A Novel Method for Location based Neighbor
Search over Spatial Database
Vinodkumar Shinde1, Madhuri Patil2
P.G. Student, Department of Computer Engineering, DYPSOET, Lohgaon, Pune, India1
Associate Professor, Department of Computer Engineering, DYPSOET, Lohgaon, Pune, India2
ABSTRACT: Customary spatial queries, for instance achieve interest and nearest neighbor retrieval, incorporate just conditions on articles geometric properties. Right now, various present day applications call for novel appearances of request that arrangement to find articles satisfying both a spatial predicate, and a predicate on their related compositions. For example, instead of considering every one of the restaurants, a nearest neighbor request would rather ask for the diner that is the closest among those whose menus contain "steak, spaghetti, cognac" all in the meantime. At present, the best response for such queries is in perspective of the IR2-tree, which, as demonstrated, has two or three deficiencies that genuinely impact its viability. Enlivened by this, develop another access framework called the spatial altered file that adds to the customary adjusted rundown to adjust to multidimensional data, and goes with estimations that can answer nearest neighbor request with conclusive words persistently. As affirmed by tests, the proposed methodologies defeat the IR2-tree being referred to response time basically, frequently by a part of solicitations of enormity.
KEYWORDS:Keyword search, nearest neighbor search, spatial index.
I. INTRODUCTION
A spatial database manages multidimensional articles, (for instance, points, rectangles, etc.), and gives snappy access to those things considering various decision criteria. The essentialness of spatial databases is reflected by the solace of exhibiting components of reality geometrically. Case in point, zones of restaurants, hotels, facilities in this way on are as often as possible addressed as centres in an aide, while greater degrees, for instance, stops, lakes, and scenes frequently as a mix of rectangles[1]. Various functionalities of a spatial database are useful in various courses specifically associations. For instance, in a geography information system, degree request can be passed on to find all diners in a specific domain, while nearest neighbor recuperation can discover the restaurant closest to a given area. Today, the no matter how you look at it use of web searchers has made it functional to create spatial queries in a sparkly new way. Commonly, addresses focus on articles' geometric properties just, for instance, whether a point is in a rectangle, or how closed two centres are from each other. We have seen some present day applications that require the ability to pick articles considering both of their geometric bearings and their related compositions. Case in point, it would be truly profitable if a web record can be used to find the nearest restaurant that offers "steak, spaghetti, and cognac" all meanwhile. Note this is not the "thoroughly" nearest restaurant (which would have been returned by a routine nearest neighbor request), however the nearest diner among simply those giving all the asked for supports and drinks. There are basic ways to deal with support request that combine spatial and content highlights. Case in point, for the above request, we could first get every one of the restaurants whose menus contain the plan of watchwords {steak, spaghetti, brandy}, and after that from the recuperated diners, find the nearest one.
give steady answers on troublesome inputs. A regular specimen is that the honest to goodness nearest neighbor lays a long way from the inquiry point, while all the closer neighbors are lost no under one of the request enchantment words. Examines recommend that at any rate approximately 20% of all web questions have neighborhood expectation, implying that the questions target nearby substance. In step with the web being utilized progressively by versatile clients, this rate can be required to increment. Next, geo-situating is progressively accessible for cell phones, e.g., by method for inherent GPS collectors. This empowers web clients who inquiry for neighborhood substance to give their areas to benefits. Web crawlers as of now perceive neighbourhood goal, and specific administrations, e.g., maps and yellow page administrations, that objective neighborhood content keep on multiplying. For illustration, travel locales, for example, Trip Advisor and Travellers Point offer administrations that empower clients to discover with specific offices and situated specifically locations. A few propositions as of now exist for the questioning for geo-found web content, termed spatial web objects. An area mindful keyword query takes an area and determined watchwords as contentions and returns web questions that are positioned by spatial nearness and content importance in respect to the question.Spatial queries with enchantment words have not been extensively explored.
