Daniel Loebenberger and Michael Nüsken November 9, 2012
Abstract. We count]B, C]-grained,k-factor integers which are simultaneously B-rough andC-smooth and have a fixed numberkof prime factors. Our aim is to exploit explicit versions of the prime number theorem as much as possible to get good explicit bounds for the count of such integers. This analysis was inspired by certain inner procedures in the general number field sieve. The result should at least provide some insight in what happens there.
We estimate the given count in terms of some recursively defined functions. Since they are still difficult to handle, only another approximation step reveals their orders.
Finally, we use the obtained bounds to perform numerical experiments that show how good the desired count can be approximated for the parameters of the general number field sieve in the mentioned inspiring application.
Keywords. Smooth numbers, rough numbers, counting, prime number theo-rem, general number field sieve, RSA.
Subject classification. 11Axx,11N05,11N25
Let us call an integer A-grained iff all its prime factors are in the set A. Then an integer is C-smooth iff it is ]0, C]-grained, and B-rough iff it is ]B,∞[-grained. You may want to call an integer familycoarse-grained if it is]B, C]-grained and the number of factors is bounded. We consider the number of integers up to a real positive boundx that are]B, C]-grained and have a given number k of factors, in formulae: (0.1) πkB,C(x) := #nn≤x ∃p1, . . . , pk∈P∩]B, C] :n=p1· · ·pk
o .
are known, see for example the overview by Granville (2008). It is difficult, however, to compare our results to existing ones, since we consider integers with afixed number of factors. This restriction is completely sufficient for the application we have in mind. To our knowledge these kind of investigations cannot be found in the literature. Our main result implies the following
Corollary. Fix k ∈N≥2, α > 0 and ε > 0. Then for large B and C =B1+α we
have uniformly forx∈[Bk(1 +ε), Ck(1−ε)] that
πkB,C(x)∈Θ x lnB
.
Actually, we can describe a piecewise smooth function that approximatesπB,Ck up to an additive error of order O√x
B
and the hidden constant depends on ε,k and α only, see Theorem 9.2, Theorem 9.3.
To avoid difficulties with non-squarefree numbers, instead of numbers we count lists of primes
(0.2) κkB,C(x) := #n(p1, . . . , pk)∈(P∩]B, C])k p1· · ·pk ≤x
o .
It turns out that there are anyways only a few non-squarefree numbers counted by πkB,C, namely k!·πB,Ck (x) ≈ κkB,C(x). This would actually be an equality if there were no non-squarefree numbers in the count. We defer a precise treatment until Section 8.
We head for determining precise bounds κkB,C(x)or πB,Ck (x)that can be used in practical situations. However, to understand these bounds we additionally consider the asymptotical behaviours. This is tricky since we have to deal with the three parameters B, C and x simultaneously. To guide us in considering different asymp-totics, we usually writeB=xβ,C=xγ andγ =β(1 +α). In particular, C=B1+α. So we replace (B, C, x) with(x, β, γ) or(x, α, β), similar to the considerations when counting smooth or rough numbers in the literature. Alternatively, it seems also natural to fix xsomehow in the interval ]Bk, Ck]by introducing a parameterξ by
x=Bk−ξCξ=Bk+ξα.
Now the parameters are(B, C, ξ) or (B, α, ξ). As a first observation, note thatκk
B,C(x)is constantly0forx < Bkand constantly
(π(C)−π(B))k for x≥Ck and grows monotonically when xgoes through [Bk, Ck]. Here π denotes the prime counting function. For ‘middle’ x-values the asymptotics can be derived from our main result:
Corollary. Fix k ∈N≥2, α > 0 and ε > 0. Then for large B and C =B1+α we
have uniformly forx∈[Bk(1 +ε), Ck(1−ε)] that
κkB,C(x)∈Θ x lnB
= Θ
x
βlnx
Later, we specify a piecewise smooth function eκkB,C which approximates κkB,C with an error of orderO√x
B
where the hidden constants depend onε,kandα only, see Theorem 3.2, Theorem 3.5, and subsequent considerations.
The preceeding result is in contrast to the asymptotics at x=Ck:
κkB,CCk≈ C
k
lnkC =
Bk(1+α)
(1 +α)klnkB ∈Θ
x βklnkx
.
This observation is explained as follows: Note that roughly half of the numbers up tox are in the interval [12x, x]and similarly for primes. Thus the behaviour of those candidates largely rule κkB,C(x)/x. For an x = Bk−ξCξ with a fixed ξ ∈ ]0, k[, it
is mostly determined by the requirement that the counted numbers are B-rough, and we thus observe a comparatively large fraction of ]B, C]-grained numbers. In the extreme case x = Ck, most candidates are ruled out by the requirement to be
C-smooth and thus we see a much smaller fraction of]B, C]-grained numbers. The case that the intervals]Bk, Ck]are disjoint for considered valueskis especially
nice, as then the number of prime factors of aB-smooth andC-rough numberncan be derived from the number n. So we assume in the entire paper that C < Bs for some fixed s >1. (Clearly, we cannot have a fixed s that grants disjointness for all intervals. But for the first few we can.) In the inspiring number field sieve application we haveC < B1.232 .1 This ensures that the intervalsBk, Ckfork≤5are disjoint. A further application is related to RSA. Decker & Moree (2008) give estimates for the number of RSA-integers. They use one ad-hoc definition proposed by B. de Weger. However, it is not so clear which numbers we should call RSA-integers. A discussion and further calculations to adapt our results to the different shape are needed. We have treated these issues in Loebenberger & Nüsken (2011).
As our basic field of interest is cryptography and there the largest occurring numbers are actually small in the number theorist’s view, we assume the Riemann hypothesis throughout the entire paper. We use the following version of the prime number theorem:
Prime number theorem 0.3 (Von Koch 1901, Schoenfeld 1976). If (and only if)
the Riemann hypothesis holds then forx≥2657
|π(x)−li(x)|< 1 8π
√
xlnx,
where li(x) =R0xln1t dt. 1
Side remark: to indicate how a real number was rounded we append a special symbol. Examples:
We have numerically verified this inequality forx≤240≈1.1·1012 based on Kulsha’s tables (Kulsha 2008) and extensions built using the segmented siever implemented by Oliveira e Silva (2003). We are confident that we can extend this verification much further. In the inspiring application we havex <237 and so for thosex we can take this theorem for granted even if the Riemann hypothesis should not hold.
We arrive at the following description of the desired count: Theorem. Let B < C =B1+α with α ≥ ln√B
B and fix k ≥2. Then for any (small)
ε > 0 and B tending to infinity we have for x ∈ Bk(1 +ε), Ck(1−ε) a value
e
a∈h αk−1˘ck k!(1+α)k,k1!
i
with˘ck=min
2−4εkk!,2−k ε(kk−−1)!1 such that
πkB,C(x)−ea x lnB
≤(2k−1)αk−2(1 +α)·√x B + 2
k−1x
B.
Also without assuming the Riemann hypothesis we can achieve meaningful re-sults provided we use a good unconditional version of the prime number theorem whose error estimate is at least in Olnx3x
. The famous work by Rosser & Schoen-feld (1962, 1975) is not sufficient. Yet, Dusart (1998) provides an explicit error bound of order Olnx3x
, and Ford (2002a) provides explicit error bounds of order
Ox exp−(ln lnA(lnxx))31//55
though this only applies for x beyond 10171 or even much later depending onA and the O-constant, see Fact 6.1.
1. The recursion
The essential basis for the analysis of the counting functions κkB,C is the following simple description.
Lemma 1.1. For all k∈N>0 we have the recursion
κkB,C(x) = X
pk∈P∩]B,C]
κkB,C−1(x/pk)
based on
κ0B,C(x) = (
0 if x∈[0,1[, 1 if x∈[1,∞[.
