International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
270
A Novel Approach to Detect and Classify the Defective of
Missing Rail Anchors in Real-time
Rubel Biswas
1, Rubayat Ahmed Khan
2, Samiul Islam
3, Jia Uddin
41,2,3,4, Computer Science and Engineering,BRAC University, Bangladesh
Abstract—In this paper, we have designed a machine vision-based method to identify the defected or missed or grounded rail anchors/fasteners that attach each line with the sleepers. Rail line inspection system is executed manually, especially in third world countries, like Bangladesh. This manual inspection is lengthy, laborious and subjective. To detect and classify the damaged or missed or grounded rail anchors/fasteners in real time based on Shi - Tomasi and Harris – Stephen feature detection algorithms with an accuracy of 81.25%. Besides SVM classifier is used to train the Shi - Tomasi and Harris – Stephen features which helps to improve the recognition accuracy. To check the robustness of this system, it was tested against on different videos which contain damaged or missed or grounded fasteners in rail line which indicates clearly the high robustness targeted by this system.
Keywords—Rail, Anchors, Shi-Tomasi, Harris, SVM
I. INTRODUCTION
The Rail line anchors are the metallic components, fixed on tie plates, which fasten the lines with the sleepers. Machine vision techniques have been developed which deal with various railway elements like sleepers, tie plates, etc. proposed system of Pavel Babenko in 2006[1]. In Bangladesh the number of derailments during 2009-2010 was 403 [2]. In many countries the condition of anchors are inspected manually by railway operators which is based on visual analysis. As a result the manual process is extremely time consuming and non-reliable as the quality of work differs from person to person. Hence it is essential to have an automatic system that can detect the presence and the absence of anchors.
In this paper, we deal with the issue of detecting the E-clip (W) type anchors from video. The proposed system is based on two feature detection algorithms, The Harris-Stephen [3] algorithm was developed to recognize frame sequences from a moving camera by extracting and tracking frame features. Matching frames using just edges work when the camera is still but when it comes to a
camera in motion just edges are not enough.
[image:1.612.327.565.444.510.2]The algorithm was developed based on two frame sequences which contained corners and edges. Shi -Tomasi [4] detector detects corner points by measuring the feature dissimilarity between the first frame and the current frame in a motion. The idea of the algorithm is when the divergence of the features of the two frames is very large they are abandoned. The paper proved that pure translation is not adequate but linear warping and translations are. This algorithm also detects features which are best for tracking. The proposed system uses also one-against-all SVM in order to train and match the descriptors of the test frame with the trained frame. This multiclass SVM works by considering the M- class problem as a series of binary problem. There are 3 classes (Existing anchors, missing anchors and unknown) in the proposed solution. Both are used collaboratively to detect the presence or missing and defective anchor. Figure 1 demonstrates an E-clip (W) type anchor.
Figure 1. E-clip (W) Anchors.
II. LITERATURE REVIEW
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
271
This framework uses integral image technique to compute the Haar Wavelet features, used Adaboost as the learning algorithm and lastly it uses a cascade of classifiers. A set of positive and negative images were used to construct the dataset. Then a set of feature template was built from it. The training set along with the feature template was fed to Adaboost. This was how the detector was created. Then it was applied on rail images to detect true and false instances of anchors. Hoang Trinh, Norman Haas, Ying Li, Charles Otto and SharathPankanti [7] have worked on detecting anchors and other rail components. Their proposed system was based Adaboost classifier. Instead of using a single cascade classifier they have used a combination of multiple classifiers where at each point of time the detection result was returned with the highest number of detections among multiple classifiers.Detecting the rail fasteners and missing rail fasteners, Shah M used SIFT features with MACH filters and SVM [5-8]. Different commercial systems are exist for executing rail track inspection such as AURORA [9] system for inspecting wood ties, rail seat scrape, tie plates, anchor and spikes. ENSCO [10] designed the Joint Bar Inspection system based on High-resolution cameras and advanced image processing algorithms to detect the rail track components. MERMEC Group [11] developed a new system to detect the track surface and measuring the track geometry, rail profile and rail corrugation using high-speed cameras and image processing technique.
Naveen Chintalacheuvu and VenkatesanMuthukumar [12] used Harris-Stephen to detect vehicles from videos. The use of Harris-Stephen eradicated the need of calibration and contrast enhancement, and it works excellent in various illuminations and very fast. Vimal Gupta and PushpaChaurasian [13] proposed a robust face detection system where both Shi-Tomasi and Harris-Stephen have been used to detect facial features. These detectors performed better and faster than the Gabor extraction method.
