http://wrap.warwick.ac.uk/
Original citation:
Jarvis, Stephen A., 1970-, He, Ligang, Spooner, Daniel P. and Nudd, G. R. (2004) The impact of predictive inaccuracies on execution scheduling. University of Warwick. Department of Computer Science. (Department of Computer Science Research report).
Permanent WRAP url:
http://wrap.warwick.ac.uk/61313
Copyright and reuse:
The Warwick Research Archive Portal (WRAP) makes this work by researchers of the University of Warwick available open access under the following conditions. Copyright © and all moral rights to the version of the paper presented here belong to the individual author(s) and/or other copyright owners. To the extent reasonable and practicable the material made available in WRAP has been checked for eligibility before being made available.
Copies of full items can be used for personal research or study, educational, or not-for-profit purposes without prior permission or charge. Provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way.
A note on versions:
..$$rH."ro,
effi
r&?
wAryrct<
Research
Report
3go
THr
In,tpncr
or
pneDrcrvE
lrunccuMcrEs
oN
Execuloru
ScnEDULtNG
Stephen
A Jarvis,
Ligang
He,
Daniet
p
Spooner
and
Graham R Nudd
The
Impact
of
Predictive
Inaccuracies
on
Execution Scheduling.
Stephen
A.
Jarvis, Ligang He, Daniel P. Spooner and Graham R. NuddHigh Performance Systems Group, Department of Computer Science,
University of l|/arwick, Coventry CV4 7AL, UK
Email : [email protected]
Tel: +41 (0)2476 524258 Fax: +41 (0)2476 573024
Abstract:
This paper investigates the underlying impact of predictive inaccuracies onexecution scheduling,
with
particular
referenceto
executiontime
predictions. Thisstudy is conducted
from two
perspectives: from that ofjob
selection and from thatof
resource allocation,
both
of
which
are fundamental componentsin
executionsched-uling.
A
new performance metric, termed the degree of misperception, is introducedto
express theprobability
that the predicted execution times ofjobs
display differentordering characteristics
from their
real execution times dueto
inaccurate prediction.Specific formulae are developed
to
calculate the degreeof misperception in
bothjob
selection and resource
allocation
scenarios. The oarameterswhich
influence thede-gree
of misperception
are also extensively investigated. The results presentedin
thispaper are
of
significant
benefltto
scheduling approaches that take into accountpre-dictive
data; the results are alsoof
importance to the applicationof
these schedulingtechniques to real-world high-performance systems.
Index terms:
performance prediction, executiontime,
scheduling,job
selection,re-source allocation, and performance evaluation
-
This work is sponsored USARDSG, contract no.
in part by grants fiom
N6817r-01-C-90l2),
the NASA AMES Research Center (administrated by
1.
Introduction
Scheduling
in
a single processor environment is, at its most basic level, the taskof
determining
the
sequencein
whichjobs
should be executed.In
a multi-processor ormulti-computer environment on the other hand,
job
scheduling also involves theproc-ess
of
resource allocation, that is, determining the resourceto which
ajob
should besent
for
execution. The designof
scheduling policiesfor
parallel and distributedsys-tems has received a good deal
of
attention12,4,5,14,
15]. These schemes are oftenbased
on the assumption
that
thejob
execution times areknown
somehow[5,
9].While
thisis
a useful assumptionto
make, informationof this type is often unknown
and must therefore be
obtainedthrough
somepredictive mechanism.
A
naive
ap-proach to this problem
might
be to require the owner of thejob
to estimate theexecu-tion time
based on their past experience.A
more sophisticated approachmight
be toutilize
performanceprediction tools
to
perform this function.
A
numberof
increas-ingly
accwate prediction tools have been developed that are able to predict theexecu-tion
timesofjobs
based on performance models [3, 6, 7, 8] or historical data [1, 13].In
spiteof
this,
an inevitable fact is that the prediction results areunlikely to
beentirely
accurate and as a result, this may have a fundamental impact onjob
selectionand resource allocation.
In
the caseofjob
selection, the inaccurate prediction may mean that the schedulerhas an incorrect
view
of the order in which
thedifferent iobs should
execute. Forex-ample,
it
may be the case that the real execution time ofjob
-[
is greater than thatof
job J2; because of the inaccurate prediction however, the scheduler may view
job
-L ashaving a shorter execution time than that of
job
-/2. Therefore,if
the schedulingpolicy
is based on
job
execution times (the shortestjob
servicedfirst, for
example), then thismisperception
will
impact on the orderin which jobs
are selectedfor
execution. Thiswill
ultimately influence
the scheduler and system performance.When a scheduler receives a
job
in a parallel or distributed system, there may be anumber
of
resources (processorsor
computers) availableon which
thejob
may
beexecuted.