Proof. In casek >0 we have
κkB,C(x) = #n(p1, . . . , pk)∈(P∩]B, C])k p1· · ·pk≤x
o
= # ]
p∈P∩]B,C] (
(p1, . . . , pk)∈(P∩]B, C])k
p1· · ·pk−1≤x/pk,
pk=p
)
= X
pk∈P∩]B,C]
The case k= 0 is immediate from the definition.
From the definition (0.2) or from Lemma 1.1, it is clear that
κ1B,C(x) =
0 if x∈[0, B[, π(x)−π(B) if x∈[B, C[, π(C)−π(B) if x∈[C,∞[.
This reveals that the case distinction in κ0B,C leaves its traces on higher κkB,C. For further calculations it is vital that we make this precise. This will enable us later to do our estimates. Fork∈Nwe distinguishk+ 2cases:
x is in case (k,−1) :⇐⇒ x∈h0, Bkh,
x is in case (k, j) :⇐⇒ x∈hBk−jCj, Bk−1−jCj+1h, x is in case(k, k) :⇐⇒ x∈hCk,∞h,
where j∈N<k. Note that most cases are characterized by the exponent of C at the
left end of the interval.
Lemma 1.2. Fork, j ∈N,0≤j < k and x in case(k, j), we have
κkB,C(x) = X
pk∈P∩
i
x Bk−1−j Cj,C
iκ
k−1
B,C(x/pk) +
X
pk∈P∩
i
B, x Bk−1−j Cj
iκ
k−1
B,C(x/pk)
where in the first sumx/pk is in case(k−1, j−1)and in the second in case(k−1, j).
For j = −1, and j = k we do not split the sum, as then all x/pk are in one case
anyways. Forj= 0 the left part is zero, so that the splitting there is less visible.
Proof. We only have to verify that x/pk ∈ Bk−1−jCj, Bk−j−2Cj+1 for pk ∈
P∩]B, x/Bk−1−jCj] and x ∈ Bk−jCj, Bk−1−jCj+1. Similarly, the statement for
the second sum is established.
For example, we obtain
κ2B,C(x) =
0 if x∈0, B2,
P
p2∈P∩]B,Bx] P
p1∈P∩
i
B,px 2
i1 if x∈B2, BC,
P
p2∈P∩]Cx,C] P
p1∈P∩
i
B,px 2
i1
+Pp
2∈P∩]B,Cx] P
p1∈P∩]B,C]1
if x∈BC, C2, P
p2∈P∩]B,C] P
p1∈P∩]B,C]1 if x∈
C2,∞.
So for κ2B,C(x) we have four cases with four 2-fold sums. In general κkB,C(x) has k+ 2cases with 2k k-fold sums. Well, we better stop unfolding here.
Based on the intuition that a randomly selected integer n is prime with proba-bility ln1n we can replace Pp∈P∩]B,C]f(p) with
RC B
f(p)
lnp dp. This directly leads to the
approximation function. We prefer however to follow a better founded way to them which will also give information about the error term.
2. Using estimates
From the recursion forκkB,C(x) it is clear that we have to compute terms like X
p∈P∩]B,C]
f(p) or X
p∈P∩]B,C]
f(x/p).
To get good estimates for such a sum we follow the classic path, as Rosser & Schoen-feld (1962): we rewrite the sum as a Lebesque-Stieltjes-integral over the prime count-ing functionπ(p). Then we substitute π(t) =Li(t) +E(t), keeping in mind that we know good bounds on the error termE(t)by the Prime number theorem 0.3. Finally, we integrate by parts, estimate and integrate by parts back:
X
p∈P∩]B,C] f(p)
= Z C
B
f(t) dπ(t)
= Z C
B
f(t) d Li(t) + Z C
B
f(t) dE(t)
= Z C
B
f(t)
lnt dt+f(C)E(C)−f(B)E(B)− Z C
B
E(t) df(t).
The existence of all integrals follow from the existence of the first. If the sum kernel f is differentiable with respect to t we can rewrite RBCE(t) df(t) =RBCf′(t)E(t) dt. Now we can use the estimate on the error termE(t):
X
p∈P∩]B,C] f(p)−
Z C
B
f(t) lnt dt
≤ |f(C)|Eb(C) +|f(B)|Eb(B) + Z C
B |
f′(t)|Eb(t)dt.
What remains is, given the concrete f, to determine the occurring integrals. For the counting functions κkB,C —as one would guess— this task is more and more complicated the largerk is. Clearly, smoothness properties off must be considered carefully.
Lemma 2.1 (Prime sum approximation). Letf,fe,fbbe functionsR>0 →R≥0 such
thatfeand fbare piecewise continuous, fe+fbis increasing, and
f(x)−fe(x)≤fb(x)
forx∈R>0. Further, let Eb(p)be a positive valued, increasing, smooth function of p
bounding |π(p)−Li(p)| on [B, C]. (For example, under the Riemann hypothesis we can takeEb(p) = 81π√plnp provided p≥2657.) Then for x∈R>0
X
p∈P∩]B,C]
f(x/p)− eg(x)
≤ bg(x)
where
e g(x) =
Z C
B
e f(x/p)
lnp dp , b
g(x) = Z C
B
b f(x/p)
lnp dp+2(fe+fb)(x/B)Eb(B) + Z C
B
e
f+fb(x/p)Eb′(p) dp .
Moreover, eg andbg are piecewise continuous, andeg+bgis increasing.
Proof. The assumption immediately implies
X
p∈P∩]B,C]
f(x/p)− X
p∈P∩]B,C] e f(x/p)
≤ X
p∈P∩]B,C] b f(x/p).
Using the techniques just sketched we obtain Pp∈P∩]B,C]fe(x/p) = RC
B
e
f(x/p) lnp dp+
RC
B fe(x/p) dE(p) with E(p) = π(p)−Li(p). Shifting the second term to the
corre-spondingly transformed error bound, we now have X
p∈P∩]B,C]
f(x/p)− Z C
B
e f(x/p)
lnp dp
| {z }
=eg(x)
≤ Z C B b f(x/p)
lnp dp+ Z C
B
(fb+fe)(x/p) dE(p).
h(p) = (fe+fb)(x/p) we estimate the last integral: Z C
B
h(p)dE(p) =h(C)E(C)−h(B)E(B)− Z C
B
E(p)dh(p)
≤h(C)Eb(C) +h(B)Eb(B)− Z C
B
b
E(p)dh(p) = +h(C)Eb(C) +h(B)Eb(B)
−h(C)Eb(C) +h(B)Eb(B)
+ Z C
B
h(p) dEb(p).
For the inequality we use that h(p)is decreasing inp. Collecting gives the claim. Finally, eg and bg being obviously piecewise continuous it remains to show that e
g+bg is increasing. By the (defining) equation (eg+bg)(x) =
Z C
B
(fe+fb)(x/p)
1 lnp+Eb
′(p) dp+2(fe+fb)(x/B)Eb(B)
this follows fromfe+fband Eb being increasing.
3. Approximations
Based on Lemma 2.1 we recursively define approximation functions κekB,C and error bounding functions κbkB,C. Recursive application of Lemma 2.1 will lead to a good estimate in Theorem 3.2. For the understanding we further need to determine the asymptotic order of the functions defined here, which we start in the remainder of this section. Theorem 3.5 relates the functionseκkB,C andbκkB,C to some easier manageable functions. These in turn are computed or estimated, respectively, in Section 4 and Section 5.
Definition 3.1. Forx≥0 we define
e
κ0B,C(x) :=κ0B,C(x), bκ0B,C(x) := 0
and recursively fork >0
e
κkB,C(x) := Z C
B
e
κkB,C−1(x/pk)
lnpk
dpk,
b
κkB,C(x) := Z C
B
b
κkB,C−1(x/pk)
lnpk
dpk
+ 2κekB,C−1+bκB,Ck−1(x/B)Eb(B)
+ Z C
B
e
These functions now describe the behavior ofκkB,C nicely: Theorem 3.2. Givenx∈R>0 and k∈N. Then the inequality
κkB,C(x)−eκkB,C(x)≤bκkB,C(x)
holds.
