Argus: A Multi-tenancy NoSQL Store with Workload-Aware Resource Reservation
(Preprint Version)
Jiaan Zeng, Beth Plale
School of Informatics and Computing, Indiana University Bloomington, Indiana 47408
Abstract
Multi-tenancy in cloud hosted NoSQL data stores is favored by cloud providers as it allows more effective resource sharing amongst different tenants thus lowering operating costs. A NoSQL provider will often present to each tenant a dedicated view of the store but then behind the scenes consolidate tenant access into a shared instance. This multi-tenancy approach with tenant data and workloads coexisting in the same infrastructure, under certain conditions can lead to performance degradation of one tenant caused by another as we show experimentally. This paper introduces Argus, a NoSQL store equipped with resource reservation to prevent performance interference across tenants in a multi-tenancy environment. Cache reservation is enforced through partitioning the cache space and disk reservation enforced through scheduling requests to a Distributed File System (DFS). We model the reservation on various workloads as a constrained optimization problem and use the stochastic hill climbing algorithm to find a near-optimum plan for different resource reservations. Empirical results show that Argus is able to prevent interference, adapt to dynamic workloads, and outperform A-Cache, another interference preventing NoSQL solution.
1. Introduction
NoSQL data stores see a great deal of usage today: managing large streams of non-transactional data, fast key-value access, big data analysis in MapReduce, etc. [1]. NoSQL data stores are hosted in a public cloud environment to offer a database-as-a-service to consumers. In the database-as-a-service model, a user (or tenant) claims a workspacee.g. a table, stores data to the space, and runs workloads within its workspace. From a tenant’s point of view, the resource is dedicated and exclusive, and as such should offer predictable performance. However, for economic reasons a cloud provider will consolidate tenant workspaces into as small an infrastructure as possible to maximize resource utilization meaning that the same cloud storage infrastructure is shared by multiple tenants. But as we show for HBase, a shared infrastructure under multi-tenancy can exhibit resource contention across tenants, and hence variable performance for an individual tenant. That is, an ill-behaved tenant can consume a well-behaved tenant’s resources and degrade the latter’s performance. This interfering behavior in multi-tenancy is undesirable.
Resource reservation is a common approach to avoiding performance interference among tenants. Intuitively, the idea is to dedicate a portion of a resource to a tenant for the duration of their use. As workloads often utilize multiple resources simultaneously
e.g.CPU for serialization/deserialization, memory for caching, disk for reading/writing data; a tenant needs to acquire a reservation for each resource. But the reservation need depends on the workload: a workload that has a hotspot access pattern to disk may require more cache than does a workload with a random access pattern of access. An equal reservation of cache and disk usage for both workloads will not yield the best result. So reservations must be based on characteristics of the workload; this is called workload-aware reservation.
Other approaches to preventing performance interference simplify the scenario either by dealing with only a single resource [2, 3, 4, 5] (e.g.CPU, cache), or by representing consumption of multiple resources as single “virtual resource” consumption [6, 7]. Ignoring the multiple resource demands that a workload could place on a data store could lead to low resource utilization of the store as the system imposes unnecessary constraints on tenants. It could additionally lead to failure to prevent interference as the system only considers a single resource.
We propose Argus1, a workload-aware resource reservation NoSQL store. Argus aims to prevent performance interference in
terms of fair throughput violation for multi-resource reservations in multi-tenancy cloud environments. Specifically, Argus enforces reservation on the cache and disk resources. It models the workload-aware reservation as a constrained optimization problem and uses stochastic hill climbing to find the proper reservation according to the workload resource demands.
This paper extends our earlier work, [8], in several dimensions. While the earlier work proposes a resource reservation frame-work and carries out a preliminary evaluation to show its effectiveness in terms of performance isolation, the contributions of this paper are a full evaluation of Argus’ behaviors in different situations. We study the performance impact of different request scheduling approaches for the disk reservation with detailed discussions. We carry out an empirical study to understand the trade-off between providing fairness and maintaining efficiency for disk reservation, and follow up with discussions about dynamic credit setting. We extend the elastic reservation approach which can adjust the cache and disk resource reservation proportionally based on request rates and reallocate accordingly. We implement A-Cache, another interference prevention system, and compare its per-formance to Argus. We run the workloads with more tenants involved against Argus to examine its stability of isolation. We also discuss possible extensions that Argus can take to overcome some of its limitations.
The remainder of the paper is organized as follows. Section 2 summarizes related work, followed by an overall architecture description in Section 3. Section 4 presents the mechanisms of resource reservation enforcement, while Section 5 describes the details of reservation planning. Extensive performance evaluation and discussion appear in Section 6. Section 7 discusses potential applications over Argus. Finally, we conclude with future work.
2. Related Work
Multi-tenancy can be realized in three different models: a shared table model, shared process model and shared machine model[9]. The shared process model has multiple tenants sharing the same service process, (versus sharing the same tables or same VMs). The shared process model is usually preferred as it trades a small amount of tenant isolation for better performance and scale. The study in [10] shows that isolation through virtual machines (VM) yields lower performance compared to the shared process model. A majority of current research in multi-tenance [5, 11, 12, 4, 7] focuses on the shared process model which our work targets as well.
For file system sharing, Wachs et al. [11] uses a time-quanta-based disk scheduling approach with cache space partitioning for performance insulation among applications running on a single file server. We adopt the idea of partitioning the cache and disk for tenants but coordinate the partitioning over these two resources through a constraint optimization model rather than treating the resource independently. In addition, we focus on a distributed store which is more complicated than a single node server. Due to the complexity, the underlying storage system is sometimes treated as a black box as responses coming out from it vary in several aspects e.g. latency, size, etc. Gulati et al. [13] use a feedback-based approach on a black-box storage system to dynamically adjust the number of IOs issued to the storage system with observed latency as feedback. We employ feedback-based scheduling, but model all the tenant behaviors in a unified constraint optimization problem and globally adjust the scheduling parameters instead of having separate adjustment per tenant.
For multi-tenancy in relational databases, Narasayya et al. SQLVM propose resource reservation on CPU, I/O and memory for tenant performance isolation and focus on I/O scheduling. Das et al. [4] present a CPU scheduling approach in SQLVM to reserve CPU usage for CPU interference prevention. While our approach uses resource reservation as well, we target multiple resources as a whole instead of treating them individually, because various resources may not be entirely independent. With regard to multiple resources, Soundararajan et al. [14] proposes a multi-resource allocator to dynamically partition the database’s cache and its storage bandwidth so as to minimize request latency for all the tenants. However, different from [14], we provide fairness across tenants. Additionally, we attempt the partitioning in a distributed NoSQL store with hierarchical architecture instead of a monolithic RDBMS. Walraven et al. [3] utilize a central scheduler to dispatch requests to different back-end RDBMS in a multi-tier web application. Our work relies on each node to enforce the resource reservation instead of a central scheduler.
For NoSQL data store, Pisces [6] uses partition placement, replica selection, and fair queuing to provide multi-tenant fair share in terms of throughput in Membase, a memory-based NoSQL store with hash partitioning. Like Pisces, our work targets system-wide fair share. In addition, we also adapt the deficit round robin algorithm [15] for scheduling. Unlike Pisces, our target storage abstraction has disk, memory and network resources involved, and is much more complicated than the memory-based store Pisces uses. Also unlike Pisces, our approach distinguishes different resource demands from different workloads. A-Cache [5]
divides the block cache space in HBase and limits a tenant’s cache activities within the cache space it is assigned to resolve the cache interference among tenants. Our earlier work, Zeng et al. [7] provide fair share (of throughput) in Cassandra using request scheduling and adaptive control approaches. Argus differs in that it identifies cache and disk usage, and dynamically adjusts the reservation on both resources according to workload resource demands. In our analysis, both the throughput regulation [6, 7] and the cache partition approach [5] fail to prevent interference in cases where tenants’ workloads have different resource demands.
