International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
249
Design of a Novel Hybrid Algorithm for Improved Speech
Recognition with Support Vector Machines Classifier
Sonia Sunny
1, David Peter S
2, K Poulose Jacob
31,3
Dept. of Computer Science, Cochin University of Science & Technology, Kochi-682022, India
2School of Engineering, Cochin University of Science & Technology, Kochi-682022, India
Abstract— Speaker independent speech recognition system has been a challenging field of research since speech is the most basic and natural means of communication. In this work, a speech recognition system is developed for recognizing isolated words in Malayalam. Here we have used two wavelet based techniques namely Discrete Wavelet Transforms (DWT) and Wavelet Packet Decomposition (WPD) for extracting features from speech. The performance of these methods is tested using Support Vector Machines (SVM) as classifier. A recognition accuracy of 85.4 % is obtained using DWT and SVM combination and 83.2% for WPD and SVM combination. A new feature extraction method is proposed which uses the combined features of both DWT and WPD called Discrete Wavelet Packet Decomposition (DWPD). The feature vectors obtained from this hybrid method is also classified using SVM which produced a better recognition accuracy of 87.8%.
Keywords—Discrete Wavelet Transforms, Soft Thresholding, Speech Recognition, Support Vector Machines, Wavelet Packet Decomposition.
I. INTRODUCTION
Automatic Speech Recognition (ASR) is basically a pattern recognition problem which also involves a number of technologies and research areas like Signal Processing, Natural Language Processing, Statistics etc [1]. A highly reliable speech recognition system is essential due to the wide application areas like mobile applications, weather forecasting, agriculture, healthcare, automatic translation, robotics, video games, transcription, audio and video database search etc [2]. Speech signals are non stationary in nature. Speech recognition is a complex task due to the differences in gender, emotional state, accent, pronunciation, articulation, nasality, pitch, volume, and speed variability in people speak [3]. Presence of background noise and other types of disturbances also affect the performance of a speech recognition system. Usually the performance of a speech recognition system is measured in terms of recognition accuracy. Recent technological advances have made much progress in the recognition of complex speech patterns.
But much more research and development is needed in this field especially in Malayalam since only few works have been reported.
In this work, a speech recognition system is designed for recognizing speaker independent isolated words in Malayalam, which is one of the four major Dravidian languages of southern India and the official language of the people of Kerala. Speaker independence is difficult to achieve because these models recognize the speech patterns of a large group of people. In isolated word recognition systems, each word is spoken with pauses before and after it. The performance of the overall speech recognition system depends on the techniques used for pre-processing, feature extraction techniques selected and the classifier used. Speech is a multi-component signal with time varying frequency and amplitude. Due to this variability, transitions may occur at different times in different frequency bands. In this work, wavelet denoising method based on soft thresholding is used for pre-processing the captured signals [4]. Two wavelet based feature extraction methods namely DWT and WPD are selected for feature extraction due to the good time and frequency resolution properties of the wavelets. The performance of both these methods in classifying the words is evaluated using SVM and a new hybrid algorithm is developed by combining the features obtained from both the methods.
The paper is organized as follows. Section 2 gives a brief description of the problem definition. The speech recognition design methodology is explained in section 3 which includes the database used, preprocessing method, various feature extraction techniques used and the classification technique used. Section 4 gives a detailed analysis of the experiments done. The performance evaluation of the results is described in section 5 and the last section gives the conclusion.
II. STATEMENT OF THE PROBLEM
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
250 Selection of the feature extraction technique plays an important role in the recognition accuracy, which is the main criterion for a good speech recognition system. Researchers have experimented with many different types of features for use in speech recognition. Most of the speech-based studies are based on Mel-Frequency Cepstral Coefficients (MFCCs), Linear predictive Coding (LPCs), and prosodic parameters. Literature on various studies reveals that in case of the above said parameters, the feature vector dimensions and computational complexity are higher to a greater extent. The computational complexity can be successfully reduced using wavelet transforms, since the size of the feature vector is very less compared to other methods. Now, more and more studies are being done on wavelets. The main objective of this work is to design a system which performs better than the existing methods. Here, the performance of two wavelet based feature extraction methods namely DWT and WPD are analysed in recognizing isolated spoken words in Malayalam. A multiclass SVM classifier is used in order to obtain the classification performance of the features. A new algorithm is developed by utilizing the features obtained from both WPD and DWT to improve the recognition rate.
