Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 286–295, Singapore, 6-7 August 2009. c2009 ACL and AFNLP
Fast, Cheap, and Creative: Evaluating Translation Quality
Using Amazon’s Mechanical Turk
Chris Callison-Burch
Center for Language and Speech Processing Johns Hopkins University
Baltimore, Maryland
ccb cs jhu edu
Abstract
Manual evaluation of translation quality is generally thought to be excessively time consuming and expensive. We explore a fast and inexpensive way of doing it using Amazon’s Mechanical Turk to pay small sums to a large number of non-expert an-notators. For $10 we redundantly recre-ate judgments from a WMT08 transla-tion task. We find that when combined non-expert judgments have a high-level of agreement with the existing gold-standard judgments of machine translation quality, and correlate more strongly with expert judgments than Bleu does. We go on to show that Mechanical Turk can be used to calculate human-mediated translation edit rate (HTER), to conduct reading compre-hension experiments with machine trans-lation, and to create high quality reference translations.
1 Introduction
Conventional wisdom holds that manual evalua-tion of machine translaevalua-tion is too time-consuming and expensive to conduct. Instead, researchers routinely use automatic metrics like Bleu (Pap-ineni et al., 2002) as the sole evidence of im-provement to translation quality. Automatic met-rics have been criticized for a variety of reasons (Babych and Hartley, 2004; Callison-Burch et al., 2006; Chiang et al., 2008), and it is clear that they only loosely approximate human judgments. Therefore, having people evaluate translation out-put would be preferable, if it were more practical. In this paper we demonstrate that the manual evaluation of translation quality is not as expensive or as time consuming as generally thought. We use Amazon’s Mechanical Turk, an online labor market that is designed to pay people small sums
of money to complete human intelligence tests– tasks that are difficult for computers but easy for people. We show that:
• Non-expert annotators produce judgments that are very similar to experts and that have a stronger correlation than Bleu.
• Mechanical Turk can be used for complex tasks like human-mediated translation edit rate (HTER) and creating multiple reference translations.
• Evaluating translation quality through read-ing comprehension, which is rarely done, can be easily accomplished through creative use of Mechanical Turk.
2 Related work
Snow et al. (2008) examined the accuracy of la-bels created using Mechanical Turk for a variety of natural language processing tasks. These tasks included word sense disambiguation, word simi-larity, textual entailment, and temporal ordering of events, but not machine translation. Snow et al. measured the quality of non-expert annotations by comparing them against labels that had been previously created by expert annotators. They re-port inter-annotator agreement between expert and non-expert annotators, and show that the average of many non-experts converges on performance of a single expert for many of their tasks.
Although it is not common for manual evalu-ation results to be reported in conference papers, several large-scale manual evaluations of machine translation quality take place annually. These in-clude public forums like the NIST MT Evalu-ation Workshop, IWSLT and WMT, as well as the project-specific Go/No Go evaluations for the DARPA GALE program. Various types of human judgments are used. NIST collects 5-point fluency and adequacy scores (LDC, 2005), IWSLT and
WMT collect relative rankings (Callison-Burch et al., 2008; Paul, 2006), and DARPA evaluates us-ing HTER (Snover et al., 2006). The details of these are provided later in the paper. Public eval-uation campaigns provide a ready source of gold-standard data that non-expert annotations can be compared to.
3 Mechanical Turk
Amazon describes its Mechanical Turk web ser-vice1asartificialartificial intelligence. The name and tag line refer to a historical hoax from the 18th century where an automaton appeared to be able to beat human opponents at chess using a clockwork mechanism, but was, in fact, controlled by a per-son hiding inside the machine. The Mechanical Turk web site provides a way to pay people small amounts of money to perform tasks that are sim-ple for humans but difficult for computers. Exam-ples of these Human Intelligence Tasks (or HITs) range from labeling images to moderating blog comments to providing feedback on relevance of results for a search query.
Anyone with an Amazon account can either submit HITs or work on HITs that were submit-ted by others. Workers are sometimes referred to as “Turkers” and people designing the HITs are “Requesters.” Requesters can specify the amount that they will pay for each item that is completed. Payments are frequently as low as $0.01. Turkers are free to select whichever HITs interest them.
Amazon provides three mechanisms to help en-sure quality: First, Requesters can have each HIT be completed by multiple Turkers, which allows higher quality labels to be selected, for instance, by taking the majority label. Second, the Re-quester can require that all workers meet a particu-lar set of qualications, such as sufficient accuracy on a small test set or a minimum percentage of previously accepted submissions. Finally, the Re-quester has the option of rejecting the work of in-dividual workers, in which case they are not paid.
The level of good-faith participation by Turkers is surprisingly high, given the generally small na-ture of the payment.2 For complex undertakings like creating data for NLP tasks, Turkers do not
1http://www.mturk.com/
2For an analysis of the demographics of
Turk-ers and why they participate, see: http:// behind-the-enemy-lines.blogspot.com/ 2008/03/mechanical-turk-demographics. html
have a specialized background in the subject, so there is an obvious tradeoff between hiring indi-viduals from this non-expert labor pool and seek-ing out annotators who have a particular expertise.
4 Experts versus non-experts
We use Mechanical Turk as an inexpensive way of evaluating machine translation. In this section, we measure the level of agreement between ex-pert and non-exex-pert judgments of translation qual-ity. To do so, we recreate an existing set of gold-standard judgments of machine translation quality taken from the Workshop on Statistical Machine Translation (WMT), which conducts an annual large-scale human evaluation of machine transla-tion quality. The experts who produced the gold-standard judgments are computational linguists who develop machine translation systems.
We recreated all judgments from the WMT08 German-English News translation task. The out-put of the 11 different machine translation systems that participated in this task was scored by ranking translated sentences relative to each other. To col-lect judgements, we reproduced the WMT08 web interface in Mechanical Turk and provided these instructions:
Evaluate machine translation qualityRank each transla-tion from Best to Worst relative to the other choices (ties are allowed). If you do not know the source language then you can read the reference translation, which was created by a professional human translator.
The web interface displaced 5 different machine translations of the same source sentence, and had radio buttons to rate them.
Turkers were paid a grand total of $9.75 to complete nearly 1,000 HITs. These HITs ex-actly replicated the 200 screens worth of expert judgments that were collected for the WMT08 German-English News translation task, with each screen being completed by five different Turkers. The Turkers were shown a source sentence, a ref-erence translation, and translations from five MT systems. They were asked to rank the translations relative to each other, assigning scores from best to worst and allowing ties.
We evaluate non-expert Turker judges by mea-suring their inter-annotator agreement with the WMT08 expert judges, and by comparing the cor-relation coefficient across the rankings of the ma-chine translation systems produced by the two sets of judges.
