The Anatomy of a Small-Scale Document
Search Engine Tool: Incorporating a new
Ranking Algorithm
1
KAUSTUBH S. RAVAL
Research Scholar
RANJEETSINGH S. SURYAWANSHI
Research Scholar
J. NAVEENKUMAR
Research Scholar
DEVENDRA M. THAKORE
Professor, Department of Computer Engineering
[email protected] 1, 2, 3, 4
Bharati Vidyapeeth Deemed University,
College of Engineering, Pune – 411043, Maharashtra, INDIA.
Abstract:
A search engine is an information retrieval system to help find out the information contained in documents
stored on a computer system. The results provided by this kind of a system are usually in form of a list. Search
engines basically work on the concept called ‘Text-Mining’. Text mining is a variation on a field called data
mining and refers to the process of deriving high-quality information from unstructured text. In this paper we
are going to depict an intelligent agent based search engine tool which takes the input from user in form of
keyword and based on the keyword, find out the matching documents and show it to user (in the form of links).
This tool uses a new ‘Ranking Algorithm’ to rank the documents.
Keywords – Search Engine, Text Mining, Intelligent Agent, Ranking Algorithm.
I. Introduction
First of all, we need basic information about various terms on which this work is to be carried out.
Search Engine: A search engine is an information retrieval system to help find out the information contained in
documents stored on a computer system. The results provided by this kind of a system are usually in form of a
list.
Search engines provide a user interface to a collection of items that enables users to specify criteria (i.e.
to as a search query. Then search engines identify the desired concept that one or more documents may contain.
The list of items that meet the criteria specified by the query is typically sorted, or ranked. Ranking items by
relevance (from highest to lowest) reduces the time required to find the desired information. [1]
Text Mining: Text-mining is a variation on a field called data-mining and refers to the process of deriving
high-quality information from the unstructured text. ‘High high-quality’ in text-mining usually refers to some combination
of relevance, novelty and interestingness. [2]
Intelligent Agents: Intelligent agents are software entities that carry out some set of operations on behalf of a
user with some degree of independence or autonomy, and in doing so, employ some knowledge or
representation of the user’s goals or desires. Software agents are useful in automating repetitive tasks, finding
and filtering information, intelligently summarizing complex data, and so on, but more importantly, just like
their human counterparts, intelligent agents can have capability to learn from the managers and even make
recommendations to them regarding a particular course of action. [3]
Ranking Algorithm: Ranking algorithms are mainly used to rank or index the documents based on some
relevance. They are a formal set of instructions that can be followed to perform ranking or indexing task, such as
a mathematical formula or a set of instructions in a computer program. A ranking is a relationship between a set
of items such that, for any two items, the first is either 'ranked higher than', 'ranked lower than' or 'ranked equal
to' the second. The rankings themselves are totally ordered and make it possible to evaluate complex
information according to certain criteria. [4]
Motivation: The literature study of various research papers and my interest in the field of ‘Data Mining’
motivated me to take up this as my dissertation topic for post-graduation.
Study of different existing ranking algorithms gave me insight how the ranking algorithms work and ultimately
provided me the idea of developing new algorithm.
Working scenario of ‘Google Search Engine’ also has been the motivational factor to take up this topic as my
dissertation work. ‘Google Search Engine’ is the best example of optimized intelligent software agent based
text-mining system encompassing a very large domain of web.
II. System Description
System description is the context which includes the details about the overall working of the existing or
proposed system.
Why Agents?
Text mining mainly includes the field of information retrieval which means the finding of documents which
contain answers to questions and not the finding of answers itself and for this to achieve statistical measures and
methods are used. By using statistical measures and methods automatic processing of text data and comparison
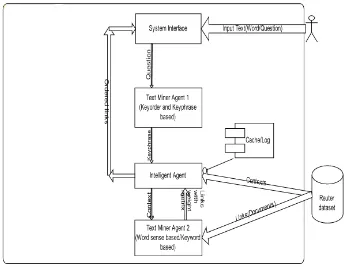
System Architecture
Fig. 1 shows the architectural diagram for intelligent agent based text-mining system. It includes all the
components required to make the system workable and the relationship and interaction between them. There are
mainly three agents, one dataset, the user category, and one cache/log component.
We are basically considering that all the processing has been done on the dataset and after those
pre-processing steps we would have following things:
i) List of keywords
ii) Table or File consisting of Contexts (categories) and their respective Keywords.
iii) Table or File consisting of Contexts and their respective Documents (Articles).
Now, how exactly the system should work is to be explained as follows:
Step 1: When the user types in something (Word), get that keyword and look up into the list of keywords.