If
the resourceallocation
policy
is also
basedon the
expected executiontime of
thejob
on thedifferent
resources (select the computer that offers the shortestexecution time, for example) then these inaccuracies might also cause the scheduler to
wrongiy
select between them. Again, this misperceptionwill
impact on the schedulingand overall system performance.
The existence
of
misperception originatesfrom
the
inaccurateprediction
(of
in
this
case executiontime), and should
be viewed as an inherent characteristicof
anyprediction-based scheduling scheme that operates
in
a highly-variable real-worldsys-tem. This said, different scheduling policies
will
have different levelsof sensitivity
tothe degree
of misperception.
Thus, the study of the impact of inaccurate prediction onscheduling performance can be decomposed into two levels
-
at the underlying level,as a study into the degree of misperception originating from inaccurate prediction; and
at the higher level, as a study into the sensitivity
of
individual
scheduling policies tothis
degreeof misperception. This
paper addresses the former, where the latter is thesubject
of future work.
Different
predicted errors can leadto different
degreesof
misperception. Theob-jective
of this paper is to establish the relationship between the predicted error and thedegree of misperception, for both
job
selection and resource allocation scenarios. Thisstudy provides an
insight into
the underlying impactof
inaccurate prediction onjob
selection and resource allocation and
significantly benefits
the design and evaluationThe rest
of
this paperis
organized asfollows.
Formulafor
the degreeof
misper-ception, and
forjob
selection and resource allocation are developedin
Section 2. Theparameters that influence the degree
of
misperception are then extensively evaluatedin
Section 3. The paper concludesin
Section 4.2.
An
Analysis
of
the Degree of
Misperception
2.1
Job Selection
When performance
prediction tools
are usedto
estimate the execution timesof
jobs,
the predicted execution time usually lies in an interval around the actualexecu-tion time (of
thejob)
according to some probability distribution [7, 8].Suppose that the actual execution
time
ofjob
Ji
isxi
and that the predictive error,denoted by y;, is a random variable in the range
I
o*,,bx,]
following
some probabilitydensity function,
gi\);
where the possible value fields of a andb are
[0,
100%] and[0,
-),
respectively.It
is assumed that the predictive errorsof different jobs
areinde-pendent random variables. The predicted execution
time
ofjob
-/,, denotedby zi,
iscomputed using Eq.1.
Zi=Xi+yi
(1)Suppose two jobs
Jt
and Jzhave the actual execution timesxt
ard x2, wherextlxz.
Then the predicted execution times of -rl and Jz, that is zr and 22, a;te
xfyl
andxzflz,
respectively.
Given
that xt*1
a misperception happensif
zr):2.
The degreeof
mis-perceptionfor
these twojobs,
denoted by MD(x1,x2), is defined by the probability thatzP-:zzwhlle xt-. ..xz. This probability is denoted by P,(zps2lx,<xz).
With
Eq.1. thisprob-ability
can be further transfbrmed using Eq.2.P,(z pz2lx
fxz):P,(x
;y
12 x2*y2lxfxz):P,(y
P- y2+x 2-xI
xz-
xP0)
(2)MD(x 1, x
z):
P,(y t> y 2+x 2-x tl x 2- xP0)
(3)From Eq.3,
it
can be seen that the probability that the misperception happens is theprobability
that given x2-xpQ, the predictive errorof
I
(i.e.,yr)
is
greater than thepredictive error of
4
(i.e.,
yz) plus the difference between x2 andxt.By
constructingthe coordinates of the
predictive
erroryr
andyz, the inequality ypy2+x2-x7 means thaty1 and )t2 are given values from the area above the line
!