Proof. Using Lemma 2.1 the claim together with the fact that κek
B,C +κbkB,C is
increasing follow simultaneously by induction onkbased oneκ0B,C =κ0B,C andbκ0B,C=
0.
In order to give a first impression we calculate eκ1B,C and κb1B,C. Analogous to Lemma 1.2, we split the integration at x/Bk−1−jCj so that the parts fall entirely
into case(k−1, j−1) or into case(k−1, j):
e
κkB,C(x) = Z C
x/Bk−1−jCj
e
κkB,C−1(x/pk) dpk+
Z x/Bk−1−jCj
B e
κkB,C−1(x/pk) dpk.
Also for bκkB,C this can be done, simply split the occurring integrals at x/Bk−1−jCj.
Now unfolding the recursive definition ofκe1B,C gives:
e
κ1B,C(x) =
0 if x∈[0, B[, Rx
B ln1p1 dp1 if x∈[B, C[, RC
B ln1p1 dp1 if x∈[C,∞[,
b
κ1B,C(x) =
0 if x∈[0, B[, b
E(x) +Eb(B) if x∈[B, C[, b
E(C) +Eb(B) if x∈[C,∞[,
which corresponds exactly to the approximation of the prime counting function by the logarithmic integral Li. In casek= 2we obtain
e
κ2B,C(x) =
0 if x∈0, B2,
R x B B
R x p2
B lnp11lnp2 dp1 dp2 if x∈
B2, BC, RC
x C
R x p2
B lnp11lnp2 dp1 dp2 +RCx
B
RC
B lnp11lnp2 dp1 dp2
if x∈BC, C2, RC
B
RC
B lnp11lnp2 dp1 dp2 if x∈
C2,∞.
(3.3)
have computed it. But the resulting terms are so complex that we didn’t really learn much from it. Here is an expression forx∈B2, BC:
b
κ2B,C(x) = Z x
B
B
Z x p
B
b E′(q)
lnp + b E′(p)
lnq +Eb
′(p)Eb′(q) !
dq dp
+ 4Eb(B) Z x
B
B
1
lnp dp + 4Eb(B)Eb(x/B)
Though this term is still handleable, it becomes apparent that things get more and more complicated with increasingk. We escape from this issue by loosening the bonds and weakening our bounds slightly. The first aim will be to obtain easily computable terms while retaining the asymptotic orders, the second aim will be to still retain meaningful bounds for the fixed valuesB = 1100·106,C= 237−1,k∈ {2,3,4}from our inspiring application.
Our next task is to describe the orders ofeκk
B,C andbκkB,C. The main problem in an
exact calculation is that most of the time we cannot elementary integrate a function with a logarithm occurring in the denominator. But usingB ≤p≤C we can obtain a suitably good approximation instead by replacing ln1p with ln1B in the integrals. At this point we start usingC≤Bs and rewriteC=B1+α where αis a new parameter (bounded bys−1). For the time being you can considerαas a constant, but actually we make no assumption on it. This leads to the following
Definition 3.4. Forx≥0 we let
e
λ0(x) :=κ0B,C(x), bλ0(x) := 0,
and recursively fork >0
e
λk(x) := Z C
B
e
λk−1(x/pk)
lnB dpk, b
λk(x) := Z C
B
b
λk−1(x/p
k)
lnB dpk
+ 2eλk−1+bλk−1(x/B)Eb(B)
+ Z C
B
e
λk−1+bλk−1(x/pk)Eb′(pk) dpk.
We observe that lnB ≤ lnpk ≤ lnC = (1 +α)lnB. Thus we obtain RBC fln(pp) dp∈
h
1 1+α,1
i RC B
f(p)
lnB dp for any positive integrable function f. By induction on k we
Theorem 3.5. WriteC =B1+α and fix k∈N>0. Then for x∈R>0 we have
e
κkB,C(x)∈
1 (1 +α)k,1
e λk(x),
b
κkB,C(x)∈
1 (1 +α)k,1
b
λk(x).
In order to determine at least the asymptotic orders of κekB,C and bκkB,C (along with precise estimates) it remains to solve the recursions for eλk and bλk, or at least to estimate these functions. As a first step, we rewrite all integrals in Definition 3.4 in terms of ̺defined by pk=B1+̺α.
Definition 3.4 continued. Rewrite x = Bk+ξα with a new parameter ξ and let
e
λkhξi:=eλk Bk+ξαandλbkhξi:=bλk Bk+ξα. (Actually, you may think offkhξi:= fk(Bk+ξα) for any family of functions fk.)
Lemma 3.6. Fork >0 we now have the recursion
e
λkhξi=α Z 1
0
e
λk−1hξ−̺iB1+̺αd̺ , b
λkhξi= α Z 1
0
b
λk−1hξ−̺iB1+̺α d̺ + 2eλk−1+λbk−1hξiEb(B)
+αlnB Z 1
0
e
λk−1+bλk−1hξ−̺iEb′(B1+̺α)B1+̺α d̺ .
4. Solving the recursion for eλk
To construct a useful description of the function eλk we make a small excursion and
consider the following family of piecewise polynomial functions.
Definition 4.1 (Polynomial hills). Initially, define the integral operatorMby
(Mf)(ξ) = Z 1
0
f(ξ−̺) d̺= Z ξ
ξ−1
f(̺) d̺
for any integrable functionf:R→R. Now fork∈N>1 let the k-th polynomial hill
be
e
mk:=Mmek−1
based on the rectangular functionme1 given byme1(ξ) = 1forξ ∈[0,1[andme1(ξ) = 0
Actually, me1 =Mme0 if we let me0 =δ be the ‘left lopsided’ Dirac delta distribution defined by its integral R−∞ξ δ(t) dt being 0 for ξ <0 and 1 for ξ ≥0. Contrastingly, the standard Dirac delta function is balanced and hasR−∞0 δ(t) dt= 12. However, we will stick to the lopsided variant throughout the entire paper. By Dξ we denote the differential operator with respect toξ .
Lemma 4.2 (Polynomial hills).
(i) mek(ξ) = 0 for ξ <0 or ξ≥k.
(ii) mek(ξ) = 1
(k−1)!ξk−1 forξ ∈[0,1[andmek(ξ) = (k−11)!(k−ξ)k−1forξ ∈[k−1, k[.
(iii) mek restricted to [j, j+ 1[ is a polynomial function of degree k −1 for j ∈
{0, . . . , k−1}. In particular,mek is smooth for ξ∈R\ {0, . . . , k}.
(iv) mek is(k−2)-fold continuously differentiable.
(v) Conversely, the conditions (i) through (iv) uniquely determine mek.
(vi) Dξimek =MDiξmek−1 as long as i≤k−2 and even fori=k−1 when read for distributions.
(vii) The function mek is symmetric to k2: mek(ξ) =mek(k−ξ).
(viii) Forξ∈[j, j+ 1[ (corresponding to case(k, j)) we have
Dkξ−1mek(ξ) = (−1)j ·
k
−1 j
.
(ix) The next derivate can only be correctly described as a linear combination of Dirac delta distributions:
Dkξmek(ξ) =
X
0≤j≤k
(−1)j
k j
·δ(ξ−j).
(x) For any 0≤ℓ < k we obtain the following explicit description:
Dξℓmek(ξ) =
1 (k−1−ℓ)!
