Natural Language Processing on Big Data
Full text
Figure
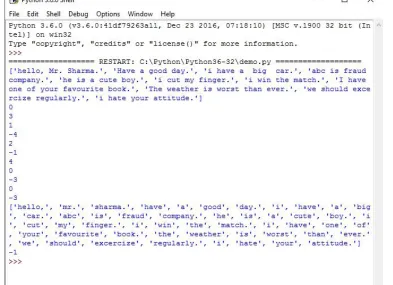
Related documents
Combining the results of the event study and the econometric estimations suggest that both lira purchases and lira sales were successful, to some extent, in changing the trend
For the proposed approach, the conduction of MPA using Pajek is identical to the traditional approach, except that each arc is assigned an initial weight equal
A ‘Call to Action’ invites customers to opt-in (join) to a text message marketing campaign or alert service by texting a specific Keyword to a Short Code.. This can be done via
We extend the user-to-user setting to consider a group of users that consists of a sender (e.g., the group administrator) and multiple receivers (e.g., all other group members):
I have presented a model in which money is used in equilibrium even though a real asset which displays a higher rate of return across periods is available and neither restrictions
Recurring EBITDA: EBITDA before non-recurring (exceptional) items. *Deconsolidation of CMore in November 2008. Diversification figures for 2008 excl.. Figures 2009 preliminary
Hertel and Martin (2008), provide a simplified interpretation of the technical modalities. The model here follows those authors in modeling SSM. To briefly outline, if a
The previous discussion has summarized various selected normative issues concerning the model curricula, including prospective IS job positions and IS teaching contents. As