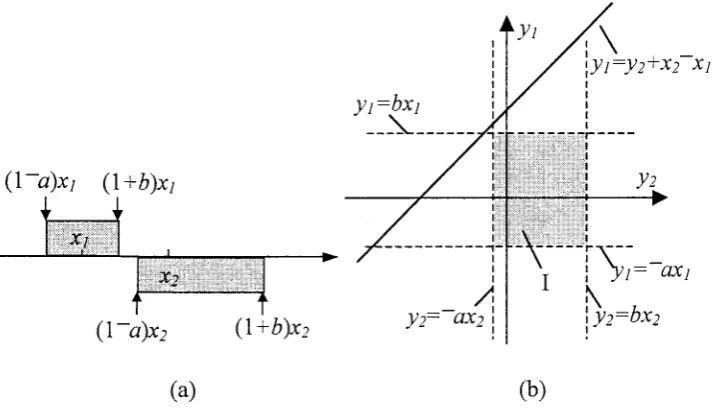
F!z-rxz-x1.Fig.
i.a, 2.a
and 3.a illustrate the relation of predicted execution times ofJt
and Jz,while Fig.1.b,2.b
and 3.b show the corresponding value fields of the predictive errorof .rr and Jz
(yt
andy2) aswell
as the corresponding area in whichy7)42*xz-xt.t\
rVt:VtrX>
XtI I
\*
I
!i:r:iil :::i:l:l:l,:ill lri:t;l
--i\--
_
t, \t:
axlt\
i Vt:DX>
(I-a)x2
Q+b)x2 [image:7.595.111.468.349.553.2](a) (b)
Figure.l.
Casestudy
1(a) the predicted
executiontimes of jobs
Jt
and,I:
do notoverlap; (b) the corresponding coordinate
area
which the predictive
errors
yl
andy2 can
be assigned valuesfrom.
Fig.1.a illustrates the case when the ranges
of predicted
execution times of -L and-/z do not overlap.
In
this
case a misperceptionwill
not occur
evenif
the predictionsare
not
accurate. Correspondingly,Figl.b
shows the coordinate areaof
the predictederrors of -L and J2 (arca
I), which
is the area surrounded by thelines:yr:-ax1,))fbxr,
!z:-ox2
andy2:bxz.
As
can be seenfrom
the figure,
all of
areaI
is below the line
/F/z*xz-xl.
Hence,P,(yP
y2+x2-xtlx2-
xp})
inEq2
is
equalto
zero.This
case isexpressed more
formally
below.P,(yp
y2+xz-xl xz-
x7>0):0
-ax2>-bx1*x2-x1,
x2-xp0
(4)(l-a)x
1(l+b)xl
(I-a)x2
(l+b)x2
(a) (b)
Figure.2.
Casestudy
2 (a)the predicted
execution times ofjobs
Jt
^nd.:I2 overlap,
however the lower
limit
of the predicted
executiontime for
Jz doesnot
cover x7i(b)
the corresponding coordinate area of predicted
errors
of.Il
and JzOt
and yz)in
which
the misperception occurs (the area is atriangle).
Fig.2.a illustrates the case when the predicted execution times of -rr and J2 overlap
and the lower
limit
of
the predicted execution time of Ju is greater thanxr.
Thecone-sponding coordinate atea of y 1
^d
yt
is shownin Fig.2.b
(areaI). In
areaI,
part of thearea
is
above the linelFlztxz-xr
(areaII),
which is itself
surroundedby
the threelines: y7:bx i,
!2:-ffi2
and ypy2*xz-xl.
When!1
andlz
are assigned valuesfrom
arealI,
y1 andy2 satisfu y12y2-rx2-x7, thatis,
a misperceptionwill
occur; a misperceptionwill
not occur
if
y7 andlz
are assigned valuesfrom any
other areain
I,
althoughpre-diction
errorswill
still
exist. Theprobability in
Eq.2 equals the double integral of theprobability
densityfunctions
of
predicted errors (i.e.,gtOt)
and g2Q2))on
areaII,
which
is calculatedin 8q.5.
v
r:bx
tP,0
P
y 2+x 2-x tl x 2- x p0):
l::,,_,. _
r,l^
j
"-'"
g' ( y ) g z(y z) dy zdy t- ax
r(x
z-x 1)<- ax 2<b xr(x
z-x r), x-.-x 7>0 r5)(l-a)x
1 (1+b)xt(l-a)x2
(l+DJX_r!Z:
ax:
IIFigure.3.
Casestudy 3 (a) the predicted
execution times of jobsJr
and "/2 overlapand the lower
limit
of predicted
execution
time of
aI2 coversxu; (b) the
corre-sponding coordinate area of predicted errors
of-/i
and JzOt
and/z)
in which
themisperception
occurs (the area is atrapezoid).