SVMs are set of related supervised learning methods used for classification. It simultaneously minimizes the empirical classification error and maximizes the geometric margin. SVM map input vector to a higher dimensional space where a maximal separating hyper plane is constructed. Two parallel hyper planes are constructed on each side of the hyper plane that separate the data. The separating hyper plane is the hyper plane that maximizes the distance between the two parallel hyper planes. An assumption is made that the larger the margin or distance between these parallel hyper planes the better the generalization error of the classifier will be [14].
III. METHODOLOGY
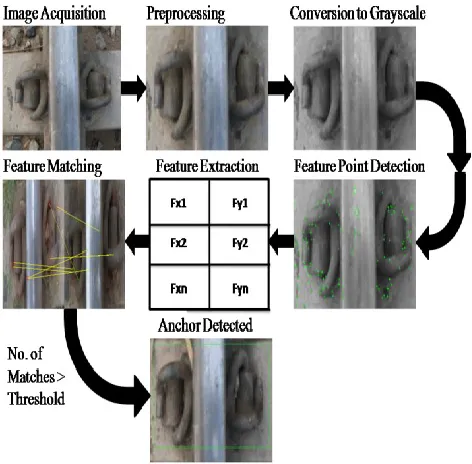
[image:2.612.325.561.324.556.2]Identification of defected or missed rail anchors/fasteners is achieved in five stages. In the first stage, the frame of the rail track scene is pre-processed for reducing the noise level and pre-processed frame is converted into grayscale in the second stage. The steps that followed conversion are the detection of feature points using Harris–Stephen and Shi–Tomasi feature detection algorithms and the extraction of the corresponding feature vectors containing M×N features. In the last stage, the features of each frame are matched with the ones of the training frame and if the numbers of matches satisfy a threshold then we conclude that an anchor has been detected or else missing. The details of the proposed system are explained in the next section.
Figure 2. Block Diagram of the System.
IV. DETECTION OF RAIL FASTENERS
A. Video Acquisition
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
[image:3.612.54.296.138.407.2]272
Figure 3.Position of the Camera.Figure 4. Frame Samples.
B. Pre-processing
In the acquisition section, it was mentioned that the videos were taken from such a height that the unwanted background could be excluded as much as possible. As seen in Figure 4 portions of avoidable background, the stone ballast, are still visible at the top and at the bottom. Therefore in order to reduce noise to its minimum, these undesired portions of frames have been cropped off so that the preferred region in better exploited. The frames are resized to [200 × 200] and then the cropping is executed with a mask of [170 × 67] starting from the coordinates (10, 48). The left column of Figure 5 shows the original frames acquired, the mid column shows the masking and the last column shows the frames after cropping.
C. Feature Point Detection and Extraction
To extract the features from pre-processed frames, we applied two feature extraction algorithms collaboratively. Those are helps to detect the presence of anchors from the video.
Harris-Stephen Feature Detector: Harris–Stephen [3] is a corner point detector based on auto-correlation function of a signal. This algorithm has been developed upon Moravec’s corner detector [15]. The major drawbacks of Moravec’s corner detector are a) not isotropic b) uses a binary rectangular window c) responds readily to edges.
These disadvantages have been overcome by Harris– Stephen by a) using expansion instead of shifted patches b) using a smooth circular window and c) modifying the corner calculation by utilizing the variation of the change with the direction of shift.
Let I be a 2D image and the image patch over the area be (u,v) which is shifted by (x,y). The weighted sum of squared difference (SSD) or the auto correlation between two patches is denoted by C.
C(x,y)=∑ ∑ ( )( ( ) ( ))2 (1)
I (u + x, v + y) is the shifted image and is approximated by Taylor’s series as follows:
I (u + x, v + y) = I (u, v) + Ix (u, v)x + Iy (u , v)y (2) Where Ix and Iy are the partial derivatives of I. The SSD function can be expressed as follows:
C(x, y) =∑ ∑ ( )( ( ) ( ) ) (3) Further the SSD can be expressed in matrix form.
C (x, y) = (x, y) A ( ) (4)
A is the matrix derived from the gradient of the function. A is the Harris – Matrix which is formed by summarizing the major directions of the gradient of a neighborhood of a point and the degree to which these directions are logical.
A = ∑ ∑ ( )[ ] (5)
A corner point is distinguished by a large variation of C
in all directions of the vector (u, v). Let λ1 and λ2 be two Eigen values of A. based on the values of λ1 and λ2 the following conclusions are made and hence a corner point is determined.
a) If λ1 = 0 and λ2 = 0, then there is no interest point b) If λ1 = 0 and λ2 is large, then there is an edge. c) If λ1 is large and λ2 is also large, then there is a
corner.
