A Statistical Approach to Automatic OCR Error Correction in Context
13
0
0
Full text
Figure
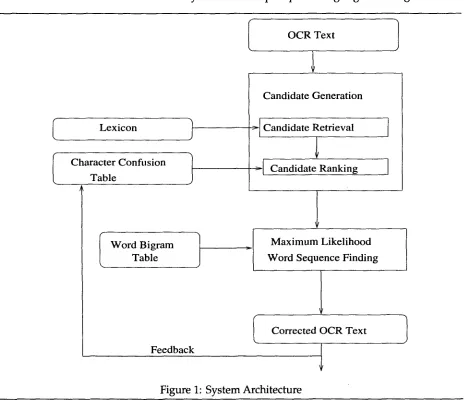


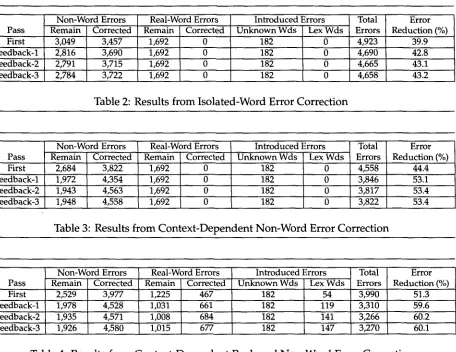
Related documents
200008 coling bckim dvi Decision Tree based Error Correction for Statistical Phrase Break Prediction in Korean ? Byeongchang Kim and Geunbae Lee Department of Computer Science &
Spelling Correction Using Context Spelling Correction Using Context* Mohammad All Elmi and Martha Evens Department o f Computer Science, Illinois Institute o f Technology 10 West 31
A STATISTICAL APPROACH TO LANGUAGE TRANSLATION A S T A T I S T I C A L A P P R O A C H T O L A N G U A G E T R A N S L A T I O N P B R O W N , J C O C K E , S D E L I , A P I E T R A , V
A HYBRID APPROACH TO ADAPTIVE STATISTICAL LANGUAGE MODELING A HYBRID APPROACH TO ADAPTIVE STATISTICAL LANGUAGE MODELING Ronald Rosenfeld School of Computer Science C a r n e g i e M e l l
(a) In order to train the error models used in post-correction, we ran the best OCR models on their respective training data sets and aligned the output with the cor- responding
We build a grammatical error correction (GEC) system primarily based on the state-of-the-art statistical machine transla- tion (SMT) approach, using task-specific features and
Extracting a Chinese Learner Corpus from the Web: Grammatical Error Correction for Learning Chinese as a Foreign Language with Statistical Machine
In This paper, we describe our system for auto- matic Arabic error correction shared task (QALB- 2014 Shared Task on Automatic Correction of Ara- bic) as part of the Arabic NLP
