 movies. Each rating has a time stamp indicating the time user rates the item.
Evaluation Metrics
In our experiments, we use MAE (mean absolute value) which is widely used as a metric for movie recommendation performance. The formula to calculate the MAE is as following:
1 | | N i i i p q MAE N
(7)Here, N is the total number of ratings over all the users, pi and qi are the actual and predicted ratings
respectively. Obviously, less MAE indicates higher recommendation quality.
Testing Results
We applied 5-fold cross validation in our experiments. In each fold we have 80% data as the training set and the remaining 20% as the test data. The unit we used for setting the time stamp is 10^9ms. As a preprocessing on the data, we sort the data according to their time stamps, and delete
the users which have less than 10 common ratings with the target user. We set k=5, which means the
5unknown items with the highest ratings scores are output as the recommendation results for target
[image:4.595.111.486.165.335.2]user.
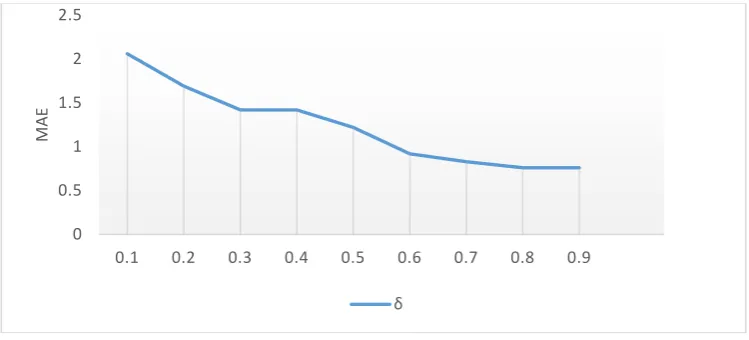
Figure 1. MAE values of the results by different values of δ.
Since fading factor δ is an important parameter in the method, we first test the method using
different values of δ to detect the influnce of δ on the recommendation results. Figure 1 shows the
MAE values of the results by different values of δ. From Figure 1, we can see that when δ<0.8, the
value of MEA decreases with larger value of δ. The MAE reaches its maximun value when δ=0.8,
therefore, we set value of δ as 0.8 in our experiment.
Table 1. MAE of the recommendation results by different algorithms.
Algorithm UBCF IBCFT UBCFT
MAE 0.82 0.80 0.76
We compare the proposed algorithm with some representative nd widely used dynamic recommendation algorithms. In the comparisons, all the competing algorithms were in online-updating forms and their parameters were set to their empirically best values. We compare our method with two similar algorithms: UBCF and IBCFT. Table 1 shows the MAE values of the results by the algorithm, where UBCF is the trditional user based collaborative filtering, and IBCFT
is the item based collaborative filtering algorithm on dynamic recommendation by Ren et al.[17], and
UBCFT is the user based collaborative filtering algorithm on dynamic recommendation predented by this paper. From the table we can infer that our algorithm UBCFT has the lowest MEA, which means it obtain the results with the highest accuracy among the algorithms.
Conclusion
In many real world applications, the user's interest may change with the time. Traditional collaborative filtering recommendation algorithms do not consider the time users rate the items. An efficient method for such dynamic recommendation is proposed. The method caculates the similarity between the users based on their evaluation scores and times on the items. A fading factor is difined to emphasis of the recent ratings. The experimental results show that the accuracy of the recommendation results by our method is improved compared with the existing similar methods.
Acknowledgments
This research was supported in part by the Chinese National Natural Science Foundation under grant Nos. 61379066, 61070047, 61379064, 61472344, 61402395, Natural Science Foundation of
0 0.5 1 1.5 2 2.5
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
MA
E
Jiangsu Province under contracts BK20130452, BK2012672, BK2012128, BK20140492 and Natural Science Foundation of Education Department of Jiangsu Province under contract 12KJB520019, 13KJB520026, 09KJB20013.
References
[1] Hooper E, Holloway R. Intelligent techniques for effective network protocol security monitoring, measurement and prediction[J]. International Journal of Security and Its Applications, 2008, 2(4): 1-10.
[2] Zhu J, Guo C, Wu Q. Conformance checking method for Web service interaction behaviors based on Petri nets[J]. Computer Engineering and Science, 2013, 35( 1) : 24 - 25.
[3] Pan F, Wu L, Du Y, et al. Overviews on protocol reverse engineering[J]. Application Research of Computers, 2011, 28( 8) : 2801- 2806.
[4 ] Resnick P, Iacovou N, et al. GroupLens: an open architecture for collaborative filtering of netnews[C]/ /Proceedings of the 1994 ACM conference on computer supported cooperative work, Chapel Hill, North Carolina, United States, October 22-26, 1994.
[5] Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions[J]. IEEE Trans. on Knowl. and Data Eng, 2005, 17: 734-749.
[6] Zhang Z, Wen Q, Tang W. Survey of mining protocol specifications[J]. Computer Engineering and Applications, 2013, 49( 9) : 1- 9.
[7] Sarwar B, Karyp Is G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms [C] Proc. Tenth International WorldW ideW eb Conference, 2001: 285-295.
[8] Deshpande M, Karypis G. Item-based top-N recommendation algorithms.[J] ACM Trans on Info Systems, 2004, 22(1): 143-177.
[9] Wang Y, Yun X, Shafiq M Z, et al. A semantics aware approachto automated reverse engineering unknown protocols[C] Proceedings of the 20th IEEE International Conference on Network Protocols. Piscataway: IEEE, 2012: 1 - 10.
[10] Zhang Z, Wen Q, Tang W. Survey of mining protocol specifications[J]. Computer Engineering and Applications, 2013, 49( 9) : 1- 9.
[11] Huang X, Chen X, Zhu N, et al. Protocol state machine reverse method based on labeling state[J]. Journal of Computer Applications, 2013, 33( 12) : 3486 - 3489.
[12] Adomavicius G, Tuzhilin A. Multidimensional recommender systems: a data warehousing approach[C] Proc of the 2nd International Workshop on Electronic Commerce. 2001: 180-192. [13] Tso-Sutter K H L, Marinho L B, Schmidt-Thieme L S. Tagaware recommender systems by fusion of collaborative filtering algorithms[C] Proc of ACM Symposium on Applied Computing. New York: ACM Press, 2008: 1995-1999.
[14] Kukar M. Drifting concepts as hidden factors in clinical studies [ C] Proc 9th Conf. on Artificial Intelligence in Medicine. Europe, Protaras, Cyprus, 2003.
[15] Y. Koren, Collaborative filtering with temporal dynamics, [J] Communicationsof the ACM, vol. 53, no. 4, pp. 89-97, 2010.
[16] H. Cao, E. Chen, J. Yang, and H. Xiong, Enhancing recommender systems under volatile user interest drifts, [C] in Proceedings of the 18th ACM Conference on Information and Knowledge Management. ACM, 2009, pp. 1257-1266.