A Cognitive Approach For Automatic Generation
Of Knowledge Map With Artificial Intelligence
B.Lavanya, A.Auxilia Princy
Abstract: The automatic generation of concept map are widely required in many fields, for precise understanding of the mandatory concepts. The concept extraction from the text automatically can help us to build any framework. This automatic generation can be achieved by the machine learning and deep learning algorithms .In this paper we have proposed an automatic system for concept map generation. Apriori, support vector machine, recurrent neural network and feed forward and back propagation algorithms are used to build our model. This automatic map generation aids the cognitive understanding of a concept, domain and a book in precise and with less time.
Keywords-: Apriori, Text Mining, SVM, Back propagation, Feed Forward, PCA Neural Network — — — — — — — — — — — — — — — — — — —
1.
INTRODUCTION
WHEN we are about to read a book, we always try to get the content of book by reading the preface or about the book, instead of reading the whole book or document or any preface, if we can automatically generate the concept of the text, it is simple and easy for us to remember the mind map drawn. Therefore we are identifying the concepts of any text book or any pdf content using artificial intelligent algorithms, like apriori algorithm, Feed Forward neural network, Back Propagation, Principle component analysis with using Support Vector Machine classification.We have proposed two systems variation with different combination of algorithms. The first approach is, the Apriori algorithm is used to find the association between the words of the text, which retrieves the most frequent words by finding the term frequency of inverse document (tdif), which helps to retrieve the rare and useful word in the document. Then the output of the apriori is fed to the Back propagation model to predict the exact words that describe the input text.The second approach is using the principal component analysis to reduce the dimension of words by calculating the tdif and retrieve a group of important words then by using SVM classifier, the words are classified that a group of same number of tdif terms are grouped, then that groupof words are allowed in a feed forward network to find the related group of terms and the concepts can be identified.
2
RELATED
WORK:
The automatic concept mapping is being researched for a very long time, there are different techniques being discussed, one of them is frequent pattern mining, apriori algorithm which is a classical and an important algorithm for pattern mining , V.R.Sadasivam states that apriori and FP growth algorithm gives a good frequent pattern mining on a crime data set[1].Sonam Tripathi says that apriori and fp growth is best in text mining and is used on existing term-based approach and produces that problem of polysemy and synonymy in text mining[2]. B.Thillaieswari gives Comparative Study on Tools and Techniques of Big Data Analysis by the following algorithms, Decision Trees, Naïve Bayes, Random Forest and Support Vector Machines (SVM), which could be used to analyse any big data [3]Neha Sharma proposes that neural network is used for sentiment analysis to find the mood of tweet , where it helps in accessing the text relation easily by Sentiment Analysis of Social Media Text Data using Back Propagation in Artificial Neural Networks[4]. Sukhpal Kaur gives a solution to overcome a problem for managing the web news data by clustering based K-means and Back Propagation Neural Network algorithm for classification.[5] It also say that big text data can be handled by back propagation.Shuihua Wang propose a system for Fruit Classification by Wavelet-Entropy and Feed forward Neural Network Trained by Fitness-Scaled Chaotic optimisation, were the developed system consists of principal component analysis (PCA), feed forward neural network (FNN) trained by fitness-scaled chaotic artificial bee colony (FSCABC).therefore the idea of implementing PCA and FNN for text can be inferred from this paper.[6] Jason Reynaldo propose that Data Mining Application using Association Rule Mining ECLAT Algorithm Based on SPMF give us a hundred percent accuracy in pattern mining, this ECLAT algorithm works similar like FP Growth algorithm.[7] Versace remy states an article about the content accuracy n extracting from memory mapping in cognitive physcology, were the extracting the content from a document will help to increase the efficiency of the knowledge extracted from the text content.[8]
3.PROPOSED
METHOD:
An automatic generation of concept map is implemented by two different algorithm, and the three stages of processes, the pre processing of the text, then we identify the concepts
_______________________
Corresponding author ,B.lavanya is Assistant professor in University of madras , Chennai-600025 E-mail: [email protected]
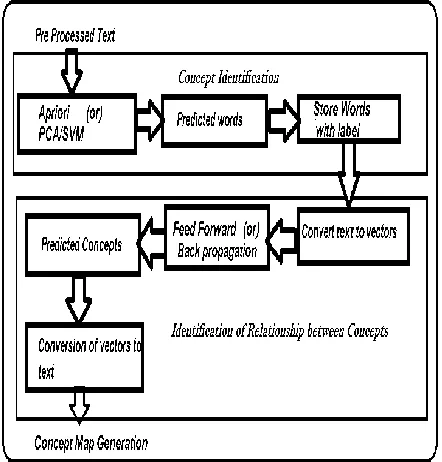
and finally, find the relationship between the words. The work flow of our model is shown in the following figure1.