X
0≤i≤⌊ξ⌋
k i
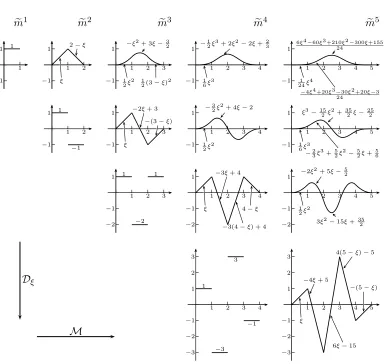
(−1)i(ξ−i)k−1−ℓ
e m1 1 −1 1 1 e m2 1 −1 1 2 ξ
2−ξ
1 −1 1 2 1 −1 e m3 1 −1
1 2 3
1
2ξ2
−ξ2+ 3ξ−32
1
2(3−ξ)2
1
−1
1 2 3 ξ
−2ξ+ 3 −(3−ξ)
1
−1
−2
1 2 3 1 −2 1 e m4 1 −1
1 2 3 4
1
6ξ3
−12ξ3+ 2ξ2−2ξ+23
1
−1
1 2 3 4
1
2ξ2
−32ξ2+ 4ξ−2
1
−1
−2
1 2 3 4
ξ
−3ξ+ 4
−3(4−ξ) + 4 4−ξ
1 2 3 −1 −2 −3
1 2 3 4
1 −3 3 −1 e m5 1 −1
1 2 3 4 5
1
24ξ4
−4ξ4+20ξ3−30ξ2+20ξ−3
24
6ξ4−60ξ3+210ξ2−300ξ+155
24
1
−1
1 2 3 4 5
1
6ξ3
−23ξ3+52ξ2−52ξ+56 ξ3−152ξ
2+35
2ξ−
25 2
1
−1
−2
1 2 3 4 5
1
2ξ2
−2ξ2+ 5ξ−52
3ξ2−15ξ+35 2 1 2 3 −1 −2 −3
1 2 3 4 5
ξ
−4ξ+ 5
6ξ−15 4(5−ξ)−5
−(5−ξ)
M Dξ
Figure 4.1: Graphs of the polynomial hills mek for k≤5 and their derivatives
Curiosity: The function√k·mekcan also be described as the volume of a slice through a(k−1)-dimensional unit hypercube of thickness √1
k orthogonal to a main diagonal.
That’s the same as saying it is √1
k times the (k−1)-volume of the cut between a
k-dimensional hypercube and the hyperplaneP1≤i≤k̺i =ξ. This last interpretation
makes it obvious that Z
k
0 e
mk(ξ) dξ= 1, since this is the volume of thek-hypercube.
Proof. From the definition (i) through (vii) follow directly. Further, note that
k >1. The recursion forme differentiated k−1times yields forξ ∈[j, j+ 1[
Dξk−1mek(ξ) =DξMDξk−2mek−1(ξ)
=Dξk−2mek−1(ξ)− Dξk−2mek−1(ξ−1)
= (−1)j
k−2 j
−(−1)j−1
k−2 j−1
= (−1)j
k−1 j
.
(ix) follows similarly.
To prove (x) consider h(ξ) = (k−11)!P0≤i≤⌊ξ⌋ ki(−1)i(ξ−i)k−1. ThenDk−1
ξ h= Dξk−1mek using (viii). And obviously Dξℓh(0) = 0 = Dξℓmek(0) for 0 ≤ ℓ < k−1, so
that inductively (with fallingℓ) we get Dξℓh=Dξℓmek.
As we do not need (v) and (xi), we leave these proofs to the interested reader.
Most of the following is easier if we first renormalize λek. So we let
e
λknormhξi:= 1 αkBk+ξαλe
k hξi. (4.3)
The recursion foreλk now turns into
e
λknorm=Meλknorm−1 .
Theorem 4.4 (Approximation order). For any ξ∈Rwe have
e
λknormhξi= Z ξ
0
B−̺αmek(ξ−̺) d̺=B−ξα Z ξ
0
B̺αmek(̺) d̺ ,
e
λknormhξi= 1 (−αlnB)k
X
0≤i≤⌊ξ⌋ k
i
(−1)iB−(ξ−i)α
− X
0≤ℓ≤k−1
(−αlnB)ℓ· Dξk−ℓ−1mek(ξ) ,
e
λknormhξi= X
0≤i≤⌊ξ⌋
k i
(−1)icutexpk(−(ξ−i)αlnB) (−αlnB)k ,
where cutexpk(ζ) =exp(ζ)−P0≤ℓ≤k−1ζℓℓ! =Pℓ≥kζℓℓ!. We can also express cutexpk
Proof. The definition foreλ0 turns into
e
λ0normhξi= Z ∞
0
B−̺αδ(ξ−̺) d̺ .
Now, sinceMcommutes with this integration this immediately implies that e
λknormhξi= Z ∞
0
B−̺αmek(ξ−̺) d̺
which is the first stated equality noting that mek is zero outside [0, k]. By partial integration we obtain
e
λknormhξi= 1 αlnBme
k(ξ)− 1
αlnB Z ∞
0
B−̺αDξmek(ξ−̺) d̺
= X
1≤i≤k
(−1)i−1
(αlnB)iD
i−1
ξ mek(ξ) +
(−1)k
(αlnB)k Z ∞
0
B−̺αDξkmek(ξ−̺) d̺ .
Using the description of Dkξmek from Lemma 4.2(ix) the last integral turns into the claimed sum of the second stated equality. Expressing Dkξ−ℓ−1mek(ξ −̺) us-ing Lemma 4.2(x) and rearrangus-ing slightly yields the third equality.
We are going to estimate the estimation of the error in the next section. To that aim we first need to estimateλeknorm. If k >0 then, based on Theorem 4.4 and
e
mk(ξ)≤1, we obtain the upper bound
e
λknormhξi= Z ∞
0
B−̺αmek(ξ−̺)d̺≤ 1 αlnB.
For k = 0 we have λe0normhξi = B−ξα for ξ ≥0 and so eλ0normhξi ≤ 1 will do for all ξ∈R.
We first describe the qualitative behaviour of eλknorm. Actually its graph looks like a slighty biaswise hill.
Lemma 4.5. The function λek
normhξi=B−ξα
Rξ
0 B̺αmek(̺) d̺ is zero at ξ = 0, posi-tive atξ =k, more precisely
e
λknormhki= 1
−B−α
αlnB k
,
and there is a position ξk1 2 ∈
]0, k] such that it is increasing on]0, ξk1 2
[and decreasing
on]ξk1 2
, ξ[. Further, ξk1 2 ≥
k
Proof. First, inspecting
e
λ1normhξi= Z ξ
0
B−̺αme1(ξ−̺) d̺
=
0 if ξ <0,
1−B−ξα
αlnB if ξ∈[0,1],
1−B−α
αlnB B−(ξ−1)α if ξ >1. 0 1
1−B−α
αlnB
shows that for k= 1 all claims hold with ξk 1 2
= 1. So in the remainder of this proof we assumek >1.
Next, computeλeknormhki inductively:
e
λknormhki=B−kα Z k
0
B̺α Z 1
0 e
mk−1(̺−̺k) d̺k d̺
=B−α Z 1
0
B̺kα d̺k
| {z }
=1−B−α αlnB
·B−(k−1)α Z k−1
0
Bτ αmek−1(τ) dτ
| {z }
=λek−1
normhk−1i
=
1−B−α
αlnB k
.
Here we have substituted τ = ̺ −̺k and collapsed the new integration interval
[−̺k, k−̺k]for τ to [0, k−1]sincemek−1 vanishes on the difference Moreover, based
onλek
normhξi=B−ξα
Rξ
0 B̺αmek(̺) d̺ we obtain
Dξλeknormhξi=−αlnB·eλknormhξi+mek(ξ), (4.6)
and infer thatDξeλknormhki=−αlnB1α−lnB−Bαk is negative. Finally, compute the derivate ofeλk
norm differently
Dξeλknormhξi=Dξ Z ξ
0
B−̺αmek(ξ−̺) d̺
=B−ξα Z ξ
0
B̺αDξmek(̺)d̺ .
