International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1, January 2013)
569
Improved Hierarchical Clustering Using Time Series Data
V. Kavitha
1, Dr. M. Punithavalli
21Research Scholar, Karpagam University, Coimbatore, India
2 Director, Department of Master of Computer Applications, Sri Ramakrishna Engineering College, Coimbatore, India
Abstract— Mining Time series data has a remarkable development of interest in today’s world. This paper presents and evaluates an incremental clustering structure for time series data stream. The new algorithm is called Improved Hierarchical Clustering Algorithm (IHCA) is developed and applied with ECG data set. This system continuously constructs a tree structure of hierarchy that progress with data set. Two kinds of operations need to grow the Hierarchical clustering algorithm. The operations are split and merge (reaggregate). According to the diameter of the cluster the specific operation is decided. The split operation is based on dissimilarity measure between time series data points. The merge operation is to combine a previous split node in order to reacts the changes in the correlation structure between time series data points. These two operators are adopting the fast arrival of time series data flow. Cluster quality, Outlier and compilation time are the main features of this research. Experimental results shows that the performance of cluster quality and computation speed are improved.
Keywords— Times Series Data Stream, Hierarchical Clustering, Similarity Distance.
I. INTRODUCTION
Time Series Data has a wonderful growth of awareness in today’s world. Clustering time series is a challenging one when the data base is large. For this reason many researchers are involved in time series clustering. A time series is a progression of real numbers. Each number represents a time point assessment. Time series data stream
applications require continues monitoring. Quicker
response is required for time series data stream. For example, the sequence could represent stock or commodity prices, sales, exchange rates, weather data, biomedical measurements etc. Recently, stream time series data management has become a hot research topic due to its wide application usage.
A data stream is an structured sequence of points x1, , , , , , , xn that must be accessed in order and that can be read only once or a small number of time. The new high speed data set will not adopt by the traditional algorithms. In this way the innovative algorithms have been developed. These algorithms should be able to purify the cluster structure whenever more information is available and to take into account that the structure can change over time.
These algorithms can able to process each example in execution time and cluster qualities, while constantly contribute a compact data description at each given moment. Generally Clustering methods can handle different dataset into five major categories:
Partitioning methods, Hierarchical methods, Density Based methods, Grid Based methods and Model Based methods.
The majority of the works in the clustering time series data streams are based on incremental clustering rather than the variable clustering. Incremental update with new data point is the main characteristic of the new algorithm. And the new algorithm can able to discover and respond to changes that may occur in it.
II. RELATED WORK
An easy way to comply with the conference paper formatting requirements is to use this document as a template and simply type your text into it.
A clustering is a group of data objects that are similar to one another within the same cluster and are dissimilar to the objects in other clusters. Clustering is the assignment of a set of observations into subsets. However, clustering is a difficult problem combinatorial, and differences in assumptions and contexts in different communities have made the transfer of useful generic concepts and methodologies slow to occur. This research is belongs to hierarchical clustering. Hierarchical clustering is one of the incremental clustering. A good clustering method produces high-quality clusters to ensure that the inter-cluster similarity is low and the intra-cluster similarity is high; in other words, members of a cluster are more like each other than they are like members of a different cluster.Basically clustering is based on two categories. They are namely descriptive clustering and predictive clustering.
This algorithm describes descriptive models, that is, the unsupervised learning functions. These functions do not expect a target value, but focus more on the essential structure, relations, interconnectedness, etc of the data.
A. Hierarchical Clustering
A hierarchical Clustering method generates a
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1, January 2013)
570 The Agglomerative also called the bottom up approach starts with each object forming a separate group. It successively merges the objects or groups that are close to one another, until all of the groups are merged into one hierarchy. The divisive approach is also called the top down approach, starts with the entire object in the same cluster. For each iteration, a cluster is split up into smaller clusters, until eventually each object is in one cluster, or until a termination condition holds. Hierarchical does not require us to pre specify the number of clusters and most hierarchical algorithms are deterministic.
