International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
337
Improved e-Governance Model Using Association Rule Mining
S. Anuradha
1, Dr. E. Kirubakaran
21
PhD Research Scholar-Full Time, School of Computer Science, Engg..&Applications, Bharathidasan University, Tiruchirappalli, India
2Additional General Manager, Bharat Heavy Electricals Limited, Tiruchirappalli, India
Abstract— The higher educational institutions uses the information systems for all their academic purposes. e-Governance is used in all the aspects of the higher education sector. Decision making is the key challenge in the current scenario. These institutions have tera bytes of data and using this data for key decision making is the critical issue. If these institutions uses the available data for better planning for their courses, this would be of much useful to the students. This research proposes of use of association rule mining algorithms for improving the e-Governance in higher educational institutions.
Keywords— Association Rule Mining, e-Governance, Software Agents.
I. INTRODUCTION
Governments around the world are recognizing the value of Government. Properly designed and implemented, e-Government can improve efficiency in the delivery of government services, simplify compliance with government regulations, strengthen citizen participation and trust in government, and yield cost savings for citizens, businesses and the government itself. Not surprisingly, therefore, policymakers and managers are looking to adopt e-Government in countries around the world - ranging from the most developed to the least developed (Otike, 2012 ). eGovernment and e-governance can be defined as two very distinct terms. e-Governance is a broader topic that deals with the whole spectrum of the relationship and networks within government regarding the usage and application of ICTs. e-Government is actually a narrower discipline dealing with the development of online services to the citizen, more the e on any particular government service-such as e-tax, e-transportation or e-health (William Sheridan, 2010).
II. MOTIVATION
Devising a successful curriculum plan is very important in any higher education system. A good curriculum plan gives a successful career path to the students.
As most of the universities used Information Systems for their successful e-Governance tasks, it is the appropriate time for the universities to use their historical data for better decision making in all the levels.
Introducing technology to the student decision making process aims at leveraging repetitive tasks on software and dedicating time to helping a student plan his/her education road map. An automated system for decision making or a technology-based advisory system helps a student plan the proper courses to take, by checking and listing courses for which he/she has satisfied the prerequisites, allowing students to do the work themselves, without referring to their advisors (Leora Waldner, E-Advising Excellence: The New Frontier in Faculty Advising, 2011). E-advising answers the question of how to provide timely, high-quality advising services to geographically separated online students and/or onsite students with conflicting work or family schedules that cannot readily come to office hours (Khalifa, 2012) (Anuradha 2017).
It is important that, the University need to facilitate the students by giving the most current information regarding course selection, educational history and as well as current and future educational and career demands. At present, most of the Universities maintain the database of the student performance for many years and have terabytes of data. Using these information systems, the student can select the courses based on the approved curriculum. Few Universities also implemented e-Advising systems at certain level. These systems lack proper decision making. If data mining is used in this decision-making process, it helps the student in preparing effective educational plans. This is the appropriate time for the Universities to apply data mining in their data and retrieve useful knowledge and share it with all the stake holders (Jiawei Han, 2011).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
338
III. OBJECTIVE
The following are the objectives of this research i. To improve the decision making in the existing
e-Governance models in higher education systems with reference to academic monitoring.
ii. Propose an architecture by including the appropriate data mining techniques and software agents.
iii. To apply data mining techniques for discovering the hidden relationships in the archive database.
In order to meet the objective, the following steps are considered
i. The existing e-Governance systems with respect to proposed interactive and improved e-advising system are analyzed in details.
ii. Analyzed the association rule mining techniques in the available e-Governance systems.
iii. Identified the appropriate association techniques. These techniques are used in the proposed architecture.
iv. A software architecture is proposed to implement the e-Governance model.
v. A prototype is developed by considering the identified data mining techniques, type of software agents, and specialized database. Microsoft Visual Studio .net platform is used as front end for prototype development.
MS-Access database is used as a back end.
vi. The developed prototype is tested to meet the stated objectives.