The integral kernel B̺αDξmek(̺) is positive on ]0,k
2[ and negative on ]k2, k[. Thus
Rξ
0 B̺αDξmek(̺) d̺ increases on ]0,k2[and decreases on]k2, k[. Since this term starts
at zero, it is positive for some time, begins to decrease at k2, traverses zero at some pointξk1
2
recalling that atkthe value is negative, and stays negative tilξ =ksince it continues to decrease. Thus the sign ofDξλek
normhξiis positive on]0, ξk1 2
[and negative on]ξk1
2
, k[, and soeλknormhξi is increasing till ξk1 2
0 1 2 3 4 5 6 7 1−B−α
αlnB
ξ
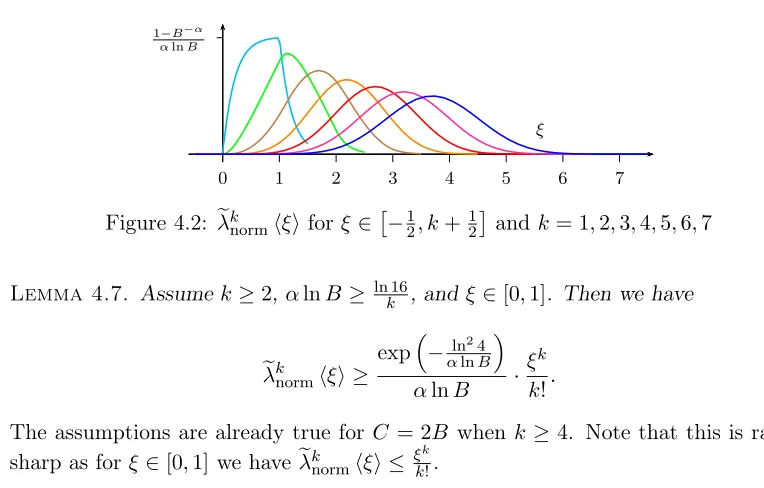
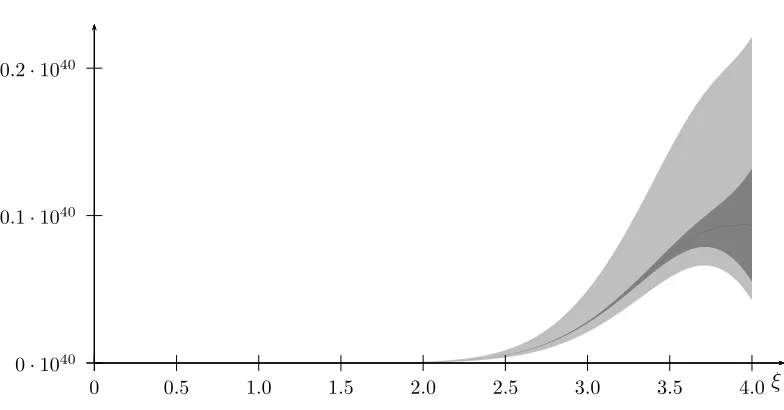
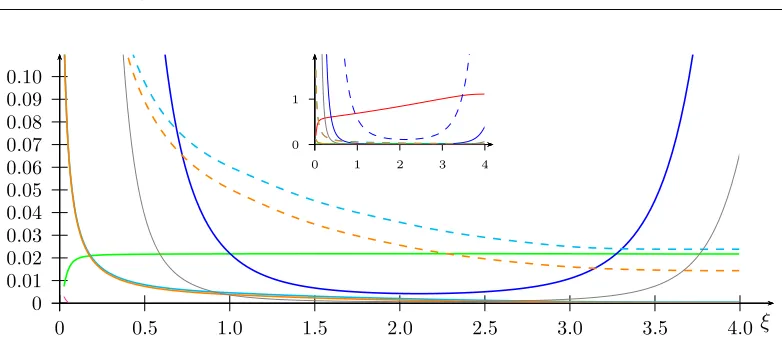
Figure 4.2: eλknormhξifor ξ ∈−12, k+ 12and k= 1,2,3,4,5,6,7
Lemma 4.7. Assume k≥2, αlnB ≥ ln16
k , and ξ∈[0,1]. Then we have
e
λknormhξi ≥
exp−αlnln24B αlnB ·
ξk k!.
The assumptions are already true for C = 2B when k≥4. Note that this is rather sharp as forξ∈[0,1]we haveλeknormhξi ≤ ξkk!.
Proof. We use the integral representation from Theorem 4.4 and estimate the polynomial hill partmek(ξ−̺) of its kernel by a simple piecewise constant function
as indicated in the picture. We obtain
e
λknormhξi= Z ξ
0
B−̺αmek(ξ−̺) d̺
≥
Z ε
0
B−̺α d̺·mek(ξ−ε)
= 1
αlnB 1−exp(−εαlnB)
e
mk(ξ−ε).
B−̺α
e
mk(ξ−̺)
0 1
0 1 2
̺ ξ
ε
This holds for anyε∈[0, ξ]since0≤ξ≤ k2 ensures thatmekis increasing. So we can optimize εdepending on ξ. We obtain a suitable value when setting εby
1−exp(−εαlnB) = ξ k. (4.8)
To make sure that now ε≤ξ we use the following simple fact. Fact 4.9. For any ϑ >0 andτ = 1−exp(−ϑ)
ϑ the map
[0, ϑ] −→ [0, τ ϑ], z 7−→ 1−exp(−z),
ϑ τ ϑ 1−e−z
τ z z
Let ϑ1 > 0 be such that 1−exp(−ϑ1) = k1. Namely, ϑ1 = −ln 1−k1. With
τ1= 1−exp(ϑ1−ϑ1) then1 =τ1ϑ1kand kξ ≤τ1ϑ1. Thus we haveεαlnB ∈[0, ϑ1]so that
τ1εαlnB≤1−exp(−εαlnB) =
ξ
k ≤εαlnB. (4.10)
In particular,ε≤ξ follows fromkτ1αlnB = ϑ11αlnB ≥1. By Fact 4.9 withϑ=ln2
we obtain τ = 2ln12 and 1−k1k ≥ exp(−1τ) = exp(−ln4) for all k ≥ 2. Thus kϑ1 = −kln 1−1k ≤ ln4. Further, αlnB ≥ lnk16 > ln4k ≥ ϑ1. This now implies
ε≤ξ.
Since ξ∈[0,1] we have the explicit expressionmek(ξ−ε) = (ξ(−k−ε)1)!k−1 and so
e
λknormhξi ≥ ξ kαlnBme
k(ξ−ε) = (1−ε/ξ)k−1
αlnB · ξk k!.
Sinceϑ1< αlnBwe can defineϑ2by1−exp(−ϑ2) = αϑln1B, and according to Fact 4.9
let τ2 = 1−exp(ϑ2−ϑ2). Combining with (4.10) gives us
1−εξk ≥ 1−kτ 1 1αlnB
k
=
exp−τ 1
2τ1αlnB
and thus simplifies our above inequality to
e
λknormhξi ≥
exp−τ 1
2τ1αlnB
αlnB · ξk
k!. (4.11)
By our choices
1 τ1τ2αlnB
=kϑ2 ≥
kϑ1
αlnB ≥ 1 αlnB.
Though these inequalities get equalities with k → ∞, we need a precise estimate. Substituting kin−kln 1− 1k≤ln4 with kαlnln4B yields
1 τ2τ1
=kαlnB·ϑ2 =−kαlnBln
1− kϑ1 kαlnB
≤ −kαlnln4B ln
1− ln4 kαlnB
ln4≤ln24
provided αlnB ≥ lnk16.
Though we know the value of eλknormhki, it is orders smaller than the above left lower bound. Thus let us consider eλk
Lemma 4.12. Ifk≥3 then forξ∈[k−1, k]we have
e
λknormhξi ≥ (1−B−
α)k
αlnB ·
(k−ξ)k−1
(k−1)! .
Proof. By definition we have eλk
normhξi =
e
λkhξi
αkBk+ξα. Theorem 4.4’s third
descrip-tion expresseseλk
normon[k−1, k]as a sum ofkterms. Adding the missing termi=k
we obtain αkλeBkhkk+iξα, noting that eλk is constant forξ > k:
e
λknormhξi=
1−B−α
αlnB k
B(k−ξ)α−cutexpk((k−ξ)αlnB) (αlnB)k
To check the claimed inequality we substitute τ = (k−ξ)αlnB ∈[0, αlnB] (elimi-natingξ):
e
λknormhξi= P
0≤ℓ≤k−1 τ
ℓ ℓ! −
1−(1−B−α)keτ
(αlnB)k .