Advantage of Hierarchical Clustering
Comes at the cost of lower efficiency.
It has a logical structure, is easy to read and interpret.
Disadvantage of Hierarchical Clustering
Not able to find out the optimum centroid point using Hierarchical Clustering.
Unable to handle the large database due to the high
dimensionality problem.
Distance between the particles within the cluster will be high.
Outlier (The data points are out of the range) is more.
Compilation Time is more. And Cluster Quality
(Intra Cluster and Inter Cluster) is less using Hierarchical Clustering.
B. Clustering Streaming Time Series
Data streams usually consist of variables producing examples continuously over time. Let X={xt1, xt2,….. xtn} be the example containing the observations of all streams xi at a specific time t. The goal of a clustering system for multiple time series is to find a partition P of streams, where streams in the same cluster tend to be more alike than streams in different clusters.
One of the most widely used clustering approaches is hierarchical clustering, due to the great visualization power it offers [8, 11]. Hierarchical clustering produces a nested hierarchy of groups of similar objects, according to a pair wise distance matrix of the objects. One of the advantages of this method is its generality; the user does not require offering any parameters such as the number of instants. However, its application is limited to small datasets, due to its quadratic computational complexity.
III. METHODOLOGY
In the proposed system the new hierarchical algorithm is called Improved Hierarchical Clustering algorithm [IHCA] is developed. This new algorithm is based on descriptive clustering method.
It means that it is a unsupervised process. Using this algorithm the computation speed is decreased and the cluster quality is improved. A good clustering method produces high-quality clusters to ensure that the inter-cluster similarity is low and the intra-inter-cluster similarity is high.
A.Improved Hierarchical Clustering
In this paper, the Improved Hierarchical Clustering algorithm [IHCA] is presented, which is an algorithm for an incremental clustering of streaming time sequence. It constructs a hierarchical tree-shaped structure of clusters by using a top-down strategy. The leaves are the resulting clusters, with each leaf grouping a set of variables. The system includes an incremental distance measure and executes procedures for expansion and aggregation of the tree based structure. The system will be monitoring the flow of continuous time series data. Then time interval will be fixed. Within the specific time interval the data points will be partitioned. In a partition the diameter is calculated. Diameter is nothing but the maximum distance between the two points. Each and every data point of the partition will be compare with the diameter value. If the data point is greater than the diameter value then the split process will be execute otherwise the
Aggregate (Merge) process will be performed. Based on the above criteria the hierarchical tree will be growing. Here we have to observe the splitting process, because the splitting will decide the growth of clusters. In the proposed technique the Hoeffding Bound is used for to observe the splitting process. In the proposed technique, IHCA the technique unequality vapnik Chervonenkis is used for splitting process. Using this technique the observation of splitting process is improved. So, the cluster is grouping properly.
In the Hoeffding Bound,
(1)
Where, the observations starting that after n independent observations of the real valued random variable r with range R, with confidence
In the proposed algorithm, the range value will be increase from R2 [1]to RN .[2] So the observation process is not a fixed one. Depends on the number of nodes the system will generating the observation process.
IV. EXPERIMENTAL EVALUATION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1, January 2013)
571 Since the scope of the system is very well defined, So The system is applied to a set of time series with clustering structure. However, if the streams present dynamic performance, then the system should notice the changes in the structure of the cluster and adapt it accordingly. We must evaluate how the system performs on real data produced by applications that generate time series data streams.
A.Evaluation Criteria for Clustering Quality
Generally, the criteria used to evaluate clustering methods concentrate on the quality of the resulting clusters. Given the hierarchical characteristics of the system, the quality of the hierarchy is constructed by our algorithm. And another evaluation criterion is computation time of the system.