IV. SCOPE OF THE PAPER
Few higher educational institutions are not producing quality graduates. This leads to long range problems to students and institutions. This research addresses this issue by using the technology in enhancing the quality of students. The available data from student information system used by these institutions are considered initially to prove the validity of the developed model. The scope of the thesis is limited to e-Governance in higher educational institutions. This research work used the academic monitoring database available with the higher educational institutions. Data mining techniques are analyzed and identified to be used in the developed prototype. The software agents’ usage and its implications are well studied. Four new algorithms are designed, developed and tested in this research work. This new data structure contains the information from the industry experts which includes the current trends, expectations and job potentials in the chosen stream
V. REVIEW OF LITERATURE
e-Advising and data mining
Lamiaa Mostafa et al (Lamiaa Mostafa N. K., 2012) proposes to produce a mechanism that executes the advising problems automatically instead of the manual academic process. The mechanism converts the individual course into a group of concepts and enables matching of similarities between concepts of different courses. The framework is proposed to overcome some of manual limitations related to limited number of advisors (labor intensive) that are not able to serve the huge number of students, advising double curricula (double major), and lack of advising knowledge.
Heba Mohammed et al (Heba Mohammed Nagy, 2013) proposes a ―Student Advisory Framework‖ that utilizes classification and clustering to build an intelligent system. The developed system is used to provide pieces of consultations to a first-year university student to pursue a certain education track where he/she will likely succeed in, aiming to decrease the high rate of academic failure among these students. The author uses the classification algorithm C4.5 and k-means clustering algorithm in the research work. The results from classification and clustering operations are combined to predict more accurate results, all of these procedures were applied to improve the level of success of the first year university stage.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
339
Moreover, further research lies in the area of expanding the system with semantic attributes, such as adding semantic annotation to the web services exported, in order to enable it with broader integration capabilities with other ontology based resources systems.
E-Advising and Software Agents
Fuhua Lin et al (McGreal, e-Advisor: A Web-based Intelligent System for Academic Advising, 2007) presents an approach to tackle a dynamic and complex individualized study planning and scheduling problem utilizing multi-agent system approach and ontology-driven methodology. To support the approach a web-based multiple intelligent agents system called e- Advisor is developed and tested with students registered with the MSc IS program offered by the School of Computing and Information System of Athabasca. e-Advisor is a Web-based intelligent system that facilitates academic advising and program planning to meet MSc IS students’ needs in seeking advice and therefore reducing the advisors’ workload, and to support decision-making of MSc IS program administrators in scheduling courses. E-advisor is implemented on the multi-agent development platform JADE (http://jade.tilab.com/) and runs on two Agent Platforms running Linux operating system. The paper describes the various types of agents used in e-Advisor, the development of the ontologies and their applicability, system implementation issues and a preference-driven planning algorithm used by the agents. This paper concludes that in future further analysis of data accumulated in planning and knowledge maintenance processes can be done to assist in determining student profiles, communications, and decision-making behavior which will make intelligent agents more adaptive and responsive, and therefore we can expect better services from the system.
Katia Sycara et al (Katia Sycara, 1996) presents a reusable multi agent computational infrastructure RETSINA Reusable Task Structure based Intelligent Network Agents for structuring and organizing distributed collections of intelligent software agents in a reusable way. This is said to have three agents namely interface agents, task agents, information agents. This system framework has been implemented and are developing collaborating agents in diverse complex real world tasks such as organizational decision making (the PLEIADES system) and financial portfolio management (the WARREN system).
The paper concludes that such flexible distributed architectures consisting of reusable agent components will be able to answer many of the challenges that face users as a result of the availability of the vast new net based information environment. These challenges include locating accessing filtering and integrating information from disparate information sources monitoring the Infosphere and notifying the user or an appropriate agent ab out events of particular interest in performing the user designated tasks and incorp orating retrieved information into decision support tasks.
E-Governance and Software Agents
Zbigniew Piotrowski paper (Piotrowsk, 2017) addresses the issues concerning citizens’ mobility (both for personal and professional purposes) and businesses’ pan-European operations. Application of autonomous software agents to aid cross-border businesses operations and citizens movements is addressed. The paper presents the possibility of making citizens’ movements smoother and involving less paperwork. To support these ideas, the foundations and conclusions from Infocitizen initiative are introduced. In the conclusions of the paper, it is suggested that the agent-based technology for opening agents-ready virtual offices by agencies at all levels of government should be used. It would benefit the users if they were allowed to set up software agents to act on their behalf and to search all possible locations in order to find required resources.
Jie Lu et al (Jie Lu, 2007) paper offers a thorough introduction and systematic overview of the new field e-service intelligence mainly based on computational intelligence techniques. It covers the state- of-the-art of the research and development in various aspects including both theorems and applications of e-service intelligence. Moreover, it demonstrates how adaptations of existing computational intelligent technologies benefit from the development of e-service applications in online customer decision, personalized services, web mining, online searching/data retrieval, and various web-based support systems.
