System-Level Heterogeneity
with Intel
®
Xeon Phi
TM
Processors
Estela Suarez
Jülich Supercomputing Centre
This project has received funding from the European Union's Seventh Framework Programme for research, technological development and demonstration under grant agreements 287530 (DEEP) and 610476 (DEEP-ER).
Collaborative R&D in DEEP & DEEP-ER
European Union
Exascale projects
20 partners
Total budget: 28.3 M€
EU-funding: 14.5 M€
Combined term: 5 years
Visit us @ ISC 2016, Frankfurt
(Germany)
June 19 – 23, 2016
Booth #1340
DEEP/-ER Approach
Co-design between applications, system SW and HW
– Application and operational requirements do shape system architecture
– HW provides performance, scalability and energy efficiency
– System SW enables applications to leverage HW potential
Objectives
– Deliver highest scalability and workload performance
– Provide leading energy efficiency (energy per result)
– Offer familiar, easy to use programming environment and APIs based on standards
– Ensure sustainability of system architecture and SW
Design elements
– Exploit benefits of processor heterogeneity
– Leverage technology advances in storage-class memory and interconnects
Co-Design Applications
DEEP + DEEP-ER applications
• Brain simulation (EPFL)
• Space weather simulation (KULeuven)
• Climate simulation (CYI)
• Computational fluid engineering (CERFACS)
• High temperature superconductivity (CINECA)
• Seismic imaging (CGG)
• Human exposure to electromagnetic fields (INRIA)
• Geoscience (BADW-LRZ)
• Radio astronomy (Astron)
• Oil exploration (BSC)
• Lattice QCD (UREG)
Goals
• Drive co-design cycle
System-Level Heterogeneity
DEEP-ER – ISC 2016, Intel Booth – 21.06.2016 5
Accelerated Cluster
Cluster-Booster Architecture
– Fixed, static ratio and assignment of
accelerators to CPUs
– Static management of resources
– Accelerators do not act autonomously
– General-purpose Cluster interconnect
– Programming via local offload interfaces
(OpenCL, CUDA, CELO, OpenACC, …)
– No fixed ratio or assignment between
resources (Multicore & Manycore nodes)
– Dynamic management and association
of resources
– High-throughput network in the Booster
– Programming via MPI and “global”
DEEP System Architecture
Cluster part
– High single thread & complex code
performance
Intel
®Xeon
®processors
– High any-to-any connection
performance & infrastructure
integration
standard switched
HPC fabric (InfiniBand
TM)
Booster part
– High throughput, autonomous
operation
Intel Xeon Phi
coprocessor (codenamed
“Knights Corner”)
– Need for low latency, spatial
application structures
3D Torus direct-connected
network (EXTOLL)
– Network bridging and KNC control
Booster Interface layer
Both parts
– Efficiency needs
use of liquid cooling
& dense packaging
DEEP Prototype Systems
Eurotech Aurora Prototype
DEEP-ER – ISC 2016, Intel Booth – 21.06.2016 7
Cluster part
128 dual-socket
Intel Xeon E5-2403
nodes
QDR InfiniBand
TM
Eurotech Aurora
liquid cooling &
packaging
Booster part
384 Intel Xeon Phi
7120X nodes
FPGA
implementation of
EXTOLL
interconnect
24 Booster interface
nodes with Intel
Xeon processor
Eurotech Aurora
liquid cooling &
packaging
Cluster
DEEP/DEEP-ER Programming Model
ParaStation Global MPI layer
Expert-level programming
Efficient communication across the whole system
Dynamic process spawning an control in both
directions
Task-based OmpSs programming model
Pragma based, emphasizes ease of use
Efficient communication across the whole system
Dynamic spawning of massively parallel tasks in
both parts
Massively Parallel Tasks in OmpSs
DEEP-ER – ISC 2016, Intel Booth – 21.06.2016 9
Published in: Sainz, F, Bellón, J, Beltran, V, Labarta, J, “Collective Offload for Heterogeneous Clusters”, IEEE 22nd International Conference on High Performance
Computing (HiPC), 2015 Rank 0 master Rank 0-15 slave0 Rank 0 WorkerRank 1 WorkerRank 2 WorkerRank 3 wk63 Rank 16-31 slave1 Rank 0 WorkerRank 1 WorkerRank 2 WorkerRank 3 wk127 Rank 240-255 slave15 Rank 0 WorkerRank 1 WorkerRank 2 WorkerRank 3 wk1023 x16 x16 x16
Figure 7: FWI hierarchical MPI architecture
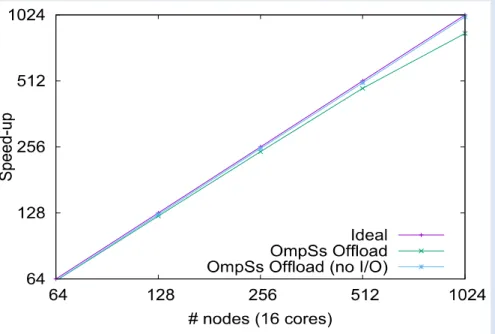
64 128 256 512 1024 64 128 256 512 1024 S p e e d -u p # nodes (16 cores) Ideal OmpSs Offload OmpSs Offload (no I/O)
Figure 8: Scalability of FWI application on up to 1024 nodes
VI. Concl usions and f ut ur e wor k
This paper presents the OmpSs O
✏
oad model that was
originally developed to ease the porting of complex
ap-plications to the highly heterogeneous cluster architecture
proposed on the DEEP Exascale project. The OmpSs O
✏
oad
model has completely
fulfilled its design goals, combining
the ease of use of Intel O
✏
oad with the
flexibility,
per-formance and scalability of the native
MPI
Comm spawn
API. Moreover, our approach is fully integrated with the
rest of features provided by OmpSs, such as support for
OpenMP codes and CUDA or OpenCL kernels. Although
it was originally conceived for heterogeneous clusters we
have also successfully used it to develop hierarchical MPI
applications such as FWI. We think that these hierarchical
MPI architectures will play an important role in exploiting
future Exascale systems. Hence, tools such as OmpSs
Of-fload will be essential for designing such architectures and
helping with their implementation for complex and large
applications.