B.Cluster Quality
A good clustering algorithm will produce high quality based on intra cluster similarity and inter cluster similarity measures. The quality of the clustering result depends on the similarity measure used by the method and its implementation. The quality of a clustering method is also measured by its ability to discover some or all of the hidden patterns. The criteria for measuring the cluster quality of intra clusters similarity will be high. And the inter cluster similarity will be low. For analysing cluster quality will be in two forms, First one is finding groups of objects will be related to one another. And second one is finding the group of objects that differ from the objects in other groups.
C.
Computation TimeAnother evaluation of this work is calculating the computation time of the process. The complexity of execution time will be decreased when using the proposed work.
D. Outlier
Outlier is nothing but, the data points which are out of the range of the cluster. The outlier is calculated for the existing method of ODAC(Online Divisive Agglomerative Clustering) and the proposed method IHCA (Improved Hierarchical Clustering Algorithm).
Outlier Calculation
Step 1: Intra Cluster value is calculated for all Clusters.
Step 2: Mean of the Intra cluster is found out.
Step 3: All the data points of the clusters will be comparing with the mean value.
Step 4: After comparison, each data point will be decided whether the point will position within a cluster or out of the cluster.
V. SYSTEM EVALUATION ON TIME SERIES DATA SET
This proposed method is evaluated with different kinds of time series data sets. Three types of data sets are used to evaluate the proposed algorithm. The data sets are namely ECG Data, EEG Data and Network Sensor Data. ECG Data set is used to find out the anomaly Identification. This data set have three attributes namely time seconds, left peek and right peek. EEG Data set is used to find out abnormal personality. The name of the attributes is Trial number, Sensor value, Sensor position, Sample number. The third type of data set is Network sensor. The name of he attributes is Total bytes, in bytes, out bytes, Total Package, in package, out package, Events.
A.Record Set Specification
TABLE I
DATA SET SPECIFICATION
Data Set Number of Instance Number of Attributes
ECG 1800 3
EEG 1644 4
Sensor Network 2500 7
Using the above three kinds of data sets we have to calculate Execution time of the system, Intra cluster , Inter cluster and outlier of the cluster.
B.Result of Outlier
TABLE 2
OUTLIER SPECIFICATION
Technique Outlier Points Existing System(ODAC) 152
Proposed System(IHCA) 123
C.Result of Execution Time
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1, January 2013)
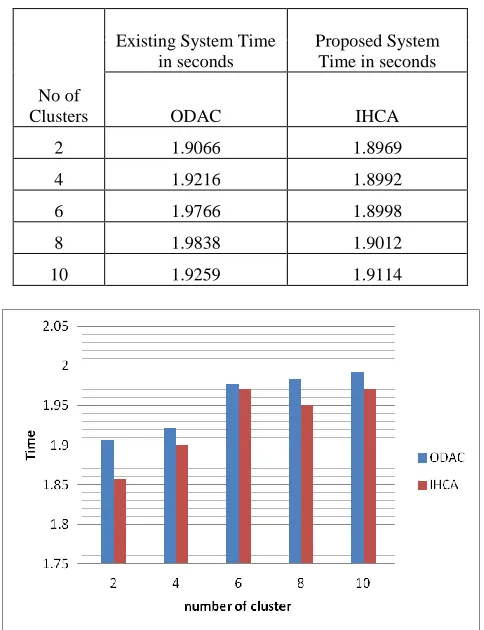
[image:4.612.48.290.142.457.2]572 TABLE 3
EXECUTION TIME BETWEEN EXISIING AND PROPOSED
No of Clusters
Existing System Time in seconds
Proposed System Time in seconds
ODAC IHCA
2 1.9066 1.8969
4 1.9216 1.8992
6 1.9766 1.8998
8 1.9838 1.9012
10 1.9259 1.9114
Figure 1 Execution time between the existing and proposed systems
[image:4.612.330.559.293.607.2]D.Result of Intra Cluster and Inter Cluster
TABLE 4
INTRA CLUSTER BETWEEN EXISIING AND PROPOSED SYSTEM
No of Clusters
Existing System Intra Cluster
Proposed System Intra Cluster
ODAC IHCA
2 890.23 865.15
4 665.67 615.63
6 480.53 413.41
8 386.45 338.54
10 292.23 266.04
Figure 2 Intra cluster between exisiing and proposed system TABLE 5
INTER CLUSTER BETWEEN EXISIING AND PROPOSED SYSTEM
No of Clusters
Existing System Inter Cluster
Proposed System Inter Cluster
ODAC IHCA
2 330.64 375.84
4 227.72 279.07
6 198.27 215.34
8 121.67 148.74
10 101.27 119.89
Figure 3 Inter cluster between exisiing and proposed system
[image:4.612.41.295.492.668.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 1, January 2013)
573
VI. CONCLUSION
Mining Time series data has a remarkable development of interest in today’s world. This paper presents and evaluates an incremental clustering structure for time series data stream. The new algorithm is called Improved Hierarchical Clustering Algorithm (IHCA) is developed and applied with ECG data set.