In the earlier years, the gathering has begun energy in considering catchphrase look for in social databases. It is as yet that thought was diverted to multidimensional data. The best framework to date for nearest neighbor look with watchwords is a direct result. They enjoyably fuse two most likely comprehended thoughts: R-tree, a noticeable spatial document, and check report, a suitable system for enchantment word based record recuperation. By doing thusly they develop a structure called the IR2-tree, which has the characteristics of both R-trees and check records. Like R-trees, the IR2-tree items spatial closeness, which is the best approach to unwinding spatial request gainfully. Then again, similar to check records, the IR2-tree has the limit channel a broad part of the articles that don't contain all the inquiry enchantment words, hence on a very basic level lessening the amount of things to be broke down.The IR2-tree, on the other hand, in like manner gets a drawback of imprint reports false hits. That is, an imprint report, in view of its conservative nature, might at present direct the request to a couple of things, regardless of the way that they don't have all the conclusive words. The discipline therefore conveyed on is the need to check an article whose delightful a request or not can't be resolved using only its mark, yet rather obliges stacking its full substance depiction, which is unrestrained in view of the consequent self-assertive gets to. It is essential that the false hit issue is not specific just to check records, but instead also exists in various schedules for estimated set support tests with diminished stockpiling. As needs be, the issue can't be cured by basically supplanting mark record with any of those procedures.
We arrange a variety of changed record that is enhanced for multidimensional centres, and is as needs be named the spatial rearranged file (SI-list). This passage technique viably solidifies point arranges into a routine adjusted rundown with minimal extra space, inferable from a delicate preservationist stockpiling arrangement. Meanwhile, a SI-file spares the spatial locale of data centres, and goes with a R-tree in light of each altered rundown at little space overhead. Likewise, it offers two fighting courses for inquiry taking care of. We can (successively) merge different records all that much like consolidating standard adjusted records by ids. On the other hand, we can in like manner impact the R-trees to look the reasons of each relevant summary in rising solicitation of their partitions to the inquiry point
II. RELATEDWORK
The IR2 - Tree and Solution based on inverted index:
stack rearranged record data (i.e., a guide of qualities to individual lines) into a social database. Our configuration gives an option where image tables map catchphrases to segments that have accessible lists. The work in locations the issue of closeness ventures over semi-organized stores. Interestingly, our centre is on finding careful matches in a multi-connection database that contains all catchphrases indicated in the question, [2]obliging us to study outline choices for image tables and additionally to create systems for join tree list. The statistical data points from chose locates on the Internet, and permits them to be joined and examined in complex courses .Since our work permits sites to uncover their even data for empowering watchword seek, the instrument at The search component of DBXplorer bears resemblance to work on universal relations by DBXplorer innovation.
The records (I-record) have ended up being an intense get to framework for watchword based report recuperation. In the spatial setting, nothing keeps us from treating content as a report, and afterward, constructing an I-record. Each word in the vocabulary has an altered once-over, numbering the canters’ ids that have the word in their documents. Note that the once-over of each word keeps up a sorted solicitation of point ids, which gives noteworthy settlement being referred to permitting to handle a beneficial union step. This is essentially to prepare the two's merging words' reworked records. As both records are sorted in the same solicitation, we can do in that capacity by consolidating them, whose I/O and CPU times are both straight to the total length of the summaries. Audit that, in N taking care of with IR2-tree, a point recouped from the rundown must be affirmed (i.e., having its substance delineation stacked and checked). Affirmation is furthermore crucial with I-list, yet for absolutely the backwards reason. For IR2 -tree, affirmation is by virtue of we don't have the separated works of a point, while for I-record, it is on the grounds that we don't have the bearings. Starting at this moment influence of I-record starts to pay off. That is, separating an modified once-over is reasonably unassuming in light of the way that it incorporates simply progressive I/Os, one as opposed to the unpredictable method for getting to the centre points of an IR2-tree.
III.PROPOSED METHOD
To identify the place of certain areas by using nearest neighbor based model. Several factors, which have great impact on the searching of the place measurements, are identified and investigated.