The open source community is addressing performance isolation for multi-tenancy in HBase [16, 17], though the work is still in progress as of submission of this manuscript, and not yet merged to the trunk yet [17]. Our work in HBase can shed some light on future development of multi-tenancy support.
3. Architecture
As shown repeatedly [5, 6, 7], multi-tenant performance interference does exist in NoSQL stores. Results in [7] show that 1) a tenant’s number of threads and data access pattern cause performance interference; 2) interference could occur in different resources e.g., cache, disk, or both. 3) resource reservation approaches considering only single resource i.e, bytes delivered and cache usage, may fail in some cases. These results motivate us to develop a workload-aware reservation approach that can handle multiple resources.
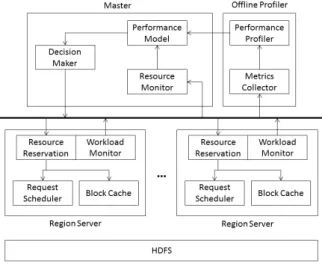
Argus is a workload-aware resource reservation framework designed to prevent performance interference across tenants. It is built on HBase’s master-slave architecture with HDFS as its underlying storage system (see Figure 1). Thus HBase can be viewed as a two-level hierarchy storage system with a clean separation between different resource management strategies at different levels: HDFS manages the disk resource while HBase servers manage caching and CPU usage. We take advantage of HBase’s level design and break down a request’s resource consumption into the usage of cache and disk since simple key-value pair access is usually not CPU intensive. The cache usage is measured as the cache occupancy i.e., the ratio between current cache size a tenant takes to the total cache size. The disk usage is difficult to be directly measured and thus approximated by HDFS throughput.
Figure 1: Architecture.
In Argus, the master node collects the resource information from RegionServers to make informed resource reservation decision-s. It has three components: 1) resource monitor that aggregates workload information from all the RegionServers; 2) performance model that takes workload information and estimates performance; 3) decision maker that takes advantage of the performance model to find an optimum resource reservation policy and sends it to all the RegionServers. The performance model relies on an offline profiler that uses linear interpolation to predict the performance. For the RegionServer, it serves as an executer to enforce the reservation plans of the Master. The disk access is approximated by HDFS throughput and controlled by the request scheduler. The block cache shipped with vanilla HBase is made reservation-aware to support cache reservation as well.
To simulate multi-tenant access, we use the Yahoo Cloud Storage Benchmark (YCSB) [18] to generate different workloads for different tenants. We define and name several workloads with different access patterns below to test HBase in a multi-tenant setting. Each Get request fetches one row per request.
1. Uniform: Series of Get requests that retrieve any data with equal probability from the table.
2. Extreme Hotspot (ExHot): Series of Get requests that retrieve a small portion of the data in the table. The requested data is
small enough to fit into cache entirely.
3. Regular Hotspot (Hot): Shows hotspot pattern but the data requested cannot fit into cache entirely.
4. Resource Reservation
For a given resource reservation policy, it is critical to enforce the resource reservation in each node as it provides the basis for cluster-wide resource reservation. In this paper, we focus on two resource reservations: block cache and disk, both of which will be discussed in the following sections. In addition, we present an elastic reservation approach that can dynamically adjust the reservation to handle the case where some tenants do not use up their reservations.
4.1. Block Cache Reservation
Cache reservation is used to provide strong isolation in the cache for tenants. In Argus, we divide the entire block cache into partitions and limit a tenant’s cache activities to the cache partition to which it is assigned. Unlike A-Cache [5] which replaces HBase’s default cache replacement, we apply the built-in LRU cache replacement in HBase to the cache partition of each tenant because the cache replacement in HBase has been improved to prioritize the eviction based on the times the blocks are reused. Although strict cache reservation can provide strong isolation, it can result in poor cache utilization if some tenants do not fully utilize the reserved resource. We discuss details and present the solutions in Section 4.3 and 5.
4.2. Disk Reservation
We use the HDFS throughput to approximate the disk usage for simplicity. We design a request scheduler in the RegionServer instead of in the HDFS to regulate throughput. Because many of the file systems including HDFS are not designed with multi-tenancy in mind: multi-multi-tenancy enforcement is carried out by the application built on top of the file system. People have done extensive work on fair share scheduling. Generalized processor sharing (GPS) is an idealized scheduler which assumes tenant traffic is fluid and achieves perfect fairness [19]. However, in real world scenarios, schedulers can only approximate the behavior of GPS due to the discretization nature of a computer [19]. In general, there are two categories of approximation: virtual time-based approximation and quanta-based approximation. To understand which approach may work well in the context of multi-tenancy in HBase, we study the Weighted Fair Queuing (WFQ) [19], which is a virtual time-based scheduler, and the deficit round robin (DRR) [15], which is a quanta-based scheduler. We experimentally compare these scheduling approaches in terms of fairness and efficiency in the next section.
4.2.1. Request Scheduling Approaches
Each tenant is assigned a queue to hold its requests. WFQ schedules requests among queues according to their finish time. To lower the computation cost of estimating request time, the notion of virtual time is used to order requests. Each request is tagged with a virtual start time and a virtual finish time. [20, 21] outlines the calculation of virtual start time and finish time. The estimate assumes a linear relationship between request length and virtual time. In each scheduling round, WFQ picks the request with the smallest virtual finish time to run. The complexity of WFQ in each scheduling round isO(log(n)) as it needs to select the request with the smallest virtual finish time fromnqueues in a min-heap.
DRR is a variant of weighted round robin [22] that uses quanta (sometimes called tokens or credits) to throttle requests. DRR associates each tenant with a credit account. To schedule a request, the scheduler takes some credits offfrom the tenant’s account according to the size of the request. Eventually a tenant’s credit account will exhaust and need to be refilled. There are two refill strategies: refill the accounts periodically; refill when tenants are either exhausted i.e., not enough credits or inactive i.e., no pending requests. Periodical refill can improve utilization as it does not need to wait until other tenants meet the refill criterions.
4.2.2. WFQ vs. DRR
The goal of the reservation is to enforce fair share across tenants while not sacrificing too much efficiency. In this section, we experimentally evaluate WFQ and DRR in terms of fairness and efficiency in the context of disk throughput reservation. Both WFQ and DRR need adaption. For WFQ, it requires the knowledge of a request size to estimate the virtual finish time but the size is unknown till the request has been serviced. Scheduling after requests are serviced may prevent the scheduler from enforcing fairness as resources have been consumed [6]. Therefore, we use a sliding window approach to predict the request size. Specifically,
the current request size is predicted as an average over a sliding window, which has the last few previous request sizes. Such an prediction is also used in DRR. [2] discusses more advanced prediction options. For the DRR prototype, it interprets the credits as the number of bytes read from or written to HDFS. It assumes there is a linear function that can translate the credits to the underlying resources usage, mainly disk access, in HDFS.
