International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
255
Virtual Machine Behaviour Identifier (VMBI) for VM Level
Auto-scaling in Cloud Environment
M. Kriushanth
1, L. Arockiam
21Research Scholar, 2Associate Professor, Department of Computer Science, St. Joseph’s College (Autonomous), Tiruchirappalli,
Tamil Nadu, India.
Abstract— Cloud computing is becoming popular day by day, due to high performance. Computing resources are available anywhere at any time with ‘pay as you go’ model. Virtualization is playing an important role to provide cloud services to the end users via internet. Virtualization is the emulation of physical machine. Number of Virtual Machines (VM) can be created from physical machines and can be provided to the users. Monitoring the health condition of all VMs is very difficult task for Cloud Service Provider (CSP). In this paper, we propose Virtual Machine Behavior Identifier (VMBI) for VM level auto-scaling mechanism to monitor the behavior of VMs. Pattern search optimization technique is used to optimize the VMs and self-optimization module is to update the parameter of optimization to auto-scale the VM.
Keywords—Cloud computing, Auto-scaling, Virtual Machine, Optimization.
I. INTRODUCTION
Virtualization, in its broadest sense, is the emulation of one or more servers within a single physical computer. In simple term, virtualization is the emulation of hardware within a software platform. This allows a single computer to take on the role of multiple computers. Virtual machine is the emulation of physical machine or host. Also, more number of VM can be created in physical machine. The configuration of a VM depends on usage like application hosting, general purpose instance, CPU optimized, Memory optimized, Storage optimized and GPU optimized.
The Quality of Service (QoS) depends on establishing continues service to the user from starting, stabilization to the service ending. Monitoring the health condition of VM is major task for the CSP. Health refers to working condition, busy, idle, needed resource and shutdown. If the number of VM is small in one host, it has to move to other host. CSP has to take replica or snap shot of each and every VM to overcome the problem. Snapshot helps to generate again in shorter duration. Healing or recovering the problems of the VM is called healing or self-optimization. Optimization technique is used identify the VM behavior and health condition to auto-scale the VM is given in this paper.
The rest of the paper is organized as follows. Section II describes the related work, Section III Motivational scenario and objective. Section IV shows the methodology followed in this paper. Section V explains the VM level Auto-scaling framework. Section VI evaluates the proposed mechanism and finally section VII concludes the paper.
II. RELATED WORKS
As cloud data systems grow in size and complexity to accommodate an increasing number of virtual machines, the scalability issues related to the process of monitoring VM resources usage for management strategies become a major challenge. Resource monitoring is particularly challenging in IaaS cloud systems, where several customer applications are hosted in virtualized environments. A customer application typically consists of multiple software components (e.g., the tiers of a multi-tier web application) and each components runs on a separate VM. In these cloud systems, VMs are usually considered as black boxes with independent behaviors. Hence information needs to be collected about each single VM of the data center [1].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
256
Two levels of management strategy are adopted in IaaS cloud system [5]. The first level consists in a local management that is performed on each physical server: it detects overload conditions in real-time making use of the resource measurements of the VMs hosted on the server, and exploits live VM migration whenever overloaded servers are detected [6]. The second level is a global management, which is controlled by a central node is responsible for periodically executing a consolidation technique to place VMs on as few physical servers as possible to reduce the infrastructure costs and avoid
expensive resource over-provisioning [7][8]. Since
consolidation strategies in IaaS cloud infrastructure usually consider each VM as a stand-alone object with independent resource usage patterns, detailed information has to be collected with high sampling frequency typically 1 sample in 5 minutes about each VM, thus creating scalability issues for the monitoring system.
Elasticity is one of the key governing properties of cloud computing that has major effects on cost and performance directly. Most of the popular IaaS providers such as amazon web services, Windows Azure, Rackspace etc. work on threshold based auto-scaling. In current IaaS environments, there are various other factors like ―Virtual Machine (VM) - turnaround time‖, ―VM-stabilization time‖ etc. that affect the newly started VM from start time to request servicing time. If these factors are not considered while auto-scaling, it will affect directly on Service Level Agreement (SLA) and users response time. So that these threshold should be a function of load trend, which makes VM readily available when needed. Karteek et al. [9] developed an approach where the thresholds adapt in advance and these thresholds are functions of all the above mentioned factors.