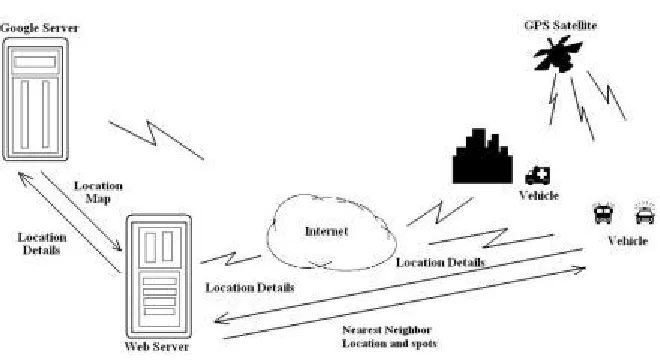
Nearest neighbor based model is utilized to evaluate the area of specific spots, completely taking the portability and item dynamism. A few key elements, which have extraordinary effect on the exactness of the area estimations of better places, are recognized and explored. Successful systems to remunerate the negative impacts have been created. Finding that diverse area can be sorted utilizing the closest area. This outcome gives valuable knowledge to the city organizers for future city advancements. The Nearest neighborspots, and examination results demonstrate that few top spots are veryarea reliable after some time.Framework structural planning comprises of Google server, web server and GPS which is allocate to the vehicles. Web server-It can gets the area data of vehicles from specific GPS then area data is send to the Google server and get back the area map from Google server. Google server-It gives the area guide to the web server. At the point when web server get the area map script around then it is broke down by web server and it anticipate the data of vehicle area and it provides for the confirm vehicle clients. The consequences of nearest neighbor based model are approving.
IV.MERGING AND DISTANCE BROWSING
From the verification is the execution bottleneck, we must try to avoid it. There is an essential way to deal with do in that capacity in an I-list: one simply needs to store the headings of each point together with each of its appearances in the upset records. The region of bearings in the rearranged records. Typically induces the development of a R-tree on each rundown indexing the centres in that (a structure reminiscent of the one in Next, we discuss how to perform keyword based closest neighbor look with such a joined structure. The R-trees grant us to cure heaviness in the way NN questions are readied with an I-list. Survey that, to answer an request, at this moment we have to first get all the core interests passing on all the inquiry words in by combining a couple once-overs This radiates an impression of being outlandish if the point, It would be magnificent in case we could discover p soon in all the appropriate records so that the computation can end promptly. This would transform into a reality in case we could look the once-overs synchronously by divisions rather than by ids. In particular, the length of we could get to the reasons of all once-overs in rising solicitation of their divisions to q (breaking ties by ids), such a p would be successfully found as its copies in all the once-overs would point of fact grow successively in our passage demand.
So we just to just to keep checking what number of copies of the same point have showed up reliably and end just check, in light of the fact that at whatever point another point creates, it is sheltered to slight the by reporting the point once the check accomplishes at any moment, it is adequate to remember one and past one. Partition examining is basic with R-trees. To be sure, the best first calculation is decisively proposed to yield data centres in rising solicitation of their partitions to q. On the other hand, we should encourage the execution of best-first on R-trees to get an overall access demand. This can be adequately achieved by, for example, at each stride taking a "look" at the taking after point to be returned from each tree, and yield the specific case that should come next universally.
V. EXPERIMENTAL RESULTS
DBXplorer has been conveyed on genuine databases from the intranet inside Microsoft. For its usage, we influence IIS web server and Active Server Pages (ASP). The principle Publish and Search segments are bundled as two separate COM (Component Object Model) objects. The distribute segment gives interfaces to select a database, select tables/sections inside of the database to distribute, and change/evacuate/keep up the production. The hunt segment gives interfaces to recover coordinating databases from an arrangement of distributed databases, and specifically recognize tables, segments/pushes that should be sought inside of every database distinguished in step. The particular interfaces for the last incorporate. It discovers all the coordinating tables/sections, for a given arrangement of watchwords, discover all lines in the database that contain the majority of the catchphrases.
over such huge archives is a test. One of the key parts of such an internet searcher is the performance. A structure for GIR frameworks concentrate on indexing systems that can prepare SK queries productively. We appear through analyses that our indexing procedures lead to noteworthy change in productivity of noting SK questions over existing strategies. An indexing structure called IR2-Tree (Information Retrieval R-Tree) which joins an R-Tree with superimposed content marks. It presents calculations that develop and keep up an IR2-Tree, and utilize it to answer top-k spatial watchword questions. Our calculations are tentatively contrasted with current strategies and are appeared to have predominant execution and astounding versatility.