VI. SOFTWARE ARCHITECTURE
e-Governance architecture
The important aspects to be considered for the proposed framework architecture are the combination of the Apriori
algorithm used for generating association rules, C4.5
algorithm used for generating classification tree and
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
340
This kind of combination is not being attempted by any of the researchers. These algorithms working principles are sequenced so that the output of Apriori is used an input for
C4.5 and the output of C4.5 is used an input to DBSCAN. Hence, each of these functional requirements is modelled as a separate module in the system.
The usage of recommendation/recommender systems are vital in most of the e-Governance applications. The rapid advance of web and its applications has created a huge reputation for recommender systems. Being functional in various domains, recommender systems were planned to make recommendations such as items or services based on user interests. Basically, recommender systems experience many issues which replicates moderated effectiveness. Integrating authoritative data managing techniques to recommender systems can address such issues and the recommendations quality can be increased significantly.
A Student recommending system is an essential component of a successful academic involvement of any university or college. At present, most of the Universities/Colleges maintain the database of the student performance for many years and have terabytes of data. Using these information systems, the student can select the courses based on the approved curriculum. Few Universities also implemented e-Governance systems at certain level. It involves tasks where faculty members help students complete the requirements necessary to graduate. It also requires considerable planning on the part of both students and teachers.
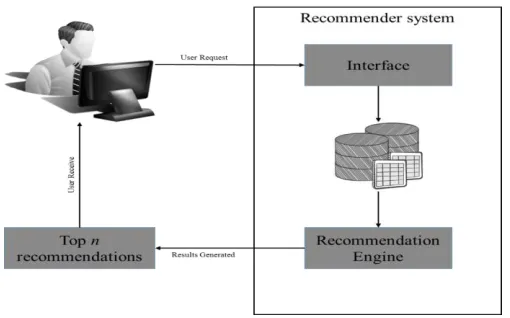
[image:4.612.322.577.137.296.2]Various universities and institutions around the world use automated advising systems. They are helpful and beneficial for both advisors and advisees in that they contribute to assisting in making better-informed decisions and improved services. Introducing technology to the advising process aims at leveraging repetitive tasks on software and dedicating time to helping a student plan his/her education road map. If the Universities/Colleges uses the historical data decision making process, it helps the student in preparing effective educational plans. This is the appropriate time for the Universities to apply data mining in their data and retrieve useful knowledge and share it with all the stake holders. Figure 6a shows the conventional work flow method in a recommender system.
Figure 1: Conventional Recommender System
In this research work, there are three distinct algorithms that can contribute to the success of the proposed framework:
Apriori algorithm C4.5 algorithm DBSCAN algorithm
The Apriori Algorithm is a significant algorithm for mining frequent itemsets for boolean association rules. In this research work it helps to find the detailed analysis of association rule mining is carried out on the student-course registration data set by considering the following parameters:
Volume of data
Maximum number of learning outcomes for a course
The C4.5 algorithm help to generate a decision tree where each node splits the classes based on the gain of information from the processed data from the Apriori algorithm. The attribute with the highest normalized information gain is used as the splitting criteria. For this the existing information system, its functionality and data structure are studied.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
341
VII. SOFTWARE AGENTS IN E-GOVERNANCE MODEL
The software agent based models are a class of computational models. They put a special emphasis on the interactions of agents to assess their effects on the system. A key notion is that simple behavioral rules on a micro-level generate complex outcomes on a macro-micro-level. A main feature of the agent-based models is the repetitive competitive interactions between the agents.
Software agents are computer programs that execute in the background and complete tasks separately. While there has been much research on this area, functioning software agents are at an early stage of development, and are only now starting to appear in real applications. A fruitful application area for software agents is in recommendation systems (e-Advising system) where agents can help students and teachers to deal with the flood of information that can be exchanged and processed (Aquibjaved Momin, 2012). The most general characterization of agents is given by the following properties:
autonomy: agents operate without the direct intervention of humans or others, and have control over their actions and internal state.
social ability: agents interact with other agents (and possibly humans) via agent-communication language. reactivity: agents perceive their environment, (which
may be the physical world, a user via a graphical user interface, a collection of other agents, the internet, or perhaps these combined), and respond to occurring changes in a timely fashion.
pro-activeness: agents do not simply act in response to their environment, they are able to exhibit goal-directed behavior by taking the initiative.
This research work is a collection of different algorithms related to recommender systems and software agents in e-advising system. This research work includes both framework development and experimental studies using the software agents. Agent based model offer three main benefits over other modelling techniques. Software agent based models.