Fig.3.a illustrates
athird
case when the predicted executiontimes of
Jt
and Jzoverlap. The dilference
from
Fig.2.a is that the valuefield
ofJ:'s
predicted executiontime
coversx7. The
corresponding coordinate area
in
which
!1
andy2
satisfyyp42*xz-x7 is highlighted
as areaII
in
Fig.3.b. The areais
a trapezoid rather than atriangle
asin
Fig.2.b. The formulafor
calculating theprobability in Eq.2 is
alsodif-ferent from Eq.5; this is shown in Eq.6.
P,$,, 12 y 2+x z-x tl x
z-rr
t0):
l*,
y
r-(x z- x r)
g
{y)
g z(y z) dy z dy t-ax z3-ax
r(x
z-x t),' xz-xP0
(6)Eq.4-6 account
for all
possible relations between the predicted execution timesof
Suppose that the
probability
density functionof
ajobs'
actual executiontime m
ajob
streamisfix)
andthatthe
valuefield
of the real
executiontimex
is
[x/,xu].The
degree of misperception of this
job
stream, denoted bVMD,
is defined by the averageof
the degreeof
misperceptionfor
any twojobs in
thejob
stream.
MD
is computedusing Eq.7, where MD(x1,x2) is computed using Eq.4-6.
MD
= f:,'f:
f
Qr)f
(xz)MD(xr,xz)dx:dxrThere are several independent parameters in Eq.7, as
well
as in Eq.4-6: a, b, xu,xl,
f.r),
andgi(xi).It
is
highly
beneficial
to
studyhow
these parameters influence thevalue
of
Un;
this is the subject of the investigation in Section 3.2.2 Resource allocation
In
dedicated environments, the execution timeof
oneunit
of
work
can berepre-sented as a predicted
point
value
[0,
11,I2].
However,
in
non-dedicatedenviron-ments. the existence
of
background workloads on the resources causes a variation inunit
execution times[3,
10, 11,12]. Henceit
can be assumed that the actual executiontime
of
oneunit
of work
locates across a range around the predicted point valuefol-lowing
acertainprobability
[10, 12, 16].Suppose there is a distributed system consisting
of
n heterogeneous computers c7,c2,
..., c,.
Computer c;is weighted
wi(l<i3n),
which
represents the timeit
takes toperform
oneunit
of
computation.Now
supposefbr
any i,i
(l<i,i<n),
wi<wiif i<i. A
job with
size s is therefore predicted to have the executiontime swi on
computer c;.The predicted execution time of a
job
is denoted by,,,,that
is,(7)
However,
in
shared environments the actual executiontime
for
ajob with
size son computer c;
ma/
not be,sl.r/i, because of the existence of background workload. Theactual execution time of a
job
on c; is therefore denoted by *",.For
ajob with
size s,its predicted error on computer
c;, denoted by "vci, iScom-puted using Eq.9:
(e)
Suppose
y,; falls in
the rangel-sw1xa,.vlr,xb]
following
the probability densityfunction
gri(!"i).
Hence, x"; locates in the range[sw;x(l-a),
s]r,x(1+b)].For
two
computersci
and cy, supposethatwfw.,.
Then, the predicted executiontime
of
ajob with
size s on c; and c; satisfu sw1<s1v . However, the rangeof
thejob's
actual execution time on computer c;
is
[sw;x(l-a),
swix(1+b)] and may overlap withthat on computer cr,
which is [sw;x(1-a),
sw.,x(l+b)]. Consequently, the actualexecu-tion
time on computer
c;ma)
be greater than that onci.In
this
case, the inaccuratepredictions cause a misperception in the order of the actual execution times on these
two
computers. Depending on theindividual
scheduling algorithm, this misperceptionmay lead to the wrong selection
of
a computer to which thejob
is sent.Similarly,
thedegree of misperceptionfor a
job
with
size s on two computers ci and c7, denoted byMDr(ci,
c;), is definedby the probability
thatx,/s".1while
zcilZcr.This probability
isdenoted
by P,(x,/s"ilz"i<z), which
can be further transformedby Eq.t0 with
Eq.8and 9.
P,(x"/s"ilz";<z"i):P,(zrr!ri)- zrr-yrilzrfzr):P,(Jrt2
yci+swt-sw1lwt-
w/0)
(10)
That is,
MD,(ci,
cy) is computed using thefollowing
equation:Applying
asimilar method to that
usedto
compute MD(x1, x2), the equation forcomputing MD"(ci, c;) is expressed
formally
as foliows.MD"(c,"r=
{
bswt 1 -aswi
*
s(w1-wi)
pbvt-s(wi-wt) pbyt
|
|
B"(y",)gq(y4)dydy,,J-aw' J ya+s\uJ-w )
-
asrri+ s(w7-
wi) < bswt < bsw, + s(w1-
w,)?DSWi tD9i
| |
g,,ly,,)g,1(y"1)dy,1dy", bswl 2 bswi +s(wi-
w,) J-aswt Jyct+slwJ-wt)1n-ln
MD.=
+t
\,MD,7c,.c,1
f- z .? t_t v 2 t=l 1=11'1
(r2)
The degree of misperception
for
ajob
with size sfor
n heterogeneous computersct,
c2,...,
cn,denotedby MD,,
is defined using the average of the degree ofmisper-ception for the
job
on any two computers, which can be computed using Eq.13.(13)
3.
