Identification and Classification of Heart
Disease with Feature Selection
A.K. Shrivas
Department of IT, Dr. C. V. Raman University, Bilaspur, Chhattisgarh, India [email protected]
Amit Kumar Dewangan
Department of CSE, Dr. C. V. Raman University, Bilaspur, Chhattisgarh, India [email protected]
Abstract: Data mining techniques are being used in every field to extract the knowledge from large amount of database. Healthcare is one of the important areas generates huge amount of data and extract the useful information or knowledge. Medical science and technology are trying to prevent and diagnosis of various types of disease which provide high degree of accurate results. Heart disease is a serious and dangerous disease facing by the human being. This research paper uses Decision tree algorithm like C4.5, Classification and Regression Technique (CART), Random Forest (RF) and Bayes Net as classifier for classification of heart disease. We have developed two ensemble models like ensemble of RF, C4.5, and CART and ensemble of Bayes Net, CART and C4.5 as classifier for classifying heart disease and achieved better classification accuracy. We have also used Info gain and Gain ratio feature selection techniques (FSTs) to develop computationally efficient model and ensemble of Bayes Net, CART and C4.5 gives better accuracy as 60.65% of accuracy with 8 features in case of both FSTs.
Keywords: Classification, Ensemble Model, Heart Disease, Feature Selection Technique (FST).
1. Introduction
In the modern era, human beings are facing various problems due to increasing number of diseases in healthcare organization. Many healthcare organizations are facing a challenging and problem of quality services like diagnosing patients correctly and administering treatment at reasonable costs [10]. Data mining techniques avoid the types of problem and give the solution to healthcare organization. Classification is one of the data mining methods for creating models based on supervised data. Data mining based classification techniques are used to identify and categorize of different level of heart disease data. Some authors have worked in the field of classification of heart disease as discussed below:
2. Proposed Model
Figure 1 shows that architecture of proposed model depicted with heart disease data set, classifiers, ensemble models, FSTs and different level of heart disease. In this architecture, heart disease data set applied on different individuals and ensemble classifiers for classification of different level of heart disease. To computationally increase the performance of model, we have applied the Info gain and Gain ratio FSTs on ensemble models. Our proposed ensemble model classifies the heart disease with safe level, low risk, medium level, high risk and very high risk and very high risk level.
C4.5
CART
RF
Bayes Net
RF+C4.5+CART
BaysNet+CART+C4.5 Ensemble Model Heart
Disease Data Set
Info gain Gain Ratio
Safe level
Low risk
Medium risk
High risk
Very High risk
Classifiers
FSTs
Fig 1. Proposed Model.
3. METHODS AND MATERIALS
This section includes various data mining based classification techniques for classification of different level of heart disease or not. This section also includes description of data set used in this research work.
3.1. Decision Tree
Decision tree is data mining based classification techniques to generate the rules and classification of data based on this rule. Decision tree [6] is most popular and powerful classification techniques in which in the training stage a tree like structure is formed where each non-leaf node is decision node which splits according to the features of training data while leaf node represent class node, Once the decision tree is formed, unknown samples can be presented to the root node of decision tree and ultimately reaches to the class node to classify the sample as one of the target class.
This research work has used C4.5, CART and RF as decision tree [8]. CART [8] builds a binary decision tree by splitting the record at each node, according to a function of a single attribute. CART uses the gini index for determining the best split. C4.5 [8] is an extension of ID3 that accounts for unavailable values, continuous attribute value ranges, pruning of decision trees and rule derivation. C4.5 produces tree with variable branches per node. Random Forest (or RF) [11] is an ensemble classifier that consists of many decision trees and outputs the class that is the mode of the classes output by individual trees. Random Forests are often used when we have very large training datasets and a very large number of input variables (hundreds or even thousands of input variables). A random forest model is typically made up of tens or hundreds of decision trees.
3.2. Bayes Net
Bayesian classifiers [6] are statistical classifiers. They can predict class membership probabilities, such as the probability that a given tuple belongs to a particular class. Bayesian classification is based on Bayes’ theorem. Classification algorithms have found a simple Bayesian classifier known as the Naive Bayesian classifier to be comparable in performance with decision tree and selected neural network classifiers. Bayesian classifiers have also exhibited high accuracy and speed when applied to large databases.
3.3. Ensemble Technique
3.4. Feature Selection
Feature selection is optimization techniques to optimize the data from data set. The main motives of FSTs are selecting the relevant feature from data set and increase the performance of models. The feature selection is not only improving the performance of model also increase the computational time. In this research work we have used Info gain and Gain ratio FST. The Info gain measures prefers to select attributes having a large number of values. The extension to Info gain known as gain ratio based on ranking, which attempts to overcome bias [6].
3.5 Data Set
We have collected Processed Cleveland Heart Diseases data set from UCI repository [9]. The data set contains 13 features and 303 instances with five classes having safe level, low level, medium level , high level and very high level. The data set is multiclass problem. The data set contains features namely age(1), sex(2), cp(3), trestbps(4), chol(5), fbs(6), restecg(7), thalach(8), exang(9), oldpeak(10), slope(11), ca(12)and thal(13), where 1 to 13 represents feature id.