VIII. SOFTWARE AGENTS IN E-GOVERNANCE MODEL
Based on the proposed research work architecture, it has been implemented a e-advising recommender system using .Net. This research work uses the following database where all the previous course details are stored as semantic data sources.
Dataset Used
TABLEI
STUDENTDETAILS
S.No Field Name Data Type
Size Description
1 Reg No Text Varchar 2(10)
Student Registration Number 2 Specialization Text Varchar
2(25)
Subject Specialization 3 Name Text Varchar
2(30)
Name of the Student 4 House No Number Varchar
2(5)
House Number
5 Street No Number Varchar 2(5)
Street Number
6 Way No Text Number (10)
Sub Street Number 7 Place Text Varchar
2(25)
Name of the Place
8 Wilayah Text Varchar 2(25)
Name of the Location 9 Manthaka Text Varchar
2(25)
Name of the city
10 Country Text Varchar 2(25)
Name of the Country 11 E-mail Text Varchar
2(30)
Student E-mail Address 12 Telephone Number Number
(20)
Student Phone Number
TABLEII
INTERNALANDEXTERNALASSESSMENT
S.No Field Name Data
Type
Size Description
1 Semester Text Varchar 2(15)
Name of the Semester 2 Year Number Number
(4)
Academic Year
3 Reg No Text Varchar 2(10)
Student Register Number 4 Module Code Text Varchar
2(20)
Subject Code
5 Assessment parameter
Text Varchar 2(30)
Assessment Parameter 6 Max Mark Number Number
(5)
Maximum Mark for each Subject 7 Marks Scored Number Number
(5)
Mark Secured
8 Percentage Number Number (5)
Total Percentage
9 Group Number Number (5)
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
342
TABLEIIIEXAMSUMMARY
S.No Field Name Data
Type
Size Description
1 Semester Text Varchar 2(15)
Name of the Semester
2 Year Number Number
(4)
Academic Year
3 Module Code Text Varchar 2(20)
Subject Code
4 Tutor Text Varchar
2(20)
Name of the Tutor 5 Session Text Varchar
2(2)
Exam Session
6 Avg_Internal Number Number 2(5)
Average Internal Marks 7 Avg_External Number Number
2(5)
Average External Marks 8 Avg_Total Number Number
2(5)
Average Total
9 Pass_Percentage Number Number 2(5)
Student Pass Percentage
Prototype Design
The above database is stored in MS-Access. A prototype is developed to test the framework and implement the algorithms as discussed in Chapters 3 and 4. The user interface is implemented as a web application using ASP.Net and VB.Net. This is a specific prototype for the defined problem and can be generalized with little modifications in the coding part of ASP.Net and VB.Net. The three developed algorithms namely Apriori, C4.5 and
DBSCAN is implemented in this prototype.
Detailed Results
The detailed results are presented in this session. The input database is presented in the session The results are validated with the following outputs generated from the prototype.
a. Association rule b. Classification tree c. Clusters
The following are the parameters and inputs considered to generate the detailed results.
Input Parameter Input Values
Year 2007,2008,2009,2010,2011
Semester Fall, Spring, Summer
Results of Association Rule Mining
The table IV, present the number of 3,4,5 and 6 item sets generated by the developed prototype with the minimum support of 50. 2 item sets are not considered as it will not provide much meaningful knowledge to the end user. Few cells shows empty value, as the respective item sets combinations are not available in the database for the chosen academic year and semester.