An
Evaluation
of
the Degree
of
Misperception
In
the previous section the general formula
for
the degreeof
misperceptionfor
both
job
selection and resource allocation were presented.In
this
section aninvesti-gation is
conducted asto how
the parametersin
these formulae impact on the valueassigned to the degree of misperception.
3.1
Job Selection
The parameters
a
and b represent the rangeof predicted
errorsin Eq.4-6.
Fig.4.aand Fig.4.b show the impact of the parameters
a
andb on the valueUn
.tt
is difflrcultto
evaluate the impactof
these parametersif
the probability densityfunction of
pre-dicted enors
takes a generalform.
Therefore in thefollowing
parameter evaluation,the predicted error
for
the execution time ofx
is
assumedto
follow
auniform
8,\!')
=(b +
a)x
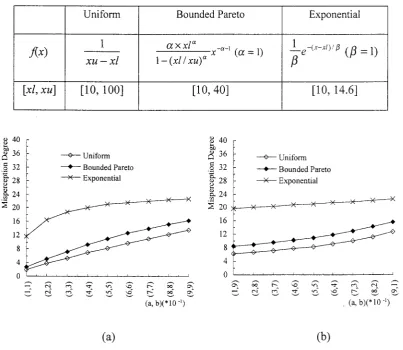
Three types of
job
stream are investigated. The actual execution timesin
thesejob
streams
follow
auniform,
Bounded Pareto and Exponential distribution, respectively.Theirprobability
densityfunctionsfx)
are shownin
Table
1.In
thejob
streamfol-lowing
the exponentialdistribution,
thejob
execution time has no upperlimit.
Onlyexecution time values
in
[10,
14.6] are considered, as 99o/oof
the execution timeslo-cate
in this
range accordingto its probability
densityfunction. This simplification
does not impact on the accuracy of the results.
Table
1.The range
ofjob
execution timesin
the threejob
streams40 36 28 1A 20 l6 t2 8 A 0
(a)
(b)Figure.4.
Impact of
the parameters
s
and
b on
l,tO
(a) the
impact of
the range
size of predicted
errors
(b) the impact
of the range location of predicted errorsu40 436 H o)z '5 Srn 9. rn
5zo
16 12 8 .l 0 o O o N6Sh€rqo N-Vn€r€o/a h\/*lA'l\
Uniform Bounded Pareto Exponential
JU)
1xu-
xl
e,x
xl"
-n-t .-x'
\u=t)
l-(xl
I xu)"lxl,
xu] [10, 100][10,40]
[10, 14.6]---+- Uniform
---i-
Bounded Pareto--x-
Exponential---9- Uniform
--f-
Bounded Pareto [image:13.595.97.501.358.708.2]In
Fig.4.a,
a
andb
increasefrom t0%
to
90o/owith
incrementsof
10%. Thismeans that the range
of
predictederror
for
the actual execution time ofx
increasesfrom
[-0.lx,0.lx]
to
[-0.9x,0.9x],
while
the
average predictederror remain
un-changed (at 0).
As can be observed
in Fig.4.a,
under all threeprobability
distributions, the degreeof misperception increases as a and b increase. This is because as a and b increase the
predicted execution times of
jobs
have a higher probability of overlappingwith
eachother, which leads
to the overall
increasein
UD.
This result suggests that when theaverage predicted error is the same, the range size of predicted errors is
critical for
thevalue
of
tvfD.
It
can also be observed that under the samea
and b, the degree of misperception ishighest under the exponential
distribution,
second highest under the Bound Paretodistribution
and the lowest under theuniform distribution. This is
because the sizeof
the range
of
actual execution times is smallest when the execution timesfollow
anex-ponential distribution and the largest when
following
auniform
distribution. Thisre-sult
suggests that the actual execution timeswill
also influence the degree ofmisper-ception. This is demonstrated in Fig.5.