As mentioned in Section 3, we use YCSB to simulate workloads with two tenants. One YCSB client uses 50 threads while the other one uses 200. Both use the uniform read-only workload. The target throughput is set as a large number to allow the client to send as many requests as possible. Since we focus on disk throughput, we disable the block cache in HBase to eliminate its impact. Similar to Das et al. [4], to quantify fairness, we use theJain index (J-index) defined in equation 1 whereviis the throughput
violation of tenantiand can be expressed asvi=(bi−ti)/bi. biis the baseline throughput andtiis the observed throughput. The
baseline is established when the workload is run in a dedicated cluster. In addition to fairness, we consider efficiency which we define as the average of throughput violation for all tenants in equation 2. A larger value of J-index and E indicates better fairness and higher efficiency respectively.
J= ( ∑ 1≤i≤nvi)2 n×∑1≤i≤nv2i (1) E=1− ∑ 1≤i≤nvi n (2)
The size of sliding window for request size prediction is set to 10, i.e., the last 10 request sizes are preserved. In DRR, each tenant is given 25 million credits initially and its account is refilled every 2 seconds. Table 1 summaries the values of the J-index and E for WFQ, DRR and a no-scheduling approach. For fairness, the no scheduling approach yields the worst fairness (lowest J-index), which matches our expectation as the tenant with a higher thread count has a bigger chance to compete resources with the other tenant. The J-index of DRR is 13% higher than WFQ’s. It indicates tenants experience less throughput violation under DRR. Therefore, DRR achieves better fairness than WFQ. We think the reasons are three folds. First, WFQ assumes requests with the same size take the same time to be processed which does not hold in our experiments. In fact, we observe a large time variant for requests with the same size. Requests that should be throttled may still be picked by the scheduler to service because of the incorrect estimate. [14] also evidences that such a variant in a single node file system setting leads to failure of fairness enforcement. Second, unlike DRR which can offset the estimate error by credit refund, WFQ does not have such a mechanism to adapt to estimate errors. Third, DRR regulates throughput by enforcing bytes delivered to or from HDFS in a short period (i.e., 2 seconds in the prototype). Thus it can yield a “flat” throughput for different tenants and achieve good fairness. Although DRR achieves the best fairness, its efficiency is the worst among the three approaches because the “flat” throughput is based on the sacrifice of efficiency. A tenant’s throughput may be unnecessarily throttled if the number of credits is set too low. But if the credits are set too high, DRR may behave like the no-scheduling approach as nothing regulates the requests. We experimentally evaluate the impact of credits to DRR in Section 6.1 to better understand its behavior. For efficiency, it is our expectation that the no-scheduling approach has the highest efficiency because no regulation is imposed in the system. Both WFQ and DRR introduce scheduling overheads, and thus have lower efficiency value. They yield similar efficiency numbers, although WFQ’s is a little bit higher.
Table 1: Comparison of scheduling approaches.
Metric NoSchedule WFQ DRR
J-Index 0.708 0.874 0.996
Efficiency 0.513 0.493 0.481
In summary, DRR can achieve better fairness than WFQ does because WFQ is very sensitive to the correctness virtual time estimate. A better virtual time estimate approach rather than the request size based approach may improve WFQ’s fairness. DRR trades fairness with efficiency. Its fairness and efficiency highly depend on the credits assigned. In the rest of the paper, we focus on the usage of DRR because it can achieve good fairness and efficiency in a simpler way than WFQ.
To integrate the block cache into DRR, we introduce a refund procedure that refunds credits later if the request can be served from cache. The refund procedure can also refund positive credits if the amount of bytes is overestimated or negative credits if it is underestimated. Algorithm 1 describes the adaption of DRR. TheScheduleprocedure runs in the background to schedule requests from different tenants’ queues in a round robin fashion. TheRefundprocedure is invoked when a request finishes.
Algorithm 1Request Scheduling Algorithm
1: crediti: current credits in tenanti’s credit account
2: esti: estimate of bytes request reads from or written to HDFS for tenanti
3: actuali: actual bytes request reads from or written to HDFS for tenanti
4: procedureSchedule 5: foreach tenantido
6: esti←BytesEstimation(tenanti)
7: whilecrediti≥estiand tenanti’s queue is not emptydo
8: crediti←crediti−esti
9: esti←BytesEstimation(tenanti)
10: end while
11: end for
12: end procedure
13: procedureRefund
14: ifrequest is served from cachethen
15: creditsi←crediti+esti
16: else
17: creditsi←crediti+(esti−actuali)
18: end if
19: end procedure
4.3. Elastic Reservation
Because both cache and disk reservation are applied statically without any elasticity, they would result in inefficient system usage if some tenants did not use up their resource reserved. There are two cases when a tenant may not use up its reservation. One is due to a tenant’s access pattern. For example, a random access workload does not need cache very much, neither does a hotspot workload need disk resource. Holding cache for random access workload or disk for hotspot workload will lead to resource idleness. Therefore, reservation has to consider workload resource demands. We will present the solution of workload-aware reservation in Section 5. The other one is when a tenant slows down its throughput (called slow tenants). To deal with such a situation, we redistribute the resource. Specifically, redundant resources from the slow tenants will be taken away and distributed evenly among tenants that are in need. [8] presents a preliminary algorithm that only redistributes credits for disk resource regulation. This paper refines the algorithm and takes cache as well as disk into account.
Algorithm 2 describes the process. It runs periodically (every 2 seconds in the current prototype) to refill tenant credit accounts and adjust cache allocation. To detect if a tenant slows down, we establish an expected throughput as a reference (line 9). We obtain the baseline throughput by running the workload delicately. Then the expected throughput is calculated by dividing the baseline throughput with the number of tenants. To quantify the cache size and number of credits need to be adjusted, we assume both the cache size and credit number reserved are linear to a tenant’s throughput. In the current prototype, 10% of a slow tenant’s cache and credits will be taken away and redistributed to other tenants in need (line 10). Busy tenants will share the redundant cache and credits evenly (line 11).
In practice, to deal with the case where a slow tenant may bump up its throughput later, we allow slow tenants to retain the t same amount credits they have before the credit redistribution even they may not need them. The cache reservation is reset periodically (2 minutes in the current prototype) and runs with equal reservation for a short period (30 seconds in the current prototype) so as to give slow tenants a chance to increase the throughput. A more accurate way of detecting slow tenants as well as reallocating cache and credits among tenants is in the future work.
5. Reservation Planning
The elastic reservation described in Section 4.3 adjusts the reservation in a monotonic way; it is not suitable to handle the case where tenants have different resource demands. Because resource usage is not independent, (e.g., increasing cache allocation may decrease the disk usage and vice versa,) a reservation of this kind requires a model that reflects the dependency between
Algorithm 2Elastic Reservation Algorithm
1: cachei: cache reservation for tenanti
2: creditsi: disk reservation for tenanti
3: eti: tenanti’s expected throughput
4: ti: tenanti’s actual throughput
5: takei: percentage of resources taken away from tenanti
6: threshold: threshold indicating a slow tenant
7: procedureRefill 8: foreach tenantido
9: if(eti−ti)/eti>thresholdthen
10: Take awaytakeiofcacheiandcreditsi
11: Redistribute to tenants in need.
12: else
13: Retain previouscacheiandcreditsi.
14: end if
15: end for
16: end procedure
different resources. In this section, we discuss the reservation planning used to decide how much resource to reserve for each tenant according to its demands dynamically.
