FACTOR – 5.088
IMPACT ON THE PERFORMANCE OF DRAM: SPECIAL REFERENCE TO DRAM ERRORS
P. Lachi Reddy1, Dr.Phool Singh Chouhan2, Dr.Senthilkumar A3 Department of Electronics and Communication Engineering
1,2,3
OPJS University, Churu (Rajasthan)
Abstract
Performance of modern Computer systems has progressions in silicon process technology. Dynamic
Random Access Memory (DRAM) has been initially made to go about as a quick middle-manto
moderate stockpiling gadgets. Once the little segment of information really being utilized was
offloaded into memory, it could work with the microchip much speedier and about dispose of deferrals.
The progressions in silicon process technology have empowered quantity of transistors on a signal chip
to generally twofold at regular intervals as recommended by Moore's Law. As a result to Moore's Law,
processor performance has likewise multiplied generally at regular intervals in a similar day and age
because of a blend of the bigger transistor spending plan and the expanded exchanging velocity of
those transistors.
Keywords:Modern DRAM, memory,DIMM, reliability, data corruption, soft error, hard error,
large-scale systems.
INTRODUCTION
Currently, DRAM devices are made on DRAM-advanced process advances though rationale gadgets are normally made on rationale improved process advances. Measure upgraded handle innovations can be utilized to manufacture rationale circuits, and rationale streamlined process advances can likewise be utilized to create DRAM circuits. Be that as it may, DRAM improved process innovations have wandered significantly from rationale streamlined process advances as of late.
FACTOR – 5.088 nature of processors and the immaculate
product financial aspects of DRAM gadgets, the difference illustrates the level of value rivalry on the offer of item DRAM gadgets. The outcome is that DRAM makers are uniquely
cantered around the minimal effort part of DRAM gadgets. Any proposition to include extra functionalities should then be weighed against the expansion in bite the dust cost and conceivable increments in selling price [1].
BACKGROUND AND METHODOLOGY
Memory errors and their handling
Mostly the memory structures being utilized as a part of the servers by modification of the codes. The ordinary arrangement is for a memory get the opportunity to word to be extended with additional bits to contain the oversight code. Ordinary bumble codes in thing server systems today fall in the single mistake right twofold error distinguish (SECDED) class. That implies they can dependably recognize and revise any single-piece error, yet they can just identify and not right various piece errors. All the more capable codes can amend and distinguish more error bits in a solitary memory word. For instance, a code family known as chip-execute [2], can remedy up to 4 contiguous bits on the double, consequently having the capacity to work around a totally broken 4-bit wide DRAM chip. We utilize the terms correctable mistake (CE) and uncorrectable error (UE) in this paper to generalize away the points of interest of the real error codes utilized.
On the off chance that done well, the
treatment of correctable memory errors is to a great extent undetectable to application programming. Adjustment of the error and logging of the occasion can be performed in equipment for a negligible execution affect. In any case, contingent upon the amount of the error taking care of is pushed into programming; the effect can be more serious, with high mistake rates creating a huge corruption of general framework execution.
Uncorrectable mistakes ordinarily prompt to a cataclysmic fall filature or something to that affect. Either there is an express disappointment activity in light of the memory error, (for example, a machine reboot), or there is danger of an information debasement initiated disappointment, for example, a bit freeze. In the frameworks we examine, all uncorrectable errors are viewed as sufficiently genuine to close down the machine and supplant the DIMM to blame.
FACTOR – 5.088 repeatable.
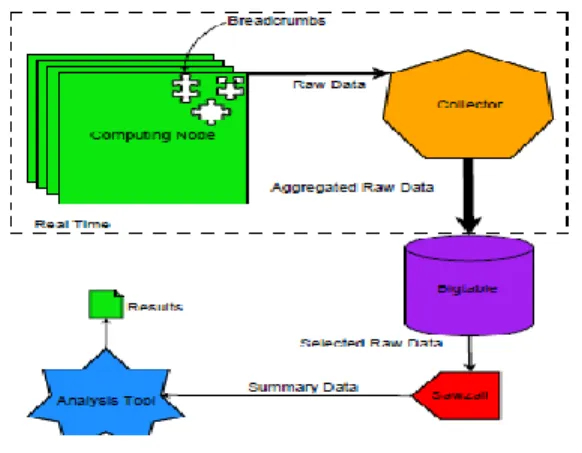
Figure 1: Collection, storage, and analysis architecture.