Sentence-level ranking
(2360 items compared)
Choose 1 2 3 4 5
run 1 run 2 run 3 run 4 run 5 run 6 run 7 run 8 run 9 run 10 Expert-Expert Agreement (56 items compared) Constituent-level ranking (4960 items compared) Choose run 1 run 2 run 3 run 4 run 5 run 6 run 7 run 8 run 9 run 10 Expert-Expert Agreement (339 items compared) Constituent-yes/no (4702 items compared) Choose run 1 run 2 run 3 run 4 run 5 run 6 run 7 run 8 run 9 run 10 Expert-Expert Agreement (294 items compared)
44.0% 51.6% 55.0% 56.8% 57.6% perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl perl analyze.perl sentence-ranking-Batch_25317_result.csv | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",RANK,"| perl ../process_judgements.pl
39.5% 51.9% 53.8% 57.0%
42.5% 51.6% 54.3% 57.5%
39.0% 53.9% 56.7% 57.6%
40.6% 51.9% 56.6% 57.1%
43.4% 49.0% 55.0% 56.2%
41.9% 52.7% 55.6% 57.6%
40.0% 47.9% 55.1% 56.6%
40.5% 49.6% 56.8% 57.6%
41.6% 47.3% 54.2% 58.4%
41.3% 50.7% 55.3% 57.2% 57.6%
41.1% 50.9% 54.9% 56.8% 57.8%<--weighted with non-experts<--weighted with non-experts
40.9% 50.6% 53.9% 57.1% 57.8%<--weighted with non-experts (only against same size choose)<--weighted with non-experts (only against same size choose)<--weighted with non-experts (only against same size choose)<--weighted with non-experts (only against same size choose) 41.5% 44.6% 47.9% 51.4% 53.0%<--- without weighting<--- without weighting
57.8% 57.8% 57.8% 57.8% 57.8% <--reported in WMT08 paper<--reported in WMT08 paper
cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",RANK," | perl ../process_judgements.pl
1 2 3 4 5
55.8% 54.8% 55.1% 53.2% 53.4% perl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.plperl analyze.perl constituent-ranking-Batch_25553_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl
55.8% 54.8% 55.1% 53.2% 53.4%
64.0% 64.0% 64.0% 64.0% 64.0% ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT," | perl ../process_judgements.pl
1 2 3 4 5
67.5% perl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plperl analyze-yes-no.perl constituent-yes-no-Batch_40756_result.csv.itemIDs_fixed | cat - ../wmt08-human-judgments.csv.expert_annotator_id | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.pl
67.5%
68.0% 68.0% 68.0% 68.0% 68.0% cat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.plcat ../wmt08-human-judgments.csv | grep German-English | grep -v Europarl | grep ",CONSTITUENT_ACCEPT," | perl ../process_judgements.pl
40% 45% 50% 55% 60%
1 2 3 4 5
Non-expert agreement with experts
Number of non-experts voting Unweighted
Weighted by non-experts Weighted by experts Expert v. Expert Agreement
Figure 1: Agreement on ranking translated sentences increases as more non-experts vote. Weighting non-experts’ votes based on agreement with either experts or other non-expert increases it up further. Five weighted non-experts reach the top line agreement between experts.
Combining ranked judgments Each item is re-dundantly judged by five non-experts. We would like to combine of their judgments into a single judgment. Combining ranked judgments it is more complicated than taking simple majority vote. We use techniques from preference voting, in which voters rank a group of candidates in order of pref-erence. To create an ordering from the the ranks assigned to the systems by multiple Turkers, we use Schulze’s method (Schulze, 2003). It is guar-anteed to correctly pick the winner that is pre-ferred pairwise over the other candidates. It fur-ther allows a complete ranking of candidates to be constructed, making it a suitable method for com-bining ranked judgments.
Figure 1 shows the effect of combining non-experts judgments on their agreement with ex-perts. Agreement is measured by examining each pair of translated sentence and counting when two annotators both indicated that A > B, A < B, or A =B. Chance agreement is 13. The top line indicates the inter-annotator agreement between WMT08 expert annotators, who agreed with each other 58% of the time. When we have only a sin-gle non-expert annotator’s judgment for each item, the agreement with experts is only 41%. As we increase the number of non-experts to five, their agreement with experts improves to 53%, if their Turker num HITs agreement A88B8YGW NRCDE A19P0XAP EMYVA4 AB1UOP54 VJ302 AHGV18N1 TW0U0 A17TQVV46 QFOPR A2KOG6YH XOH6NC A35JEX1CT HJ33Q A38NBJV89 Z0LZX AYMF2DS6 36OWV A2CGL84Z8 W7SBS A37CX0VE G3TG23 A1036VFVD H85DY A2Y4KSQZ JTFGGN A35Y70MA3 4AFQ6 A2XUF8U8 TMOZ15 AA0KYO0D ZS6WI A339F49S4 6I0EC A20YJNU6Y X5DMS A1XH9D9A 4NHG4 A1A6PCJW CD65GU A3VK3AVK Z6WE90 A1LZZD7E C0CUR5 AY1636IGK CLHY ACPRBLND ZYK62 A2MLF2ME MTX888 AMXXRYD C28BY8 A2AJJ7A2V LJR8V AVIKREHT NVTR5 AP914VPXZ EVUW AANG4NIT PGM9A A3JG7O1D F5P7TI A3IP9RZLIV 3UVJ A2IINUWLH XF4L7 A1O9BHBJ KVI5PS A1EVIR5BC W38EG A18B5QL32 8E02A A16YNOXG 4YX7W0 AZSX83KO OREJ0 AYWWEG6 5YVGCI AS65HZZ5T 2B0U A3MBIJON2 PHBNC A37JQWRR V7IS37 A2HBWOM 2DGNTCF A24ZRABM VOF68V A1FM4EOZ WGF6VV A19X9J18Q 19NGY AYUEYT9T ZJDGU AN7O7OLS 9ND8K A8H56XB9K 7DB5 A3FGNLFD OSH8W7 A36EOEBV BUTO85 A2U5YY5E2 KPTP2 A2SB2BW2 W4T4WW A20J9VGW RY6KCP A1OCUUH OWY8B52 A1MBZ6LM 7JZKP7 A1E8EDB7 UZK38D AUAZYGJW M6JLK A523O8LQ K0C6E A3V6V5LSC 4PN8H A3OHQRF1 MDQ99B A3MVGVHE 2HCERO A3LSSQO6 UWSKFR A3DOUTFZ 2DG53L A2WLPO1V YCAEQF A2LYIHZLR YIKPQ A2HNP1YL 1IBFMU A2CGQY6J ZGGLYP A2B8DTCHI 9U902 A2A4OZEX 98MVZS A25ZA4IBIE ZGNC A235PZXM LBGA4Q A1T4TJIPC OQOGP A1SXPREF GUADVY A1MI7U9VJ HRIPK A1KS77MY C4GGZ3 A1JQN7G6 S8158G A169X9KQI 7BMA3 A15A3FUIS ZDPI4 A14LPCJ1O 1773B 190 0.32321429 70 0.5710754 66 0.24120603 39 0.29553903 39 0.3436853 38 0.39960239 34 0.58924731 30 0.41605839 25 0.32698413 25 0.30027548 20 0.375 17 0.60888889 15 0.34259259 13 0.43842365 13 0.44970414 11 0.38922156 11 0.6 10 0.39751553 10 0.57236842 10 0.5 9 0.60759494 9 0.66666667 8 0.61151079 8 0.67346939 8 0.61983471 7 0.43220339 7 0.44615385 6 0.60683761 6 0.44859813 6 0.52941176 6 0.63265306 6 0.60833333 6 0.52136752 6 0.59183673 6 0.5 5 0.50943396 5 0.55905512 4 0.60526316 4 0.67708333 4 0.58 4 0.63218391 4 0.51041667 4 0.54545455 4 0.55660377 4 0.50515464 4 0.46938776 3 0.68131868 3 0.62790698 3 0.65853659 3 0.61842105 3 0.59210526 3 0.52631579 3 0.65384615 3 0.59210526 3 0.55714286 3 0.55263158 3 0.58571429 2 0.65151515 2 0.625 2 0.57352941 2 0.65151515 2 0.62121212 2 0.59090909 2 0.60294118 2 0.62121212 2 0.63636364 2 0.54545455 2 0.65151515 2 0.63768116 2 0.64705882 2 0.57575758 2 0.59090909 2 0.60606061 2 0.65151515 2 0.70512821 2 0.54545455 2 0.66666667 2 0.67948718 2 0.64473684 2 0.63235294 0 0.2 0.4 0.6 0.8
0 50 100 150 200
Agreement of individual Turkers v # HITS
Number of HITs completed
Turker Num HITs Agreement
AHHIWLEV WDLLL A2T20OFL M0TLDD A3A5BBI7T HNYAM A3CS8NKS 64RQEK A189OYGO EA9SE1 ATFFJKQ1 CSJRS ATZVHF3D 2AH3U A2XIZGKT9 7P8OQ A2LWJW1H UBILFO A38UZKXY E10BN7 AAGC1LGV UHGFM A23V9FCS ERQFF4 AVWJPWU EE3U4Q A3L4VHAI7 BMHC5 A13M4NKIO XIIYL A3FV4AOL7 N1JBS A1XH9D9A 4NHG4 A2HNP1YL 1IBFMU A2S44DG2 KJIR39 A15ENPH8 2MTLJF AIG9DJSR WGIY0 A1RXZQVZ XHYGB9 A3UQJGXM MOUVJQ AIQ1I6ODSI O56 A1CC4Z6E6 08UHR A2VO7B7F XDHM47 AH52LWLX YY5KT AB4WMS5 WKULFP AUAZYGJW M6JLK A3J51GPLV UTEVT A2B032AIP 4I6HH A2A4OZEX 98MVZS A3R5BMMS 0J77E4 A2V2IA1P5 MWP9H A2O7MKGT GDB2O5 A1HUS55R Z2IO4Q AG1TKYUK S97EV A3U6F7Q77 IZXIO AVUVW19F TPZX6 A3QKCDF WGN3QKL A3KEBTLZF JVKBG A2HNJBV33 OV5EZ A1IER46T8 7OQSH A1HAIFNO PYYZIJ A1FU5C6U S2L0J0 ARXKQFSE KTYID A3TY1HAD H82YAP A3RN8UHU A2H8YD A3NPGGTT ZXNZUL 300 0.39726734 200 0.68883878 157 0.63821138 151 0.721513 141 0.73357106 104 0.66446062 92 0.63443223 83 0.7 74 0.57422222 67 0.70319241 48 0.56639248 37 0.73545706 36 0.70944993 36 0.728739 31 0.7250384 29 0.64666667 28 0.70786517 22 0.72791519 18 0.55384615 15 0.71369295 13 0.57941834 13 0.6719457 12 0.69392523 11 0.69638554 11 0.59701493 10 0.61463415 9 0.60913706 9 0.71907216 8 0.66219839 8 0.60742706 8 0.67875648 8 0.70866142 7 0.62303665 7 0.69518717 6 0.72965879 6 0.64347826 4 0.68674699 4 0.69325153 3 0.66878981 3 0.66049383 3 0.68012422 3 0.68152866 3 0.7 3 0.67405063 3 0.67924528 2 0.67763158 2 0.67763158 2 0.69871795 2 0.67105263 0 0.2 0.4 0.6 0.8
0 75 150 225 300
Agreement of Individuals on Yes No
[image:3.595.72.289.59.261.2]Number of HITs completed
Figure 2: The agreement of individual Turkers with the experts. The most prolific Turker per-formed barely above chance, indicating random clicking. This suggests that users who contribute more tend to have lower quality.