We have to show that this is at least (1−B−α)k
(αlnB)k
τk−1
(k−1)! which we rewrite to
X
0≤ℓ≤k−2
τℓ ℓ! ≥
1−(1−B−α)k eτ− τ
k−1
(k−1)!
.
Obviously(1−B−α)k ≥(1−e−τ)k in our situation, with equality for τ =αlnB or
ξ=k−1. Thus it suffices to show for any τ >0 X
0≤ℓ≤k−2
τℓ
ℓ! ≥(1−(1−e −τ)k)
eτ− τ
k−1
(k−1)!
. (4.13)
The remaining proof proceeds in four steps:
◦ High case: P0≤ℓ≤k−2 τℓℓ! ≥k.
◦ Low case: 1−τe−τ ≥ qk 1+σ
k! , where 1σ + 1≤
ek−1(k−1)!
(k−1)k−1 . ◦ Covering: Fixingσ := √ 1
2π(k−1)−1 these cases cover allτ >0 if k≥4.
◦ Brute-force: Prove (4.13) fork= 3. (Actually, for k∈ {3,4,5,6,7,8,9}.) High case: Since eτ ≥ P0≤ℓ≤k−2τℓℓ! ≥ k in this case we have τ ≥ lnk. Employing
Bernoulli’s inequality(1−T)k≥1−kT for T =e−τ ≤1 we obtain (1−(1−e−τ)k)
eτ− τ
k−1
(k−1)!
≤ke−τ
eτ − τ
k−1
(k−1)!
=k
1− τ
k−1
(k−1)!e −τ
≤k≤ X
0≤ℓ≤k−2
τℓ
As Bernoulli’s inequality is good forT close to 0 only, it is not surprising that this only gives a sufficient result forτ large enough.
Low case: Assume 1−τe−τ ≥ qk 1+σ
k! where σ is chosen such that σ1 + 1 <
ek−1(k−1)!
(k−1)k−1 .
(Since 1−eτ−τ is decreasing, this is always true on some interval[0, τ0].)
The condition on σ implies that eτ− 1σ + 1(τk−k−1)!1 is non-negative for all τ >0: Considerf0(τ) = e
τ(k−1)!
τk−1 − σ1 + 1
. Then f0′ vanishes at τ =k−1 only and thusf0
is minimal there. The assumption onσ is precisely f0(k−1)≥0.
Further, note that (τkk−−2)!2 + (kτk−−1)!1 ≤ eτ ≤ P0≤ℓ≤k−1 τℓℓ! +eτ τkk!. We use this to obtain:
1−(1−e−τ)k | {z } ≥(1+kσ!)τ k
eτ− τ
k−1
(k−1)!
| {z }
≥0
≤eτ − τ
k−1
(k−1)! −(1 +σ) τk k!e
τ+ (1 +σ)τk
k! τk−1 (k−1)!
≤ X
0≤ℓ≤k−2
τℓ ℓ! −
στk k! e
τ + (1 +σ)τk
k! τk−1 (k−1)!
= X
0≤ℓ≤k−2
τℓ ℓ! −σ
τk k!
eτ−
1 σ + 1
τk−1 (k−1)!
| {z }
≥0
≤ X
0≤ℓ≤k−2
τℓ ℓ!.
Notice that the value ofσ only influences the set of values ofτ that fall in this case. Covering: We chooseσ := √ 1
2π(k−1)−1. Recall Stirling’s formula: For any n >0there
is a ϑ ∈ ]0,1[ such that n! = nen√2πne12n1+ϑ, see Robbins (1955). We thus have
1
σ+1 =
p
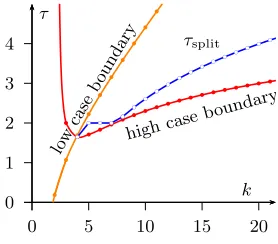
2π(k−1)< e(kk−−1(1)kk−−1)!1 as required. Further, we define the valueτsplitwhere
we split between the low and the high case:
τsplit:=
2lnke if k≥8, 2 if 5≤k≤7,
√
7−1 if k= 4. We start with the treatment of the casesk≥8.
We claim that for τ ≤τsplit we are in the low case, ie.
1−e−τ
τ ≥
k
r 1 +σ
k! =:ϑ. (4.14)
Consider f2(τ) = 1−e−τ −ϑτ. It obviously vanishes atτ = 0. The derivative off2
Coarse-grained integers 21 0 1 2 3 4
0 5 10 15 20
τ τsplit low case bou nd ary highcase boundary k b
b b b b b
b b b b
b b
b b b b b b b b b b b b b b b b
b b b b b b b b b b b b b b b b b b b b b b b b b c b
c bc bc bcbc
b c b c b c b c b c b
c bc
b
c bc
b
c bc
b
c bc
b
c bc bc
b
c bc bc
b
c bc bc
Figure 4.3: Case coverage and τsplit
prove (4.14) forτ ∈]0, τsplit]it is thus sufficient to prove that f2 is at least 0at the
right boundary. First, note that by Stirling’s formula we have k!≥ kek√2π and so we can estimate ϑby ke:
ϑ= k r
1 +σ k! ≤
e k k s 2 √ 2π | {z }
≤1
≤ ke.
Well, now we have
k·f2(τsplit) =k−
e2
k −kϑτsplit
≥k−e
2
k −2e ln k
e =:f3(k).
Checking that f3(e) = 0 and the derivative f3′(k) = (1− ek)2 is positive for k > e
shows that f3(k) >0 for all k ≥ 3. Thus for τ ≤τsplit we are in the low case with
the above choice of σ.
It remains to check that forτ ≥τsplitwe are in the high case. We use the Lagrange
remainder estimate of the power series of the exponential function and again Stirling’s formula to obtain
X
0≤ℓ≤k−2
τℓ
ℓ! ≥e
τ
1− τ
k−1
(k−1)!
≥eτ 1−
eτ k−1
k−1!
=:f5(k, τ).
As the left hand side is increasing in τ > 0 we consider the smallest τ in question: letf6(k) :=f5(k, τsplit)/k. Therein,
eτsplit
k−1 k−1
=exp
−(k−1) | {z }
(I)
−ln2−1−ln lnk
e +ln(k−1)
| {z }
(II)
Observe that the term (I) is obviously positive and increasing fork≥8. The same is true for the term (II): its derivative k−11−k(ln1k
−1) is positive fork≥e2≈7.39 and
the value of term (II) at e2 is positive. Using this we infer that f
6 is increasing and
positive. Checkingf6(10)>1(f6(10)∈]1.19,1.20[) now provesP0≤ℓ≤k−2
(2lnke)ℓ
ℓ! ≥
kfor k≥10. For k= 8 andk= 9 we just verify this inequality directly.
It remains to consider4≤k≤7. Here we use individual seperation positions as defined above:
k 4 5 6 7 (8) (9)
τsplit √7−1 2 2 2 2ln8e 2ln9e 1−e−τsplit
τsplit 0.49 0.43 0.43 0.43 0.40 0.37
∨ for low case
k
q
1+σ
k! 0.48 0.40 0.35 0.31 0.28 0.25
P
0≤ℓ≤k−2
τℓ
split
ℓ! 4 6.33 7.00 7.27 8.60 10.93 ≥kfor high case
Just check that for this τsplit the low and the high case conditions are both fulfilled.