Fig 1: Work flow of Automatic generation of concept map.
3.1 Pre Processing text:
A whole document or text is pre processed, before feeding to our model, that is first we remove stop words , and perform tokenization ,Lemmatisation, Term Frequency – Inverse Document Frequency (TF-IDF) for each word , which helps to find the frequency of word and its importance.
3.2 Proposed Algorithm
The proposed algorithm uses the following data mining and machine learning algorithms
3.2.1 Apriori Algorithm:
The Apriori helps to find the association between the most frequent words . the output of apriori is rule that is formed for the support and confidence level specifed, calculated by our algorithm.support is minimum count of the number of time the word has appeared. Confidence is Confidence(A->B)=Support count(A∪B)/Support count(A)
3.2.2 Principal Component Analysis :
It helps to reduce the dimensions of space by vector factor, of the text.
3.2.3 Support vector machine:
It helps to separate the linearly separable problem, that the group of words will have same number of Tf-IDF factor. By using SVM classifier we can group the words.
3.2.4 Eclat Algorithm:
The Eclat is like FP Growth algorithm, where it finds frequent item set by generating the tree, which is easy to find the redundant data. It uses a depth first search
3.2.1 3.2.5 Feed Forward Neural Network:
The neuron is trained with the weight and bias calculation and it predict the word present or not. This help in identifying the relationship between the words
3.2.2 3.2.6 Back Propagation:
The Output is given again as an input so by training the model for some n number of times we can find the word most important in our text.
Proposed Algorithm:
Input: Plain text document Output: Concepts
Begin
Txt=Input the text document
Filter text= pre process Txt to get the content Rule1=Proposed Algorithm(Filter text) # Proposed Algorithm=Apriori or PCA/SVM or Éclat
Vec= Rule1 to Vector Predicted Word=Network(Vec)
#Network=Feed Forward or Backpopagation Cmap=any concept mapping tool (Predicted Word)
#Map is Generated End
3.3 Concept map Generation
The proposed algorithm give us important words from the text and how relatively it is needed, therefore we can give this to any open source software for further application of mapping.
4. DATA
AND
RESULTS:
We are using five different books from different discipline; the yoga research book is our first data D1. It is of 175 Pages and 1, 605, 64 words in the book. Our proposed model has three different approaches.
4.1 The Association Approach:
a) the Pre processed , then filtered or cleaned text contains, 14236 words ,
b) Now the words are ready to process through apriori algorithm to find the most frequent word and the rule is formed. The figure2 is the screen shot of the apriori output.
c) The rule is given to the Back Propagation (BP) model for further process to find the relation between the words. The result of BP is shown in the figure3.
Fig2: Output of Apriori Algorithm
Fig3: output of Back Propagation Network model
Fig4 : Final concept Mapping of Approach 1
4.2 The Classification approach:
a) The processed text has 4011 words after calculating tfid value
b) Then text i processed by PCA algorithm with 811 words as showm in figure5.
c) Then the SVM Classification is used to get the group of same number of TD-Idf value,figure6 d) Then the classified group of data is taken into a
feed forward network to find one particular group of words which are useful. figure 7
Fig 5: Traing data after PCA .
Fig 6: Output after Feed Forward Network
Fig 7: Final Concept Mapping of Approach 2
4.3 Graph Mining Approach:
a) The eclat algorithm is used and the output rules obtained is shown in figure8.
Fig 8:Output of Eclat
Fig9: Output concept map of eclat
5
WORK
ANALYSIS:
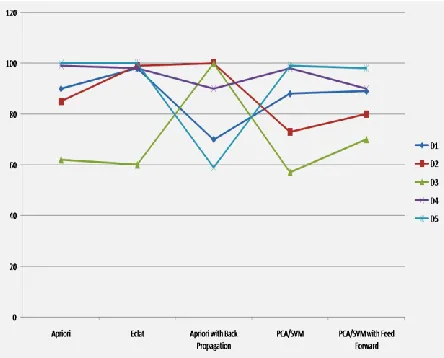
The Model was tested by five different data,D1 is a yoga research Book, D2 is a General Physcology book,D3 is a White paper of Google security,D4 is a Bio medical Digital Signal Processing book,D5 is a Software engineering book. The performance of the algorithm by accuracy score is listed in the tabel1
TABEL1
PERFORMANCE COMPARISION BY ACCURACY(IN PERCENTAGE)
DATA SET
Apriori Eclat
Apriori with Back Propagation
PCA/SVM
PCA/SVM with Feed Forward
D1 90 98 70 88 89
D2 85 99 100 73 80
D3 62 60 100 57 70
D4 99 98 90 98 90
D5 100 100 59 99 98
The data D1 has 175 pages and D2 has 83 pages and D3 is a security agreement document which has only 17 pages, and D4 is a 378 pages book and finally the D5 has 648 pages book, From the table we infer that the performance is good when we have more number of pages, and when there are less number of words accordingly it give us the accuracy score. Comparing the performance of D3 from D4 we can say that apriori with back propagation can give us good result whether the number of pages is big or small.