votes are counted equally.
Weighting votes Not all Turkers are created equal. The quality of their works varies. Fig-ure 2 shows the agreement of individual Turkers with expert annotators, plotted against the num-ber of HITs they completed. The figure shows that their agreement varies considerably, and that Turker who completed the most judgments was among the worst performing.
To avoid letting careless annotators drag down results, we experimented with weighted voting. We weighted votes in two ways:
• Votes were weighted by measuring agree-ment with experts on the 10 initial judgagree-ments made. This would be equivalent to giving Turkers a pretest on gold standard data and then calibrating their contribution based on how well they performed.
• Votes were weighted based on how often one Turker agreed with the rest of the Turkers over the whole data set. This does not re-quire any gold standard calibration data. It goes beyond simple voting, because it looks at a Turker’s performance over the entire set, rather than on an item-by-item basis.
Figure 1 shows that these weighting mechanisms perform similarly well. For this task, deriving weights from agreement with other non-experts is as effective as deriving weights from experts. Moreover, by weighting the votes of five Turkers,
[image:3.595.316.503.62.221.2]E-all E0 E0.o E1 E1.o E2 E2.o E3 E3.o E4 E4.o E-all E0 E0.o E1 E1.o E2 E2.o E3 E3.o E4 E4.o N.ew.1.0 N.ew.1.1 N.ew.1.2 N.ew.1.3 N.ew.1.4 N.ew.1.5 N.ew.1.6 N.ew.1.7 N.ew.1.8 N.ew.1.9 N.ew.2.0 N.ew.2.1 N.ew.2.2 N.ew.2.3 N.ew.2.4 N.ew.2.5 N.ew.2.6 N.ew.2.7 N.ew.2.8 N.ew.2.9 N.ew.3.0 N.ew.3.1 N.ew.3.2 N.ew.3.3 N.ew.3.4 N.ew.3.5 N.ew.3.6 N.ew.3.7 N.ew.3.8 N.ew.3.9 N.ew.4.0 N.ew.4.1 N.ew.4.2 N.ew.4.3 N.ew.4.4 N.ew.4.5 N.ew.4.6 N.ew.4.7 N.ew.4.8 N.ew.4.9 N.ew.5.0 N.nw.1.0 N.nw.1.1 N.nw.1.2 N.nw.1.3 N.nw.1.4 N.nw.1.5 N.nw.1.6 N.nw.1.7 N.nw.1.8 N.nw.1.9 N.nw.2.0 N.nw.2.1 N.nw.2.2 N.nw.2.3 N.nw.2.4 N.nw.2.5 N.nw.2.6 N.nw.2.7 N.nw.2.8 N.nw.2.9 N.nw.3.0 N.nw.3.1 N.nw.3.2 N.nw.3.3 N.nw.3.4 N.nw.3.5 N.nw.3.6 N.nw.3.7 N.nw.3.8 N.nw.3.9 N.nw.4.0 N.nw.4.1 N.nw.4.2 N.nw.4.3 N.nw.4.4 N.nw.4.5 N.nw.4.6 N.nw.4.7 N.nw.4.8 N.nw.4.9 N.nw.5.0 N.uw.1.0 N.uw.1.1 N.uw.1.2 N.uw.1.3 N.uw.1.4 N.uw.1.5 N.uw.1.6 N.uw.1.7 N.uw.1.8 N.uw.1.9 N.uw.2.0 N.uw.2.1 N.uw.2.2 N.uw.2.3 N.uw.2.4 N.uw.2.5 N.uw.2.6 N.uw.2.7 N.uw.2.8 N.uw.2.9 N.uw.3.0 N.uw.3.1 N.uw.3.2 N.uw.3.3 N.uw.3.4 N.uw.3.5 N.uw.3.6 N.uw.3.7 N.uw.3.8 N.uw.3.9 N.uw.4.0 N.uw.4.1 N.uw.4.2 N.uw.4.3 N.uw.4.4 N.uw.4.5 N.uw.4.6 N.uw.4.7 N.uw.4.8 N.uw.4.9 N.uw.5.0 bleu
1 0.957 0.989 0.879 0.993 0.893 0.989 0.864 0.989 0.857 0.979
0.957 1 0.921 0.929 0.932 0.857 0.957 0.786 0.975 0.779 0.964
0.989 0.921 1 0.854 0.996 0.893 0.979 0.871 0.975 0.889 0.968
0.879 0.929 0.854 1 0.857 0.693 0.900 0.739 0.904 0.654 0.886
0.993 0.932 0.996 0.857 1 0.896 0.982 0.861 0.979 0.896 0.964
0.893 0.857 0.893 0.693 0.896 1 0.846 0.768 0.907 0.829 0.918
0.989 0.957 0.979 0.900 0.982 0.846 1 0.868 0.975 0.839 0.961
0.864 0.786 0.871 0.739 0.861 0.768 0.868 1 0.836 0.671 0.857
0.989 0.975 0.975 0.904 0.979 0.907 0.975 0.836 1 0.846 0.989
0.857 0.779 0.889 0.654 0.896 0.829 0.839 0.671 0.846 1 0.818
0.979 0.964 0.968 0.886 0.964 0.918 0.961 0.857 0.989 0.818 1
0.800 0.746 0.793 0.757 0.811 0.711 0.821 0.707 0.793 0.689 0.757
0.700 0.639 0.721 0.625 0.739 0.725 0.714 0.732 0.679 0.636 0.675
0.789 0.725 0.811 0.814 0.807 0.689 0.789 0.679 0.789 0.664 0.782
0.779 0.664 0.829 0.668 0.825 0.757 0.779 0.739 0.757 0.779 0.764
0.743 0.671 0.789 0.714 0.782 0.671 0.761 0.786 0.732 0.725 0.757
0.871 0.904 0.850 0.832 0.861 0.825 0.886 0.746 0.879 0.721 0.886
0.875 0.800 0.893 0.800 0.889 0.800 0.871 0.893 0.857 0.711 0.875
0.664 0.604 0.668 0.679 0.682 0.554 0.693 0.732 0.654 0.564 0.643
0.900 0.893 0.904 0.871 0.911 0.771 0.936 0.854 0.900 0.811 0.889
0.786 0.739 0.793 0.657 0.814 0.846 0.754 0.564 0.804 0.850 0.782 0.7679090909 0.804 0.743 0.829 0.771 0.825 0.786 0.793 0.704 0.825 0.736 0.821 0.0853592028
0.807 0.771 0.825 0.832 0.839 0.707 0.825 0.696 0.811 0.757 0.786
0.668 0.582 0.696 0.621 0.693 0.671 0.646 0.654 0.679 0.636 0.700
0.818 0.793 0.836 0.832 0.832 0.775 0.821 0.832 0.836 0.668 0.854
0.786 0.700 0.800 0.739 0.804 0.707 0.796 0.761 0.768 0.643 0.761
0.704 0.600 0.757 0.704 0.739 0.604 0.718 0.668 0.696 0.682 0.704
0.696 0.675 0.725 0.721 0.732 0.689 0.714 0.643 0.707 0.661 0.718
0.825 0.732 0.861 0.768 0.854 0.711 0.850 0.779 0.804 0.761 0.804
0.821 0.729 0.836 0.764 0.829 0.711 0.804 0.779 0.818 0.718 0.829
0.807 0.729 0.846 0.739 0.850 0.804 0.793 0.671 0.811 0.811 0.800 0.7546
0.836 0.746 0.861 0.739 0.868 0.796 0.821 0.718 0.836 0.829 0.821 0.0673480893
0.832 0.761 0.864 0.729 0.875 0.825 0.821 0.675 0.832 0.879 0.818
0.775 0.704 0.811 0.729 0.814 0.764 0.775 0.704 0.786 0.764 0.775