5.1. Problem Formalization
As shown in [7], setting the reservation evenly among tenants may not fully utilize the resources. For example, in the case of multiple uniform workloads, it is better to reserve resources equally among tenants. While in the case of uniform workloads mixed with extreme hotspot workloads, it is better to reserve more cache space for extreme hotspot workloads and more HDFS throughput for uniform workloads.
The resource reservation planning in Argus is done by the decision maker in the master node. In the following discussion, we first formalize the decision problem, and then present a solution based on the hill climbing algorithm and offline training models. Notations in Table 2 are used for discussion.
Table 2: Notations.
Notations Description
n Number of tenants
m Number of resources
bi Baseline throughput for tenanti
ti Actual throughput for tenanti
vi Throughput violation for tenanti
ri j Amount of resourcejreserved for tenanti
Mj Total amount of resource j
The goal of the reservation planning is to let tenants have fairness in terms of throughput violation and keep the efficiency as much as possible. We use equation 1 to describe fairness and equation 2 to represent efficiency. We need to maximizeJto achieve similar throughput violation among tenants as well asE to improve efficiency. Combining equation 1 and 2, we can express the optimization objective in 3.
D=α×J+(1−α)×E (3)
whereαis a variable between 0 and 1. It indicates how much impactJandE have in the decision procedure. In the current prototype, we set it to 0.5. Dis the objective that the decision maker needs to maximize. With the baseline throughput and resources
reserved, we express the resource reservation planning problem as a constrained optimization below. max D s.t. ∑ 1≤i≤n ri j=Mj vi=(bi−fi(ri1, . . . ,rim))/bi i=1,2, . . . ,n j=1,2, . . . ,m (4)
wherefiis the performance function that represents the throughput for tenanti’s workload, given a set of resource reservations
(ri1, . . . ,rim). The solution for the above problem is a list of resource reservations (ri1, . . . ,rim) for each tenant that maximizes the
value ofD. In this paper, we only consider cache and HDFS throughput. So there are two resources in equation 4, i.e.,m=2.
5.2. Solution
Solving the problem above requires the knowledge of various performance functions. Instead of inferring an analytic form of the function, which is difficult and error prone [14], we simply use regression to interpolate the function on some sample data collected by running the workload offline with different cache and HDFS throughput reservation percentages. The profiler in Figure 1 conducts the interpolation and generates the performance function. The key repeat ratio is used to characterise a workload and calculated as the number of keys repeatedly accessed divided by the total keys accessed within a certain period. For an incoming workload, Argus associates it with a performance function which has the closest key repeat ratio to the workload. If a workload changes its access pattern, say from uniform to hotspot, the decision maker is able to detect the change and adjust the performance function associated to the workload accordingly. The resource reservation may be changed consequently.
To find an optimum solution for equation 4, we use the stochastic hill climbing algorithm to search the feasible space. The basic idea is to let the search algorithm start from a potential solution point and pick a neighbor according to the probability distribution of all the neighbors. The distribution is based on the evaluated value of each neighbor state. Since the search space is infinite as both cache size and HDFS throughput are continuous variables, we discretize them into 20 equal pieces, i.e. the basic unit of share is 0.05 given the entire share is 1.0. Notice that the number of pieces must be larger than the number of tenants in the current prototype to guarantee each tenant can get its share of the resources. Generally speaking, the finer the discretization is, the better result the searching algorithm can yield, but the longer it takes to search. Dynamically adjusting the granularity of discretization according to tenant number and accuracy is an ongoing work. The algorithm starts the searching from (r1j, . . . ,rn j),j=1, . . . ,m
whereri j =rk j,i,k. That is equal reservation. In addition, during the search, we only change one variable i.e., either cache size
or HDFS throughput. This limits the number of neighbors to explore and makes the search tractable.
6. Evaluation
Argus is prototyped with HBase 0.94.21. It is evaluated using a 28-node cluster where each node has a 2.0 GHz dual-core CPU with 4 GB memory and a 40 GB disk. Three nodes are setup as a Zookeeper ensemble, one node is setup up with both HDFS master and HBase master, and the other 24 nodes are set up as HRegion servers and HDFS data nodes. The block cache size is set at 1.2 GB and the number of RPC handler threads in HBase is set to 30. The HDFS replication factor is set to 1 to conserve disk space. We use the YCSB benchmark [18] to populate the data and generate the workload. After all the data is pre-loaded, we run major compactions to compact the store files. We have HBase balance the number of regions across nodes. The YCSB clients are run in additional nodes to simulate multiple tenants accessing the system simultaneously. Running YCSB clients on separated nodes can avoid interference on the client side. Each tenant has its own data set in HBase. The throughput on the client side, i.e., operations per second (ops/sec), is used as a measurement to reflect a tenant’s performance on the system. We first present the micro evaluation which mainly focuses on the reservation enforcement as it is the fundamental of Argus, then describe the macro evaluation which studies the overall performance in various scenarios. Due to space limitations, we skip results which appeared earlier in [8].
6.1. Micro Evaluation
We study the impact of disk reservation on fairness and efficiency. Then we investigate the effectiveness of elastic reservation. Finally, we assess the overhead introduced by the enforcement approaches. The reservation planning is turned offin this set of experiments to allow us to focus on reservation enforcement.
6.1.1. Disk Reservation
We adapt the deficit round robin algorithm as the request scheduler to enforce throughput reservation on HDFS. As discussed in Section 4.2, the total number of credits per node is a parameter set by the system admin and has an impact on the performance of the scheduler. To quantify its impact, we set the credit number to several different values and report the changes of throughput as well latency, and fairness as well as efficiency. The block cache in HBase is disabled so that we can concentrate on the HDFS usage.
Impact on throughput and latency. We have two tenants with 50 threads to carry out uniform read-only workloads respectively.
We report the throughput as well as latency. Throughput is measured as aggregated throughput of tenants and latency is measured as average latency. Figure 2a shows the result. The x axis indicates the number of credits allocated to tenants in every refill period (2 seconds in the current prototype) for each node. The ideal throughput and ideal latency are obtained by running the workloads against vanilla HBase. From the results, we can see that the throughput increases as the number of credits increases from 30 million to 50 million. Afterwards, the throughput gets close to the ideal throughput. Latency has a similar trend. As the number of credits increases, latency decreases until it gets close to the ideal one.
We explain the reason behind such results as follows. The number of credits in the scheduler is used to throttle requests sent to HDFS. The larger the number is, the less constraints the scheduler imposes. Theoretically, if the number goes positive infinity, no throttling will imposed because the credit number will never run out. As a result, the requests should flow through the scheduler without any regulations. However, due to the implementation overhead of the scheduler e.g., en-queuing and de-queuing, requests may still experience some regulations. That is why in Figure 2a, the throughput and latency curves can get close to the ideal ones when the credit number goes beyond 60 million, but still cannot reach the ideal ones. On the other hand, when the number of credits goes down, a tenant may quickly use up its credits and is subject to schedule. Specifically, in one scheduling cycle (2 seconds in our prototype), the fewer credits are given, the quicker requests are throttled. Requests will not be dispatched to HDFS until the next scheduling cycle comes. That is why we see a dramatic drop of throughput and increase of latency when the credit number goes below 50 million.
In a word, the scheduler becomes ineffective if the credit number is set too high and inefficient if the number is set too low. In the next section, we investigate how this number influences fairness and efficiency.
