© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1461
An Robust Outsourcing of Multi Party Dataset by Utilizing
Super-modularity and Perturbation
Priya Rajput
1, Amit Thakur
21
(M.Tech. Scholar), Swami Vivekanand College of Science and Technology
2A.Prof., Swami Vivekanand College of Science and Technology
---***---Abstract -
The period of vast database is currently a majorissue. So specialists attempt to build up an elite stage to proficiently secured these sort of information before distributing. Here proposed work has resolve this issue of computerized information security by finding the connection between the segments of the dataset which depends on the profoundly relative affiliation designs. Here when various party undergo any data sharing than utilization of super-modularity is likewise done which adjust the risk and utilization of the information. While at the same time sensitive rules are hide and then send this data to the knowledge server for gathering information for multiple parties. Examination is done on vast dataset which have all sort of property for actualizing proposed work highlights. Results are contrast on past existing strategies and it was gotten that proposed work was better on various assessment parameters.
Key Words: Association Rule Mining, Aggregation, Data
Perturbation, Encryption, Privacy Preserving Mining.
1.INTRODUCTION
Information mining procedure can help associating learning differences in human comprehension. For example, examination of any scholar dataset gives a superior scholar show yields better guideline, which prompts enhanced learning. More exact ability conclusion prompts better forecast of what an scholar knows which gives better appraisal. Better evaluation prompts more effective learning by and large. The primary goals of information mining are to have a tendency to be forecast and illustration [4, 5]. Foreseeing execution includes factors, IAT marks and task grades and so forth in the scholar database to foresee the obscure esteems. Information mining is the center procedure of learning revelation in databases. It is the way toward extricating of valuable designs from the huge database. So as to break down substantial measure of data, the region of Knowledge Discovery in Databases (KDD) gives systems by which the fascinating examples are removed. In this way, KDD uses techniques at the cross purpose of machine learning, measurements and database frameworks.
Diverse approach of digging is accomplished for various sort of information, for example, printed, picture, video, and so on. Data extraction is done in computerized for settling many issues. Yet, sometime this information contain data that is not productive for an association, nation, raise, and so on. So before extraction such sort of data is expel. By doing this security for such out of line data is finished. This is extremely
helpful for the security of information which contain some sort of medicinal data about the individual, monetary data of family or any class. As this roll out a few improvements on the dataset, so present data in the dataset get alter and make it general for all class or rework so digger not reach to concern individual.
So protection safeguarding mining comprise of many methodologies for saving the data at different level shape the person to the class of things [3, 4]. Yet, vision is to discover the data from the dataset by watching rehashed design introduce in the fields or information which can give data of the individual, at that point annoy it by various techniques, for example, concealment, affiliation rules, swapping, and so on.
2. Related Work
In [14] exhibit a hybrid discovery algorithm called HyFD, which joins quick guess methods with effective approval strategies keeping in mind the end goal to locate all negligible functional dependency in a given dataset. While working on minimal information structures, HyFD not just outperform all current methodologies, it additionally scales to considerably bigger datasets.
Li et al (2013), issue of finding the insignificant arrangement of constants for conditional functional dependency show in utilized dataset. Here negligible arrangement of conditional functional dependency is acquired by insignificant generator and additionally by closures of those sets. Here proposed work has discover the pruning criteria so general work get decrease and undesirable generator, terminations get abbreviate. So in light of the proposed work a dataset modular is create where every node go about as an information push. Pruning of node is relying upon two condition initially is node have no conditional functional dependency rules. Second is descendent node of the node have no conditional functional dependency rules.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1462 databases. The outcomes have demonstrated that the
calculation is speedier being used. It is watched that for benchmark databases the running circumstances have moved forward.
In [16] unique information is circulated among various gatherings. Here information is evenly and vertically circulate by using the arbitrary tree dissemination with homomorpic composition conveyance. So all gathering concur with outline of appropriated tree. Here issue of building time is high with increment in number of characteristics of the element. At that point information misfortune is next issue in this paper as pattern development is irregular so order precision is less.