Due to the expensive computation of the Eigen values, computation of R has been suggested by [12].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
273
Det (A) = λ1.λ2 and Trace (A) = λ1+ λ2.Shi-Tomasi Feature Detector: Shi-Tomasi [4] feature detector is fully based on Harris–Stephen feature detector with certain improvements which made the latter perform better in areas where the former fails. Shi-Tomasi feature detector identifies a corner using two Eigen values as Harris–Stephen but the alteration is made in the calculation of R. For Shi-Tomasi R is calculated as follows:
R = min (λ1, λ2) (7)
[image:4.612.321.576.131.238.2]If R is greater than a certain threshold then it can be concluded as a corner.
Figure 5. Pre-processing
D. Valid Feature Points Selection
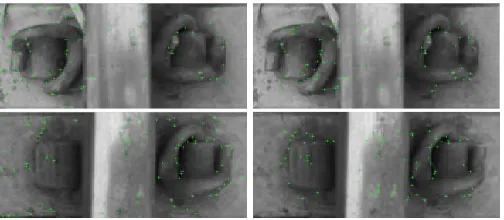
Feature points are detected using Harris–Stephen and Shi–Tomasi feature detector. Those points obtained are the centers of square neighborhoods. The consequent feature vectors containing the M × N features, are extracted along with the valid feature points. Detected all the points are not valid. Only those points are valid if the square neighborhood of that point is completely enclosed within the frame. If the neighborhood lies outside the frame that point is ignored. Figure 8 and 9 shows the possible feature points and the valid feature points detected using the two algorithms.
[image:4.612.47.299.307.421.2]Figure 6. Possible Harris-Stephen Feature Points (Left Column) Valid Feature Points (right column)
Figure 7. Possible Harris-Stephen Feature Points (Left Column) Valid Feature Points (right column)
E. Detection Procedure of Anchors based on Feature Matching and Thresholding
Feature Matching: The detection process is based on matching the feature vectors obtained in the previous section. The pair of the feature vectors (one for Harris-Stephen and the other for Sh–Tomasi) are matched with those of the training frames. Figure 8 explains the feature matching process.
The matrices named Features 1 and Features 2 are the feature vectors of a train frame and a test frame respectively. When a particular feature matches between these two metrics, their corresponding indices are stored in a new matrix. First column of that new matrix stores in the index of the matched features1 matrix the second column stores the index of the matched feature2 matrix
.
Aswe are using two detectors, eventually there will be two matrices (one from each detector) that storing the indices of the matched features.
The number of rows the new matrix measure the number of matches. The measure of matches of each detector is summed up and it must satisfy a threshold in order to conclude that an anchor has been detected. Figure 9 and 10 show the matched feature points between a training frame and a test frame for Harris-Stephen and Shi-Tomasi, respectively. Figure 10 illustrates the presence and the absence of the rail anchors.[image:4.612.331.572.592.695.2] [image:4.612.48.300.603.713.2]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
[image:5.612.58.296.134.226.2]274
Figure 9. Matched Harris-Stephen Feature Points.Figure 10. Matched Shi-Tomasi Feature Points.
F. Measuring the Dynamic Thresholding Value
The number of corners detected for each algorithm is different and hence the number of matches. Among the input frames used the maximum number of matches for Harris–Stephen is 11 and for Shi–Tomasi is 26. For Harris – Stephen, ×11=1.833 and for Shi–Tomasi, ×26 = 4.33. Summing up the results we get, 1.833 + 4.33 = 6.163. Flooring the sum, we get 6 and this is the threshold we have considered for our proposed approach. The formula for finding the threshold is generalized as follows:
T =└ [ (Max Harris – Stephen + Max Shi – Tomasi)] ┘ (8)
where T is the threshold, MaxHarris – Stephen is the maximum number of matches found through the implementation of Harris–Stephen algorithm and
MaxShi – Tomasi is the maximum number of matches
found through the execution of Shi–Tomasi algorithm.
G. Training of the Support Vector Machine (SVM)
The Shi - Tomasi and Harris – Stephen featureare invoked to train a SVM classifier for the purpose of recognizing the damaged/missed and grounded anchors. A training set of 500 images of those different anchors were collected. The 195 points are invoked as feature vector to train the SVM classifier. The trained SVM is employed to classify the damaged/missing and grounded anchors in the unknown scenes.
V. RESULTS AND DISCUSSION
Our experiment was tested on different video. Those are collected from different locations in Dhaka, Bangladesh under a wide range of visual conditions. The video comprised of both attached, missing and no anchors. Our proposed approach has achieved an average success rate of 90.91%. The experimental results are given in Table 1 and Table 2 and some experimental video frames are shown in Figure 12.