Step 2: If the ‘keyword’ appears in the list then look for the corresponding category.
Step 3: After getting the corresponding category, find out all the documents in that category in which ‘keyword’
appears.
Step 4: Now, weigh all these documents for a given ‘keyword’ using term frequency method and assign weight
values to respective documents (articles).
Step 5: Now, using the ranking algorithm (which will be presented in the next section), rank all the documents
and then shows those ranked documents to user.
III. Algorithm
According to Webster’s Dictionary “An algorithm is a precise set of rules specifying how to solve some
problem”.
I’m going to write the steps for a new ranking algorithm which is used to rank documents based on their
weights. Weights of the documents are calculated using (tf*idf) equation, where ‘tf’ represents term frequency
(word frequency) and ‘idf’ represents inverse document frequency.
So, the equation for weighing a particular document d1 can be,
(1)
Where, tf(d1) - term frequency in document d1
n – Total number of documents
df – no. of documents in which the term appears.
Moreover, I’m considering that all the documents which contains the required word are weighted using the [Equ
– 1].
Now, below is the ranking algorithm for ranking the documents based on weight values calculated.
Ranking Algorithm
Inputs: list l, int dw[], int num
// ‘l’ is the list of documents in which inputted word appears.
// ‘dw’ is an integer array containing weight values of the documents in ‘l’.
// ‘num’ represents the no. of documents containing inputted word.
Output: list final // ‘final’ will contain all the ranked documents
Step 1: Find the average weight value by adding the weights of all documents in ‘l’ and dividing that by ‘num’.
Step 2: for all the documents in ‘l’, compare the weight of document with the ‘avg. weight’.
Step 3: The documents which are having less weight than the ‘avg. weight’ will be added to another list ‘M’ and
their weights are added to another array ‘weight1’ and the documents which are having more weight than ‘avg.
weight’ will be added to another list ‘N’ and their respective weights are added to another array ‘weight2’.
Step 4: If there are more than one documents in the list ‘N’ then recursively call the Algorithm with parameters
related to documents in list ‘N’. If all the documents in the list ‘N’ are having same ‘weight value’ then there is
no need to repeat the process because every time the average weight will be same and thus it will go into the
infinite loop. And if there is only one document in the list ‘N’ then add that document in the ‘final’ list.
Step 5: If there are more than one documents in the list ‘M’ then recursively call the Algorithm with parameters
related to documents in list ‘M’. If all the documents in the list ‘N’ are having same ‘weight value’ then there is Weight (d1) = tf(d1) * idf
no need to repeat the process because every time the average weight will be same and thus it will go into the
infinite loop. And if there is only one document in the list ‘N’ then add that document in the ‘final’ list.
Step 6: Display the documents in the list ‘final’ to the user.
Thus ‘final’ will have all the ranked documents with their title and data which will be displayed to user who had
given the search query using particular keyword.
IV. Results
We converted the above algorithm into JAVA programming code and tested it on the Reuters-21578 news
articles dataset. We had compiled and ran that code into command prompt and got the results as shown below
for the inputted word ‘APPLE’.
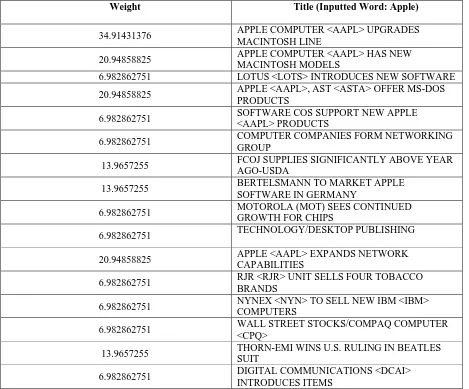
Table 1: Weighted Documents
Weight Title (Inputted Word: Apple)
34.91431376 APPLE COMPUTER <AAPL> UPGRADES MACINTOSH LINE
20.94858825 APPLE COMPUTER <AAPL> HAS NEW MACINTOSH MODELS
6.982862751 LOTUS <LOTS> INTRODUCES NEW SOFTWARE
20.94858825 APPLE <AAPL>, AST <ASTA> OFFER MS-DOS PRODUCTS
6.982862751 SOFTWARE COS SUPPORT NEW APPLE
<AAPL> PRODUCTS
6.982862751 COMPUTER COMPANIES FORM NETWORKING
GROUP
13.9657255 FCOJ SUPPLIES SIGNIFICANTLY ABOVE YEAR
AGO-USDA
13.9657255 BERTELSMANN TO MARKET APPLE
SOFTWARE IN GERMANY
6.982862751 MOTOROLA (MOT) SEES CONTINUED
GROWTH FOR CHIPS
6.982862751 TECHNOLOGY/DESKTOP PUBLISHING
20.94858825 APPLE <AAPL> EXPANDS NETWORK CAPABILITIES
6.982862751 RJR <RJR> UNIT SELLS FOUR TOBACCO BRANDS
6.982862751 NYNEX <NYN> TO SELL NEW IBM <IBM> COMPUTERS
6.982862751 WALL STREET STOCKS/COMPAQ COMPUTER
<CPQ>
13.9657255 THORN-EMI WINS U.S. RULING IN BEATLES
SUIT
6.982862751 DIGITAL COMMUNICATIONS <DCAI> INTRODUCES ITEMS
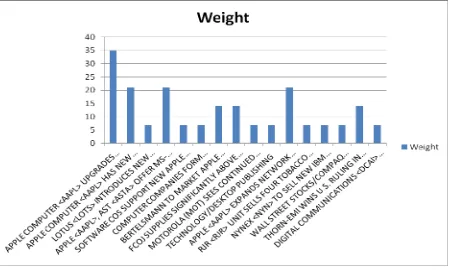
The graph has been generated on the basis of the result of the above table which shows the weight of the word in
each document with respect to which the documents has been weighted in descending order. The graph is shown
Figure 2: Weighted document graph.