TABLEIV
NUMBEROFFREQUENTITEMSETSFORMINIMUMSUPPORT
50
Minimum Support
50
Frequent itemset 3 4 5 6
Fall 2007 64 24 11 0
2008 64 24 11 7
2009 64 24 17 7
2010 21 8 3 0
2011 68 21 0 0
Spring 2007 107 55 52 10
2008 107 60 52 4
2009 107 55 41 4
2010 150 42 50 25
2011 110 41 0 0
Summer 2007 6 21 30 4
2008 6 21 30 3
2009 6 21 30 3
2010 36 9 15 15
2011 12 17 0 0
Interpretation:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
343
The number of item sets in Spring is more in all year’s due to the maximum enrolment of the students. The end user selects the interesting 3/4/5/6 item set combinations that will serve as input to the classification rule mining techniques. Zero(‘0’) in few cases represents the non-availability of those item sets in that year/semester
The table V, present the number of 3,4,5 and 6 item sets generated by the developed prototype with the minimum support of 60. 2 item sets are not considered as it will not provide much meaningful knowledge to the end user. Few cells shows empty value, as the respective item sets combinations are not available in the database for the chosen academic year and semester
TABLEV
NUMBEROFFREQUENTITEMSETSFORMINIMUMSUPPORT
60
Minimum Support
60
Frequent itemset 3 4 5 6
Fall 2007 64 24 11 0
2008 64 24 11 7
2009 64 24 17 7
2010 21 8 3 0
2011 58 21 0 0
Spring 2007 107 55 51 10
2008 107 55 52 4
2009 102 55 41 4
2010 150 39 50 25
2011 110 41 0 0
Summer 2007 6 21 30 4
2008 6 21 30 3
2009 6 21 30 3
2010 36 9 15 15
2011 12 17 0 0
Interpretation:
The figure 6, 7, 8 and 9 represents the number of 3/4/5/6 item sets for the provided input (Academic year: 2007, 2008, 2009, 2010, 2011, Semester: Fall, Spring, Summer, Minimum Support: 60). The number of item sets in Spring is more in all year’s due to the maximum enrolment of the students. The end user selects the interesting 3/4/5/6 item set combinations that will serve as input to the classification rule mining techniques. Zero(‘0’) in few cases represents the non-availability of those item sets in that year/semester
The table VI, present the number of 3,4,5 and 6 item sets generated by the developed prototype with the minimum support of 70. 2 item sets are not considered as it will not provide much meaningful knowledge to the end user. Few cells shows empty value, as the respective item sets combinations are not available in the database for the chosen academic year and semester.
TABLEVI
NUMBEROFFREQUENTITEMSETSFORMINIMUMSUPPORT
70
Minimum Support
70
Frequent itemset 3 4 5 6
Fall 2007 0 24 11 0
2008 0 24 11 7
2009 0 24 17 7
2010 0 8 3 0
2011 0 21 0 0
Spring 2007 0 55 52 10
2008 0 55 51 4
2009 0 55 41 4
2010 0 36 50 25
2011 0 41 0 0
Summer 2007 0 21 30 4
2008 0 21 30 3
2009 0 21 30 3
2010 0 9 15 15
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
344
Interpretation:
The figure 8j, 8k and 8l represents the number of 4/5/6 item sets for the provided input (Academic year: 2007, 2008, 2009, 2010, 2011, Semester: Fall, Spring, Summer, Minimum Support: 70). The number of item sets in Spring is more in all year’s due to the maximum enrolment of the students. The end user selects the interesting 4/5/6 item set combinations that will serve as input to the classification rule mining techniques. Zero(‘0’) in few cases represents the non-availability of those item sets in that year/semester. The three itemset are not available for the minimum support 70.
The table VII, present the number of 3,4,5 and 6 item sets generated by the developed prototype with the minimum support of 80. 2 item sets are not considered as it will not provide much meaningful knowledge to the end user. Few cells shows empty value, as the respective item sets combinations are not available in the database for the chosen academic year and semester.
TABLEVII
NUMBEROFFREQUENTITEMSETSFORMINIMUMSUPPORT
80
Minimum Support
80
Frequent itemset 3 4 5 6
Fall 2007 0 0 11 0
2008 0 0 11 7
2009 0 0 17 7
2010 0 0 3 0
2011 0 0 0 0
Spring 2007 0 0 27 9
2008 0 0 52 4
2009 0 0 41 4
2010 0 0 50 25
2011 0 0 0 0
Summer 2007 0 0 30 4
2008 0 0 30 2
2009 0 0 30 3
2010 0 0 15 15
2011 0 0 0 0
Interpretation:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
345
Zero(‘0’) in few cases represents the non-availability of those item sets in that year/semester. The three and four item sets are not available for the minimum support 70.
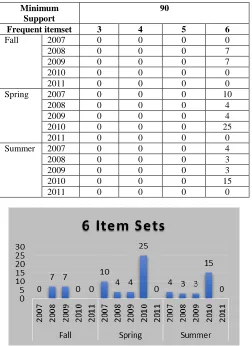
The table VIII, present the number of 3,4,5 and 6 item sets generated by the developed prototype with the minimum support of 90. 2 item sets are not considered as it will not provide much meaningful knowledge to the end user. Few cells shows empty value, as the respective item sets combinations are not available in the database for the chosen academic year and semester.