This system continuously constructs a tree structure of hierarchy that progress with data set. Split and Merge are two operators adopting the fast arrival of time series data flow. Cluster quality, Outlier and compilation time are the main features of this research. Experimental results show that the performances of cluster quality, Outlier and computation speed are improved.
VII. FUTURE WORK
In this work, we have to face some of the problems. The draw backs are
Centroid Points are not optimized.
Repeated data points are more.
To reduce the outlier.
To improve the Cluster Quality and Computation Time.
The above problems are faced in this work. Using innovative techniques to avoid the problems.
REFERENCES
[1] Pedro Pereira Rodriguess and Joao Pedro Pedroso, ―Hierarchical
Clustering of Time Series Data Streams‖ IEEE Transactions on Knowledge and Data Engineering vol.20,no.5,pp.615-627,May 2008.
[2] ‖Concentration Inequalities‖, Stephane Boucheron, Gabor Lugosi,
Olivier Bousquet
[3] Jian Yin, Duanning Zhou and Qiong-Qiong Xie, ―A Clustering
Algorithm for Time Series Data‖ Seventh international Conference on Parallel and Distributed Computing, Applications and Technologies pp. 119-122, 2006.
[4] Sudipto Guha, Adam Meyerson, Nine Mishra and Rajeev Motiwani,
―Clustering Data Streams: Theory and Practice‖, IEEE Transactions on Knowledge and Data Engineering. Vol. 15, no. 3, pp. 515-528, May/June 2003.
[5] Ashish Singhal, and Dale E Seborg, ―Clustering Multivarriate Time
Series Data,‖ Journal of Chemometrics, vol. 19, pp. 427-438, Jan 2006.
[6] M. Halkidi, Y. Batistakis, and M. Varzirgiannis, ―On clustering
validation techniques,‖ Journal of Intelligent Information Systems, vol. 17, no. 2-3, pp. 107–145, 2001.
[7] L. O’Callaghan, A. Meyerson, R. Motwani, N. Mishra, and S.
Guha,― Streaming-data algorithms for high-quality clustering,‖ in Proceedings of the Eighteenth Annual IEEE International Conference on Data Engineering. IEEE Computer Society, 2002, pp. 685–696.
[8] C. Aggarwal, J. Han, J. Wang, and P. Yu, ―A framework for
clustering evolving data streams,‖ in VLDB 2003, Proceedings of Twenty-Ninth International Conference on Very Large Data Bases. Morgan Kaufmann, September 2003, pp. 81–92.
[9] S. Guha, A. Meyerson, N. Mishra, R. Motwani, and L. O’Callaghan,
―Clustering data streams: Theory and practice,‖ IEEE Transactions on Knowledge and Data Engineering, vol. 15, no. 3, pp. 515–528, 2003.
[10] Pedro P. Rodrigues ,‖ A Semi-Fuzzy Approach for Online