Leverage Statistics Reduplication To Improve The Capability Of Key
Storage Design In The Cloud
1M.Bhanu Sri, 2K. Spurthy & 3 I. Narasimha Rao
1M-Tech, Dept. of CSE,Medha Institute of Science Technology for Woman,Khammam.
2Associate professor, Dept. of CSE,Medha Institute of Science Technology For Woman,
Khammam.
3HOD, Dept. of CSE,Medha Institute of Science Technology For Woman,Khammam.
Abstract
With the touchy amplification in information
volume, the I/O bottleneck has turned into an
undeniably overwhelming test for enormously
monster information examination in the Cloud.
Late examinations have demonstrated that direct
to high information repetition limpidly subsists
in essential stockpiling frameworks in the Cloud.
Our trial contemplates uncover that information
excess shows a considerably higher bore of
power on the I/O way than that on plates
because of moderately high worldly get to
territory related with minute I/O solicitations to
repetitive information. Besides,
straightforwardly applying information
deduplication to essential stockpiling
frameworks in the Cloud will probably cause
space dispute in memory and information
discontinuity on circles. Predicated on these
perceptions, we propose an execution situated
I/O deduplication, called POD, as opposed to a
capacityoriented I/O deduplication, exemplified
by iDedup, to improve the I/O execution of
essential stockpiling frameworks in the Cloud
without sacrificing limit reserve funds of the last
mentioned. Case adopts a two dimensional
strategy to enhancing the execution of essential
stockpiling frameworks and limiting execution
overhead of deduplication, to be specific, a
demand predicated particular deduplication
procedure, called SelectDedupe, to ease the
information fracture and a versatile memory
administration conspire, called iCache, to
encourage the memory conflict between the
bursty read traffic and the bursty indite traffic.
We have executed a model of POD as a module
in the Linux working framework. The trials
directed on our lightweight model usage of POD
demonstrate that POD significantly beats
iDedup in the I/O execution measure by up to
87.9% with a normal of 58.8%. Also, our
assessment comes about furthermore
commensurable or preferable limit funds over
iDedup.
Key words: - I/O Deduplication, Data
Redundancy, Primary Storage, I/O Performance,
Storage Capacity.
1.INTRODUCTION
Information deduplication has been exhibited to
be a strong strategy in Cloud reinforcement and
filing applications to decrease the reinforcement
window, enhance the storage room efficiency
and system data transfer capacity use. Late
investigations uncover that direct to high
information repetition limpidly subsists in VM
(Virtual Machine) [6], [7], venture [2], [9], [3],
[8] and High-Performance Computing (HPC)
[1], [7] capacity frameworks. These
investigations have demonstrated that by
applying the information deduplication
innovation to enormously giant scale
informational collections, a normal space saving
of 30%, with up to 90% in VM and 70% in HPC
stockpiling frameworks, can be accomplished
[6], [3], [2]. For instance, the ideal opportunity
for the live VM movement in the Cloud can be
significantly decreased by embracing the
information deduplication innovation [6]. The
subsisting information deduplication plans for
essential stockpiling, for example, iDedup [3]
and Offline-Dedupe [8], are capacityoriented in
that they focus on capacity limit investment
funds and just winnow the cosmically enormous
solicitations to deduplicate and sidestep all the
minute solicitations (e.g., 4KB, 8KB or less).
The basis is that the tiny I/O asks for represent a
modest division of the capacity limit essential,
making deduplication on them unprofitable and
conceivably counterproductive considering the
significant deduplication overhead included. In
any case, point of reference workload examines
have uncovered that moment files overwhelm in
essential stockpiling frameworks (over half) and
are at the foundation of the framework execution
bottleneck [9], [3], [4], [10], [7]. Besides,
because of the support impact, essential
stockpiling workloads display prominent I/O
burstiness [5], [4]. From an execution point of
view, the subsisting information deduplication
plans neglect to consider these workload
qualities in essential stockpiling frameworks,
missing the chance to address a standout
amongst the most important issues in essential
stockpiling, that of execution.
2. RELEGATED WORK 2.1Existing System
The subsisting information deduplication plans
for essential stockpiling, for example, iDedup
and Offline-Dedupe, are limit arranged in that
they focus on capacity limit funds and just
to deduplicate and sidestep all the moment
demands (e.g., 4KB, 8KB or less). The basis is
that the small I/O asks for represent a minute
part of the capacity limit essential, making
deduplication on them unfruitful and possibly
counterproductive considering the generous
deduplication overhead included.