TABLE 1. DETECTION OF ATTACHED AND DAMAGED/MISSING ANCHORS (USING DYNAMIC THRESHOLDING)
Scenario No of
Frames
Correct Detection
Frame with Grounded Anchors
150 120
Frame with Missing Anchors
50 35
Frame with no Anchors
200 170
Total no of Frames 400 325
Total Detected (%) 100% 81.25%
TABLE 2.DETECTION OF ATTACHED AND DAMAGED/MISSING ANCHORS (USING SVM)
Scenario No of
Frames
Correct Detection
Frame with Grounded Anchors
150 136
Frame with Missing Anchors
50 40
Frame with no Anchors
200 185
Total no of Frames 400 361
[image:5.612.58.297.255.360.2] [image:5.612.320.568.272.471.2] [image:5.612.321.566.512.711.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
275
[image:6.612.51.290.142.325.2]Comparison between two approaches
Figure 11.Comparison Results between two Method.
Random Frame No Frame wise Result
Frame No: 1
Frame No: 2
Frame No: 49
Frame No: 50
Frame No: 113 Fastener Exist
Frame No: 150
Frame No: 226 Fastener Exist
Frame No: 530
Frame No: 556 Missing Fastener
0 50 100 150 200
Using Dynamic Thresholding
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 6, Issue 12, December 2016)
276
Frame No: 678 Detected as a Missing Fastener [image:7.612.48.290.105.332.2]Frame No: 730 Missing Fastener
Figure 12. Frame Wise Results (Random)
VI. CONCLUSION AND FUTURE RESEARCH
In this paper we have worked on a system that detects rail line anchors in real time. We are planning to design an intelligent car for our system which will run along the rail track and collect input data, process and store the information with the exact GPS location for future maintenance work. Along with the GPS receiver, we are planning to install a gyroscope and an accelerometer sensor in that cart which will let us know whether there is a height mismatch between both sides of the lines or not.
References
[1] Pavel Babenko, "Visual Inspection of Railroad Tracks," Ph D. dissertation, School of Electrical Engineering and Computer Science, University of Central Florida, 2006.
[2] http://www.railway.gov.bd/train_accidents.asp.
[3] Chris Harris and Mike Stephens, "A Combined Corner and Edge Detector," in 4th Alvey Vision Conf., Manchester, 1988, pp. 147-151.
[4] Jianbo Shi and Carlo Tomasi. "Good Features to Track," in Computer Vision and Pattern Recognition, Proceedings CVPR'94, IEEE Computer Society Conf., Seattle, 1994, pp. 593-600. [5] Sawadisavi, S., Edwards, J.R., Hart, J.M., Resendiz, E., Barkan,
C.P.L., Ahuja, N, ―Machine-Vision Inspection of Railroad Track,‖ in Proc. AREMA, 2008,Landover,Maryland.
[6] Yohan Rubinsztejn, "Automatic Detection of Objects of Interest from Rail Track Images," Masters of Science dissertation, Faculty of Engineering and Physical Science, University of Manchester, 2011.
[7] H Hoang Trinh, Norman Haas, Ying Li, Charles Otto and Sharath Pankanti, "Enhanced Rail Component Detection and Consolidation for Rail Track Inspection," in Application of Computer Vision (WACV) 2012 IEEE Workshop, Breckenridge, CO, 2012, pp. 289-295.
[8] Shah, M., ―Automated Visual Inspection/Detection of Railroad Track,‖ University of Central Florida. Rep. WO-08, July. 2010. [9] AURORA,Georgetown Rail Equipment Company:
http://www.auroratrackinspection.com. Accessed in April 2015. [10]ENSCO, Track Inspection Vehicles and Systems:
http://www.ensco.com. Accessed in April 2015.
[11]MERMEC Group, Diagnostic Solutions: http://www.mermecgroup.com, Accessed in April 2015.
[12]Naveen Chintalacheruvu and Venkatesan Muthukumar, "Video Based Vehicle Detection and its Application in Intelligent Transport Systems," Journal of Transportation Technologies, vol. 2, No. 4, 2012, pp. 305-314.
[13]Vimal Gupta and Pushpa Chaurasia, "Automatic and Robust Detection of Facial Features in Posed and Tilted Face Images," International Journal of Engineering Research and Applications, vol. 2, Issue 2, 2012, pp. 1119-1125.
[14]Durgesh and Lekha, ―Data Classification Using Support Vector Machine‖, Journal of Theoretical and Applied Information Technology, 2005-2009.