4. Results and Discussion
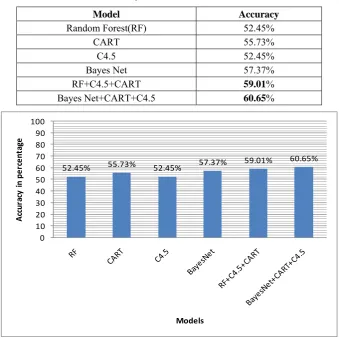
In this research work, we have used WEKA data mining tool [7] for analysis of Processed Cleveland Heart Diseases data set. WEKA is an open source software tool which contains various classification techniques used in this research work. This research work used decision tree techniques like C4.5, CART and RF and Bayes Net for analysis and classification of different level of heart disease with 80%-20% training-testing data partition. The accuracy of RF, CART, C4.5 , Bayes Net as shown in table 1 where CART gives better classification accuracy as 55.73%.
To achieve the better classification accuracy, we have ensemble the individuals trained classifiers and achieved the best accuracy 59.01% and 60.65% of accuracy with proposed ensemble of RF, C4.5 and CART and ensemble of Bayes Net, CART and C4.5 respectively as shown in table 1. Fig. 2 shows that accuracy of individuals and its ensemble models.
Table 1. Accuracy of individuals and ensemble models.
Model Accuracy
Random Forest(RF) 52.45%
CART 55.73%
C4.5 52.45%
Bayes Net 57.37%
RF+C4.5+CART 59.01%
Bayes Net+CART+C4.5 60.65%
52.45% 55.73% 52.45% 57.37% 59.01%
60.65%
0 10 20 30 40 50 60 70 80 90 100
A
ccu
ra
cy
i
n
p
e
rce
n
ta
ge
Models
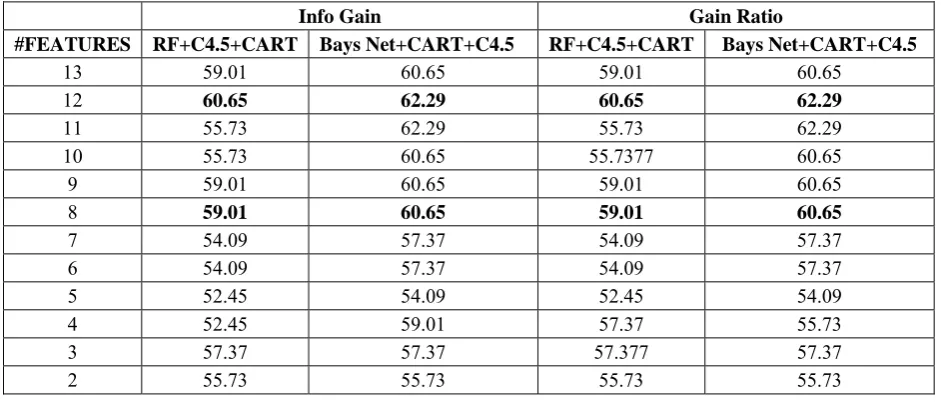
Feature selection is a feature optimization technique which is remove the irrelevant features from data set and is used to improve the performance of models. This research work has used Info gain and Gain ratio FST to rank the features based on its importance. Info gain FST ranks the features in descending order as feature-id 13,3,12,10,9,8,11,1,2,5,6,4,7 while Gain ratio FST ranks the feature as feature-id 13,3,12,9,10,8,11,1,2,5,6,4,7. Table 2 shows that accuracy of ensemble of RF,C4.5, and CART and ensemble of Bayes Net ,CART and C4.5 with different feature subset . Table 2 shows that accuracy of best ensemble models with Info gain and Gain ratio FST. The proposed ensemble of RF,C4.5, and CART gives 59.01% of accuracy with 8 features in case of both Info gain and Gain ratio FST while ensemble of Bayes Net, CART and C4.5 gives 60.65% of accuracy with 8 features in case of both Info gain and Gain ratio FST. The accuracy of ensemble models give similar accuracy in case of both FST because most of the features are ranked same order. We have recommended an ensemble of Bayes Net, CART and C4.5 model gives satisfactory results. Table 3 shows that comparative analysis of existing and proposed model with Cleveland heart disease data set where our proposed model outperform others.
Table 2. Accuracy of models with different feature subset with multiclass problem.
Info Gain Gain Ratio
#FEATURES RF+C4.5+CART Bays Net+CART+C4.5 RF+C4.5+CART Bays Net+CART+C4.5
13 59.01 60.65 59.01 60.65
12 60.65 62.29 60.65 62.29
11 55.73 62.29 55.73 62.29
10 55.73 60.65 55.7377 60.65
9 59.01 60.65 59.01 60.65
8 59.01 60.65 59.01 60.65
7 54.09 57.37 54.09 57.37
6 54.09 57.37 54.09 57.37
5 52.45 54.09 52.45 54.09
4 52.45 59.01 57.37 55.73
3 57.37 57.37 57.377 57.37
2 55.73 55.73 55.73 55.73
Table 3. Comparative Analysis of existing and proposed model with Cleveland heart disease data set.