III.METHODOLOGY
In this paper, the speech recognition process is divided into four phases. The first phase is the creation of the database. Next one is the preprocessing stage where the recorded speech signals are modified and tuned so that it is more suitable for the next stage which is the feature extraction stage. During this stage, the relevant features are extracted which are then given to the final phase called the classification phase. During classification stage, the words are classified into different classes. The different modules in this work are explained below.
A. Creation of the Speech Database
The first and foremost step in any speech recognition system is the creation of a good database. Since there is no standard database available in Malayalam, ten isolated words are chosen to create the database. 500 speakers of age between 6 and 70 are selected to record the words. Each speaker utters 10 words. Thus the database consists of a total of 5000 utterances of the spoken words. This gives a moderate size for our study. We have recorded the speech from 200 male speakers, 200 female speakers and 100 children for creating the database. Male, female and voice of children differ in pitch, frequency, phonetics and many other factors.
The samples stored in the database are recorded by using a high quality studio-recording microphone at a sampling rate of 8 KHz (4 KHz band limited). The spoken words, words in English, their International Phonetic Alphabet
(IPA) format and translation in English are shown in Table 1.
TABLEI
WORDS STORED IN THE DATABASE AND THEIR IPAFORMAT
Words in Malayalam
Words in English
IPA format
English translation
Onam /əunΛm/ Onam
Chiri /t∫iri/ Smile
Veedu /vi:də/ House
Kutti /kuţi/ Child
Maram /mΛrəm/
Tree
Mayil /mΛjil/ Peacock
Lokam /ləukΛm/ World
Mounam /maunəm/ Silence
Vellam /ve!!Λm/ Water
Amma /ΛmmΛ/
Mother
B. Preprocessing using Wavelet Denoising
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
251 The elements whose absolute values are lower than the threshold are first set to zero and then shrinks the nonzero coefficients towards 0. Hard and soft thresholding can be expressed as
| |
0 | |
(1)
{
X if XHard if X
X
( ) (| | | |) | |
0 | |
(2)
{
sign X X if XSoft if X
X
Where X represents the wavelet coefficients and ι is the threshold value. Here we have used soft thresholding technique. Threshold value can be obtained using different methods. In this work, we have used the universal threshold derived by Donoho and Johnstone [6] for the white Gaussian noise under a mean square error criterion which is defined as
ι = (3)
Where σ is the standard deviation and N is the length of the signal.
The algorithm used for denoising mainly consists of 3 steps.
a)Apply wavelet transform to the noisy signal to produce the noisy wavelet coefficients upto 8 levels. b)Detail wavelet coefficients are then shrinked using
soft thresholding technique by selecting an appropriate threshold limit.
c)The inverse discrete wavelet transform of the thresholded wavelet coefficients is computed which produces the denoised signal.
C. Feature Extraction
Feature extraction is the initial signal processing front end that converts speech signal into a more compact and convenient mode called feature vectors. During feature extraction, the denoised signals obtained after pre-processing are processed to extract the relevant features. The wavelet transform is a multi- resolutional, multi-scale analysis, which has been shown to be very well suited for speech processing because of its similarity to how the human ear processes sound [7]. A brief description of the three methods used namely DWT, WPD and the new proposed method DWPD are given below.
1)Discrete Wavelet Transforms: DWT is a relatively recent and computationally efficient technique for extracting information about non-stationary signals like audio.
The main advantage of the wavelet transforms is that it has a varying window size, being broad at low frequencies and narrow at high frequencies, thus leading to an optimal time–frequency resolution in all frequency ranges [8]. DWT and WPD use digital filtering techniques to obtain a time-scale representation of the signals. DWT is defined by
/2
( ,
)
( )2
j(2
j)
j k
W j K
X k
n k
(4)Where Ψ (t) is the basic analyzing function called the mother wavelet. In DWT, the original signal passes through a low-pass filter and a high-pass filter and emerges as two signals, called approximation coefficients and detail coefficients [9]. In speech signals, low frequency components h[n] are of greater importance than high frequency signals g[n] as the low frequency components characterize a signal more than its high frequency components [10]. The successive high pass and low pass filtering of the signal is given by
[ ]
[ ] [2
]
high
n
Y
k
x n g k
n
(5)[ ]
[ ] [2
]
low
n
Y
k
x n h k
n
(6)Where Yhigh (detail coefficients) and Ylow
(approximation coefficients) are the outputs of the high pass and low pass filters obtained by sub sampling by 2. The filtering is continued until the desired level is reached according to Mallat algorithm [11]. The DWT decomposition tree is given in figure 1.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
252
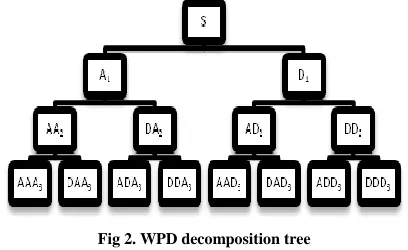
[image:4.612.339.548.131.251.2]2)Wavelet Packet Decomposition: WPD is also used in many fields since it also gives good time and frequency resolutions. It is a generalization of DWT and is a more flexible and detailed method than DWT. Here also, the signal is decomposed into low frequency components and high frequency components at each level. The difference between DWT and WPD is that the discrete wavelet transform is applied to the low pass result only whereas WPD applies the transform step to both the low pass and the high pass result. The decomposition tree for WPD is shown in figure 2.