TABLEVIII
NUMBEROFFREQUENTITEMSETSFORMINIMUMSUPPORT
90
Minimum Support
90
Frequent itemset 3 4 5 6
Fall 2007 0 0 0 0
2008 0 0 0 7
2009 0 0 0 7
2010 0 0 0 0
2011 0 0 0 0
Spring 2007 0 0 0 10
2008 0 0 0 4
2009 0 0 0 4
2010 0 0 0 25
2011 0 0 0 0
Summer 2007 0 0 0 4
2008 0 0 0 3
2009 0 0 0 3
2010 0 0 0 15
2011 0 0 0 0
Figure 15: 6 Item sets for Minimum Support 90
Interpretation:
The table VIII represents the number of 6 item sets for the provided input (Academic year: 2007, 2008, 2009, 2010, 2011, Semester: Fall, Spring, Summer, Minimum Support: 90).
The number of item sets in Spring is more in all year’s due to the maximum enrolment of the students. The end user selects the interesting 6 item set combinations that will serve as input to the classification rule mining techniques.
Zero(‘0’) in few cases represents the non-availability of those item sets in that year/semester. The three, four and five item sets are not available for the minimum support 70. All these results serve as input to the classification analysis. To proceed further a sample subset is needed as the input. The subset provided in table IX is considered in this research work to move to the next phase.
TABLEIX
INPUTCONSIDEREDFORGENERATINGCLASSIFICATION
TREE
Minimum Support- 60
Semester Year 4 item set 5 itemset 6 itemset
Fall 2007 24 11 0
2008 24 11 7
2009 24 17 7
2010 8 3 0
2011 21 0 0
Minimum support 60 is considered as the all the maximal item sets are generated for this input. The three item sets are ignored as these combinations may not help the students for effective decision making in e-Advising. In e-Advising, the student needs more interesting combination to design an effective study plan.
IX. CONCLUSION AND FUTURE SCOPE
E-Governance in higher educational institution is very important in the academic system and it is the duty of the Universities/Colleges to use the appropriate technologies and providing the best available knowledge to the student community. This research work clearly shows that, the e-Governance model will surely benefit the faculty/student. The developed model provides the administration with a set of possible courses that can be offered in a semester. With this input, the management can plan for expertise and other resources needed effectively. This research will help the Universities/Colleges to improve the quality of the e-Governance models as a supplement tool in addition to their existing student information systems models.
REFERENCES
[1] Heba Mohammed Nagy, W. M. (2013). An Educational Data Mining
System for Advising Higher Education Students. International Journal of Computer, Electrical, Automation, Control and Information Engineering, 7(10).
[2] Jiawei Han, M. a. (2011). Data Mining: Concepts and Techniques.
[image:9.612.324.564.283.384.2] [image:9.612.44.296.292.638.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 7, Issue 11, November 2017)
346
[3] Jie Lu, D. R. (2007). E-Service Intelligence: An Introduction.
Springer-Verlag Berlin Heidelberg.
[4] Katia Sycara, K. D. (1996). Distributed Intelligent Agents. IEEE
Expert: Intelligent Systems and Their Applications, 11(6), 36-46.
[5] Khalifa, M. a. (2012). The Role of Semantic Expansion Network in
E-advising. International Conference on Management and Education Innovation IPEDR .
[6] Lamiaa Mostafa, N. K. (2012). The Role of Semantic Expansion
Network in E-advising. International Conference on Management and Education Innovation.
[7] Leora Waldner, D. M. (2011). E-Advising Excellence: The New
Frontier in Faculty Advising. MERLOT Journal of Online Learning and Teaching, 7(4)
[8] McGreal, F. L. (2007). e-Advisor: A Web-based Intelligent System
for Academic Advising. ABSHL in AAMAS 2007. USA.
[9] Nguyen Thanh Binh, H. T. (2008). An integrated approach for an
academic advising system in adaptive credit-based learning environment. VNU Journal of Science, Natural Sciences and Technology 24, 110-121.
[10] Otike, J. (2012 ). E – Government: Its Role, Importance and
Challenges. School of Information Sciences.
[11] Piotrowsk, Z. (2017). Perspectives for using software agents in e-Government applications. Annales UMCS Informatica.
[12] S Anuradha, Dr. E. Kirubakaran (2017), Improved e-Advisng Model
using data mining: A Software Agent Perspective, International Journal of Advanced Research in ocmputer Science and Software Engineering, Volume 7, Issue 5, May 2017, pp 871-876.
[13] S Anuradha, Dr. E. Kirubakaran (2017), Using Software Agents for
Improved e-Governanance using Data Mining, Educreator Research Journal, Volume 4, Issue 3, June-Jule 2017, pp 87-98.
[14] William Sheridan, T. B. (2010). Comparing Government Vs.