0.714 0.661 0.757 0.711 0.754 0.732 0.711 0.632 0.739 0.714 0.743
0.796 0.704 0.832 0.682 0.839 0.789 0.800 0.754 0.771 0.764 0.771
0.739 0.618 0.779 0.639 0.782 0.700 0.736 0.679 0.711 0.729 0.711
0.721 0.636 0.771 0.707 0.761 0.664 0.729 0.757 0.729 0.711 0.739
0.764 0.700 0.804 0.739 0.800 0.696 0.782 0.779 0.764 0.739 0.775
0.743 0.693 0.779 0.743 0.782 0.743 0.739 0.625 0.764 0.736 0.754
0.800 0.700 0.829 0.729 0.832 0.704 0.811 0.682 0.779 0.775 0.764 0.7559
0.743 0.654 0.796 0.704 0.793 0.707 0.754 0.664 0.736 0.761 0.732 0.0562407913
0.718 0.632 0.771 0.675 0.768 0.700 0.729 0.661 0.714 0.746 0.718
0.843 0.775 0.875 0.757 0.886 0.814 0.843 0.700 0.843 0.875 0.821
0.786 0.689 0.836 0.721 0.832 0.729 0.796 0.686 0.768 0.793 0.764
0.714 0.611 0.768 0.661 0.764 0.675 0.725 0.732 0.696 0.711 0.707
0.739 0.661 0.782 0.711 0.786 0.711 0.743 0.632 0.743 0.761 0.729
0.775 0.707 0.804 0.743 0.807 0.682 0.800 0.654 0.761 0.757 0.754
0.754 0.693 0.804 0.743 0.796 0.736 0.750 0.618 0.768 0.779 0.771
0.796 0.711 0.850 0.746 0.836 0.746 0.796 0.750 0.800 0.800 0.814
0.739 0.636 0.793 0.671 0.789 0.707 0.750 0.700 0.721 0.746 0.725 0.7468
0.0574048555
0.743 0.654 0.796 0.704 0.793 0.707 0.754 0.664 0.736 0.761 0.732 0.7312727273
0.546 0.504 0.571 0.546 0.564 0.539 0.568 0.425 0.543 0.536 0.568
0.771 0.682 0.814 0.721 0.804 0.689 0.793 0.711 0.768 0.764 0.764
0.900 0.875 0.889 0.814 0.882 0.889 0.868 0.904 0.914 0.679 0.946
0.686 0.711 0.661 0.739 0.686 0.643 0.718 0.596 0.704 0.557 0.689
0.736 0.721 0.768 0.789 0.754 0.700 0.750 0.718 0.757 0.629 0.793
0.854 0.832 0.868 0.868 0.864 0.786 0.864 0.782 0.879 0.729 0.875
0.871 0.825 0.864 0.789 0.861 0.721 0.889 0.782 0.861 0.775 0.864
0.746 0.686 0.736 0.654 0.764 0.682 0.739 0.532 0.743 0.782 0.686
0.807 0.746 0.796 0.775 0.814 0.696 0.811 0.679 0.779 0.643 0.757
0.704 0.661 0.704 0.711 0.707 0.564 0.754 0.579 0.693 0.632 0.668 0.7362636364 0.821 0.761 0.857 0.804 0.854 0.754 0.839 0.725 0.825 0.771 0.814 0.1071247817
0.782 0.704 0.825 0.725 0.821 0.754 0.786 0.686 0.789 0.800 0.786
0.829 0.746 0.839 0.786 0.850 0.689 0.839 0.696 0.807 0.761 0.786
0.596 0.500 0.657 0.618 0.646 0.550 0.618 0.664 0.600 0.604 0.596
0.800 0.768 0.839 0.857 0.821 0.718 0.811 0.743 0.825 0.707 0.836
0.714 0.679 0.750 0.729 0.761 0.679 0.739 0.604 0.714 0.729 0.704
0.689 0.629 0.682 0.604 0.707 0.704 0.679 0.489 0.686 0.671 0.654
0.743 0.671 0.775 0.689 0.779 0.729 0.754 0.829 0.729 0.650 0.743
0.811 0.732 0.854 0.796 0.839 0.679 0.839 0.775 0.789 0.732 0.804
0.800 0.718 0.811 0.729 0.814 0.768 0.775 0.668 0.786 0.675 0.793 0.7396272727 0.846 0.754 0.850 0.750 0.861 0.779 0.829 0.782 0.832 0.725 0.821 0.0794354922
0.739 0.646 0.775 0.679 0.779 0.675 0.757 0.679 0.721 0.736 0.718
0.700 0.607 0.743 0.661 0.739 0.675 0.700 0.718 0.707 0.696 0.711
0.764 0.671 0.782 0.704 0.789 0.714 0.761 0.746 0.739 0.636 0.743
0.864 0.839 0.879 0.864 0.889 0.779 0.882 0.746 0.864 0.775 0.850
0.768 0.686 0.793 0.732 0.800 0.661 0.793 0.779 0.746 0.704 0.743
0.757 0.664 0.782 0.736 0.771 0.639 0.775 0.764 0.739 0.625 0.754
0.836 0.757 0.846 0.789 0.854 0.707 0.846 0.768 0.825 0.757 0.811
0.729 0.707 0.754 0.761 0.757 0.704 0.736 0.564 0.754 0.718 0.750
0.832 0.761 0.861 0.768 0.868 0.779 0.836 0.725 0.836 0.832 0.818 0.7593363636 0.825 0.711 0.879 0.725 0.864 0.775 0.814 0.793 0.811 0.807 0.829 0.0655079346
0.718 0.636 0.768 0.711 0.761 0.664 0.739 0.714 0.714 0.689 0.718
0.786 0.707 0.836 0.750 0.821 0.704 0.804 0.757 0.775 0.761 0.796
0.764 0.664 0.818 0.693 0.807 0.714 0.775 0.761 0.750 0.761 0.768
0.693 0.611 0.750 0.704 0.739 0.632 0.707 0.639 0.693 0.707 0.700
0.789 0.729 0.825 0.779 0.832 0.714 0.807 0.668 0.782 0.779 0.764
0.725 0.625 0.786 0.689 0.771 0.664 0.736 0.721 0.711 0.725 0.732
0.814 0.732 0.861 0.746 0.854 0.761 0.825 0.739 0.811 0.821 0.814
0.768 0.675 0.818 0.700 0.814 0.739 0.779 0.725 0.761 0.775 0.761
0.743 0.643 0.800 0.650 0.793 0.736 0.754 0.704 0.729 0.775 0.739 0.7502181818 0.0566353833
0.739 0.646 0.793 0.682 0.789 0.736 0.739 0.682 0.739 0.761 0.739 0.7313636364
0.811 0.711 0.846 0.746 0.839 0.714 0.821 0.739 0.800 0.775 0.796
0.729 0.679 0.736 0.761 0.725 0.625 0.750 0.657 0.711 0.507 0.721
0.739 0.643 0.761 0.700 0.757 0.586 0.775 0.846 0.707 0.625 0.714
0.879 0.832 0.861 0.786 0.879 0.854 0.839 0.711 0.879 0.739 0.857
0.682 0.625 0.725 0.700 0.711 0.668 0.679 0.693 0.714 0.661 0.732
0.711 0.650 0.757 0.671 0.732 0.764 0.675 0.604 0.736 0.679 0.779
0.854 0.754 0.875 0.796 0.864 0.739 0.839 0.879 0.836 0.679 0.850
0.800 0.736 0.836 0.782 0.821 0.746 0.796 0.707 0.829 0.761 0.814
0.886 0.829 0.907 0.804 0.893 0.775 0.893 0.832 0.893 0.850 0.896
0.764 0.696 0.800 0.718 0.789 0.782 0.732 0.750 0.779 0.689 0.814 0.7625454545 0.825 0.750 0.868 0.757 0.861 0.804 0.811 0.682 0.836 0.832 0.832 0.0784769745