Summing up: the claim is proved fork≥4.
k <10: For k= 3 we need an explicit check as the estimates done in the low and the high case are too sloppy. As the following actually is a general computational way to verify the inequality (4.13) we do describe it in general, show computational results for 3≤k≤10 and make the critical case k= 3 hand-checkable at the end. For the verification we use a small trick and brute force: First, we substitute occurrences of e−τ with a new variableT. The task turns into showing that the bivariate polynomial
Fk(τ, T) :=
X
0≤ℓ≤k−2
τℓ
ℓ! −
(1−(1−T)k)
T
1− τ
k−1
(k−1)!T
is non-negative at τ = −lnT for T ∈ ]0,1]. Now, observe that Fk is increasing in
τ >0 for fixed T ∈ [0,1]. If we thus replace −lnT with a lower bound and we can show that the resulting term is still non-negative then we are done. For T ∈ ]0,1] we have −lnT ≥P1≤ℓ≤s(1−ℓT)ℓ. This lower bound even converges to −lnT, which actually ensures that we can always find some sthat allows the following reduction. We consider the univariate polynomial
gk,s(T) :=Fk
X
1≤ℓ≤s
(1−T)ℓ ℓ , T
.
By our reasoning, the claim follows if ∀T ∈ ]0,1] : gk,s(T) ≥0 for some s. This in
turn is implied by
gk,s(0)>0 ∧ gk,s(T) has no zero for0< T <1.
The second statement can be checked using Sturm’s theorem (Sturm 1835) by only evaluating certain rational polynomials at T = 0 and T = 1. However, this only works if the chosensis large enough. We have determined the smallest sthat make (4.15) true:
k 3 4 5 6 7 (8) (9)
s 4 3 4 5 6 7 8
deggk,s 11 13 21 31 43 57 73
time (sec) 0.19 0.29 0.60 2.8 24 235 1704 Though we can always divide out(1−T)k fromg
k,s the degrees are in all cases quite
high and the computations better done by a computer. The timings refer to our own (non-optimized) MuPad-program used to assert (4.15). As k = 3 is the only case that we do not cover otherwise we giveg3,4 here:
g3,4(T)/(1−T)3 =
1
12(1−T) + 5
6T+T(1−T)
481
96 (1−T)
2+35
24T
2+T(1
−T)
245
96 (1−T) + 103
24 T +T(1−T)
119
144(1−T)
2+ 89
144T
2+T(1−T)·407
288
With this description you can easily see that it is positive on[0,1[. Finally, we put together the upper bound oneλknorm, Lemma 4.5, Lemma 4.7, and Lemma 4.12 in the following theorem.
Theorem 4.16. For any k≥1 we have
e
λknormhξi ≤eck:=
( 1
αlnB if k >0,
1 if k= 0.
Assume αlnB ≥max ln2,lnk16. Then for any ε∈]0,1] withε≤k−ξk1 2
or k < 3
there is ac˘k >0such that for ξ ∈[ε, k−ε]
e
λknormhξi ≥ ˘ck αlnB.
Here we can choose
˘
ck=min
2−4·ε
k
k!, 2
−k· εk−1
(k−1)!
Note thatξk1 2
is the maximum ofeλknormwhich in our experiments is always less thenk− 1fork≥3. However, proving that would result in a stronger version of Lemma 4.12, which even in the given form required quite some effort. However, we just want that to work for some small εand that is always granted.
Proof. The upper bound being proven we consider the lower bound. First, keeping in mind that αlnB ≥ln2 andαlnB ≥ lnk16, we consider the cases k≥3. We know by Lemma 4.5 thateλk
normon[ε, k−ε]attains its minimal value at one of the boundaries
since ξk1 2 ∈
[ε, k −ε] (by assumption). We thus only need to consider its values at ξ=ε and atξ=k−ε.
On the left hand side Lemma 4.7 gives
αlnB·eλknormhεi ≥exp
− ln
24
αlnB
εk
k! ≥exp
−ln
24
ln2
εk
k! = 2 −4·εk
k!
using the conditions onαlnB.
On the right hand side by Lemma 4.12 we find
αlnB·eλknormhk−εi ≥(1−exp(−αlnB))k ε
k−1
(k−1)! ≥2
−k εk−1
(k−1)!
using again αlnB ≥ln2. This completes the proof for the casesk≥3.
We will now show corresponding lower bounds for the cases k= 1,2. For k= 1 we have forε∈]0,1] usingαlnB ≥ln2:
αlnB·λe1normhεi= 1−exp(−εαlnB)≥1−exp(−εln2). Using Fact 4.9 and ε≤1, we have
1−exp(−εln2)≥ 1−exp(−ln2) ln2 ε=
1 2ln2ε≥
1 2ε.
Fork= 2 we again apply Lemma 4.7 for the left hand side as in the general case. For the right hand side we show that
α2ln2B·λe2normh2−εi ≥
1− 1 2ln2
εαlnB
for0≤εαlnB ≤αlnB, ln2≤αlnB. Since 1−2ln12≥2−2 this proves the claim. Now, using Theorem 4.4 we write the left hand side minus the right hand side as f5(εαlnB, αlnB) withf5(τ, ϑ) =exp(τ −2ϑ)−2exp(τ −ϑ) +2ln21 τ + 1. We have
to show thatf5 is non-negative if0≤τ ≤ϑandϑ≥ln2. Theϑ-derivative of f5,
∂f5
is positive forϑ >0. Thus it suffices to show thatf5(τ, ϑ)≥0for the smallest allowed
ϑ, which is the larger ofτ and ln2. Ifτ ≥ln2then we considerf5(τ, τ) =exp(−τ) + 1
2ln2τ −1. This expression is increasing in this case (even for τ ≥ln2 +ln ln2) and
so it is greater than or equal tof5(ln2,ln2) = 0. If otherwise 0 ≤τ ≤ln2 then we
considerf5(τ,ln2) =−34exp(τ) +2ln12τ + 1which is decreasing even for τ ≥0 and
so it is greater than or equal tof5(ln2,ln2) = 0.
Summing up we obtain:
Corollary 4.17. For any ε ∈ ]0,1] and any k ≥ 1 we have uniformly for ξ ∈
[ε, k−ε]
e
λknormhξi ∈Θ
1
αlnB
.
5. Estimating the estimate bλk
The recurrence Lemma 3.6 for bλk is more complex than the one for eλk, so instead
of solving it we estimate it. We consider also here the normed version bλknormhξi :=
b
λkhξi
αkBk+ξα. To better understand how the error behaves we compute it for k= 1:
b
λ1normhξi=
0 if ξ∈]−∞,0[,
1+ξα
8πα lnB B12 +ξα2
+8πα1 lnB
B12 +ξα if ξ∈[0,1[,
1+α
8παB1lnB 2−α2 +ξα +
1 8παBln1B
2 +ξα if ξ∈[1,∞[.
From this we estimatebλ1
norm directly:
b
λ1normhξi ≤
0 if ξ ∈]−∞,0[,
(2+α)lnB
8πα B− 1+ξα
2 ifξ ∈[0,1[,
(1+α)lnB
8πα B− 1
2+α2−ξα+lnB
8πα·B− 1
2−ξα ifξ ∈[1,∞[.
We have also looked at precise expressions for largerk, yet they are huge and do not give rise to better bounds.
Theorem 5.1. Define values bck recursively by
b
ck:=bck−1+
4 + 3lnB
8πα√B (eck−1+bck−1)
for k≥3 based on bc0 := 0, bc1:= (2+8παα)√lnBB, and
b c2 :=
6 + 3α 8πα2
1
√
B +
4 + 3lnB
8πα√B (ec1+bc1)
= 9 + 3α 8πα2
1
√
B +
1
2πα2√BlnB +
Then for any kand ξ∈Rwe have
b
λknormhξi ≤bck
Ifα≥ ln√B
B we have for k≥2 and largeB the inequality
b ck≤
(2k−1)(1 +α) α2√B .
For k = 1 the order of bc1 is necessarily slightly larger. More precisely, we have for largeB that
b c1≤
(1 +α)lnB α√B .
Instead of definingbc2 and bc1 we could have left that to the recursion. But the given
values are smaller than the ones derived from the recursion based on bc0 only. For
k= 1 the recursion would give 4+3lnB
8πα√B. For k≥2 however the improvement due to
these explicit settings is a factor of order lnB.