In [8] present dithered B-tree, a B-tree record structure that can fill in as a building impede for recognizing beneficial method use in the zone of secure and private database outsourcing. The dithered tree embed calculation [8] can be additionally upgraded to bring about just a single traversal from the root to the leaf, rather than two. The file structure from learning regardless of whether the inquiry term (i.e., key) is available in the database and check the information for secure and private database outsourcing.
3. Proposed Methodology
Pre-Processing
As the dataset got from the above strides contain numerous superfluous data which one should be evacuated for making legitimate operation on those sets [1, 2, 9]. This can be comprehended as given the name a chance to be the same as it is in the first set so to put this segment in the first dataset is a bit much and it can be expelled move from the above arrangement of vectors, while if to hide salary data of the individual then one needs to roll out improvements from the first, in this manner this sort of numeric information which should be stow away is perturbed by our strategy.
Multi-quality Super-modularity
In this progression entire multi qualities are supplant by its chain of command an value in the supermodularity tree, while supplanting it is required to adjust the dataset utility and risk by rolling out required improvements. This was done in [4]. This substitution is designed to the point that utility of the information get increment while chance stay beneath under some limit esteem.
Generate Rules
With a specific end goal to conceal the data from the dataset one approach is to decrease the support and confidence of the coveted thing. For finding the thing set which is most coveted one needs to find that the incessant example in the dataset. There are many methodologies of example finding in
the dataset which are most persistent a standout amongst the most well known is aprior calculation.
Separate Sensitive Rule
Presently from the created rules one can get cluster of principles then it is required to isolate those rules from the accumulation into frequent and non-frequent lead set. Those guidelines which contain frequent things are distinguished as the frequent standards while those not containing are aberrant rules. This can be comprehended as the Let A, BC where An is set of sensitive thing then this lead to frequent administer, where B, C are non frequent things. In the event that D, B C is a rule and D is the non frequent thing set this rules is not frequent rule.
Hide Sensitive Pattern:
So with a specific end goal to conceal an example, {X, Y), it can decrease its support to be littler than client determined least confidence value (MCT) [10, 11, 12]. To decrease the support of a rule, there is an approach: Decrease the support of the thing set {X ,Y}. For this case, by just reduction the support of Y, the right hand side of the rules, it would decrease the support quicker than basically decreasing the support of {X , Y}. To decrease the confidence of a govern, there is two approach:
(1) Increase the support of X, the left hand side of the rules, yet not support of X → Y.
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1463 Fig. 1 Block diagram of proposed work at client side.
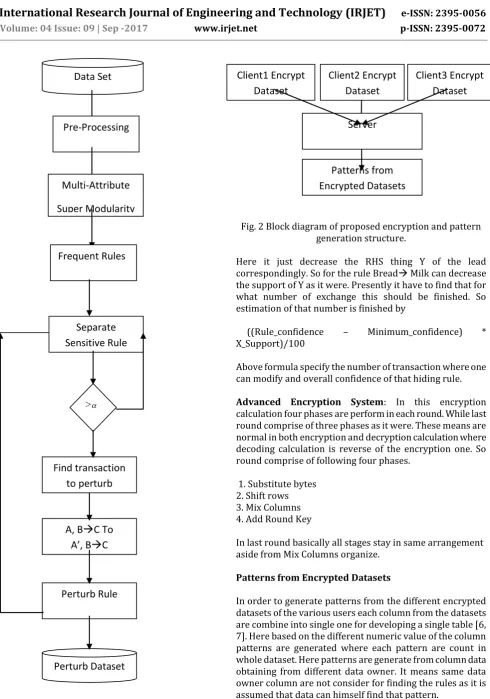
Fig. 2 Block diagram of proposed encryption and pattern generation structure.
