2017 International Conference on Computer, Electronics and Communication Engineering (CECE 2017) ISBN: 978-1-60595-476-9
Performance Optimization of Self-represented Systems
Supporting Run-time Meta-modeling
Jin-song LUO, Zai-lin GUAN, Yan-yan CUI
and Lei YUE*
State Key Lab of Digital Manufacturing Technology & Equipment; School of Mechanical Science &
Engineering, Huazhong University of Science and Technology, 1037 Luoyu Road, Wuhan 430074, Hubei, China
*Corresponding author
Keywords: Run-time meta-modeling, Run-time models, Multilevel caching, Run-time adaptability.
Abstract. Fully self-representing architecture, which supports parallel evolution of meta-models and models when the system running, was proposed by integrating runtime meta-modeling and run-time modeling approaches in current research. Secondly, we focused on the study of the unified structure method, which was put forward to represent in-memory objects at different levels of abstraction and can significantly simplify caching mechanism. After that, a 3-level caching system based on web application was proposed in current research as well. In the end, the availability of the proposed approach was verified from aspects of performance analysis and practical application.
Introduction
(Self-)Adaptive systems are required to adapt dynamically at runtime. They are often used in the situations where uncertain events may happen at design time. Most of the application codes generated based on the design-time models are not significant to provide the required flexibility, because the design rationale used in the models are not available at runtime. Therefore, to address this issue the use of run-time models (or [email protected] [1]) has been proposed by shifting the models from design time to runtime, but Most of their modeling capabilities are fixed and cannot be modified at run-time. The concepts of modeling are closely related with the domains and the domain requirements in the future are often uncertain and unpredicted. The hard-coded modeling capabilities can limit the run-time adaptability of the systems. Therefore, a run-time meta-modeling environment is desired to be integrated into the system and current research provides run-time adaptability at a higher level of abstraction, supporting co-evolution of run-time metamodels (or modeling languages) and run-time models.
Limited number of run-time model based systems can modify modeling capabilities when the system is running. Adrian Kuhn et al developed a framework of Fame [2] , put forward the concept of meta-modeling at run-time. The Fame implemented a lightweight core, using a unified structure to represent in-memory objects and provided a unified APIs to access objects. Magritte [3] also proposed run-time meta-modeling, allows end users to build their own meta-models on the fly. MOOSE [4] present how the meta-model infrastructure is used in the particular context of reengineering environment. First of all, these frameworks are tightly embedded Smalltalk environment, and Smalltalk is not widely used. Some of them proposed the performance degradation, but none of them provide solutions to performance problems.
Run-time meta-modeling environment not only can help to modify the existing modeling languages but it is also significant to create new domain-specific modeling languages (DSMLs) by defining the concepts of modeling languages, the attributes of concepts, the relationship between concepts and the behavior of constraints and execution engines.
objects at M0 layer. With the tower of run-time models, the system is full self-represented. In the model tower, only the domain-independent M3 layer is predefined.
The entire system is dynamically executed by reflecting multilevel meta-information. The reflection often crosses multiple layers from M1 to M3, which leads to frequent database accesses and severe performance degradation. This research is focus to unify the representation of objects at different levels of abstraction, in addition to optimize the performance of fully self-represented systems, especially web-based applications by providing a multi-level caching system.
Unifying the Representation and Management of Objects at Different Levels of Abstraction In the current research, the representation and management of objects at different level of abstraction is presented. The object-oriented language provides class and object as the two levels of abstraction corresponding to the development time and run-time, or the meta-level and instance-level. In multi-level architecture of abstraction, meta-level and instance-level are relative concepts. An object is at the meta-level relative to the lower level of abstraction and it is at the instance-level relative to the higher level of abstraction.
It is significant to provide a unified structure for in-memory objects at different levels of abstraction. The unified object structure can not only simplify the representation and manipulation mechanism of objects, but it can also simplify the persistence, caching, access control, version control mechanism, etc. Furthermore, it helps to make the design and implementation more simple and elegant. The unified memory structure is obviously more conducive to the implementation of object caching and is therefore used in the current research.