Jingqi et al. [10] proposed a cost-aware auto-scaling approach. Scaling methods are divided into three categories: self-healing, resource level scaling and VM-level scaling. The first two methods are vertical scaling methods, and the last one is horizontal scaling. The idea of self-healing is that if two VMs of a service are allocated in the same cluster node, resources of VMs may complement each other. The resource-level scaling up uses unallocated resources available at a particular cluster node to scale up a VM execution on it. Both of them can scale up and down virtual resources within milliseconds. The self-healing scaling is free of scaling cost, it is usually executed first, and then the resources-level scaling is conducted.
Protecting the key resources such as data and recovering against cyber threats and infrastructure has become a critical concern. At the same time, cloud computing technology such as virtualization and on-demand provisioning can be leveraged to implement protection and recovery mechanisms for sensitive computing services. However, the energy costs of such self-healing mechanisms have been ignored. Juan et al. [11] proposed a novel Intrusion Detection System (IDS) based self-protection mechanism at the virtual machine level.
III. MOTIVATION AND OBJECTIVE
A. Motivation
Cloud services are provided as virtualized resources, the uninterruptable and failure free services gaining the better scalability and Quality of Service. To achieve scalability, VMs health should be monitored continuously to establish a better superior service. In some cases, the VMs resources should add and removed with respect to the usage. By identifying the behaviour of the VM, the health and VM level scaling is possible.
B. Objective
Identify the VM behaviour to auto-scale the running and newly generated virtual machine in cloud environment.
IV. METHODOLOGY
Request Pool Load Balancer Virtual Machine Resource Provisioning
[image:2.612.327.562.439.549.2]VM Behavior Identifier VM Level Scaling
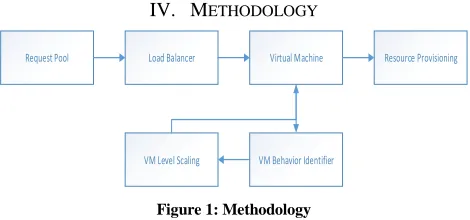
Figure 1: Methodology
Fig. 1, describes the methodology followed to identify the VM behavior by VM health monitor. Optimization technique is used validate the VM health monitor parameters and finally the VM is scaled.
V. VMLEVEL AUTO-SCLAING
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
257
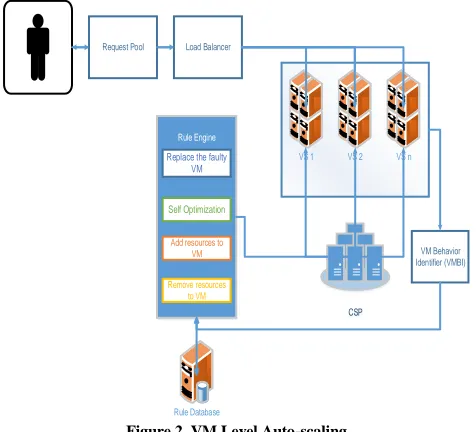
VM behavior identifier does all monitoring action. The rule engine receives monitored data; generate the rule to scale the VM. This approach is shown in Fig. 2.
Request Pool
CSP VS 2
VS 1 VS n
Load Balancer
VM Behavior Identifier (VMBI) Rule Engine
Add resources to VM Self Optimization
Remove resources to VM
Rule Database
[image:3.612.318.570.146.666.2]Replace the faulty VM
Figure 2. VM Level Auto-scaling
A. Request Pool (RP)
The cloud user requests come through the request pool. The cloud user’s credentials will be stored in resource pool. It will categorize all the requests and finally the requests forwarded to the load balancer.
B. Load Balancer (LB)
Load balancing is a technique to enhance resources, developing parallelism, exploiting throughput invention and to reduce response time through the appropriate distribution of the application. Load balancing is to send the user request (or) workload to the available cloud resources.