On account of a physical deformity (e.g. "stuck bits"). Our estimation foundation catches both hard and delicate errors, however does not permit us to dependably recognize these sorts of mistakes. Every one of our numbers incorporates both hard and delicate mistakes. Single-piece delicate errors in the memory cluster can aggregate after some time and transform into multi-bit mistakes. Keeping in mind the end goal to stay away from this aggregation of single-piece errors, memory frameworks can utilize an equipment scrubber [3] that sweeps through the memory; while the memory is generally sit out of gear. Any memory words with single-piece errors are composed back after redress, along these lines taking out the single-piece mistake in the event that it was delicate. Three of the six equipment stages (Platforms C, D and F) we consider make utilization of memory
scrubbers. The normal cleaning rate in those frameworks is 1GB at regular intervals. In the other three equipment stages (Platforms A, B, and E) errors are just recognized on get to.
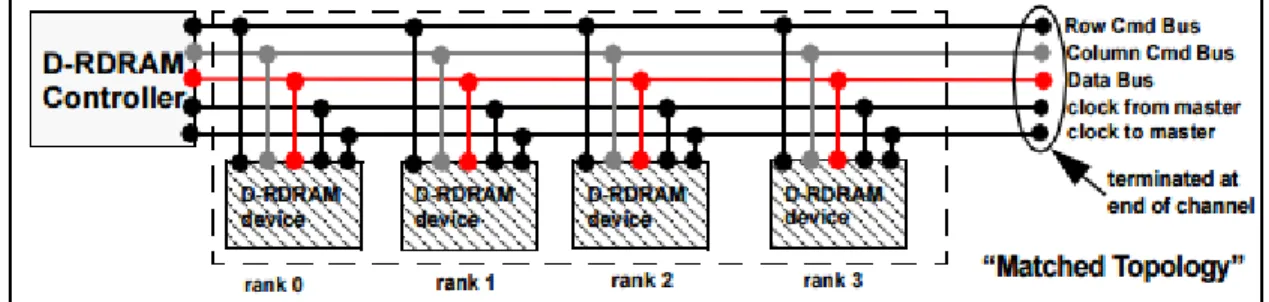
Direct-RDRAM System Topology
FACTOR – 5.088 arranged into the get to tradition and provided
for structure level synchronization. Along these lines [6], despite when pushed to essentially indistinguishable data rates, multi-rank DRAM
memory structures with customary system topologies are less viable to the extent data transported per cycle per stick [7].
Figure 2: topology of a generic direct RDRAM memory system BASELINE STATISTICS
Table 1:Memory errors per year:
Machine we start by taking a gander at the recurrence of memory errors per machine. We then concentrate on the recurrence of memory errors for individual DIMMs [8].
Errors per machine
FACTOR – 5.088 memory confuse for consistently [9] and the
typical number of correctable errors consistently is more than 22,000. These numbers vary across over stages, with a couple stages (e.g. Arrange A and B) seeing about portion of their machines cautioned by correctable goofs, while in others only 12–27% are alarmed. The center number of bungles each year for those machines that inclusion
with least one slip-up reaches from 25 to 611.
Unusually, for those phases with a lower rate of machines alarmed by correctable oversights, the ordinary number of correctable bungles per machine each year is the same or extensively higher than for substitute stages. We will examine the reverence's among stages
and technologies[10].
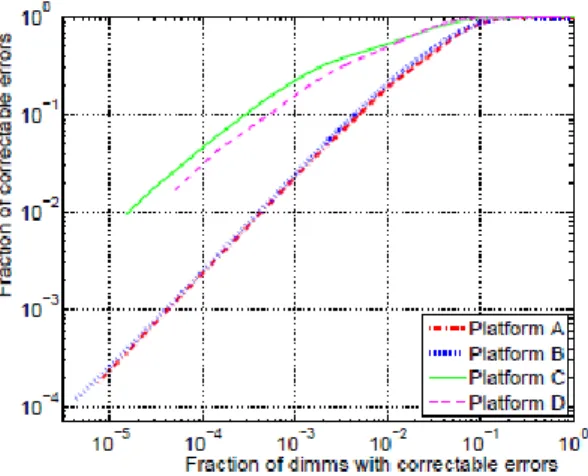
Figure 2 The distribution of correctable errors over DIMMsThe graph plots the fraction Y of all errors in aplatform that is made up by the fraction X of DIMMs with the largest number of errors.