0.879 0.804 0.911 0.793 0.907 0.793 0.871 0.764 0.857 0.839 0.871
0.771 0.689 0.818 0.743 0.814 0.707 0.786 0.661 0.768 0.779 0.757
0.804 0.686 0.854 0.693 0.843 0.764 0.800 0.814 0.779 0.757 0.800
0.761 0.671 0.807 0.704 0.804 0.739 0.764 0.704 0.764 0.768 0.761
0.764 0.711 0.796 0.768 0.789 0.721 0.754 0.739 0.789 0.718 0.804
0.879 0.804 0.907 0.800 0.914 0.811 0.868 0.736 0.875 0.879 0.861
0.804 0.711 0.846 0.786 0.832 0.646 0.821 0.750 0.786 0.761 0.793
0.843 0.768 0.886 0.821 0.879 0.721 0.854 0.768 0.836 0.821 0.836
0.714 0.625 0.761 0.718 0.754 0.643 0.711 0.704 0.718 0.696 0.725 0.7846
0.832 0.789 0.854 0.793 0.861 0.804 0.814 0.757 0.850 0.804 0.854 0.0639298928
0.807 0.775 0.818 0.829 0.825 0.668 0.832 0.661 0.807 0.757 0.796
0.729 0.675 0.754 0.761 0.757 0.632 0.761 0.650 0.721 0.650 0.711
0.746 0.625 0.796 0.679 0.786 0.671 0.746 0.782 0.714 0.686 0.739
0.771 0.650 0.811 0.679 0.800 0.704 0.761 0.800 0.739 0.682 0.771
0.886 0.825 0.914 0.825 0.918 0.829 0.882 0.757 0.893 0.864 0.879
0.779 0.696 0.821 0.761 0.814 0.679 0.793 0.793 0.775 0.746 0.782
0.857 0.775 0.889 0.761 0.896 0.821 0.846 0.718 0.854 0.868 0.839
0.875 0.775 0.918 0.779 0.911 0.800 0.864 0.768 0.861 0.861 0.864
0.754 0.675 0.789 0.704 0.796 0.729 0.757 0.704 0.757 0.761 0.746 0.7819
0.789 0.664 0.839 0.671 0.829 0.768 0.771 0.775 0.775 0.771 0.793 0.0698718289
0.829 0.736 0.875 0.761 0.864 0.746 0.846 0.818 0.811 0.779 0.821
0.832 0.729 0.861 0.771 0.850 0.725 0.821 0.782 0.825 0.750 0.832
0.871 0.771 0.914 0.782 0.907 0.775 0.871 0.775 0.850 0.850 0.854
0.850 0.754 0.896 0.754 0.889 0.814 0.839 0.739 0.846 0.854 0.846
0.725 0.621 0.775 0.721 0.761 0.618 0.736 0.686 0.714 0.693 0.721
0.832 0.743 0.879 0.757 0.871 0.771 0.843 0.768 0.825 0.825 0.825
0.796 0.693 0.843 0.718 0.832 0.711 0.811 0.768 0.775 0.775 0.789
0.775 0.671 0.804 0.707 0.811 0.704 0.764 0.629 0.757 0.764 0.743
0.818 0.707 0.850 0.725 0.843 0.714 0.818 0.768 0.796 0.775 0.807 0.7852818182 0.0622027068
0.818 0.725 0.864 0.732 0.857 0.757 0.829 0.750 0.804 0.818 0.811 0.7968181818
0.321 0.328 0.292 0.353 0.263 0.149 0.374 0.353 0.306 0.135 0.349
Choose
1 2 3 4 5
unweighted 0.7625454545 0.7846 0.7819 0.7852818182 0.7968181818 non-expert weights0.7362636364 0.7625454545 0.7593363636 0.7502181818 0.7313636364 expert weights 0.7679090909 0.7546 0.7559 0.7468 0.7313636364
1 2 3 4 5
unweighted expert weights non-expert expert-expert BLEU
0.7625454545 0.7846 0.7819 0.7852818182 0.7968181818 0.7679090909 0.7546 0.7559 0.7468 0.7313636364
0.7362636364 0.7625454545 0.7593363636 0.7502181818 0.7313636364
0.778 0.778 0.778 0.778 0.778
0.293 0.293 0.293 0.293 0.293
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1 2 3 4 5
Correlation with Expert ranking of systems
Unweighted Non-expert weights Expert-Expert BLEU 0 0.225 0.45 0.675 0.9 unweighted
[image:4.595.73.285.66.237.2]expert weightsnon-expertexpert-expert BLEU Spearman’s correlation
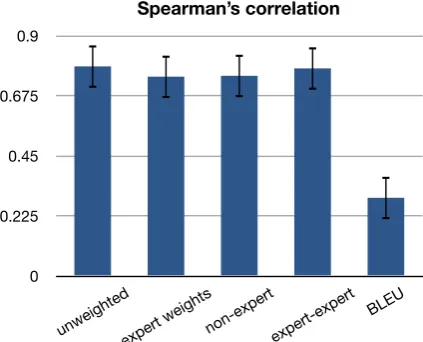
Figure 3: Correlation with experts’ ranking of sys-tems. All of the different ways of combining the non-expert judgments perform at the upper bound of expert-expert correlation. All correlate more strongly than Bleu.
we are able to achieve the same rate of agreement with experts as they achieve with each other.
Correlation when ranking systems In addi-tion to measuring agreement with experts at the sentence-level, we also compare non-expert
system-level rankings with experts. Following Callison-Burch et al. (2008), we assigned a score to each of the 11 MT systems based on how of-ten its translations were judged to be better than or equal to any other system. These scores were used to rank systems and we measured Spearman’s ρ against the system-level ranking produced by ex-perts.
Figure 3 shows how well the non-expert rank-ings correlate with expert rankrank-ings. An up-per bound is indicated by the expert-expert bar. This was created using a five-fold cross valida-tion where we used 20% of the expert judgments to rank the systems and measured the correlation against the rankings produced by the other 80% of the judgments. This gave aρof 0.78. All ways of combining the non-expert judgments resulted in nearly identical correlation, and all produced cor-relation within the range of with what we would experts to.
The rankings produced using Mechanical Turk had a much stronger correlation with the WMT08 expert rankings than the Blue score did. It should be noted that the WMT08 data set does not have multiple reference translations. If multiple
ref-erences were used that Bleu would likely have stronger correlation. However, it is clear that the cost of hiring professional translators to create multiple references for the 2000 sentence test set would be much greater than the $10 cost of col-lecting manual judgments on Mechanical Turk.