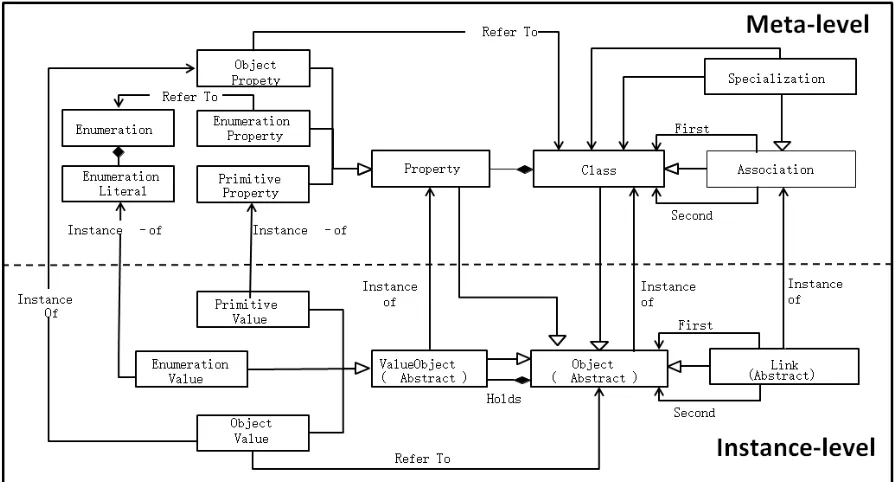
[image:2.612.82.529.420.661.2]Unified structure for representing the in-memory objects at four-layer tower from M0 to M3 is illustrated in Figure 1. In meta-level, Classes can be used to describe their instances. A Class can define multiple Properties. An Association is a relationship between classes which is used to show that instances of classes could be either linked to each other. A Specialization is a taxonomic relationship between a more general class and a more specific class.
Figure 1. Unified structure for representing the in-memory objects.
describes its structure and behavior. The objects at top-most layer describe the structure and behavior of their own. As a result, any object has a class describing it.
Object Container is a kernel component which is obtained from Registry [6] pattern, and can provide a shared container for holding in-memory objects at different levels of abstraction. Each object is automatically assigned an ID (GUID) when it is created, and is automatically registered in Object Container to allow the search of existing objects through the ID. If an object already exists in the Object Container, before it is eliminated, the object can be accessed directly without accessing database.
When creating a Class, the system can automatically register the class as an object to Object Container. The system can save the definition information of that class to database while saving the newly created class. At the same time, the system can automatically create a Table for the Class in the database, and create the corresponding Column for each Property. Furthermore, the instances of that class can be saved to the table. The mapping between in-memory objects and database is achieved by using a metadata driven object-relational mapping engine.
When modeling at run-time, classes are created to capture the concepts of domains and the corresponding tables are created to store domains data. When meta-modeling at run-time is performing, the classes are created to capture the concepts of DSMLs and the corresponding tables are created to store run-time models.
Objects at different layer have a unified memory structure representation, which provides a significant basis for multi-level object caching system. Object Container manages in-memory objects on the server, including registration, retrieval, removal, etc.; in fact, the Object Container provides an implementation of a memory object cache system.
Object, as the root class of all classes can provide a set of generic API, including creation, deletion, modification, loading, and Saving. These APIs encapsulate the underlying complexity, including caching mechanism, persistence mechanism, access control mechanism, and so on. When accessing an object presumed to exist in the backing database, it first checks the cache. If the object can be found, the object in the cache is used instead of accessing backing database. On the other hand, when the cache is consulted and do not have the object, the previously uncached object fetched from the backing database during miss handling is usually copied into the cache, ready for the next access. These technical details are transparent to developers. In the next section, on multi-level caching systems and performance tuning is presented.