C. Virtual Machine Behavior Identifier (VMBI)
The role of VMBI is to ensure virtual machine is working acceptable condition and resources needed to be added. If any virtual machine needs resources of CPU, memory, storage and network, the performance metrics are measured are downtime, CPU usage, memory, storage and network. Categorized metrics are tabulated below for easy understanding [12] [13] [14]. With respect to the metrics resources auto-scaled without affecting the performance of other virtual machines.
TABLEI
OVERALL VIRTUAL MACHINE METRICS
Parameter Description
Monitor information
VM Name The name of the virtual machine.
VM Type Type of the virtual machine.
VM Health Denotes the health (Clear, Warning, Critical) status, of the VM.
Availability Shows the current status of the VM - Available or Not available.
CPU Utilization
CPU
Utilization The CPU Usage of the VM, in percentage.
Memory Utilization
Memory Utilization
The memory utilization of the VM, in percentage.
Active Memory
Amount of memory that is actively used, measured as recently touched pages (MB).
Storage Utilization
Capacity GB The total space available in this data store, in giga bytes.
Used GB The used space of this data store, in giga bytes.
Free GB The free space of this data store, in giga bytes.
Health Overall health of the data store.
Network Usage
Network
Utilization The network usage of the VM, in kbps.
D. Pattern Search Optimization
Pattern search (PS) is a family of
numerical optimization methods that do not require
the gradient of the problem to be optimized. Hence, PS can
be used on functions that are
not continuous or differentiable. Such optimization methods are also known as direct-search, derivative-free, or black-box methods.
[image:3.612.50.288.174.390.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
258
1) Exploratory Move
Exploratory move find the best point in the vicinity of the current point. This is done by perturbing the current point by small amounts in each of the variable directions and observing whether the objective function value improves or descend.
First need to define the sizes of perturbation steps, that will take in each dimension by setting up the perturbation vector P0 = (∆x1, ∆x2, ∆x3,……. ∆xn). The perturbation steps sizes do not all have to be equal, in general they are all relatively small. Current point is x(0) given and its associate objective function value f(x(0)) perform an exploratory search around. The algorithm shows the further steps as follows.
a)Exploratory Search Algorithm
Step 1: x(1) x(0) , i.e copy x(0) into x(1). Initialize fbest
f (x(0))
Step 2: For each variable xj in turn: x(1) x1(1), x2(1),
x3(1),……….., xj(1) + ∆xj(1),…… xn(1), collide the jth variable up by its perturbation value.
Step 3: If f(x(1)) improves over current value of fbest: retain
the perturbation, update fbest f(x(1)) and go to step 2 for
the next variable.
Step 4: [f(x(1)) decends or stays the same for the upwards
perturbation]: x(1) (x1(1), x2(1), x3(1),……….., xj(1) +
∆xj(1),…… xn(1)) collide the variable down by its perturbation value.
Step 5: if f(x(1)) improves over current value of fbest: retain
the perturbationand update fbest f(x(1)). Otherwise
discard the perturbation: xj(1) xj(0)
Step 6: Go to step 2 for the next variable.
Step 7: the improving direction is given by the vector x(1) -
x(0). If x(1) = x(0) then the exploratory search has failed.
There are few things to notice about the exploratory search algorithm:
If the upward perturbation for a variable is successful,
then the downward perturbation for that variable is not even attempted.
The downward perturbation for a variable is tried only
if the upward perturbation for that variables fails.
It’s possible that both the upward and the downward
perturbation fail for a particular variable, in which case its value is not changed.
Exploratory search does not try all possible
combinations of upward and downward perturbations of the variables. It is simple one pass through the list of variables.
The worst case where the upward perturbation fails for
every variable, then it will try 2n combinations of perturbations, but it normally tries fewer than that.
The best case where every upward perturbation
succeeds, it will try just n perturbations.
2) Pattern Move
Pattern move requires two points: the current point x(0) and some other point x(1) that has a better value of the objective function. It gives the pattern move an improving direction to move in. A new point x(2) is generated by moving from x(0) through x(1) as follows:
x(2) = x(0) + a [x(1) - x(0)] (1)
Where a is a positive acceleration factor that just multiplies the length of the improving direction vector given by x(1) - x(0). A common choice is a = 2, in which case the equation reduces to: x(2) = 2x(1) - x(0) (2)
a)Pattern Search Complete Algorithm
The Complete algorithm requires 4 inputs in addition to the objective function to be optimized:
A starting point x(0)
The value of the acceleration factor a,
The value perturbation vector P0
The perturbation tolerance vector T = (t1, t2,t3,
…. , tn).