VI.
Fig. 2. (a) Search Result Of multiple User Login(b) Nearest Place Search Result.
VII. CONCLUSION
Thus the proposed system remedied the situation by developing an access method nearest neighbor based model search depending on distance and function or properties of location. We have seen a considerable measure of usages requiring a web searcher that has the limit gainfully to very strong novel sorts of spatial queries that are facilitated with vital word look. The present responses for such queries either realize prohibitive space use or are not ready to give ceaseless answers. We have offered the condition by adding to a passageway framework some assistance with calling the spatial changed rundown (SI-index). Not only that the SI-rundown is modestly space judicious, furthermore it can perform significant word extended nearest neighbor look in time that is at the solicitation of numerous milli-seconds. Plus, as the SI-record is considering the normal development of surprise show, it is expeditiously incorporable in a business web crawler that applies huge parallelism, inferring its brisk advanced advantages.
REFERENCES
[1] Yufei Tao and Cheng Sheng, ”Fast Nearest Neighbor Search with Keywords”(IEEE), VOL. 26, NO. 4, APRIL 2014.
[2] S. Agrawal S. Chaudhuri, and G. Das, “Dbxplorer: A System for Keyword-Based Search over Relational Databases,” Proc. Int’l Conf Data Eng. (ICDE), pp. 5-16, 2002.
[3] G. Bhalotia, A. Hulgeri, C. Nakhe, S. Chakrabarti, and S.Sudarshan, “Keyword Searching and Browsing in Databases Using Banks,” Proc. Int’l Conf. Data Eng. (ICDE), pp. 431-440,2002.
[4] D. Zhang, Y.M. Chee, A. Mondal, A.K.H. Tung, and M. Kitsuregawa,“Keyword Search in Spatial Databases: Towards Searching by Document,” Proc. Int’l Conf. Data Eng. (ICDE),pp. 688-699, 2009.
[5] I. D. Felipe, V. Hristidis, and N. Rishe, “Keyword Search on Spatial Databases,” Proc. Int’l Conf. Data Eng. (ICDE), pp. 656-665, 2008. [6] X. Cao, G. Cong, C.S. Jensen, and B.C. Ooi, “Collective Spatial Keyword Querying,” Proc. ACM SIGMOD Int’l Conf. Management of Data,
pp. 373-384, 2011.
[7] R. Hariharan, B. Hore, C. Li, and S. Mehrotra, “Processing Spatial- Keyword (SK) Queries in Geographic Information Retrieval (GIR) Systems,” Proc. Scientific and Statistical Database Management (SSDBM), 2007.
[8] V. Hristidis and Y. Papakonstantinou, “Discover: Keyword Search in Relational atabases,” Proc. Very Large Data Bases (VLDB), pp. 670-681, 2002.
[9] J. Lu, Y. Lu, and G. Cong, “Reverse Spatial and Textual k Nearest Neighbor earch,” Proc. ACM SIGMOD Int’l Conf. Management of Data, pp. 349-360, 2011.
[10] Y. Zhou, X. Xie, C. Wang, Y. Gong, and W.-Y. Ma, “Hybrid Index Structures for Location-Based Web earch,” Proc. Conf. Information and Knowledge Management (CIKM), pp. 155-162, 2005.
[11] G. Cong, C.S. Jensen, and D. Wu, “Efficient Retrieval of the Top-kMost Relevant Spatial Web Objects,” PVLDB, vol. 2, no. 1, pp. 337-348, 2009.