30 40 50 60 70
#Credits Per Node (×106)
400 500 600 700 800 Ag gre ga ted Th rou gh pu t ( op s/se c) ideal throughput 60 80 100 120 140 160 180 200 220 La ten cy (m s) ideal latency Throughput Latency
(a) Impact of #credits on throughput and latency.
30 40 50 60 70
#Credits Per Node ( ×106) 0.0 0.2 0.4 0.6 0.8 1.0 Fa ir ne ss target fairness 0.0 0.2 0.4 0.6 0.8 1.0 Ef fic ie nc y target efficiency Fairness Efficiency
(b) Impact of #credits on fairness and efficiency.
Figure 2: Impact of #credits on disk reservation. The x-axis represents the number of credits allocated in every refill period.
Fairness and efficiency tradeoff. To study the impact of the number of credits on fairness and efficiency, we have two tenants run
the uniform read-only workload. One uses 50 threads while the other one uses 200 threads. Figure 2b displays the result. Fairness is quantified with equation 1, and efficiency is measured as the average throughput violation defined in equation 2. The target fairness and efficiency are observed by running vanilla HBase and having both tenants use 50 threads. The credit number starts at 30 million where Argus can achieve the target fairness. However, it also has the lowest efficiency. As the credit number increases and goes beyond 50 million, the efficiency goes up and is getting close to the target efficiency. But meanwhile fairness drops significantly.
As explained previously, the credit number controls how much constrain the scheduler can impose to the request scheduling. A small number allows the scheduler to shape the throughput to achieve fairness easily but also introduces idleness as tenants use up the credits quickly and have to wait for the next refill cycle. In contrast, a large number makes the scheduler effortless. As a result, Argus acts as vanilla HBase. Fairness is thus not enforced.
In summary, fewer credits tend to have better fairness but lower efficiency, while more credits have worse fairness but higher efficiency. Thus, the amount of credits is a tradeoffbetween fairness and efficiency. In the current prototype, we set it to 50 million per node. Each tenant receives an equal share of the credits at the beginning. Such a setting sacrifices efficiency a little bit but gives good fairness as the experiments shown above. A more advanced option is to dynamically adjust the credits according to the workload characteristics suggested in [11]. Specifically, a credit number represents the reservation on the disk resource for a particular workload. It would be better to be a dynamic number instead of a static setting owing to different workload demands and fairness/efficiency goals. As discussed in Section 5, different workloads may require different reservations. Additionally, a certain fairness or efficiency goal may require a specific setting of the credit number. In order to select an appropriate credit number, we need to establish an upper bound of the credits for a fairness goal and a lower bound for an efficiency goal. An upper bound avoids the case where credits increase too many resulting to fairness violation while a lower bound prevents efficiency violation due to small credit allocation. The upper bound and lower bound can be obtained by either running offline experiments with regression or inferring analytically. The former requires a large sample set for regression while the latter needs proper resource modeling. Once we have the bounds, we can apply them to the credit allocation and change according to different workloads and fairness/efficiency goals. We feel that Argus can be extended to use the dynamic credit setting approach although there are challenges from getting the upper and lower bound of credit number. We leave such an extension for future work.
6.1.2. Elastic Reservation
Real world workloads usually have dynamics and require the storage system to be able to automatically adapt. The kinds of dynamics include change of throughput and access pattern e.g. hotspot, uniform, etc. The elastic reservation approach is applied to block cache and disk reservation to dynamically adjust the reservation when some tenants decrease their throughput. The reservation planning is used to adjust the reservation when tenants’ workload have different resource demands. We evaluate the elastic reservation by having two tenants run the uniform workloads. They both use 50 threads.
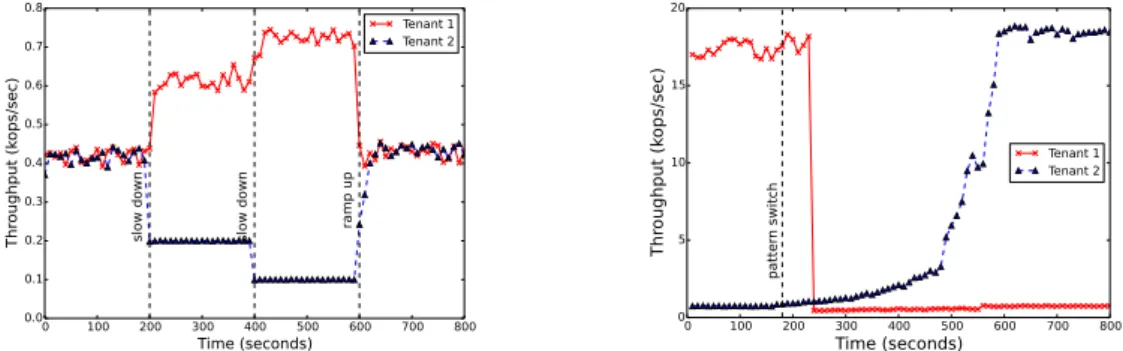
0 100 200 300 400 500 600 700 800 Time (seconds) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Th rou gh pu t ( ko ps/ se c) slo w do wn slo w do wn ram p u p Tenant 1 Tenant 2
(a) Tenant #1 is allowed to have higher throughput when tenant #2 slows down.
0 100 200 300 400 500 600 700 800 Time (seconds) 0 5 10 15 20 Th rou gh pu t ( ko ps/ se c) pa tte rn sw itc h Tenant 1 Tenant 2
(b) Argus reacts when workload changes its access pattern over time.
Figure 3: Argus dynamically adjusts its reservations to adapt to changes from tenant workloads.
In the first experiment, we study how Argus reacts to slow tenants. Figure 3a shows the throughput as a function of time when a tenant slows down at some point. Both tenants fair share the system in the first 200 seconds. Between the 200th second and the 400th second, tenant #2 decreases its throughput to 200 ops/sec. During that period, Argus is able to raise the throughput of tenant #1 to about 600 ops/sec by increasing tenant #1’s cache and credit allocation. Then tenant #2 further decreases its throughput to 100 ops/sec in the next 200 seconds. Thanks to the elastic reservation approach, tenant #1’s throughput is increased from 400 ops/sec to 600 ops/sec and further to 700 ops/sec. Finally, tenant #2 increases its throughput and both tenants start seeing similar throughput after the 600th second.
Next, we examine Argus’ capability of dealing with workloads changing access patterns. Two tenants switch their access patterns at some point to simulate access pattern change in Figure 3b. Tenant #1 starts with an extreme hotspot workload and tenant #2 runs an uniform workload. At the 180th second, they switch the access pattern i.e., tenant #1 now runs uniform workload and tenant #2 runs extreme hotspot workload. It takes the decision maker about 60 seconds to realize the change because it operates every 60 seconds. Once the decision maker adjusts the resource reservation for both tenants, tenant #2’s throughput increases gradually. Finally at about 580th second, tenant #2 achieves its maximum throughput. Tenant #2 takes around 300 seconds to get to
the maximum because it needs to replace most of the cache items in the block cache. The reservation planning plays an important role to adjust the reservation according to workloads’ demands. The results above show that Argus can handle workloads varying in throughput and access pattern efficiently.