Here it just decrease the RHS thing Y of the lead correspondingly. So for the rule Bread Milk can decrease the support of Y as it were. Presently it have to find that for what number of exchange this should be finished. So estimation of that number is finished by
((Rule_confidence – Minimum_confidence) * X_Support)/100
Above formula specify the number of transaction where one can modify and overall confidence of that hiding rule.
Advanced Encryption System: In this encryption calculation four phases are perform in each round. While last round comprise of three phases as it were. These means are normal in both encryption and decryption calculation where decoding calculation is reverse of the encryption one. So round comprise of following four phases.
1. Substitute bytes 2. Shift rows 3. Mix Columns 4. Add Round Key
In last round basically all stages stay in same arrangement aside from Mix Columns organize.
Patterns from Encrypted Datasets
In order to generate patterns from the different encrypted datasets of the various users each column from the datasets are combine into single one for developing a single table [6, 7]. Here based on the different numeric value of the column patterns are generated where each pattern are count in whole dataset. Here patterns are generate from column data obtaining from different data owner. It means same data owner column are not consider for finding the rules as it is assumed that data can himself find that pattern.
Data Set
Pre-Processing
Multi-Attribute
Super Modularity
A, B
C To
A’, B
C
Perturb Rule
Perturb Dataset
Frequent Rules
Separate
Sensitive Rule
Find transaction
to perturb
>
Patterns from
Encrypted Datasets
Client1 Encrypt
Dataset
Server
Client2 Encrypt
Dataset
[image:3.595.66.217.77.742.2]© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1464
4. Experiment and Results
This segment exhibits the trial assessment of the proposed work of perturbation and encryption procedure for protection of multiparty dataset. All calculations and utility measures were executed by utilizing the MATLAB tool. The tests were performed on a 2.27 GHz Intel Dual Core machine, furnished with 2 GB of RAM, and running under Windows 7 operating system.
Dataset:
To analyze proposed calculation, it need the dataset. One basic adult dataset is utilize that has total fourteen attributes. Here individual data are present like gender, education, marital status,, salary, etc.. Whole dataset consist of 32561 sessions. In this work, an arrangement of calculations and systems were proposed to take care of security safeguarding information mining issues. The analyses demonstrated that the proposed calculations perform well on huge databases. It work better as the Maximum lost example rate was reduced a specific estimation of support. It is appeared in the outcomes that precision of the perturbed dataset is protected for low support esteems also. Here Proposed work has resolve the multi party information appropriation issue and also extraordinary level trust party get diverse level of bothered dataset duplicate.
Results
Table 3. Comparison of Risk value.
Dataset Size Proposed Work Previous Work
400 6800 7203
1200 20400 21469
5000 85000 88879
[image:4.595.303.567.121.198.2]From above table 3 risk value of the proposed work is comparatively less as by the use of super modularity technique information sharing is done under less risk.
Table 4. Comparison of Utility value.
Dataset Size Proposed Work Previous Work
400 205.5197 117.9165
1200 631.9918 347.7699
5000 2.7110e+03 1.4598e+03
From above table 4 utility value of the proposed work is comparatively less as by the use of super modularity technique information sharing is done under less risk.
Table 5. Comparison of rule count.
Dataset Size Proposed Work Previous Work
400 14 94
1200 16 120
5000 16 126
From above table 5 it is obtained that proposed work have less number of rules as compare to the previous work. As high sensitive rules are perturb below some threshold confidence.
Table 6 Comparison of Space Cost for data.
Dataset Size Proposed Work Previous Work
400 400 452
1200 1200 1356
5000 5000 5650
From above table 6 it is obtained that proposed work have less space cost as compare to the previous work. As high sensitive rules are perturb below some threshold confidence so no need to increase the number of fake transaction for increasing the confusion in dataset.