Fig 2. WPD decomposition tree
3) Proposed Hybrid Algorithm DWPD: A wavelet transform decomposes a signal into sub-bands with low frequency components which contain the characteristics of a signal and high frequency components which are related with noise and disturbance in a signal [12]. Removing the high frequency contents retain the features of the signal and thus reduces the noise in the signal [13]. But sometimes the high frequency components may contain useful features of the signal. The main drawback of DWT is that it cannot decompose the high frequency band into more partitions. Although WPD can achieve this decomposition, it is also applied to low frequency band signals, which mainly includes the desired signals. So this causes unnecessary computational complexity. To overcome the limitations of DWT and WPD, we propose a new algorithm for speech enhancement by combining the features of both DWT and WPD. The outline of the proposed DWPD algorithm is given below.
a)The speech signal is split into two bands namely a low frequency band signal and a high frequency band signal.
b)7 scales of DWT is applied on the low frequency components and 7 scales of WPD are applied on the high frequency component.
[image:4.612.66.270.269.394.2]c)The features obtained from both decomposition are combined together to form the feature vector set.
Fig. 3 DWPD decomposition tree
The main advantage of the new hybrid algorithm is that it can not only decompose high frequency band into more partitions but also save complexities in computation.
D. Classification using SVM
Pattern recognition is becoming increasingly important in the age of automation, information handling and retrieval. During classification stage, training is done using information relating to known patterns and decisions are made based on all the similarity measures from the trained patterns. Speech recognition is basically a pattern recognition problem. SVM is a classifier which performs classification methods by constructing hyper planes in a multidimensional space that separates different class labels based on statistical learning theory [14][15]. Though SVM is inherently a binary nonlinear classifier, we can extend it to multiclass classification since ASR is a multiclass problem. There are two major strategies for multiclass classification namely against-All [14] and One-against-One or pair wise classification[16]. The conventional way is to decompose the M-class problem into a series of two-class problems and construct several binary classifiers. In this work, we have used One-against-One method in which there is one binary SVM for each pair of classes to separate members of one class from members of the other. This method allows us to train all the system, with a maximum number of different samples for each class, with a limited computer memory [17].
IV.EXPERIMENTS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
253 Among the Daubechies family of wavelets, the db4 type of mother wavelet is used for feature extraction since it gives better results [18]. The speech samples in the database are successively decomposed into approximation and detailed coefficients. Another consideration is the level up to which decomposition is to be performed. For DWT, less frequency components from level 8 is used to create the feature vectors. In WPD, both the high frequency and low frequency components are decomposed upto level 8. The number of features obtained using DWT is 12 and using WPD is 16. In the proposed DWPD, the features from both DWT and WPD are combined.
The feature vectors obtained from all the three techniques are given to SVM for classification. Since one-againt-one SVM classification is used, we construct a binary SVM for each pair of classes. The number of binary SVMs built is defined as C* (C-1)/2, where C is the number of classes. So a total of 10*(10-1)/2 = 45 binary SVMs are built. Classification task using SVM involves separating data into training and testing sets. In all the three methods, we have divided the database into three. 70% of the data for training, 15% for validation and 15% for testing. All these methods produced good recognition accuracies after classification using SVM.