6.1.3. Overhead
Finally, we study the overhead introduced by resource reservation. For the disk reservation, there are two sources where overhead comes from. One is the implementation of the DRR algorithm and the queues associated with it. Figure 2a shows that when the number of credits per node is 70 million, which does not impose any constraints to the request scheduling, about 2% overhead is observed for throughput and about 1% for latency. We attribute that to the implementation of DRR and queues. The other source of overhead is the number of credits used in the DRR algorithm. For 50 million credits in Figure 2a, we observe around 3% overhead for throughput and 2% for latency. To study the overhead of the cache reservation, we disable the disk reservation and have two tenant run the uniform, hotspot and extreme hotspot workloads respectively with the same number of threads. The overhead is ignorable for all three workloads (less than 1%).
To get the total overhead of a fully functioning system, we enable both the cache and the disk reservations in Argus. We have two tenants run the same workloads above with 50 threads, and compare the aggregated throughput with the ones generated from vanilla HBase. We observe approximately a 5% throughput decrease for the uniform workload, a 4% drop for the hotspot workload, and ignorable overhead for the extreme hotspot workload. Compared with the overhead obtained solely from disk reservation, the overhead from cache and disk reservation increases. We think the usage of cache magnifies the throughput overhead.
6.2. Macro Evaluation
We study the overall performance of Argus in more complex scenarios in this section. We present the performance of Argus by running various workloads. Then we compare Argus with A-Cache [5], an key-value store system that aims at preventing cache interference. 6.2.1. Overall Performance 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Uniform-200 Uniform-50 N o r m a l i z e d M e t r ic throughput violation
HDFS throughput cache occupancy
(a) Two uniform workloads with diff
eren-t number of eren-threads. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Hot-50 Uniform-50 N o r m a l i z e d M e t r ic throughput violation
HDFS throughput cache occupancy
(b) Regular hotspot workload mixed with u-niform workload. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ExHot-50 Uniform-200 N o r m a l i z e d M e t r ic throughput violation
HDFS throughput cache occupancy
(c) Extreme hotspot workload mixed with uniform workload.
Figure 4: Overall performance of different workloads.
The throughput (ops/sec) is computed as the average of the measures taken over an 800 second period. We use the J-index from our equation 1 as a measure of the fairness in terms of throughput violation, and the D-score (D) from equation 3 as a measure of improvement. To ensure stability in the measures, we begin taking measures after a ramp-up time of 300 seconds has completed, and ensure a cold-cache start on every run. We evaluate whether Argus can prevent interference in cases where workloads with different access patterns are mixed together. We run the workloads defined in Section 3 with different thread number. The purpose is threefold: is Argus able to handle tenants with different thread numbers? Can Argus differentiate cache and disk demands from
different workloads? How does Argus react when tenants with varying number of threads and resource demands coexist?
We pre-load 80,000,000 rows to each tenant with each row about 1.2 KB in size (96GB). Figure 4 plots the throughput violation, normalized HDFS throughput and cache occupancy. The legend shows the workload type and number of threads it uses. For example, Uniform-200 means uniform workload sent by 200 threads. Table 3 summaries the J-index, D-score and compares them with scores obtained from vanilla HBase.
Table 3: Performance interference compared with vanilla HBase. Values in parentheses are the performance numbers from vanilla HBase.
Workload J-index D-score
Uniform-50 and Uniform-200 0.999 (0.746) 0.715 (0.620) Hot-50 and Uniform-50 0.997 (0.968) 0.741 (0.704) ExHot-50 and Uniform-200 0.995 (0.662) 0.909 (0.656)
For throughput violation, both tenants see roughly the same violation in all experiments (Figure 4 a, b, c) which suggests that Argus prevents interference through informed resource reservation. The extreme hotspot workload appearing with the uniform workload in Figure 4c experiences the least violation because the two workloads do not compete for the same resource i.e., ex-hotspot tenant uses cache while uniform tenant tends towards disk. The scheduler recognizes the resource demands and reallocates resources based on needs. For HDFS throughput and cache occupancy, both tenants have a similar share in Figure 4a. As a hotspot tenant becomes more hotspot oriented (in b) the uniform tenant will begin to take a larger share of HDFS throughput and give away more share in cache occupancy to ex-hot tenant. The similar throughput under change over time reinforces the claim of Argus’ ability to identify workload resource demands and adjust the resource reservation.
In Figure 4b and 4c, the regular hotspot workload takes a larger share of HDFS throughput and less of a share of cache occupancy than the extreme hotspot workload does which matches our expectation because the regular hotspot workload demands more disk accesses and less cache visits. From Table 3, it is clear that Argus outperforms vanilla HBase in terms of J-index and D-score. For regular hotspot workload mixed with the uniform workload, although the J-index value of HBase is close to the one in Argus, Argus has a higher D-score value which indicates its throughput violation is better than the one in HBase.
6.2.2. Comparison with A-Cache
Lastly, we compare Argus with A-Cache [5], a system developed on top of HBase to prevent the performance interference among workloads. It focuses on preventing the cache interference. It uses the cache reuse ratio to represent the cache utilization for each tenant. The reuse ratio is calculated as the ratio of the number of cache blocks visited at least twice to the total number of cache blocks. It estimates how much cache space this workload may need because a cache block only becomes useful when it is visited at least twice. A-Cache uses the reuse ratio multiplied by a margin factor as the portion of cache size a tenant needs. The intuition is a tenant should only have what is needed. Workloads with large reuse ratios deserve more cache space while workloads with small reuse ratios need less.
Table 4: Comparison with A-Cache. Values in parentheses are the performance numbers from A-Cache.
Workload J-index D-score
Uniform-50 and Uniform-200 0.999 (0.733) 0.715 (0.691) Hot-50 and Uniform-50 0.997 (0.963) 0.741 (0.745) ExHot-50 and Uniform-200 0.995 (0.691) 0.909 (0.667)
We implement the A-Cache approach and evaluate its fairness as well as overall score with the three workloads defined in Section 3. Table 4 shows the results. Overall, A-Cache performs worse than Argus – the J-index drops 30% and the D-score drops 25%. Compared with the values of vanilla HBase in table 3, A-Cache has very similar performance. It means A-Cache fails to prevent interference in the uniform and extreme hotspot workload groups.
We attribute A-Cache’s failure of interference prevention to the fact that it only considers cache interference and ignores other resource demands. In the uniform workload and extreme hotspot groups, tenants use different thread numbers to access. Although A-Cache can provide strong cache isolation, it has no mechanism for disk access scheduling and thus does not provide the disk access isolation like Argus does. The tenant with a larger thread count can take most of the disk resource, which results in higher throughput than it is supposed to receive and interference. In contrast, Argus has scheduling mechanisms for both cache and disk. In the case of workloads using different thread numbers, the disk reservation approach in Section 4.2 prevents interference by throttling requests. In the hotspot mixed with uniform workload group, tenants use the same thread number but access with different patterns. A-Cache gets similar performance to Argus. But for the J-index, A-Cache still lags behind. We think it is because Argus has the model-based approach to adjust the cache reservation systematically, which can measure resource demands more accurately.
Comparing table 4 with table 3, the J-index values of A-Cache are very close to the ones of vanilla HBase. A-Cache performs a little bit worse (around 1%) than HBase in the uniform workload group and but achieves better (about 2%) in the extreme hotspot workload group. In the hotspot workload group, both A-Cache and HBase can get close to the value Argus achieves but still fall a little bit behind due to the reasons explained above. For overall score, A-Cache has slightly higher D-score than vanilla HBase in all three workload groups. We think the small performance variants between A-Cache and HBase are caused by different cache reservation and replacement approaches. A-Cache essentially provides an isolated cache space for each tenant while HBase does not distinguish tenants from the cache space. Even tenants interfere with each other in the disk access level, their activities remain isolated in the cache. Therefore A-Cache yields better D-score. This is also true for fairness in workloads mixed with different patterns i.e., the hotspot group and the extreme hotspot group. In general, there is no significant difference between A-Cache and vanilla HBase in our workload experiments since they both suffer from interference. But different cache reservation and replacement approaches do lead to small performance variants. We leave the investigation of those approaches for future work.