Proof. We first show that the valuebckis bounded as claimed. Fork= 1the claim follows directly from the definition, since we have forB >exp(1)that(2 +α)lnB≤ 2(1 +α)lnB asα is positive. Fork= 2we have for ln2B ≤√B the inequality
b c2 =
6 + 3α 8πα2
1
√
B +
4 + 3lnB
8πα√B (ec1+bc1)
≤ 1 +α
α2√B +
1 α2√B +
(1 +α)ln2B α2B
≤ 3(1 +α)
α2√B .
Fork≥2we proceed inductively. We have b
ck=bck−1+
4 + 3lnB
8πα√B (eck−1+bck−1)
≤ (2
k−1−1)(1 +α)
α2√B +
lnB α√B
1 αlnB +
(2k−1−1)(1 +α) αlnB
= (2
k−1)(1 +α)
α2√B .
Now we prove the remaining estimate by induction onk. The casek= 0is true by definition ofλb0(with equality). Fork= 1the inspection above proves the claim. The
case. So assumek≥3. Using the definition of bλk from Lemma 3.6 we split bλk into three summands:
b
λknormhξi= Z 1
0
b
λknorm−1 hξ−̺i d̺
+2Eb(B) αB ·(eλ
k−1
norm+λbknorm−1 )hξi
+ Z 1
0
(eλknorm−1 +bλknorm−1 )hξ−̺iEb′(B1+̺α)lnB d̺ .
ForEb(x) = 81π√xlnx we calculate as a preparative 2Eb(B)
αB = lnB 4πα√B, (5.2)
Z 1
0
b
E′(B1+̺α)lnB d̺= 4 +lnB 8πα√B −
4 +lnC 8πα√C. (5.3)
The first summand of bλk
norm is at most bck−1 by induction hypothesis. The second
summand we estimate using (5.2) by lnB
4πα√B(eck−1+bck−1).
The third summand is bounded by
(eck−1+bck−1)
Z 1
0
b
E′(B1+̺α)lnB d̺ .
By (5.3) the third summand is at most 4 +lnB
8πα√B (eck−1+bck−1).
This completes the proof of the casek≥3: b
λknormhξi ≤bck−1+
lnB
4πα√B(eck−1+bck−1) +
4 +lnB
8πα√B (eck−1+bck−1) =bck.
prove. Forξ∈[0,1[we find for this first summand Z ξ
0
b
λ1normhξ−̺i d̺≤ Z ξ
0
(2 +α)lnB 8πα B−
1 2−
(ξ−̺)α 2 d̺ = (2 +α)lnB
8πα B
−1 2 B−
ξα 2
Z ξ
0
B̺α2 d̺
| {z }
=αln2B
1−B−ξα2
≤ 2 +α
4πα2√B.
Forξ∈[1,2]we find Z 1
0
b
λ1normhξ−̺i d̺≤ Z 1
ξ−1
(2 +α)lnB 8πα B−
1 2−
(ξ−̺)α 2 d̺ +
Z ξ−1
0
b
λ1normh1iB1+αB−(1+(ξ−̺)α) d̺
= (2 +α)lnB 8πα B−
1 2−
(ξ−1)α 2 B−
α 2
Z 1
ξ−1
B̺α2 d̺
| {z }
=αln2B
1−B−(2−2ξ)α
+λb1normh1iB−(ξ−1)α Z ξ−1
0
B̺α d̺
| {z }
=αln1B(1−B−(ξ−1)α)
≤ 2 +4παα2B−12− (ξ−1)α
2 + 1 +α 8πα2B−
1 2−
α 2 + 1
8πα2B−
1 2−α
≤ 6 + 3α
8πα2√B
As bλ1
norm decreases for ξ ≥ 1 this bound also holds for ξ ≥ 2. Putting everything
together the above defined valuebc2 boundsλb2normhξias claimed.
It is tempting to guess that we can save more lnB factors for larger k. How-ever, inspecting bλ2
norm shows that, say, bλ3norm
1
2
∈Ω√1
B
. (For ξ ∈[0,1[ we find b
λ2
normhξi= 4πα3√B+O
1
√
BlnB
.)
6. Reestimating λbk without Riemann
Fact 6.1. ◦ Forx >10 we have
|π(x)−Li(x)| ≤11.88x(lnx)35 exp
−571 (lnx)35(ln lnx)− 1 5
.
◦ There is a constantC and a frontier x0 such that for x > x0 we have
|π(x)−Li(x)| ≤C xexp−0.2098(lnx)35(ln lnx)−15
.
Admittedly, these bounds only start to be meaningful at large values of x (eg. the first statement around10159 299). All those bounds are of the form: For all x > x
0
|π(x)−Li(x)| ≤C x(lnx)c0exp −A(lnx)c1(ln lnx)−c2
| {z }
=:Eb(x)
holds. Here, C >0,x0 >0,c0 ∈R,c1 >0,c2 >0 and A >0 are given parameters
(which are not always known). Note that we have that b
E(x)/x
is decreasing for large x. Actually, with the parameter sets from Fact 6.1 this is already true forx≥5. Moreover, the quotient of the relative errors atx1+αand atx
b
E(x1+α)lnx1+α x1+α
b
E(x)lnxx =
(1 +α)Eb(x1+α) xαEb(x)
is bounded (or even tends to zero) with x → ∞ for any α > 0. This follows from b
E(x)/x decreasing when α is constant, but you may also consider values for α that increase when xgrows.
Revisiting the proof of Theorem 5.1 shows that only (5.2), (5.3), and the initial valuesbc1 andbc2 depend on the specific boundE. We now use the following recursionb
for the bounds: b
ck:=bck−1+
2Eb(B) αB +
Z 1
0
b
E′(B1+̺α)lnB d̺ !
| {z }
=:u
(eck−1+bck−1)
for k≥1 based on bc0 = 0, and possibly values forbc1 and bc2.
To bound u tightly the trickiest step is bounding the integral. As our interests lie elsewhere we take the easy way out. We integrate by parts and use that Eb(x)/x is decreasing for the following rough estimate
Z 1
0
b
E′(B1+̺α)lnB d̺= Eb(B
1+α)
αB1+α −
b E(B)
αB +lnB Z 1
0
b
E(B1+̺α)
B1+̺α d̺
| {z }
≤Eb(BB)
Thusu is bounded by
u≤ 1 + 1
αlnB 1 + b
E(B1+α) BαEb(B)
| {z }
bounded
!! b
E(B)lnB
B .
In the following we neglect the bounded term, as we can compensate its effect for example by a small additional factor. Since u is small for large B, we expect bck to
be dominated bybc1 =u. Precisely, for k >1 we havebck = (1 +u)bck−1+αlnuB, thus
b
ck= (1 +u)k−1u+
(1 +u)k−1−1 αlnB ∼
1 + k−1 αlnB
u.
Theorem 6.2. Assume that Eb(x) bounds |π(x)−Li(x)| and Eb(x)/x is decreasing
for x > x0 and the relative error decreases fast, ie.
b
E(x1+α)lnxx1+1+αα
b
E(x)lnxx =
(1 +α)Eb(x1+α)
xαEb(x)
is bounded under the chosen behavior ofα. Then for anyk≥2 andB large we have
b
λknormhξi ∈ O 1 + k−1
αlnB 1 + 1 αlnB
bE(B)lnB B
!
for k≥2.
This is close to optimal, we only loose a factor of order lnB in the relative error compared to the used error bound in the prime number theorem:
b λk
normhξi
e λk
normhξi
≤ 1 + k−1
αlnB
1 +αln1BEb(BB)lnB
˘
ck αlnB
∼ α
˘ ck
lnB·Eb(B)lnB
B .
The assumptions onEbalso hold for explicit error bounds withEb(x)∈ O x
lnℓx
. Due to the lost lnB the result is only meaningful if ℓ≥3, so Rosser & Schoenfeld (1962) does not suffice. From Dusart (1998) we can useEb(x) = 2.3854 x
ln3x for x >355 991,
and obtain
b
λknormhξi ∈ O 1
lnB