In
Fig.4.b, the range sizeof
the predicted errorfor the
actual executiontime of x
remains unchanged (at
x), while
the locationof
the range shifts towards theleft from
[-0.lx,
0.9x]to [-0.9x, 0.lx].
The result of this is that the degree of misperceptionin-creases as the range
location shifts leftwards
(see Fig.4.b). The reasonfor
this is
asfollows.
Consider Fig.2.aand Fig.3.a. When (a, b) rs (0.1, 0.9), the range of predictederrors for xr and x2 ait? [-0.1x7, 0.9x7] and [-0.1x2 ,0.9x2], respectively. The size of the
range where the predicted execution times for xr and rc2 overlap is
When
(a,b)
is (0.9,0.1) however, the range of predicted errors are [-0.9x7,0.1x7] andf-0.9x2,0.Lx2f, respectively, and the size of the overlapping ranges is
0.9x2+0.lxrkz-xt)
Since x2 is greater than x7, hence,
0. 9xr+0. I x 2-(x 2-x 1)<0. 9x2+0. lx
7(x
2-x 1)this means that in general the size
of
the overlapping rangesis
greater when (a, b) ts(0.9, 0.1) than when (a, b) is (0.1, 0.9). This therefore leads to the increased degree
of
misperception.
This result
suggests that comparedwith
an overestimationof
execu-tion time, the
same levelof
underestimation may resultin
a higher degreeof
misper-ception. o40 i^ oJo aJ' .E g26
R rr
5ro
lo t2 8 4 o40 OFo
-.
AJO H AJL '5 Szs Ltd Ezo i6 t2 8 4 0 O\€r\On$Oal No.f,n€r€o, \or€o10NO$ i:-{: Nca$ocooo h€r€c\ (a)Figure.S.
The impact of actual
execution times on the degree of misperception (a)the
impact
of the range sizeof actual execution times
(b) the impact
of the rangelocation of actual
execution times(b)
---l- a h:O Q
---_6- ' . h:n qv v.J<
---<!- r h:O I
---l- a h=0 Q
----6- q h=n s
Fig.5.a and Fig.5.b show
the impact
of
actual executiontimes on the
degreeof
misperception. The results show the data
for
the actual execution timesfollowing
auniform
distribution; the resultsfor
the Bounded Pareto distribution display a similarpattern. This study does
not
consider the execution timeswith
an exponentialdistri-bution,
sincetheir range
size(xu-xl)
is fixed
when 99o/oof
the execution times areconsidered.
Fig.5.a shows
the impact
of
the sizeof
the rangeof
actual execution times (i.e.,xu-xl).In
this same figure, the average of the actual execution times remains the same(at
100)while
the range sizeof
execution times decreasesfrom
180 to 20with
decre-ments
of
20. This experiment is conductedwith
different valuesof a
and b.It
can beobserved
in
Fig.5.a thatfor
the
same valuesof
a andb,the
degreeof
misperceptionincreases as the range size decreases. The reason
for
this is
asfollows:
as the rangesize
of
the actual execution times decrease, the valueof
x2-x1(in
Fig.2.aor
Fig.3.a)decreases on average under the same
a
and b. As a result of this, the overlapping areaof
the two predicted execution times increases,which frnally
leadsto
an increasein
tttn
.
tt it
result
suggeststhat when the
average executiontimes are
the
same, agreater variance
in
execution time is of benefrt, as thiswill
reduce the degree ofmis-perception.
Fig.5.b
demonstrates the impactof
the locationof
the rangeof
actual executiontimes. In Fig.5.b, the range size
of
execution times remains constant (at 50) while therange shifts
from
[10,60]
to
[90,
140].As
can be seenin Fig.5.b,
the degreeof
mis-perception increases
in all
cases as the range location shiftsfrom
[10,60]
to
[90, 140].The reason
for this
is that
as the rangelocation shifts, the
mean execution timein-creases. Under the same
a
and b, the larger the actual executiontime,
the greater thehave
higher probability
of
overlappingwith
each other, which then incurs a higherdegree
of
misperception.This result
shows that when other parameters remaincon-stant, the
job
streamwith
the greater average execution time tends to cause the highestdegree of misperception.
3.2 Resource allocation
In
Eq.12 and 13, the parameters that influenceMD,
includethe error
rangepa-rameters
a
and b, the computer weight wi
and theprobability
density function ofpre-dicted errors
g"i(!ri).
in
thefollowing
experiments, the valuesof
these parameters aregiven in Table 2 unless otherwise stated.