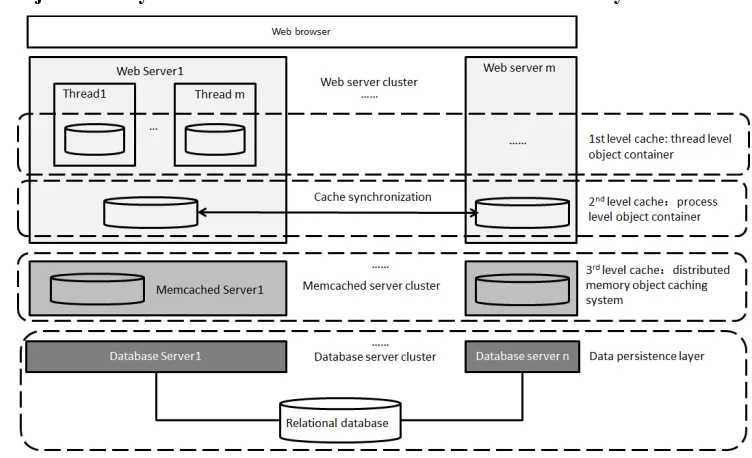
[image:3.612.114.490.497.726.2]Caches Objects at Any Levels of Abstraction with a Multilevel Cache System
The proposed multi-level cache system architecture is presented in Figure 2. It can be seen from Figure 2, that the current research provides three-level cache mechanism. The 1st level cache is thread-level; the 2nd level cache is Process-level; the 3rd level cache is distributed memory system (our research based on Memcached implementation).
The 1st level cache is used to cache the objects accessed in an HTTP request and to isolate uncommitted temporary objects in different threads in a concurrent environment. The cache is closest to the business logic. Web-based applications work on request / response mechanism. For each request from browser, the server processes the request by temporarily assigning a thread and create a temporarily Object Container for caching all the objects that the thread uses, and when it is finished, submits the data and destroys the temporary object container and returns a Response to the browser.
The 2nd level cache is the process level cache. When an application process starts at the beginning, the system automatically creates a process level Object Container which caches only metadata from M1 to M3. In a clustered environment, when a process-level object has been changed on a server, all the copies of the object in process-level Object Containers on other servers can be updated synchronously to ensure cache data consistency.
The 3rd Distributed Memory Object Cache uses a distributed memory object caching system (we use Memcached [7] in F++Builder). The cache provides faster access speed than the database, and greater capacity and scalability than the 1st and 2nd level cache. The objects are serialized at first, and then are cached in memory of one or more cache servers of a cluster. When demanded, objects can be located and read from the cluster and then they are de-serialized back.
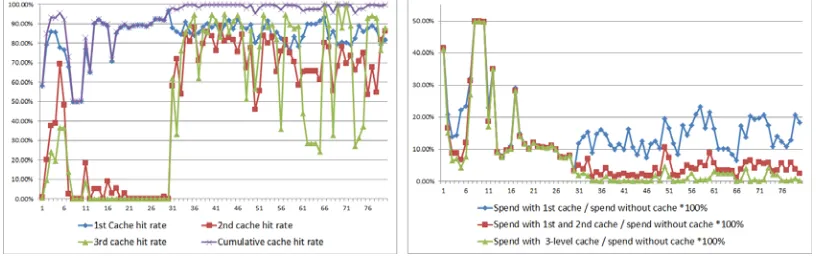
[image:4.612.102.512.438.566.2]Based on the above architecture, a tool called F++ Builder is developed in the current research, and a Lenovo ThinkPad T440 notebook computer to build a test environment. From the start of the system, every 1000 visits to take a point, a total of 80 sets of statistical data, statistics the cache hit rate of 1st cache, 2nd cache, 3rd cache and cumulative hit rate, as shown in Figure 3. The average time of accessing server memory, Memcached distributed memory database and Oracle database is 0.0011ms, 0.330ms and 15.526ms respectively. When the 1st level cache, 2nd level cache and 3rd level cache are added successively, Figure 4 displays the Cache optimization time analysis. The vertical axis is "spend with cache / spend without cache *100%".