The complete algorithm has 3 main parts: initialization, start/restart routine, and the pattern move routine.
b)Initialization
Choose the values for the starting pint x(0), acceleration factor a, perturbation vector P0, and perturbation tolerance
vector T. initialize the current perturbation vector: P P0.
c)Start/Restart Routine:
Step 1: Use an exploratory search x(0) to find an improved
point x(1) that has a better value of the objective function.
Step 2: IF the exploratory search fails (i.e. x(1) does not
give a better value of the objective function x(0)) then:
Step 2.a: Reset all of the perturbations to ½ their current
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
259
Step 2.b: If any member of P is now smaller than its
corresponding perturbation tolerance in T, then exit with x(0), as the solution. Else go to Start/Restart.
Step 3: ELSE [x(1) gives a better value of the objective
function than x(0), so we have an improving direction]:
Step 3.a: Reset the perturbation vector to is original values:
PP0.
Step 3.b: Go to Pattern Move.
b)Pattern move
Step 1: Obtain tentative x(2) by a pattern move from x(0)
through x(1).
Step 2: Obtain final x(2) by an exploratory search around
tentative x(2).
Step 3: IF f(x(2)) is worse than f(x(2)) then:
Step 3.a: Update points: x(0) x(1). [x(1) is the best point
seen so far]
Step 3.b: Go to Start/Restart.
ELSE [f(x(2)) is better than or equal to f(x(1))]:
Update points: x(0) x(1) and x(1) x(2)
Go to Pattern Move.
d)Self-Optimization Module
Self-optimization is a process in which the system’s settings are autonomously and continuously adapted to the demand, system performance. The similar term planning and healing, goes together with self-optimization. The autonomous trait of self-optimization involves no human intervention at all during the aforementioned optimization process.
Self-optimization module has three tasks (1) Analysis of the situation; (2) Determination of objectives; and (3) Adjustment of system behavior.
E. Rule Engine (RE)
Rule engines’ activity is to receive the updated parameters from VMBI. It identifies the total number of VM running, resources needed for the VM, Idle and Failure of VM. If the VM is a failure, it refers the VM description replica of the VM form the server and re provision service to the user. Any VM is lack of resources, it automatically adds the sufficient amount of resources to the VM. When the situation occurs to migrate from one host to another host, those VMs are migrated.
F. Rule Database
The generated rule and health monitor parameters are stored in the rule database for future reference.
G. VM Auto-scaling process flow
Rule Engine Begin
Identify the request
Boot VMs
If VM is healthy
If Resource is needed for
the VM
If VM is Failure or Idle
Provision the resource
End Auto-scale the resource
Identify the Virtual Machine Behavior (Monitor the VM health)
Leave as it is Add Resources to VM Replace the VM Replica or Snapshot of VM
Rule Database
VI. EVALUATION
UK natural grid real time data is consider to evaluate the proposed mechanism. One day request with half an hour time interval has taken for evaluation.
Minimize f(x) = 3x12 + x22 - 12x1 - 8 x2 (3)
A. Initialize
Initial point: x(0) = (1,1)
Acceleration factor a=2
Perturbation vector P0=(0.5,0.5)
Perturbation tolerance vector T = (0.1,0.1)
P P0
P0 and T chosen in this case, the Algorithm terminates after a small number of steps. The elements in T would usually be even smaller.
B. Start / Restart
fbest = f(x(0)) = -16.
Try x(1) = (1.5,1). f(x(1)) = 18.25, keep the
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
260
Try x(1) = (1.5,1.5). f(x(1)) = -21, keep the
perturbation and update fbest = -21.
The exploratory search are shown in first Start/Restart, but are omitted from forward.
C. Pattern move
Move from x(0) = (1,1) through x(1) = (1.5, 1.5)
Tentative x(2) = 2(1.5,1.5) (1,1) = (2,2). f(2,2) =
-24.