Table
2.The default values of the parameters
for
the experimentationW1 wi-wi-r
Q<i<n)
n s10 5 6 50
In
thefollowing
figures, the predicted error for the executiontime of
x
is alsoas-sumed
to follow
auniform
distribution
in
l-asw6
bsw;], whoseprobability
densityfunction
g,i(!,i)
is expressed as follows:g"i(y"i) =
i"*,
The parameters
c
and b indicate the range of the predicted error. Fig.6.a shows theimpact
of
the range size
on WA
.
The result has a similar
patternto
that
seen inFig.4.a, which suggests that the range size
of predicted errors is also critical
for
thevalue
of
MD.
Similarly
to
Fig.4.b, Fig.6.b demonstrates the impactof
the rangelo-cation
on MD,. In
the study
of
resourceallocation,
lsw{I-a),
sw;(l+b)]
represents [image:17.595.125.470.374.437.2]to (9,
1) means that the predicted execution time swi changes graduallyfrom
anun-derestimate
to
an overestimate.In Fig.6.b
it
can be seenthat
MD"d,ecreases as (a, b)shifts
from
(1, 9) to
(9,
1). These results coincidewith
those seenin
Fig.4.b, in
thatcompared
with
an overestimateof
execution time, the same levelof
underestimationmay incur a higher degree of misperception.
840
oo
o 'lA
o-"
'g a165zo
16 12 8 4 0o An
oo
o iA 't *rl g >20 16 1) 8 4 0 -iat"o"qh"e"\-"c\ clo$r^€r€a
I^ hV+ln -l\
(a)
Figure.6.
Impact
of the parameters a and bon MD,
(a) the impact of the rangesize of
predicted
errors
(b) the impact of the range
location of
predicted errors
q6O o -"
Ssa
o-848 8+t E" :o
.2
E:o
24 18 t2 6 0l0 15 20 25 30 35 40 45
50 lllo6O o ""
S s'r
o-Eot
3+/
cJo .2 2:O 24 18 12 05 7.5
10 t2.5 15 17.5 20 tv22.5 25
(b)
---.-
a,b=O.1--€-
a,b=0.5--l-
a,b-0.9---+- a,b=O.1
--+-
a,b=0.5--r-
a,b-0.9Figure.7.
The impact
of
computer
weight
on
MD, (a) the impact of the
sizeof
computer weights (b) the impact
of theweight difference
between computersFig.7.a shows the impact
of
computer weighton MD,. In
Fig.7.a, the differenceof
the weight between computer ciand c;-7is fixed (at
5). As w7 increases (whichmeans that resource c1 becomes slower), the weights
of all
the remaining computersincrease accordingly.
As
can be observedin
Fig.7.a,
MD,
increases as w7 increasesunder
all
valuesof a
andb. This is
because as u/r increases, the rangeof
the actualexecution time
([sw;(l-a),
sw1(7+b)]) also increases. Thisin
turn
increases theprob-ability
that the rangeof
actual execution times on different computers overlap, whichfinally
leads to an increase d,-MD.
This result suggests that slower computers tend togenerate higher degrees of misperception than faster computers.
Fig.7.b
demonstratesthe
impact
of
weight
difference
between computers.In
Fig.7.b, the difference between
wi
andwi-1(2<i<n)
increaseswhile
the meanof
thesecomputer weights remains constant (at 70).
It
can be observedfrom this figure
thatMD,
decreases as rri-wi-t increases.This is
because zs wi-w;-l increases, thediffer-ence between the predicted execution times on
two
computersci
and c., (r.e.,sw;swi)
increases,
which
in
turn reduces theprobability that
the rangesof their
actualexecu-tion times overlap. This result
suggests that resource pools with higher heterogeneitywill
achieve a lower degree of misperception.4.
Conclusions
This
paper investigates the underlying impactof
inaccurate prediction onjob
se-lection and resource allocation.
A
new performance metric, termed the degree ofbeen developed
in
order to calculate the degreeof misperception
for
a varietyofjob
streams and
for distributed
resource pools of varying levels of heterogeneity. Thepa-rameters that influence the degree
of
misperception are also investigated.This
studywill
benefit the design and evaluation of different scheduling mechanismsfor parallel
and
distributed
systemsthat take prediction
into
account.It
is likely
that different
scheduling policies
will
havedifferent
levelsof
sensitivityto this
degreeof
misper-ception. Further work is planed to investigate how individual scheduling policies and
specific performance measures are affected by this new performance metric.