The weighted document shown above in table 1 is just a sample, for showing the result of the algorithm which is
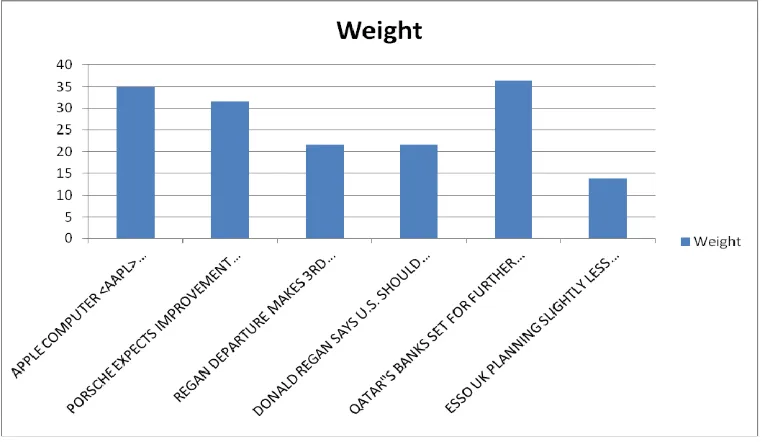
been implemented. Some more results about the words inputted to the algorithm are shown below. The graph
below shows the highest ranked documents for the searched word.
Table 2: Highest Ranked documents for various words
Weight Title
34.91431376 APPLE COMPUTER <AAPL> UPGRADES MACINTOSH LINE
31.59958129 PORSCHE EXPECTS IMPROVEMENT IN U.S.
SALES
21.61913187 REGAN DEPARTURE MAKES 3RD VOLCKER
TERM LIKELY
21.61913187 DONALD REGAN SAYS U.S. SHOULD EASE
CREDIT SUPPLY
36.35504269 QATAR"S BANKS SET FOR FURTHER LEAN SPELL
13.77510514 ESSO UK PLANNING SLIGHTLY LESS OIL
Figure 3: Graphs for highest ranked documents
Conclusion
Information retrieval in documents became a very tedious work because of very large amount of data. But if the
documents are weighted and ranked properly then the relevant documents are retrieved easily and with less
amount of time. Results in this research paper shows that, both, document weighing and ranking works
correctly. Thus we can conclude that there could be a small-scale search engine tool that can incorporate a new
ranking algorithm and serve the purpose of information retrieval in documents.
References
[1] http://en.wikipedia.org/wiki/Search_engine_ (computing)
[2] Vishal Gupta and Gurpreet S. Lehal, “A Survey of Text Mining Techniques and Applications”, Journal of Emerging Technologies in Web Intelligence, vol. 1,pages 60-76, August 2009
[3] Stuart Russell and Peter Norvig, “Artificial Intelligence, Chapter 2: Intelligent Agents – A Modern Approach”. [4] http://en.wikipedia.org/wiki/Ranking
[5] Kaustubh S. Raval, Ranjeetsingh S. Suryawanshi and Prof. Devendra M. Thakore, “An Intelligent Agent Based Text-Mining System: Presenting Concept through Design Approach”, International Journal of Computer Science and Information Security, Vol.9 No.4, pages. 112-117, April 2011.