Authors Technique Accuracy
Pawlak, A. (1991) Genfis 2 39.2%
Tsipouras, M. G. (2008) Fuzzy+ Decision tree classifier 51.79%
Mantas, J. C. (2014) C4.5 59.97%
Srinivas, K. (2014) Rough-Fuzzy classifier 46.48%
Patel, J. (2015) J48 56.76%
Shrivas, A. K. et al. Proposed Technique(Ensemble of Bayes Net,
CART and C4.5) 60.65%
5. Conclusion
Detection of heart disease is very sensitive and challenging task for medical science. Classification techniques play major role to identify and categorize the various level of heart disease or not. In this research work, proposed two ensemble models in which ensemble of Bayes Net, CART and C4.5 gives better results compares to individuals and other ensemble model. An optimization of features play important role to develop computationally efficient model. We have used Info gain and Gain ratio FST to select the relevant features from original feature space. The proposed ensemble model gives satisfactory results with few numbers of features and recommended as classifier for classification of heart disease.
References
[1] Khormehr, A. and Maihami, A. (2016): A Novel Fuzzy Expert System Design for Predicting Heart Diseases. International Journal of Computer Applications, 138 (4) , pp. 33-38.
[5] Raghavendra, S. and Indiramma, M. (2015) , Classification and Prediction Model using Hybrid Technique for Medical Datasets. International Journal of Computer Applications, 127 (5) , pp. 20-25.
[6] Han, J. and Kamber, M. (2006): Data Mining Concepts and Techniques. Morgan Kaufmann, San Francisco. 2nd ed.. [7] Web source: http:// www.cs.waikato.ac.nz/~ml/weka/ (last accessed on Feb. 2017).
[8] Pujari, A. K. (2001): Data Mining Techniques. Universities Press (India) Private Limited, 4th ed..
[9] UCI Repository of Machine Learning Databases, University of California at Irvine, Department of Computer Science. Available:http://www.ics.uci.edu/~mlearn/databases/ (Browsing date: Feb. 2017).
[10] Akhil Jabbar , M. , Deekshatulu ,B. L. and Chandra, P. (2013): Classification of Heart Disease Using K- Nearest Neighbor and Genetic Algorithm. International Conference on Computational Intelligence: Modeling Techniques and Applications (CIMTA) 2013, 10, pp. 85 – 94.
[11] Parimala, R. and Nallaswamy, R. (2011): A Study of Spam e-mail Classification using Feature Selection Package. Global Journal of Computer Science and Technology, 11, ISSN: 0975-4172.
[12] Patel, P., Upadhyayand, T., Patel, S. (2016): Heart Disease Prediction Using Machine learning and Data Mining Technique. International Journal of Computer Science Communication, 7 (1), pp. 129- 137.
[13] Long, N. C. , Meesad, P. and Unger , H. (2015): A highly accurate firefly based algorithm for heart disease prediction. Expert Systems with Applications , 2015, pp. 1-11.
[14] El-Bialy, R. ,.Salamay, M. A , Karam , O. H and Khalifa, M. E. (2015): Feature Analysis of Coronary Artery Heart Disease Data Sets. International Conference on Communication, Management and Information Technology , 65 , pp. 459 – 468.
[15] Leema, N., Nehemiah, H. K. and Kannan, A. (2016): Neural Network Classifier Optimization using Differential Evolution with Global Information and Back Propagation Algorithm for Clinical Datasets. Applied Soft Computing, 49(C), pp. 834-844.
[16] Srinivas, K. , Rao, G. R. and Govardhan, A. (2014): Adapting rough fuzzy classifier to solve class imbalance problem in heart disease prediction using FCM. International. Journal of Medical Engineering and Informatics, 6 (4) , pp. 297-318.
[17] Mantas, C. J. and Abellán, J. (2014): Credal-C4.5: Decision tree based on imprecise probabilities to classify noisy data . Expert Systems with Applications , 41, pp. 4625- 4637.
[18] Dennis, B. and Muthukrishnan, S. (2014): AGFS: Adaptive Genetic Fuzzy System for medical data Classification . Applied Soft Computing, 25, pp. 242–252.
[19] Pawlak, A. (1991): Rough Sets: Theoretical Aspects of Reasoning about Data, Kluwer AcademicPublishers.
[20] Tsipouras, M. G., Exarchos, T. P. , Fotiadis , D.I., Kotsia, A. P. , Vakalis, K. V. , Naka, K. K. and and Michalis, L. K.(2008): Automated diagnosis of coronary artery disease based on data mining and fuzzy modeling. IEEE Transactions on Information Technology in Biomedicine, 4(12) , pp. 447–458.