Fig10: The Performance evaluation Graph between
Algorithms for five Different Data
In figure 10 the graph contains, the x axis is the Algorithm names and the y axis is the scale of accuracy value, the different data (D1, D2...D5) is shown in different colour. From the graph we observe that the performance of the algorithm are similar range with respect to the data and also the éclat give us a same level of performance for any kind of data, because among the five data only one data is varied level of performance.
TABLE 2
OVER ALL COMPARISON OF PERFORMANCE BETWEEN THE THREE APPROACHES
Performa nce metrics
Association Approach (Apriori with BP)
Graph Mining Approach (Eclat)
Classificatio n Approach (PCA with SVM and FF) Accuracy 83.8 (in %) 91(in %) 85.4(in %)
Execution time
133.28(in sec)
80.6481(i n sec)
199.0988(in sec) Number
of rule
Average of 15 rules
Average of 10 rules
Average of 20 rules
From the performance table, it is understood that, the éclat gives rules in more précised manner than PCA , and the apriori has a moderate set of rules generated. The execution time approach 2 takes less time than the other two approaches because the other two approaches uses the neural network algorithm to predict the final words, so by comparing the association approach and graph mining approach we get to know the usage of association approach is good than the other approach.
6
APPLICATION
OF
THE
MODEL:
7
CONCLUSION
AND
FUTURE
WORK:
The concept mapping is widely used by students, researchers, and it helps to find the knowledge about the document in a short form, and in short period of time. However, big the document may be or any kind of document can be tested!! Future work can be extended to any language ,that is now our model support s English language only, it can be extended to any other languages by using NLP processing according to the language of that text in beginning of our model process and that can be applied further to our proposed model, and it application are vast in technology.
8
REFERENCE:
[1] V R Sadasivam, Dr K Duraisamy , R Mani Bharathi:” Association Rule Mining And Frequent Pattern Mining Applications On Crime Pattern Mining: A Comprehensive Survey”: International Journal Of Innovative Research In Science, Engineering And Technology Vol. 4, Special Issue 6, May 2015 [2] Ms. Sonam Tripathi , Asst Prof. Tripti Sharma:”A
Survey Paper For Finding Frequent Pattern In Text Mining”: International Journal Of Advanced Research In Computer Engineering & Technology (Ijarcet) :Volume 4 Issue 3, March 2015
[3] B.Thillaieswari:” Comparative Study On Tools And Techniques Of Big Data Analysis”: International Journal Of Advanced Networking & Applications (Ijana): Volume: 08, Issue: 05 Pages: 61-66 (2017) [4] Neha Sharma, Sarang Mandloi:” Sentiment Analysis
Of Social Media Text Data Using Back Propagation In Artificial Neural Networks”: International Journal For Research In Applied Science & Engineering Technology (Ijraset): Issn: 2321-9653; Ic Value: 45.98; Sj Impact Factor :6.887 Volume 6 Issue I, January 2018- Available At www.Ijraset.Com.
[5] Sukhpal Kaur And Er. Mamoon Rashid:” Web News Mining Using Back Propagation Neural Network And Clustering Using K-Means Algorithm In Big Data”: Indian Journal Of Science And Technology:Vol 9(41), Doi: 10.17485/Ijst/2016/V9i41/95598, November 2016
[6] Shuihua Wang , Yudong Zhang , Genlin Ji , Jiquan Yang , Jianguo Wu And Ling Wei :” Fruit Classification By Wavelet-Entropy And Feedforward Neural Network Trained By Fitness-Scaled Chaotic Abc And Biogeography-Based Optimization”: Entropy 2015, 17, 5711-5728; Doi:10.3390/E17085711 [7] Jason Reynaldo, David Boy Tonara:” Data Mining
Application Using Association Rule Mining Eclat Algorithm Based On Spmf”: Matec Web Of
Conferences 164, 01019 (2018)
https://Doi.Org/10.1051/Matecconf/201816401019 Icesti 2017
[8] Versace Remy, Mathieu Lesourd, Elodie Labeye :” Journal Of Cognitive Psychology”: Article In Journal Of Cognitive Psychology · January 2014