2.2Proposed System
To address the significant execution issue of
essential stockpiling in the Cloud, and the above
deduplication-initiated difficulties, we propose a
Performance-Oriented information
Deduplication conspire, called POD, instead of a
limit arranged one (e.g., iDedup), to change the
I/O execution of essential stockpiling
frameworks in the Cloud by considering the
workload qualities. Unit adopts a two
dimensional strategy to improving the execution
of essential stockpiling frameworks and limiting
execution overhead of deduplication, to be
specific, a demand predicated particular
deduplication procedure, called Cull-Dedupe, to
reduce the information fracture and a versatile
memory administration conspire, called iCache,
to encourage the memory conflict between the
bursty read movement and the bursty indite
activity.
3. IMPLEMENTATION
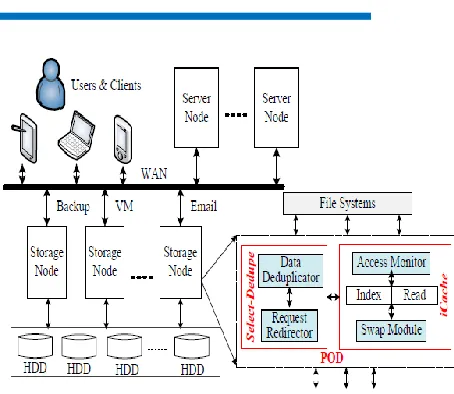
Fig 1: System Architecture
3.1Information deduplication:
Information deduplication has been exhibited to
be a solid strategy in Cloud reinforcement and
documenting applications to lessen the
reinforcement window, revise the storage room
productivity and system data transmission usage.
The Data deduplication procedure to recognize
the repetitive substance on plates yet does not
dispose of them on the I/O way. This authorizes
the circle make a beeline for settlement the read
asks for by pre-getting the most proximate
squares from all the repetitive information
obstructs on plate to lessen the look for idleness.
The indite demands are still issued to circles
regardless of the possibility that their
information has just been put away on plates.
3.2Unit:
Unit dwells in the capacity hub and
communicates with the File Systems by means
POD can be simply fused into any
HDD-predicated essential stockpiling frameworks to
speed up their framework execution.
Additionally, POD is autonomous of the upper
document frameworks, which makes POD more
adaptable and convenient than entire record
deduplication and iDedup. It can be conveyed in
an assortment of situations, for example, virtual
machine pictures that are generally
indistinguishable however contrast in a couple of
information squares.
3.3Separate Dedupe:
The ask for predicated Cull-Dedupe incorporates
two individual modules: Data Deduplicator and
Request Redirector. The Data Deduplicator
module is in charge of part the approaching
indite information into information pieces,
computing the hash estimation of every
information lump, and recognizing whether an
information piece is excess and mainstream.
Predicated on this data, the Request Redirector
module chooses whether the indite demand
ought to be deduplicated, and keeps up
information consistency to block the referenced
information from being overwritten and
refreshed.
3.4iCache:
The iCache module withal incorporates two
individual modules: Access Monitor and Swap
Module. The Access Monitor module is in
charge of checking the power and hit rate of the
approaching read and indite demands. Predicated
on this data, the Swap module powerfully
modifies the reserve space parcel between the
list store and read reserve. In addition, it swaps
in/out the reserved information from/to the
back-end stockpiling. iCache profits ask for
predicated Cull-Dedupe deduplicate whatever
number excess information obstructs as could be
expected under the circumstances and corrects
the read execution by extending the read reserve
measure in face of read blasts.