6.2.3. Large Scale Experiments
The experiments so far demonstrate that Argus can effectively reserve cache as well as disk resource and achieve fair share across two tenants. To take this one step further, we evaluate Argus in more complex scenarios with more tenants involved. Specifically, we examine the reservation and the isolation capability under different workloads with different tenants.
In the first experiment, we have 3 groups of workloads: uniform, extreme hotspot, and mixed. There are 1, 2, 5 and 8 tenants to run the workloads. Tenants run the same workload in uniform and extreme hotspot group while some tenants run uniform workload and some run extreme hotspot workload in the mixed group. For the 1 and 2 tenants cases, each tenant uses 50 threads. For the cases of 5 and 8 tenants, the thread counts are 50, 50, 100, 200, and 300, and 50, 50, 100, 100, 200, 200, 300, and 300 respectively. The reservation planning is turned offto avoid resource re-allocation. We measure tenant #1’s (represented asT1) throughput to
see how much it changes in different settings. T1runs the extreme hotspot workload in the mixed workload group. T1’s HDFS
throughput and cache occupancy percentages are set to 0.5. The remaining HDFS throughput and cache occupancy percentage, i.e. 0.5, are distributed evenly across other tenants. Figure 5 displays the results. For the mixed group, we only reportT1’s throughput
when the number of tenants is at least 2. Each bar represents the throughput of T1. Bars with different stripe patterns mean
the throughput observed under different tenant number settings. We can see that for all different workload groups,T1 achieves
consistent performance even when the number of tenants increases from 1 to 8 andT1is mixed with the uniform workload. Thus
Argus is able to preserve throughput in a multi-tenant environment by enforcing resource reservation.
10 100 1000 mixed extreme hot uniform
1 T enant 2 T enants 5 T enants 8 T enants
T 1 ' s t h r o u g h p u t ( o p s / s e c )
Figure 5:T1’s throughput under different workloads and different number of tenants..
Next, we run different workload groups with different resource demands against Argus. This is to test if Argus can handle cases which have more tenants involved. We run three groups of workload: uniform workloads, uniform workloads mixed with hotspot workloads, and uniform workloads mixed with hotspot as well as extreme hotspot workloads. Similar to the previous experiment, in each group, different tenant may use different thread number to run the workload. We report the J-index and D-score in Table 5. The workload naming convention follows the naming convention used before. The J-index values from all three groups are close to 1 indicating that Argus can achieve fairness among different tenants with different resource demands. In fact, by comparing the J-index and D-score values to the ones in Table 3, we can see that they are very similar. This indicates that Argus has consistent performance when multiple tenants involve, even when the number of tenants increases from 2 to 5.
Table 5: Performance of Argus in complicated scenarios.
Workload J-index D-score
Uniform-50, Uniform-50, Uniform-100, Uniform-150, Uniform-200 0.999 0.72
Uniform-50, Uniform-50, Hot-100, Hot-150, Uniform-200 0.993 0.736
Uniform-50, Uniform-50, Hot-100, ExHot-150, ExHot-200 0.996 0.895
6.3. Extension Discussion
To simplify the scenario, the current prototype of Argus is bound by some limitations. In this section, we discuss potential approaches Argus can take to handle more general cases and overcome some of the limitations. Interference caused by read and write operations is not uncommon in real world scenarios. As shown in [8], for read workloads mixed with write workloads, Argus does not provide the same level of fairness and efficiency as it does in the read-only workload. Its J-index and D-score drop over 20% and 10% respectively. The main reason is writes not only change the internal data structures (i.e., SSTableand
MemTable), which affects the read performance, but also trigger internal I/O i.e., the compaction, which competes resources with
regular requests. The key to this issue is to have a resource consumption model that can represent the I/O behavior of the system. Specifically, the model should be able to reflect the resource consumption change of reads when writes are admitted. The impact of internal I/O should also be reflected in the model. An analytical form of such a model turns out to be very difficult, even in a single node system [23]. Therefore, instead of deducting the mathematical form of the model, [23] derives the model through offline samplings, a similar approach Argus uses for the reservation planning. The model is represented as a non-linear function and uses a “virtual IOPS” concept to represent the underlying resource consumption. Such an approach can be applied in Argus to get a better resource consumption model in order to handle the read-write interference.
Another limitation of Argus is it ignores the data locality impact. Reading from local disk is faster and consumes less resources than from remote nodes. Argus simplifies the situation by assuming every byte read from HDFS consumes the same amount of resources. Setting the replication factor to 1 not only conserves disk space but also mitigates the data locality impact. To take the data locality into account and handle the case where replication factor is larger than 1, the resource model in HDFS needs to be refined to include disk I/O as well as network I/O. Such a refinement requires some significant changes to Argus’ HDFS reservation mechanism. Specifically, it needs to be able to distinguish the disk I/O and network I/O from requests resource consumption. This can be done by checking if the requested data is local to the current node. If it is, then only disk I/O will be counted. Otherwise, network I/O is also measured and counted as part of the resource consumption. Besides the refinement of resource monitoring, the scheduler also needs to be modified. Argus needs a way to translate the disk I/O and network I/O to the number of credits, and vice versa. A simple approach is to simply sum up the disk IOPS and network IOPS. The problem is they may be measured in different scales. A normalized approach can be used to unify these two I/O measurements. A better approach is to use the dominant resource fairness [24] which pick the dominant resource for scheduling.
7. Applications
To see how Argus could work for real world applications, we draw on big data text mining of the HathiTrust Research Center (HTRC) [25, 26]. HTRC provisions for community research text mining of the nearly 14 million digital documents (books, serials, government documents) of the HathiTrust digital repository [27]. HTRC manages different types of data objects: raw text data, metadata about the books, and derived datae.g. term frequency count. This is managed through a single key-value store. All of these data objects are slow changing so workloads against all three are largely read-only, matching the observation in [28] capturing realistic workloads in NoSQL stores.
The access patterns are different amongst workloads and could thus result in performance interference. Reading from raw text and metadata has evidenced locality as parts of the corpus are more interesting than other parts. Reading from derived data, however, is likely done using a linear scan, which may interfere with the cache contents and access patterns used by workloads over raw text and metadata. Additionally, some of the text analysis may run on the same data set repeatedlye.g.topic modeling analysis, advanced machine learning for classification [29, 30], while some of the others may just run for one time,e.g.a tag cloud generator may fetch the term frequency from the derived data set. The cache in the topic modeling workload may be interfered by the other one-time workloads where requests are mostly random. Argus can protect the cache by enforcing reservation and allocating more disk resource to the random workload accordingly. Another interference scenario is the number of requests made to the metadata is
a lot higher than the number made to the raw text as users may want to investigate enough metadata before studying the text. Argus can prevent the interference from high volume of requests on metadata to workloads on raw text.