V. ANALYSIS OF RESULTS
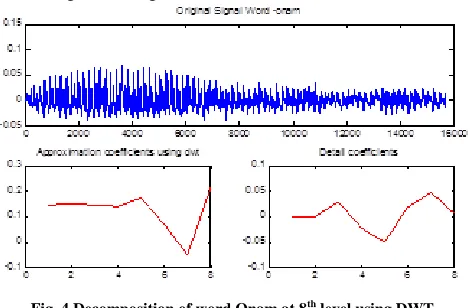
[image:5.612.322.560.115.269.2]In this work, better results are obtained at level 8 during decomposition. The original signal and the 8th level decomposition coefficients of spoken word Onam using DWT is given in figure 4.
Fig. 4 Decomposition of word Onam at 8th level using DWT
[image:5.612.52.287.484.638.2]The original signal and the 8th level decomposition coefficients of spoken word Onam using WPD is given in figure 5.
Fig 5. Decomposition of word Onam at 8th level using WPD The overall recognition accuracies obtained using DWT, WPD and DWPD are shown in table 2.
TABLE 2
COMPARISONOFRESULTS
Feature Extraction Method Recognition Accuracy (%)
DWT 85.40
WPD 83.20
DWPD 87.80
VI. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 6, June 2013)
254 By increasing the vocabulary size and by using alternate classifiers like Artificial Neural networks, Genetic algorithms, Fuzzy set approaches etc. we can have different extensions of this study.
REFERENCES
[1] B. Gold, N. Morgan. 2002 ―Speech and audio signal processing‖; New York: John Wiley and Sons.
[2] Kuldeep Kumar, R. K. Aggarwal. 2011 ―Hindi Speech Recognition System Using Htk‖; International Journal of Computing and Business Research, Vol. No. 2, Issue No. 2.
[3] .recognition.http://www.learnartificialneuralnetworks.com/speechrec ognition.html
[4] Daniel M. Rasetshwane, J. Robert Boston, Ching-Chung Li. 2006 ―Identification of Speech Transients Using Variable Frame Rate Analysis and Wavelet Packets‖; Proc.of the 28th IEEE EMBS Annual International Conference, 1727-1730.
[5] Yasser Ghanbari, Mohammad Reza Karami. 2006 ―A new Approach for Speech Enhancement based on the Adaptive Thresholding of the Wavelet Packets‖; Speech Communication, Vol. No. 48, Issue No. 8, 927–940.
[6] D.L. Donoho. 1995 ―De-noising by Soft Thresholding‖; IEEE transactions on Information Theory, Vol. No. 41, Issue No. 3, 613-627.
[7] P. P. Vaidyanathan. 1993 Multirate Systems and Filter Banks, Prentice Hall, Englewood cliffs, NJ.
[8] Elif Derya Ubeyil. 2009 ―Combined Neural Network model Employing Wavelet Coefficients for ECG Signals Classification‖; Digital Signal Processing, Vol. No. 19, Issue No. 2, 297-308.
[9] S. Chan Woo, C.Peng Lin, R. Osman. 2001 ―Development of a Speaker RecognitionSystem using Wavelets and Artificial Neural Networks‖; Proc. of Int. Symposium on Intelligent Multimedia, Video and Speech processing, 413-416.
[10] S. Kadambe, P. Srinivasan. 1994 ―Application of Adaptive Wavelets for Speech, Optical Engineering‖; Vol. No. 33, Issue No. 7, 2204-2211.
[11] S .G. Mallat. 1989 ―A Theory for Multiresolution Signal Decomposition: The Wavelet Representation‖; IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. No. 11, Issue No. 7, 674-693.
[12] B. C. Li, J. S. Luo. 2003 ―Wavelet Analysis and Its Applications‖; Electronics Engineering Press, Beijing, China.
[13] Zhen-li Wang, Jie Yang, Xiong-wei Zhang. 2006 ―Combined Discrete Wavelet Transform and Wavelet Packet Decomposition for Speech Enhancement‖; Proc. of 8th International Conference on Signal Processing, Vol. No. 2.
[14] V.N. Vapnik. 1998 Statistical Learning Theory, J. Wiley, N.Y. [15] N. Cristianini, J. Shawe-Taylor. 2000 ―An introduction to Support
Vector Machines‖; Cambridge University Press, Cambridge, U.K. [16] Ulrich H.-G. Kreßel. 1999 ―Pairwise Classification and Support
Vector Machines, Advances inKernel Methods Support Vector Machine Learning‖; Cambridge, MA, MIT press, pp. 255-268. [17] C.W. Hsu, C.J. Lin. 2002 ―A Comparison of Methods for
Multi-class Support Vector Machines‖; IEEE Transactions on Neural Networks, Vol. No. 13, Issue No. 2, 415–425.