While correctable botches regularly don't prompt influence a machine, uncorrectable missteps when in doubt result in a machine shutdown. Table 1 gives the idea that while uncorrectable bungles are less typical than correctable errors; they do happen at a basic rate. Over the entire task force, 1.3% of machines are frightened by uncorrectable goofs each year, with a couple stages seeing upwards of 2-4% alerted[11].
Errors per DIMM
FACTOR – 5.088 size, the principle gathering has a much higher
segment of DIMMs alarmed by correctable slip-ups [13], and the second assembling has a much higher division of DIMMs cautioned by uncorrectable errors.
We inspected different external factors that may illuminate the disparity in memory rates transversely over stages, including temperature, utilize, DIMM age and cutoff. While we will see that all these choose the repeat of bungles, they are insufficient to clear up the divergences between stages [14]. While we can't make certain about the explanation
behind the dissimilarity between stages, we estimate that the watched uniqueness in correctable oversights is for the most part due to board and DIMM plot disparity. We hypothesize that the dissimilarity in uncorrectable botches is relied upon to disparity in the mix-up review codes being utilized. In particular, Platforms C and D are the fundamental stages that don't use a sort of chip-butcher [15]. Chip-butcher is an all the more extreme code that can correct certain sorts of various piece botches, while the codes in Platforms C and D can perfectly single-piece bungles.
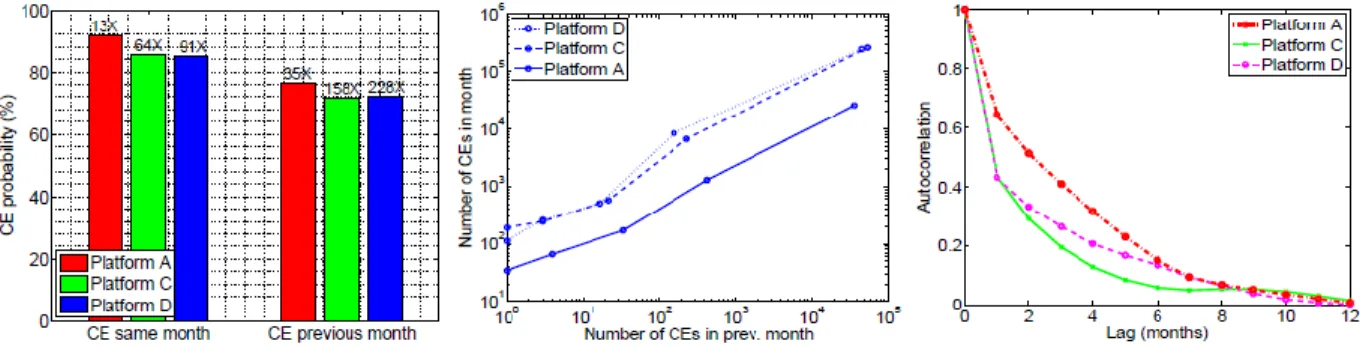
Figure 3: Correlations between correctable errors in the same DIMM: The left graph shows the probability of seeinga CE in a given month, depending on whether there were other CEs observed in the same month and the previous month
The numbers on top of every bar demonstrate the calculate increment likelihood contrasted with the CE likelihood in an arbitrary month (three remaining most bars) and contrasted with the CE likelihood when there was no CE in the earlier month (three right-generally bars). The center chart demonstrates the normal number of CEs in a month as a component of
FACTOR – 5.088 on just those DIMMs that have ex-congruity
mistakes; the inconstancy is still high (not appeared in table). The C.V. values extend from 3–7 and there are huge difference between the mean and the middle number of correctable mistakes: the mean reaches from 20,000 − 140,000, while the middle numbers
are between 42 − 167. To a first request, the above outcomes outline that errors in DRAM are a substantial worry practically speaking. This rouses us to further review the factual properties of mistakes [17] and how errors are by different variables, for example, ecological conditions.
SUMMARY AND DISCUSSION
This paper thought the event and characteristics of DRAM mix-ups in a broad naval force of item servers. Our survey relies on upon data accumulated more than 2 years and spreads DIMMs of various dealers, periods, advancements, and breaking points. All DIMMs were furnished with mix-up changing method of reasoning (ECC) to reconsider in any occasion single piece errors.