As future work, we plan to integrate our allocation API
with a resource manager/job scheduler to avoid the need
to reserve all the resources that will be required before
the program is launched. We also plan to investigate the
potential of OmpSs O
✏
oad to improve the malleability of
existing MPI applications, as well as the implications of
using this o
✏
oad model from the resilience point of view.
Ref er ences
[1] D. A. Mallon, N. Eicker, M. E. Innocenti, G. Lapenta, T. Lip-pert, and E. Suarez, “ On the scalability of the clusters-booster concept: a critical assessment of the DEEP architecture,” in
Proceedings of the Future HPC Systems: the Challenges of Power-Constrained Performance. ACM, 2012, p. 3.
[2] A. Duran, E. Ayguad´e, R. M. Badia, J. Labarta, L. Martinell, X. Martorell, and J. Planas, “ OmpSs: a proposal for pro-gramming heterogeneous multi-core architectures,” Parallel Processing Letters, vol. 21, no. 02, pp. 173–193, 2011. [3] K. O. W. Group et al., “ The OpenCL specification,” A.
Munshi, Ed, 2008.
[4] C. Nvidia, “ Compute Unified Device Architecture program-ming guide,” 2007.
[5] C. J. Newburn, R. Deodhar, S. Dmitriev, R. Murty, R. Narayanaswamy, J. Wiegert, F. Chinchilla, and R. McGuire, “ O✏oad compiler runtime for the Intel R
Xeon Phi R coprocessor,” in Supercomputing. Springer,
2013, pp. 239–254.
[6] “ OpenMP 4.0 specification,” http://www.openmp.org/mp-documents/OpenMP4.0.0.pdf, 2013, [Online; accessed 20-Dec-2013].
[7] O. W. Groupet al., “ The OpenACC application programming interface,” 2011.
[8] F. Sainz, S. Mateo, V. Beltran, J. L. Bosque, X. Martorell, and E. Ayguad´e, “ Leveraging OmpSs to exploit hardware accelerators,” in 26th IEEE International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD 2014, Paris, France, October 22-24, 2014. IEEE, 2014, pp. 112–119. [Online]. Available: http: //dx.doi.org/10.1109/SBAC-PAD.2014.26
[9] J. Duato, A. J. Pena, F. Silla, R. Mayo, and E. S. Quintana-Orti, “ rCUDA: Reducing the number of GPU-based accel-erators in high performance clusters,” in High Performance Computing and Simulation (HPCS), 2010 International Con-ference on. IEEE, 2010, pp. 224–231.
[10] A. Barak and A. Shiloh, “ The mosix Virtual OpenCLl (VCL) cluster platform,” in Proc. Intel European Research and Innovation Conference, 2011.
[11] F. Sainz and V. Beltran. (2015) OmpSs Collective O✏oad. User Manual. [Online]. Available: http://pm.bsc.es/ ompss- docs/user-guide/run-programs- archs-o✏oad.html
From DEEP to DEEP-ER
Simplified Interconnect
On-Node NVM
Self-Booting Nodes
Network attached
memory
DEEP-ER Scalable I/O
Leverage presence of fast local
NVM storage
– Scalable caching of read/write data
close to requesting node
– Prefetching stages read data into
caches
– Write-back scheme saves data to
permanent storage
– Synchronous (done) and
asynchronous (WIP) versions/APIs
BSC Full Waveform Inversion
Results
Using 60 cores per Xeon Phi coprocessor node with 180 threads
0
2
4
6
8
10
12
0
20
40
60
80
100
120
140
160
Speed
u
p
Gfl
o
p
s/s
Impact of different optimizations of
wave propagator on Xeon Phi
Gflops/s
speedup
INRIA MAXW-DGTD Results
0
1
2
3
4
16
64
256
1024
Speed
up ov
er
in
it
ia
l v
er
si
on
# of cores
Before
After
0.50
0.75
1.00
1.25
1.50
16
64
256
1024
P
ar
al
le
l E
ffic
ie
ncy
# of cores
Before
After
Improvements applied below
:
• Non-blocking communication
• Renumbering scheme
• Vectorisation and locality
Performance improvement up to 3.3x
Almost perfect parallel efficiency now
Setup:
- Human head - DEEP Cluster
- Mesh: 1.8 million cells - 16 processes per node - Pure MPI.