5 Feasibility of more complex evaluations
In this section we report on a number of cre-ative uses of Mechanical Turk to do more so-phisticated tasks. We give evidence that Turkers can create high quality translations for some lan-guages, which would make creating multiple ref-erence translations for Bleu less costly than using professional translators. We report on experiments evaluating translation quality with HTER and with reading comprehension tests.
5.1 Creating multiple reference translations
In addition to evaluating machine translation qual-ity, we also investigated the possibility of using Mechanical Turk to create additional reference translations for use with automatic metrics like Bleu. Before trying this, we were skeptical that Turkers would have sufficient language skills to produce translations. Our translation HIT had the following instructions:
Translate these sentencesYour task is to translate 10 sen-tences into English. Please make sure that your English translation:
• Is faithful to the original in both meaning and style
• Is grammatical, fluent, and natural-sounding English
• Does not add or delete information from the original text
• Does not contain any spelling errors When creating your translation, please:
• Do not use any machine translation systems
• You may look up a word on wordreference.com if you do not know its translation
Afterwards, we’ll ask you a few quick questions about your language abilities.
We solicited translations for 50 sentences in French, German, Spanish, Chinese and Urdu, and designed the HIT so that five Turkers would trans-late each sentence.
Filtering machine translation Upon inspecting the Turker’s translations it became clear that many had ignored the instructions, and had simply cut-and-paste machine translation rather then translat-ing the text themselves. We therefore set up a sec-ond HIT to filter these out. After receiving the
Topline MTurk MT Topline MTurk MT Spanish
German French Chinese Urdu
0.54 0.50 0.41 Spanish STDDEV 0.07 0.03 0.02 0.54 0.48 0.33 German STDDEV 0.07 0.02 0.02 0.54 0.33 0.25 French STDDEV 0.07 0.02 0.01 0.54 0.52 0.24 Chinese STDDEV 0.07 0.02 0.00 0.32 0.21 0.14 Urdu STDDEV 0.02 0.02 0.01
0 0.10 0.20 0.30 0.40 0.50 0.60
Spanish German French Chinese
Bleu scores of professional translators, Mechanical Turk, and MT
1 LDC translator v. other LDC translators Mechanical Turk v. other LDC MT v. other LDC
0 0.10 0.20 0.30 0.40 0.50 0.60
[image:5.595.104.465.65.224.2]Urdu
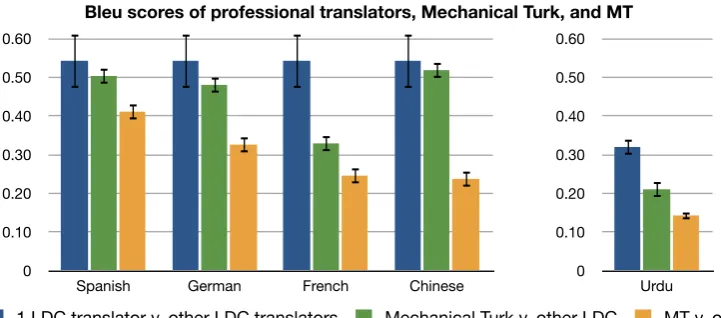
Figure 4: Bleu scores quantifying the quality of Turkers’ translations. The chart shows the average Bleu score when one LDC translator is compared against the other 10 translators (or the other 2 translators in the case of Urdu). This gives an upper bound on the expected quality. The Turkers’ translation quality falls within a standard deviation of LDC translators for Spanish, German and Chinese. For all languages, Turkers produce significantly better translations than an online machine translation system.
translations, we had a second group of Turkers clean the results.
Detect machine translationPlease use two online machine translation systems to translate the text into English, and then copy-and-paste the translations into the boxes below. Finally, look at a list of translations below and click on the ones that look like they came from the online translation services.
We automatically excluded Turkers whose transla-tions were flagged 30% of the time or more.
Quality of Turkers’ translations Our 50 sen-tence test sets were selected so that we could com-pare the translations created by Turkers to transla-tions commissioned by the Linguistics Data Con-sortium. For the Chinese, French, Spanish, and German translations we used the the Multiple-Translation Chinese Corpus.3 This corpus has 11 reference human translations for each Chinese source sentence. We had bilingual graduate stu-dents translate the first 50 English sentences of that corpus into French, German and Spanish, so that we could re-use the multiple English reference translations. The Urdu sentences were taken from the NIST MT Eval 2008 Urdu-English Test Set4 which includes three distinct English translations for every Urdu source sentence.
Figure 4 shows the Turker’s translation quality in terms of the Bleu metric. To establish an upper bound on expected quality, we determined what
3LDC catalog number LDC2002T01 4LDC catalog number LDC2009E11
the Bleu score would be for a professional trans-lator when measured against other professionals. We calculated a Bleu score for each of the 11 LDC translators using the other 10 translators as the reference set. The average Bleu score for LDC2002T01 was 0.54, with a standard deviation of 0.07. The average Bleu for the Urdu test set is lower because it has fewer reference translations.
To measure the Turkers’ translation quality, we randomly selected translations of each sentence from Turkers who passed the Detect MT HIT, and compared them against the same sets of 10 ref-erence translations that the LDC translators were compared against. We randomly sampled the Turkers 10 times, and calculated averages and standard deviations for each source language. Fig-ure 4 the Bleu scores for the Turkers’ translations of Spanish, German and Chinese are within the range of the LDC translators. For all languages, the quality is significantly higher than an online machine translation system. We used Yahoo’s Ba-belfish for Spanish, German, French and Chinese,5 was likely and Babylon for Urdu.
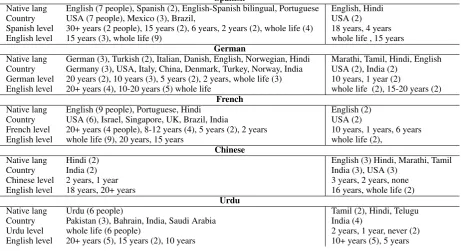
Demographics We collected demographic in-formation about the Turkers who completed the translation task. We asked how long they had ken the source language, how long they had
spo-5We also compared against Google Translate, but
ex-cluded the results since its average Bleu score was better than the LDC translators, likely because the test data was used to train Google’s statistical system.
Spanish
Native lang English (7 people), Spanish (2), English-Spanish bilingual, Portuguese English, Hindi
Country USA (7 people), Mexico (3), Brazil, USA (2)
Spanish level 30+ years (2 people), 15 years (2), 6 years, 2 years (2), whole life (4) 18 years, 4 years
English level 15 years (3), whole life (9) whole life , 15 years
German
Native lang German (3), Turkish (2), Italian, Danish, English, Norwegian, Hindi Marathi, Tamil, Hindi, English Country Germany (3), USA, Italy, China, Denmark, Turkey, Norway, India USA (2), India (2)
German level 20 years (2), 10 years (3), 5 years (2), 2 years, whole life (3) 10 years, 1 year (2)
English level 20+ years (4), 10-20 years (5) whole life whole life (2), 15-20 years (2)
French
Native lang English (9 people), Portuguese, Hindi English (2)
Country USA (6), Israel, Singapore, UK, Brazil, India USA (2)
French level 20+ years (4 people), 8-12 years (4), 5 years (2), 2 years 10 years, 1 years, 6 years
English level whole life (9), 20 years, 15 years whole life (2),
Chinese
Native lang Hindi (2) English (3) Hindi, Marathi, Tamil
Country India (2) India (3), USA (3)
Chinese level 2 years, 1 year 3 years, 2 years, none
English level 18 years, 20+ years 16 years, whole life (2)
Urdu
Native lang Urdu (6 people) Tamil (2), Hindi, Telugu
Country Pakistan (3), Bahrain, India, Saudi Arabia India (4)
Urdu level whole life (6 people) 2 years, 1 year, never (2)
[image:6.595.72.534.69.320.2]English level 20+ years (5), 15 years (2), 10 years 10+ years (5), 5 years
Table 1: Self-reported demographic information from Turkers who completed the translation HIT. The statistics on the left are for people who appeared to do the task honestly. The statistics on the right are for people who appeared to be using MT (marked as using it 20% or more in the Detect MT HIT).
ken English, what their native language was, and where they lived. Table 1 gives their replies.