Final x(2) after exploratory search around tentative
x(2) is (2.0,2.5). f(x(2)) = -25.75 is better than f(x(1)) = -21 so the move is accepted.
Update points: x(0) x(1) = (1.5,1.5) and x(0)
x(1) = (2.0,2.5)
The sequence of the points to our evaluation are taken to the self-optimization module for Auto-scaling.
VII. CONCLUSION AND FUTURE WORK
Monitoring all Virtual Machine health, idle VM, failure and resource needed VM is tedious task for CSP. The effective VM Behavior Identification (VMBI) method monitors all VM. In this paper Hooke Jeeves pattern search optimization technique is used to find out the behavior of all VMs. Self-optimization module first analyzed the situation, next determined of objectives and finally adjusted the system behavior.
REFERENCES
[1] Claudia Canali and Riccardo Lancellotti, ―An adaptive techniques to model virtual machine behavior for scalable cloud Monitoring‖, IEEE symposium on computers and Communication (ISCC), June 2014, pp. 1-7.
[2] Claudia Canali and Riccardo Lancellotti, ―Automatic virtual machine clustering based on Bhattacharyya distance for multi-cloud systems‖, In proceedings of International Workshop on Multi-cloud Applications and Federated Clouds, Prague, Czech Republic, Apr. 2013, pp. 45–52.
[3] Claudia Canali, Riccardo Lancellotti, ―Improving Scalability of Cloud Monitoring Through PCA-Based Clustering of Virtual Machines,‖ Journal of Computer Science and Technology, Springer, Vol. 29, No. 1, 2014, pp. 38–52.
[4] D. Durkee, ―Why cloud computing will never be free‖, Queue, Vol 8, No 4, April 2010, pp. 20-29.
[5] Claudia Canali, Riccardo Lancellotti, "Detecting Similarities in Virtual Machine Behavior for Cloud Monitoring using Smoothed Histograms", Journal of Parallel and Distributed Computing, Vol. 74, No. 8, August 2014
[6] T. Wood, P. Shenoy, A. Venkataramani and M. Yousif, ―Black-box and gray box strategies for virtual machine migration‖, In proceedings of Conference on Networked systems design and implementation (NSDI), Cambridge, April, 2007.
[7] D. Ardagna, B. Panicucci, M. Trubian and L. Zhang, ―Energy Aware Autonomic Resource Allocation in Multitier Virtualized Environments‖, IEEE transactions onn services computing, Vol 5, No 1, Jan 2012, pp. 2-19.
[8] T. Setzer and A. Stage, ―Decision support for virtual machine reassignments in enterprise data centers‖, in proceedings of Network operations and management symposium (NOMS’ 10), Osaka, Japan, April 2010.
[9] Kartheek Kanagala and K. Chadra Sekaran, ―An Approach for Dynamic Scaling of Resources in Enterprice Cloud‖, In procedings of the IEEE international Conference on Cloud Computing Technology and Science, IEEE, 2013, ISBN 978-0-7695-5095-4, pp. 345-348.
[10] Jing Jiang, Jie Lu, Guangquan Zhang and Guodong Long, ―Optimal Cloud Resource Auto-Scaling for Web Applications‖, 13th Internatinal Symposium on Cluster, Cloud and Grid Computing, IEEE/ACM, 2013, ISBN 978-0-7695-5, pp. 58-65.
[11] Juan J. Villalobos, Ivan Rodero and Manish Parashar, ―Energy-Aware Autonomic Framework for Cloud Protection and Self-Healing‖, International Conference on Cloud and Autonomic Computing, IEEE, 2014, ISBN 978-1-4799-5841-2, pp. 3-4.
[12] Parameter of Virtual machine,
https://www.paessler.com/blog/2008/10/01/all-about- prtg/monitoring-system-parameters-of-vmware-esx-servers-hosts-and-virtual-machines, Dated – 25.09.2015
[13] VM health monitoring, https://www.manageengine.com/network-monitoring/vmware
monitoring.html?gclid=CLSb1Iy8lsgCFVYVjgodILMJJw, Dated – 25.09.2015.
[14] VM monitoring,
https://www.manageengine.com/it360/help/meitms/applications/help /monitors/virtual-machines.html