Our audit joins both correctable errors (CE) and un-correctable errors (UE). Correctable oversights can be dealt with by the ECC and are, all things considered, clear to the application. Uncorrectable slip-ups have more extraordinary results, and in our structures incite to a machine shut down and substitution of the cautioned DIMM. The screw up rates we report consolidate both fragile slip-ups, which are heedlessly, destroyed bits that can be altered without leaving unending mischief, and hard errors, which are a direct result of a physical flaw and are invariable. Underneath we rapidly pack our results and discuss their suggestions.
CONCLUSION
FACTOR – 5.088 association up to 7 months. We also watch
strong associations betweenthe correctable errors and uncorrectable errors. In 70-80% of the cases an uncorrectable screw up is gone before by a correctable error around a similar time or the prior month, and the closeness of a correctable misstep extends the probability of an uncorrectable bungle by factors between 9– 400. Still, the through and through probabilities of viewing an uncorrectable goof taking after a correctable error are for the most part little, between 0.1–2.3% consistently, so supplanting a DIMM only in light of the proximity of correctable slip-ups would appeal just in circumstances where the cost of downtime is adequately high to surpass the cost of the ordinary high rate of false positives. The recurrence of CEs augmentations with age, while the event of UEs decreases with age (due to re-positions).
REFERENCES
1. Z. Al-Ars, A. J. van de Goor, J. Braun, and D. Richter. Simulation based analysis of temperature effect on the faulty behavior of embedded drams. In ITC’01: Proc. of the 2001 IEEE International Test Conference, 2001. R. Baumann. Soft errors in advanced computer systems. IEEE Design and Test of Computers, pages 258–266, 2005.
2. F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A distributed storage system for structured data. In Proc. of OSDI’06, 2006.
3. C. Chen and M. Hsiao. Error-correcting codes for semiconductor memory applications: A state-of-the-art review. IBM J. Res. Dev., 28(2):124–134, 1984.
4. T. J. Dell. A white paper on the benefits of chipkill-correct ECC for PC server main memory. IBM Microelectronics, 1997.
FACTOR – 5.088 6. T. Hamamoto, S. Sugiura, and S.
Sawada. On the retention time distribution of dynamic random access memory (dram). IEEE Transactions on Electron Devices, 45(6):1300–1309, 1998.
7. H. Johnston. Scaling and technology issues for soft error rates. In Proc. of the 4th Annual Conf. on Reliability, 2000.
8. X. Li, K. Shen, M. Huang, and L. Chu. A memory soft error measurement on production systems. In Proc. of USENIX Annual Technical Conference, 2007.
9. T. C. May and M. H. Woods. Alpha-particle-induced soft errors in dynamic memories. IEEE Transactions on Electron Devices, 26(1), 1979. Messer, Bernadat, Fu, Chen, Dimitrijevic, Lie, Mannaru, Riska, and Milojicic. Susceptibility of commodity systems and software to memory soft errors. IEEE Transactions on Computers, 53(12), 2004.
10. D. Milojicic, A. Messer, J. Shau, G. Fu, and A. Munoz. Increasing relevance of memory hardware errors: a case for recoverable programming models. In Proc. of the 9th ACM SIGOPS European workshop, 2000.
11. S. S. Mukherjee, J. Emer, T. Fossum, and S. K. Reinhardt. Cache scrubbing in microprocessors: Myth or necessity?
12. S. S. Mukherjee, J. Emer, and S. K. Reinhardt. The soft error problem: An architectural perspective. In HPCA ’05: Proc. of the 11th International Symposium on High-Performance Computer Architecture, 2005. 13. E. Normand. Single event upset at
ground level. IEEE Transaction on Nuclear Sciences, 6(43):2742–2750, 1996. T. J. O’Gorman, J. M. Ross, A. H. Taber, J. F. Ziegler, P. Muhlfeld, C. J. Montrose, H. W. Curtis, and J. L. Walsh. Field testing for cosmic ray soft errors in semiconductor memories. IBM J. Res. Dev., 40(1), 1996.
14. R. Pike, S. Dorward, R. Griesemer, and S. Quinlan. Interpreting the data: Parallel analysis with sawzall. Scientific Programming Journal, Special Issue on Grids and Worldwide Computing Programming Models and Infrastructure, 13(4), 2005.
FACTOR – 5.088 Conference on Dependable Systems
and Networks, 2006.
16. Schroeder and G. A. Gibson. Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? In 5th USENIX FAST Conference, 2007.