8. Conclusion
Argus is a NoSQL data store that supports multi-tenancy through tenant performance isolation using a workload-aware resource reservation framework. Argus implements mechanisms to enforce reservations on cache and disk usage. Furthermore, Argus utilizes optimization modeling techniques to dynamically adjust the reservation according to different workload access patterns. Micro evaluation is carried out to understand the impact of different scheduling algorithms, the trade-offbetween fairness and efficiency, and overhead incurred. Macro evaluation is used to study Argus’ overall performance in comparison to A-Cache.
The open questions for this work are several: the impact of writes on reads and model the I/O behavior needs to be better understood to provide isolation between reads and writes. A resource reservation, i.e. the memory usage for writes, offers benefits in the reservation framework. An increased write buffer size will boost the write performance but harm the read performance as the size of block cache decreases. It is beneficial to study the impact of setting the sizes of cache and write buffer according to different workload characteristics. The query we currently use is key-value pair lookup. We intend to investigate the impact of SQL-like queries on resource reservation. Finally, it is worthwhile to fully evaluate how Argus performs under the realistic workloads of the HathiTrust Research Center when those workloads become available.
9. Acknowledgements
This work is funded in part by a grant from the Alfred P. Sloan Foundation, Grant 2011-6-27. We thank the HathiTrust as well for making the study possible.
[1] What the heck are you actually using nosql for?,http://goo.gl/Fg0AtH.
[2] R. Krebs, S. Spinner, N. Ahmed, S. Kounev, Resource usage control in multi-tenant applications, in: Proceedings of the 14th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, IEEE/ACM, 2014.
[3] S. Walraven, T. Monheim, E. Truyen, W. Joosen, Towards performance isolation in multi-tenant saas applications, in: Proceedings of the 7th Workshop on Middleware for Next Generation Internet Computing, ACM, 2012, pp. 1–6.
[4] S. Das, V. R. Narasayya, F. Li, M. Syamala, CPU sharing techniques for performance isolation in multi-tenant relational datab-as-a-service, in: Proceedings of the VLDB Endowment, PVLDB ’13, Very Large Data Bases Endowment Inc., 2013.
[5] B. Ravi, H. Amur, K. Schwan, A-Cache: Resolving cache interference for distributed storage with mixed workloads, in: 2013 IEEE International Conference on Cluster Computing, CLUSTER’13, IEEE, 2013, pp. 1–8.
[6] D. Shue, M. J. Freedman, A. Shaikh, Performance isolation and fairness for multi-tenant cloud storage, in: Proceedings of the 10th USENIX Conference on Operating Systems Design and Implementation, OSDI ’12, USENIX Association, 2012, pp. 349–362.
[7] J. Zeng, B. Plale, Multi-tenant fair share in nosql data stores, in: 2014 IEEE International Conference on Cluster Computing, CLUSTER ’14, IEEE, 2014, pp. 176–184.
[8] J. Zeng, B. Plale, Workload-aware resource reservation for multi-tenant nosql, in: 2015 IEEE International Conference on Cluster Computing, CLUSTER ’15, IEEE, 2015, pp. 32–41.
[9] D. Jacobs, S. Aulbach, T. U. Mnchen, Ruminations on multi-tenant databases, in: BTW Proceedings, volume 103 of LNI, GI, 2007, pp. 514–521.
[10] C. Curino, E. Jones, R. A. Popa, N. Malviya, E. Wu, S. Madden, H. Balakrishnan, N. Zeldovich, Relational Cloud: A Database Service for the Cloud, in: 5th Biennial Conference on Innovative Data Systems Research, CIDR ’11, Asilomar, CA, 2011.
[11] M. Wachs, M. Abd-El-Malek, E. Thereska, G. R. Ganger, Argon: Performance insulation for shared storage servers, in: Proceedings of the 5th USENIX Conference on File and Storage Technologies, FAST ’07, USENIX Association, 2007, pp. 1–16.
[12] A. Wang, S. Venkataraman, S. Alspaugh, R. Katz, I. Stoica, Cake: Enabling high-level slos on shared storage systems, in: Proceedings of the 3rd ACM Symposium on Cloud Computing, SoCC ’12, ACM, 2012, pp. 1–14.
[13] A. Gulati, I. Ahmad, C. A. Waldspurger, PARDA: proportional allocation of resources for distributed storage access, in: Proccedings of the 7th Conference on File and Storage Technologies, FAST ’09, USENIX Association, 2009, pp. 85–98.
[14] G. Soundararajan, D. Lupei, S. Ghanbari, A. D. Popescu, J. Chen, C. Amza, Dynamic resource allocation for database servers running on virtual storage, in: Proccedings of the 7th Conference on File and Storage Technologies, FAST ’09, USENIX Association, 2009, pp. 71–84.
[15] M. Shreedhar, G. Varghese, Efficient fair queueing using deficit round robin, in: Proceedings of the Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, SIGCOMM ’95, ACM, 1995, pp. 231–242.
[16] Quota management in hbase,https://issues.apache.org/jira/browse/HBASE-8410.
[17] Region server grouping in hbase,https://issues.apache.org/jira/browse/HBASE-6721.
[18] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, R. Sears, Benchmarking cloud serving systems with YCSB, in: Proceedings of the 1st ACM Sympo-sium on Cloud Computing, SoCC ’10, ACM, 2010, pp. 143–154.
[19] A. K. Parekh, R. G. Gallager, A generalized processor sharing approach to flow control in integrated services networks: The single-node case, IEEE/ACM Transactions on Networking 1 (3) (1993) 344–357.
[20] Fair queuing,https://en.wikipedia.org/wiki/Fair_queuing.
[22] M. Katevenis, S. Sidiropoulos, C. Courcoubetis, Weighted round-robin cell multiplexing in a general-purpose atm switch chip, IEEE Journal on Selected Areas in Communications 9 (8) (2006) 1265–1279.
[23] D. Shue, M. J. Freedman, From application requests to virtual iops: Provisioned key-value storage with libra, in: Proceedings of the 9th ACM European Conference on Computer Systems, ACM, 2014, pp. 1–14.
[24] A. Ghodsi, M. Zaharia, B. Hindman, A. Konwinski, S. Shenker, I. Stoica, Dominant resource fairness: Fair allocation of multiple resource types, in: Proceed-ings of the 8th USENIX Conference on Networked Systems Design and Implementation, NSDI’11, USENIX Association, 2011, pp. 24–37.
[25] Hathitrust research center,http://www.hathitrust.org/htrc.
[26] J. Zeng, G. Ruan, A. Crowell, A. Prakash, B. Plale, Cloud computing data capsules for non-consumptiveuse of texts, in: Proceedings of the 5th ACM Workshop on Scientific Cloud Computing, ScienceCloud ’14, ACM, 2014, pp. 9–16.
[27] Hathitrust digital library,http://www.hathitrust.org/.
[28] B. Atikoglu, Y. Xu, E. Frachtenberg, S. Jiang, M. Paleczny, Workload analysis of a large-scale key-value store, in: Proceedings of the 12th ACM
SIGMET-RICS/PERFORMANCE Joint International Conference on Measurement and Modeling of Computer Systems, SIGMETRICS ’12, ACM, 2012, pp. 53–64.
[29] W. Shen, J. Wang, Y.-G. Jiang, H. Zha, Portfolio choices with orthogonal bandit learning, in: Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’ 15, AAAI Press, 2015, pp. 974–980.
[30] W. Shen, J. Wang, Transaction costs-aware portfolio optimization via fast lowner-john ellipsoid approximation, in: Proceedings of the National Conference on Artificial Intelligence, AAAI’ 15, AAAI Press, 2015, pp. 1854–1860.