A security analysis of automated Chinese turing tests
Full text
Figure

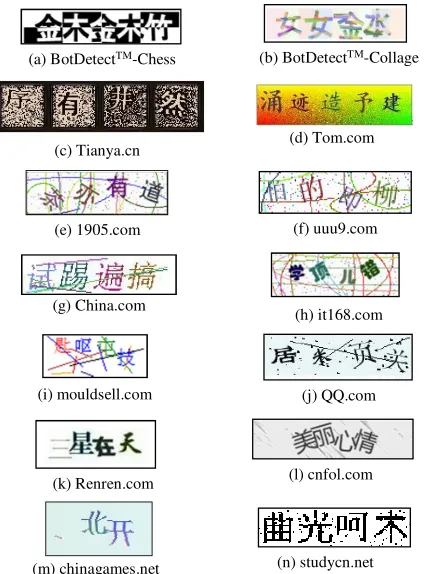
![Figure 7: Examples of the Chinese Touclick CAPTCHA.(a)taken from [41]; (b) from Touclick website [15]](https://thumb-us.123doks.com/thumbv2/123dok_us/9410374.442253/5.612.367.508.542.640/figure-examples-chinese-touclick-captcha-taken-touclick-website.webp)



Related documents
C., “Identification of Tire Leachate Toxicants and a Risk Assessment of Water Quality Effects Using Tire Reefs in Canals”, Bulletin of environmental contamination and toxicology,.
This work attempts to build an analogy between the human immune system (HIS) and intrusion detection system (IDS) methods for wireless sensor networks. This is
The Campus Activities Program (CAP) must identify relevant and desirable student learning and development outcomes and provide programs and services that encourage the achievement
4 SIMULATION METHODOLOGY 15 • An eligibility dummy for attainment of a minimum of 15 years of contributions; three industry- specific variables: the fraction of collective
The data types that can be viewed and analyzed are: (1) data stored using different data models: vector or raster; (2) data in different file formats: feature classes, shape
AACR2: s (for single publication and/or copyright date) RDA:. s (for ascertained or inferred publication date without citing copyright date) t (for publication and
But we need to understand that Jesus did not mean that Peter as an INDIVIDUAL had the authority to decide who will and who will not enter the Kingdom of Heaven!.
Building customer database for mobile customer relationship management purposes (together with Jaakko Sinisalo, Jari Salo, Matti Leppäniemi and Xiande Zhao)..