Cost and speed We paid Turkers $0.10 to trans-late each sentence, and $0.006 to detect whether a sentence was machine translated. The cost is low enough that we could create a multiple reference set quite cheaply; it would cost less than $1,000 to create 4 reference translations for 2000 sentences. The time it took for the 250 translations to be completed for each language varied. It took less than 4 hours for Spanish, 20 hours for French, 22.5 hours for German, 2 days for Chinese, and nearly 4 days for Urdu.
5.2 HTER
Human-mediated translation edit rate (HTER) is the official evaluation metric of the DARPA GALE program. The evaluation is conducted an-nually by the Linguistics Data Consortium, and it is used to determine whether the teams partic-ipating the program have met that year’s bench-marks. These evaluations are used as a “Go / No Go” determinant of whether teams will continue to receive funding. Thus, each team have a strong incentive to get as good a result as possible under the metric.
Each of the three GALE teams encompasses
multiple sites and each has a collection of ma-chine translation systems. A general strategy em-ployed by all teams is to perform system combi-nation over these systems to produce a synthetic translation that is better than the sum of its parts (Matusov et al., 2006; Rosti et al., 2007). The con-tribution of each component system is weighted by the expectation that it will produce good out-put. To our knowledge, none of the teams perform their own HTER evaluations in order to set these weights.
We evaluated the feasibility of using Mechan-ical Turk to perform HTER. We simplified the official GALE post-editing guidelines (NIST and LDC, 2007). We provided these instructions:
Edit Machine TranslationYour task is to edit the machine translation making as few changes as possible so that it matches the meaning of the human translation and is good English. Please follow these guidelines:
• Change the machine translation so that it has the same meaning as the human translation.
• Make the machine translation into intelligible English.
• Use as few edits as possible.
• Do not insert or delete punctuation simply to follow traditional rules about what is “proper.”
• Pleasedo notcopy-and-paste the human translation into the machine translation.
Number of editors
System 0 1 2 3 4 5
google.fr-en .44 .29 .24 .22 .20 .19
google.de-en .48 .34 .30 .28 .25 .24
rbmt5.de-en .53 .41 .33 .28 .27 .25
geneva.de-en .65 .56 .50 .48 .45 .45
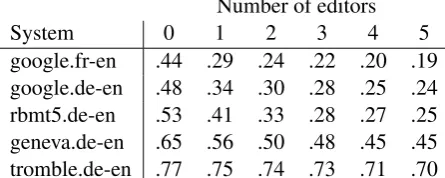
tromble.de-en .77 .75 .74 .73 .71 .70 Table 2: HTER scores for five MT systems. The edit rate decreases as the number of editors in-creases from zero (where HTER is simply the TER score between the MT output and the reference translation) and five.
We displayed 10 sentences from a news article. In one column was the reference English translation, in the other column were text boxes containing the MT output to be edited. To minimize the edit rate, we collected edits from five different Turkers for every machine translated segment. We verified these with a second HIT were we prompted Turk-ers to:
Judge edited translationsFirst, read the reference human translation. After that judge the edited machine translation using two criteria:
• Does the edited translation have the same meaning as the reference human translation?
• Is it acceptable English? Some small errors are OK, so long as its still understandable.
For the final score, we choose the edited segment which passed the criteria and which minimized the edit distance to the unedited machine translation output. If none of the five edits was deemed to be acceptable, then we used the edit distance between the MT and the reference.
Setup We evaluated five machine translation systems using HTER. These systems were se-lected from WMT09 (Callison-Burch et al., 2009). We wanted a spread in quality, so we took the top two and bottom two systems from the German-English task, and the top system from the French-English task (which significantly outperformed everything else). Based on the results of the WMT09 evaluation we would expect the see the following ranking from the least edits to the most edits: google.fr-en, google.de-en, rbmt5.de-en, geneva.de-en and tromble.de-en.
[image:7.595.73.296.66.155.2]Results Table 2 gives the HTER scores for the five systems. Their ranking is as predicted, indi-cating that the editing is working as expected. The
table reports averaged scores when the five anno-tators are subsampled. This gives a sense of how much each additional editor is able to minimize the score for each system. The difference between the TER score with zero editors, and the HTER five editors is greatest for the rmbt5 system, which has a delta of .29 and is smallest for jhu-tromble with .07.
5.3 Reading comprehension
One interesting technique for evaluating machine translation quality is through reading comprehen-sion questions about automatically translated text. The quality of machine translation systems can be quantified based on how many questions are an-swered correctly.
Jones et al. (2005) evaluated translation quality using a reading comprehension test the Defense Language Proficiency Test (DLPT), which is ad-ministered to military translators. The DLPT con-tains a collection of foreign articles of varying lev-els of difficulties, and a set of short answer ques-tions. Jones et al used the Arabic DLPT to do a study of machine translation quality, by automat-ically translating the Arabic documents into En-glish and seeing how many human subjects could successfully pass the exam.
The advantage of this type of evaluation is that the results have a natural interpretation. They indi-cate how understandable the output of a machine translation system is better than Bleu does, and better than other manual evaluation like the rela-tive ranking. Despite this advantage, evaluating MT through reading comprehension hasn’t caught on, due to the difficulty of administering it and due to the fact that the DLPT or similar tests are not publicly available.
We conducted a reading comprehension evalua-tion using Mechanical Turk. Instead of simply ad-ministering the test on Mechanical Turk, we used it for all aspects from test creation to answer grad-ing. Our procedure was as follows:
Test creation We posted human translations of foreign news articles, and ask Tukers to write three questions and provide sample answers. We gave simple instructions on what qualifies as a good reading comprehension question.
Reading comprehension testPlease read the short news-paper article, and then write three reading comprehension questions about it, giving sample answers for each of your questions. Good reading comprehension questions:
• Ask about why something happened or why someone did something.
• Ask about relationships between people or things.
• Should be answerable in a few words. Poor reading comprehension questions:
• Ask about numbers or dates.
• Only require a yes/no answer.
Question selection We posted the questions for each article back to Mechanical Turk, and asked other Turkers to vote on whether each question was a good and to indicate if it was redundant with any other questions in the set. We sorted questions to maximize the votes and minimized redundan-cies using a simple perl script, which discarded questions below a threshold, and eliminated all re-dundancies.
Taking the test We posted machine translated versions of the foreign articles along with the questions, and had Turkers answer them. We en-sured that no one would see multiple translations of the same article.
Answer questions about a machine translated textYou will answer questions about an article that has been automat-ically translated from another language into English. The translation contains many errors, but the goal is to see how understandable it is. Please do your best to guess at the right answers to the questions. Please:
• Read through the automatically translated article.
• Answer the questions listed below, using just a few words.
• Give your best guess at the answers, even if the trans-lation is hard to understand.
• Don’t use any other information to answer the ques-tions.
Grading the answers We aggregated the answers and used Mechanical Turk to grade them. We showed the human translation of the article, one question, the sample answer, and displayed all answers to it. After the Turkers graded the answers, we calculated the percentage of questions that were answered correctly for each system.
Turkers created 90 questions for 10 articles, which were subsequently filtered down to 47 good ques-tions, ranging from 3–6 questions per article. 25 Turkers answered questions about each translated article. To avoid them answering the questions multiple times, we randomly selected which tem’s translation was shown to them. Each sys-tem’s translation was displayed an average of 5
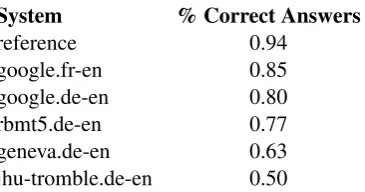
System % Correct Answers
reference 0.94
google.fr-en 0.85
google.de-en 0.80
rbmt5.de-en 0.77
geneva.de-en 0.63
[image:8.595.327.510.61.157.2]jhu-tromble.de-en 0.50
Table 3: The results of evaluating the MT output using a reading comprehension test
times per article. As a control, we had three Turk-ers answer the reading comprehension questions using the reference translation.