Figure 3. Cache hit ratio analysis. Figure 4. Cache optimization time analysis.
It can be seen from Figure 3, that 1st level cache hits very high, averaging 84%, because the execution of the application presents a high degree of temporal and spatial locality. The 2nd level cache system does not hit well at the initial stage of system startup, because the meta-objects in 2nd level cache are loaded on demand, as time goes on, hit rates can rise gradually. The volatility of the 3rd level cache is relatively large, because most metadata has been hit in caches of the previous two levels, and business objects at M0 layer are more dispersed.
16.01%, 8.97%, 6.98% of the total execution time without the 3-level cache system. If removing the unstable part of the initial start of the system, the three-level cache system optimizes the run-time to 1.08% of the total time.
The average response time of the system is less than 10% with respect to the hard coded system, which shows significant results, reaching a practical level. Fully self-represented systems with run-time meta-modeling capability require additional supports, such as user interface modeling, behavioral modeling, access control, versioning, and so on. We have carried out research and application in these areas. Because of the limitation of space, we do not introduce it here.
The proposed F++ Builder has been successfully applied to the development of a manufacturing execution system, F++ MES. F++ MES now has been applied in more than 30 factories and verified the availability of this multi-level cache system supporting run-time metamodeling and modeling. At present, more than 80% of the F++ MES customers are TOP 500 manufacturers in China in industries such as electric power equipment (Dongfang Electric Group Corporation, State Grid NARI Group Corporation, China XD Group Corporation, etc.), aerospace & defense (e.g., China Electronics Technology Group Corporation, China Aviation Industry Corporation, China North Industries Group Corporation), railway rolling stock (e.g., China Railway Rolling Stock Corporation), communication equipment (e.g., FiberHome Technologies Group).
Summary
The use of run-time models has been proposed by shifting the models from design time to runtime, but Most of their modeling capabilities are fixed and cannot be modified at run-time. The hard-coded modeling capabilities can limit the run-time adaptability of the systems. By integrating meta-modeling approach, we proposed a four-layer tower of run-time models supporting the full representation of systems. The entire system is dynamically executed by reflecting multilevel meta-information, but it leads to frequent database accesses and severe performance degradation.
This research proposed a unify representation of in-memory objects at different levels of abstraction, in addition to optimize the performance of fully self-represented systems, especially web-based applications by providing a multi-level caching system. The average response time of the system is less than 10% with respect to the hard coded system, which shows significant results, reaching a practical level. Performance analysis shows that our approach can significantly improve hit rate and reduce the number of database access. In addition, the widespread use of F++ MES also demonstrates the availability of our approach.
Acknowledgement
This work was supported by China technological innovation fund for technology-based small and medium-sized enterprise (No. 14C26214202387).
References
[1] G. Blair, N. Bencomo, R.B. France, Models@ run.time, Computer, 42 (2009) 22-27.
[2] M.B. Stegmann, B.K. Ersbøll, R. Larsen, FAME - A Flexible Appearance Modelling Environment, IEEE Transactions on Medical Imaging, 22 (2003) 1319-1331.
[3] L. Renggli, S. Ducasse, A. Kuhn, Magritte – A Meta-driven Approach to Empower Developers and End Users, (Springer Berlin Heidelberg, 2007).
[4] S. Ducasse, T. Girba, A. Kuhn, L. Renggli, Meta-environment and executable meta-language using smalltalk: an experience report, Software and Systems Modeling, 8 (2008) 5-19.
[5] D. Riehle, M. Tilman, R. Johnson, Dynamic object model, Pattern Languages of Program Design, 5 (2000) 3-24.
[6] M. Fowler, Patterns of enterprise application architecture, (Addison-Wesley Longman Publishing Co., Inc., 2002).