References
[1]
D.A
Bacigalupo, S.A Jawis,L
He,G.RNudd,
"An
Investigation into theApplica-tion of
Different
Performance Prediction Techniquesto
e-CommerceApplications,"
Submitted to the
International
Workshop on PerformanceModelling,
Evaluation andOptimization of
Parallel
and Distributed Systems, 18th IEEE International Paralleland Distributed Processing Symposium 2004 (IPDPS'04),
April
26-30, Sante Fe,New
Mexico, USA.
[2]
J Cao,D.P
Spooner, S.A Jarvis, S Saini, G.R Nudd. "Agent-based Grid LoadBal-ancing using Performance-driven Task Scheduling," ITth IEEE International
Parallel
and Distributed Processing Symposium 2003 (IPDPS'03),
Apri|22-26,
Nice, France.[3] Linguo
Gong,Xian-He
Sun and Edward F. Watson, "PetformanceModelling
andPrediction of Nondedicated
Networking Computing," IEEE
Transactions onComput-ers 2002, pp. 1 04 1-1 055.
[4]
Ligang
He,
S.A Jarvis, G.R Nudd, "Dynamic
Schedulingof
Parallel Real-timeJobs
by
Modelling
Spare Capabilitiesin
Heterogeneous Clusters," 2003 IEEE15]
Ligang He, S.A
Jarvis,D.P
Spooner, G.RNudd,
"Performance-based DynamicScheduling
of Hybrid
Real-timeApplications on
a Clusterof
HeterogeneousWork-stations,"
International
Conference onPorallel
andDistribiled
Computing (Euro-Par2003),26th -
29th August 2003, Klagenfurt, Austria.[6]
S.A
Jarvis,D. P
Spooner, FfNLim
Choi Keung, J Cao, S Saini, GR Nudd."Per-formance Prediction and its use
in
Parallel and Distributed Computing Systems,"In-ternationol
l|/orkshopon Performance
Modelling, Evaluation and Optimization
of
Parallel
andDistributed
Systems, 17thIEEE International Parallel
and DistributedProcessing Symposium 2003 (IPDPS'03),
Apr||22-26,
Nice, France.[7]
G.R. Nudd, D.J.Kerbyson et al, "PACE-a toolset for the performance predictionof
parallel
and distributed systems," International Journal ofHigh
PerformanceCom-puting Applications, Special Is sue s on P erformanc e
Modelling,
l4(3),
2000, 228-251.[8]
E.
Papaefstathiou,D.J.
Kerbyson, G.R. Nudd,D.V. Wilcox,
J.S. Harper, S.C.Perry,
"A
CommonWorkload Interface for
the Performance Predictionof High
Per-formance
Systems,"IEEE International
SymposiumOn
Computer Architecture,
Workshop on Performance Analysis in Design
(PAID'98),Barcelona,
1998.[9]
X.
Qin
andH.
Jiang,"Dynamic, Reliability-driven
Schedulingof
ParallelReal-time
Jobsin
Heterogeneous Systems," 30'hInternational
Conference onParallel
Processing, Valencia, Spain, September 3-7,
200I.
[10] Jennifer
M.
Schopf and Francine Berman, "Performance Prediction in ProductionEnvironments,"
I2th InternationalParallel
Processing Symposittmon
Parallel
andDistributed Processing (IPPS/SPDP '98), Orlando, Florida, 1998.
[11]
JenniferM.
Schopf and Francine Berman,"Using
Stochastic Information toFoun-dations of Computer Science, Special Issue on
Parallel Distributed
Computing,I2(3),
200t,34t-364.
[12]
JenniferM.
Schopf and Francine Berman, "Stochastic Scheduling,"SuperCom-puting
99, November 13-19, Portland Oregon, USA.U3]
W.
Smith,
I.
Foster, andV.
Taylor, "Predicting Application
Run Times UsingHistorical Information,"
Proceedings of the4th
Workshop on Job SchedulingStrate-gies
for
Parallel Processing,
1998.U4]
D.P
Spooner,S.A
Jarvis,J
Cao,S Saini, GR Nudd.
"Local Grid
SchedulingTechniques using Performance Prediction," IEE Proc. Comp.
Digit.
Tech.,150(2):87-96,2003.
[15]
X.Y.
Tang, S.T. Chanson,"Optimizing
staticjob
schedulingin
a network ofhet-erogeneous computers,;> 29th
International
Conference onParallel
Processing (ICPP2000), August