Table 3 gives the percent of questions that were correctly answered using each of the different sys-tems’ outputs and using the reference translation. The ranking is exactly what we would expect, based on the HTER scores and on the human eval-uation of the systems in WMT09. This again helps to validate that the reading comprehension methodology. The scores are more interpretable than Blue scores and than the WMT09 relative rankings, since it gives an indication of how un-derstandable the MT output is.
Appendix A shows some sample questions and answers for an article.
6 Conclusions
Mechanical Turk is an inexpensive way of gather-ing human judgments and annotations for a wide variety of tasks. In this paper we demonstrate that it is feasible to perform manual evaluations of machine translation quality using the web ser-vice. The low cost of the non-expert labor found on Mechanical Turk is cheap enough to collect re-dundant annotations, which can be utilized to en-sure translation quality. By combining the judg-ments of many non-experts we are able to achieve the equivalent quality of experts.
The suggests that manual evaluation of trans-lation quality could be straightforwardly done to validate performance improvements reported in conference papers, or even for mundane tasks like tracking incremental system updates. This challenges the conventional wisdom which has long held that automatic metrics must be used since manual evaluation is too costly and time-consuming.
We have shown that Mechanical Turk can be used creatively to produce quite interesting things.
We showed how a reading comprehension test could be created, administered, and graded, with only very minimal intervention.
We believe that it is feasible to use Mechanical Turk for a wide variety of other machine translated tasks like creating word alignments for sentence pairs, verifying the accuracy of document- and sentence-alignments, performing non-simulated active learning experiments for statistical machine translation, even collecting training data for low resource languages like Urdu.
The cost of using Mechanical Turk is low enough that we might consider attempting quixotic things like human-in-the-loop minimum error rate training (Zaidan and Callison-Burch, 2009), or doubling the amount of training data available for Urdu.
Acknowledgments
This research was supported by the EuroMatrix-Plus project funded by the European Commission, and by the US National Science Foundation under grant IIS-0713448. The views and findings are the author’s alone.
A Example reading comprehension questions
Actress Heather Locklear arrested for driving under the influence of drugs
The actress Heather Locklear, Amanda on the popular se-ries Melrose Place, was arrested this weekend in Santa Bar-bara (California) after driving under the influence of drugs. A witness saw her performing inappropriate maneuvers while trying to take her car out of a parking space in Montecito, as revealed to People magazine by a spokesman for the Califor-nian Highway Police. The witness stated that around 4.30pm Ms. Locklear “hit the accelerator very roughly, making ex-cessive noise and trying to take the car out from the park-ing space with abrupt back and forth maneuvers. While re-versing, she passed several times in front of his sunglasses.” Shortly after, the witness, who at first, apparently had not rec-ognized the actress, saw Ms. Locklear stopping in a nearby street and leaving the vehicle.
It was this person who alerted the emergency services, be-cause “he was concerned about Ms. Locklear’s life.” When the patrol arrived, the police found the actress sitting inside her car, which was partially blocking the road. “She seemed confused,” so the policemen took her to a specialized centre for drugs and alcohol and submitted her a test. According to a spokesman for the police, the actress was cooperative and ex-cessive alcohol was ruled out from the beginning, even if “as the officers initially observed, we believe Ms. Locklear was under the influences drugs.” Ms. Locklear was arrested under suspicion of driving under the influence of some - unspecified substance, and imprisoned in the local jail at 7.00pm, to be re-leased some hours later. Two months ago, Ms. Locklear was released from a specialist clinic in Arizona where she was treated after an episode of anxiety and depression.
4 questions were selected
• Why did the bystander call emergency services?
He was concerned for Ms. Locklear’s life.
• Why was Heather Locklear arrested in Santa Barbara?
Because she was driving under the influence of drugs
• Where did the witness see her acting abnormally?
Pulling out of parking in Montecito
• Where was Ms. Locklear two months ago?
She was at a specialist clinic in Arizona.
5 questions were excluded as being redundant
• What was Heather Locklear arrested for?
Driving under the influence of drugs
• Where was she taken for testing?
A specialized centre for drugs and alcohol
• Why was Heather Locklear arrested?
She was arested on suspicion of driving under the in-fluence of drugs.
• Why did the policemen lead her to a specialized centre for drugs and alcohol
Because she seemed confused.
• For what was she cured for two months ago?
She was cured for anxiety and depression.
Answers toWhere was Ms. Locklear two months ago?
that were judged to be correct:
Arizona hospital for treatment of depression; at a treat-mend clinic in Arizona; in the Arizona clinic being treated for nervous breakdown; a clinic in Arizona; Arizona, un-der treatment for depression; She was a patient in a clinic in Arizona undergoing treatment for anxiety and depression; In an Arizona mental health facility ; A clinic in Arizona.; In a clinic being treated for anxiety and depression.; at an Arizona clinic
These answers were judged to be incorrect: Locklear was retired in Arizona; Arizona; Arizona; in Arizona; Ms.Locklaer were laid off after a treatment out of the clinic in Arizona.
References
Bogdan Babych and Anthony Hartley. 2004. Extend-ing the Bleu MT evaluation method with frequency weightings. InProceedings of ACL.
Chris Callison-Burch, Miles Osborne, and Philipp Koehn. 2006. Re-evaluating the role of Bleu in ma-chine translation research. InProceedings of EACL. Chris Callison-Burch, Cameron Fordyce, Philipp Koehn, Christof Monz, and Josh Schroeder. 2008. Further meta-evaluation of machine translation. In
Proceedings of the Third Workshop on Statistical Machine Translation (WMT08).
Chris Callison-Burch, Philipp Koehn, Christof Monz, and Josh Schroeder. 2009. Findings of the 2009 Workshop on Statistical Machine Translation. In
Proceedings of the Fourth Workshop on Statistical Machine Translation (WMT09), March.
David Chiang, Steve DeNeefe, Yee Seng Chan, and Hwee Tou Ng. 2008. Decomposability of trans-lation metrics for improved evaluation and efficient algorithms. InProceedings of EMNLP.
Douglas Jones, Wade Shen, Neil Granoien, Martha Herzog, and Clifford Weinstein. 2005. Measuring translation quality by testing English speakers with a new defense language proficiency test for Arabic. InProceedings of the 2005 International Conference on Intelligence Analysis.
LDC. 2005. Linguistic data annotation specification: Assessment of fluency and adequacy in translations. Revision 1.5.
Evgeny Matusov, Nicola Ueffing, and Hermann Ney. 2006. Computing consensus translation for multiple machine translation systems using enhanced hypoth-esis alignment. InProceedings of EACL.
NIST and LDC. 2007. Post editing guidelines for GALE machine translation evaluation. Guidelines developed by the National Institute of Standards and Technology (NIST), and the Linguistic Data Consor-tium (LDC).
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of ACL.
Michael Paul. 2006. Overview of the IWSLT 2006 evaluation campaign. In Proceedings of Interna-tional Workshop on Spoken Language Translation. Antti-Veikko Rosti, Necip Fazil Ayan, Bing Xiang,
Spyros Matsoukas, Richard Schwartz, and Bonnie Dorr. 2007. Combining outputs from multiple machine translation systems. In Proceedings of HLT/NAACL.
Markus Schulze. 2003. A new monotonic and clone-independent single-winner election method. Voting Matters, (17), October.
Matthew Snover, Bonnie Dorr, Richard Schwartz, Lin-nea Micciulla, and John Makhoul. 2006. A study of translation edit rate with targeted human annotation. InProceedings of AMTA.
Rion Snow, Brendan O’Connor, Daniel Jurafsky, and Andrew Y. Ng. 2008. Cheap and fast - but is it good? Evaluating non-expert annotations for natural language tasks. InProceedings of EMNLP.
Omar F. Zaidan and Chris Callison-Burch. 2009. Fea-sibility of human-in-the-loop minimum error rate training. InProceedings of EMNLP.