4. EXPERIMENTAL RESULTS
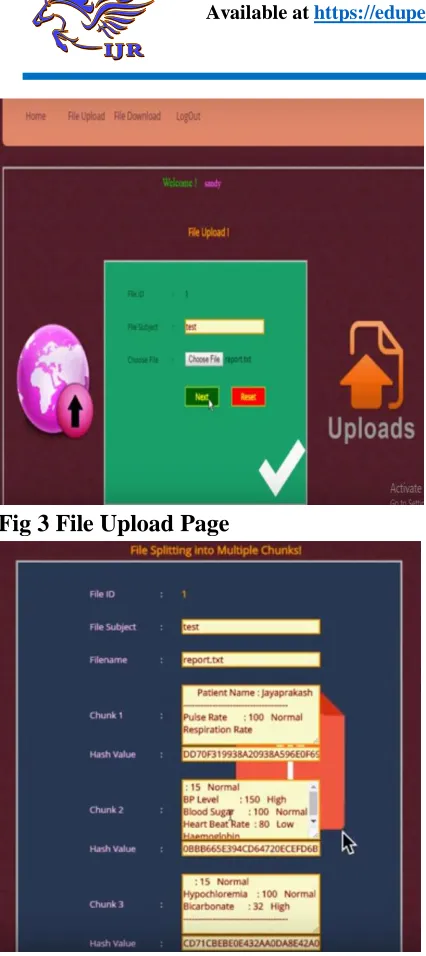
Fig 3 File Upload Page
Fig 4 while uploading a file data split into multiple chunks
Fig 5 View all storage space
Fig 6 File download page 5. CONCLUSION
In this paper, we propose POD, an execution
situated deduplication conspire, to change the
execution of essential stockpiling frameworks in
the Cloud by utilizing information deduplication
on the I/O way to extract repetitive indite
demands while withal saving storage room. It
deduplication approach (Cull-Dedupe) to
deduplicating the I/O excess on the basic I/O
way such that it limits the information fracture
problem. In the in the mean time, a sharp reserve
administration (iCache) is utilized in POD to
additionally improve read execution and
augmentation space safeguarding, by habituating
to I/O burstiness. Our broad tracedriven
assessments demonstrate that POD significantly
improves the execution and jam limit of
essential stockpiling frameworks in the Cloud.
Case is a never-ending research venture and we
are at present investigating a few headings for
the future research. To start with, we will
consolidate iCache into other deduplication
plans, for example, iDedup, to examine how
much benefit iCache can convey to safeguarding
additional capacity limit and enhancing read
execution. Second, we will manufacture a
strength measurement module to assess the
vitality efficiency of POD. By lessening indite traffic and protecting storage room, POD can
possibly save the puissance that plates expend.
We will analyze the additional power that CPU
expends for processing fingerprints with the
puissance that the capacity jam, subsequently
efficiently examining the vitality efficiency of
POD.
6. REFERENCE
[1] Bo Mao, Member, IEEE, Hong Jiang, IEEE
Fellow, Suzhen Wu, Member, IEEE and Lei
Tian, Senior Member, IEEE Leveraging Data
Deduplication to Improve the Performance of
Primary Storage Systems in the Cloud.
[2] A. Anand, S. Sen, A. Krioukov, F. Popovici,
A. Akella, Andrea C. Arpaci-Dusseau, Remzi H.
Arpaci-Dusseau, and S. Banerjee. Avoiding File
System Micromanagement with Range Writes.
In OSDI’08, Dec. 2008
[3] A. Batsakis, R. Burns, A. Kanevsky, J.
Lentini, and T. Talpey. AWOL: An Adaptive
Write Optimizations Layer. In FAST’08, Feb.
2008.
[4] P. Carns, K. Harms, W. Allcock, C. Bacon,
S. Lang, R. Latham, and R. Ross. Understanding
and Improving Computational Science Storage
Access through Continuous Characterization.
ACM Transactions on Storage, 7(3):1–26, 2011.
[5] F. Chen, T. Luo, and X. Zhang. CAFTL: A
Content-Aware Flash Translation Layer
Enhancing the Lifespan of Flash Memory based
Solid State Drives. In FAST’11, pages 77–90,
Feb. 2011.
[6] A. T. Clements, I. Ahmad, M. Vilayannur,
and J. Li. Decentralized Deduplication in SAN
Cluster File Systems. In USENIX ATC’09, Jun.
2009.
[7] L. Costa, S. Al-Kiswany, R. Lopes, and M.
trade-offs from an Energy Perspective. In ERSS’11,
Jul. 2011.
[8] A. El-Shimi, R. Kalach, A. Kumar, A.
Oltean, J. Li, and S. Sengupta. Primary Data
Deduplication - Large Scale Study and System
Design. In USENIX ATC’12, Jun. 2012.
[9]FIUtraces. http://iotta.snia.org/traces/390.
[10] D. Frey, A. Kermarrec, and K. Kloudas.
Probabilistic Deduplication for Cluster-Based
Storage Systems. In SOCC’12, Nov. 2012.
Authors Profiles
M.BHANU SRI
She is presently pursing M-Tech in Medha
institute of technology for woman in branch of
computer science. I did my bachelor degree in
computer science engineering stream
K.SPURTHY
Currently working as an associate professor in
Medha institue of science technology for woman
in JNTUH University in branch of computer
science. I published more than 4 papers in
different journals in different zones. She did
specialization in mobile computing and network
security.
NARASIMHA RAO
Currently working as a head of department in
medha institue of science technology for woman
in JNTU University in branch of computer
science. He published more than 4 papers in
different journals in different zones. He did