5. Conclusions
In this work, a set of algorithms and techniques were proposed to solve privacy-preserving data mining problems. The experiments showed that the proposed algorithms perform well on large databases. It work better as the Maximum lost pattern percentage is zero a certain value of support. Then this work shows that false patterns value is zero. Comparison with the other algorithm it is obtained that including the differential privacy and then directly hide the sensitive information. It is shown in the results that accuracy of the perturbed dataset is preserved for low support values as well. Here Proposed work has resolve the multi party data distribution problem as well as different level trust party get different level of perturbed dataset copy.
REFERENCES
[1] Abedjan, Z., Grütze, T., Jentzsch, A., Naumann, F.: Mining and profiling RDF data with ProLOD++. In: Proceedings of the International Conference on Data Engineering (ICDE), pp. 1198–1201(2014).
© 2017, IRJET | Impact Factor value: 5.181 | ISO 9001:2008 Certified Journal | Page 1465 [3] Thorsten Papenbrock, Jens Ehrlich, Jannik Marten,
Tommy Neubert, Jan-Peer Rudolph, Martin Schonberg, Jakob Zwiener and Felix Naumann, “Functional Dependency Discovery: An Experimental Evaluation of Seven Algorithms”, Proceedings of VLDB 2015.
[4] Mohamed R. Fouad, Khaled Elbassioni, Member, IEEE, and Elisa Bertino . “A Supermodularity-Based Differential Privacy Preserving Algorithm for Data Anonymization”. IEEE
TRANSACTIONS ON KNOWLEDGE AND DATA
ENGINEERING, VOL. 26, NO. 7, JULY 2014.
[5] Huhtala, Y., Karkkainen, J., Porkka, P., and Toivonen, Dependencies Using Partitions, IEEE ICDE 1998.
[6] Shyue-liang Wang, Jenn-Shing Tsai and Been-Chian Chien, “Mining Approximate Dependencies Using Partitions on Similarity-relation-based Fuzzy Databases”, IEEE International Conference on Systems, Man and Cybernetics(SMC) 1999.
[7] Yao, H., Hamilton, H., and Butz, C., FD_Mine: Discovering Functional dependencies in a Database Using Equivalences, Canada, IEEE ICDM 2002.
[8] Wyss. C., Giannella, C., and Robertson, E. (2001), FastFDs: A Heuristic-Driven, Depth-First Algorithm for Mining Functional Dependencies from Relation Instances, Springer Berlin Heidelberg 2001.
[9] Russell, Stuart J. and Norvig, Peter. Arti cial Intelligence: A ModernApproach. Prentice Hall, 1995.
[10] Mannila, H. (2000), Theoretical Frameworks for Data Mining, ACM SIGKDD Explorations, V.1, No.2, pp.30-32.
[11] Stephane Lopes, Jean-Marc Petit, and Lotfi Lakhal, “Efficient Discovery of Functional Dependencies and Armstrong Relations”, Springer 2000.
[12] Heikki Mannila and Kari-Jouko R¨aih¨a. Design by example: An application of Armstrong relations. Journal of Computer and System Sciences, 33(2):126{141, 1986.
[13] Lichun Li, Rongxing Lu, Kim-Kwang Raymond Choo, Anwitaman Datta, and Jun Shao .“Privacy-Preserving-Outsourced Association Rule Mining on Vertically Partitioned Databases”. IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY, VOL. 11, NO. 8, AUGUST 2016 1847
[14]. Thorsten Papenbrock, Felix Naumann .” A Hybrid Approach to Functional Dependency Discovery”. SIGMOD’16, June 26-July 01, 2016, San Francisco, CA, USA c 2016 ACM. ISBN 978-1-4503-3531-7/16/06. .
[15]. Akshay Kulkarni, Sachin Batule, Manoj Kumar Lanke, Adityakumar Gupta. “Functional Dependencies Discovery in RDBMS”. International Journal of Advanced Research in Computer Science and Software Engineering Volume 6, Issue 4, April 2016 ISSN: 2277 128X.