2016 3rd International Conference on Information and Communication Technology for Education (ICTE 2016) ISBN: 978-1-60595-372-4
1 INTRODUCTION
A main problem modern consumer faced is how to find useful information which is the information overload problem. To cope with this problem, Recommender Systems (RSs) are designed. Collaborative filtering(CF) is a well-known technique to generate recommendations (Adomavicius & Tuzhilin 2005). The two more successful approaches to CF are memory-based and model-based approaches. In this paper, we focus on the memory-based method, which can be classified into user-based and item-based approaches. User-based CF(UBCF) utilizes the similarity computed between the active user and all other users to predict the rating of a target item that has not been rated by the active user. Item-based CF(IBCF) applies the same idea of UBCF, but computes the similarity of two items rather than two users.
In order to solve several inherent deficiencies of CF, such as data sparsity and cold start, additional information from other sources have been studied and incorporated into traditional CF, such as social trust (Golbeck 2005, Massa & Avesani 2007). The trust information can be classified into two: explicit trust and implicit trust. The explicit trust which is directly by users themselves is more accurate than the implicit one. In this paper, we will only focus on the explicit trust. Recently, some works explore the
benefits of combining the explicit trust to further enhance RSs (Golbeck 2005, Massa & Avesani 2007, Guo et al. 2014). However, these works focus on either UBCF or IBCF. And some works predict ratings only based on ratings of trusted neighbors. Since trust information is also very sparse, the performance is limited. Only a few neighbors can be incorporated for recommendation. Some works rely on CF to find similar users before they can apply trust information. Since CF suffers from data sparsity and cold start problems, this fact leads to bad performance. Some works (Lampropoulos et al. 2012, Shambour & Lu 2012) suggest merging UBCF and IBCF to handle the data sparsity problems. However, those methods usually depend on heterogeneous information, such as music genre (Lampropoulos et al. 2012) or item taxonomy (Shambour & Lu 2012), so those methods are not generic.
Therefore, in this paper, we focus on improving the overall performance of RSs and mitigating the data sparsity and cold start problems of CF. A novel hybrid CF called “Hybrid” with the combination of trust is proposed in this paper. We use trust neighbors to pre-process user profile first before CF, so as to cover more ratings to help finding more similar neighbors. Then we propose a novel fusion method to combine UBCF and IBCF, And use both ratings of active user and trusted users to predict
A New Hybrid Collaborative Filtering Algorithm with
Combination of Trust
Yuqing Shi, Huan Zhao*, Yufeng Xiao
School of Information Science and Engineering, Hunan University, Changsha, Hunan, China
*Correspondence Author: [email protected]
ABSTRACT: Trust as one of additional information has been merged into traditional collaborative filtering(CF) to alleviate data sparisity and cold start problems. However, the trust based CF, some predict ratings only based on the ratings of trusted neighbors, or some rely on CF to find similar users before they can apply trust information, and very few of them merge user-based and item-based approaches together, but usually depend on heterogeneous information. In this paper, we propose a novel method called “Hybrid”. First, before CF we pre-process the user profile by using the ratings of trusted neighbors to form a new profile, which covers more ratings both of the active user and trusted users. Then, we use a novel general hybrid CF which merges user-based and item-based approaches together only based on rating information for making recommendations. Experimental results demonstrate that our method outperforms others both in accuracy and coverage.
ratings. Specifically, our work is only based on rating information, namely item ratings and trust ratings. Hence, our method is more generic than other hybrid ones.
The rest of the paper is organized as follows. Section 2 gives a brief overview of related works. Problems and notations are defined in section 3. The details of our proposed method are presented in section 4. Experiments are conducted and analyzed in section 5. Finally, section 6 concludes our work and outlines potential future research.
2 RELATED WORK
CF suffers from fundamental problems: data sparsity and cold start. To solve the problems, trust as one of additional information has been merged into CF. The TCF approach (Chowdhury et al. 2009) enhances UBCF by using ratings of similar users' trusted neighbors to predict ratings of similar users who have not rated target items, so as to incorporate more users. TCF relies on CF to find similar users before it can apply trust information. The Mole Trust approach(Massa & Avesani 2007) uses trust propagation. Their work uses the explicit trust information to infer the trust value of the undirected users. The Mole Trust approach predicts ratings only based on the ratings of trusted neighbors. The Tidal Trust approach(Golbeck 2005) which also uses the directed trusted neighbors to infer the undirected trusted users as is done in Mole Trust, differs because it uses a breath-first search method whereas Mole Trust uses the depth-first search method. Recently, the Merge method (Guo et al. 2014) incorporates trusted neighbors into traditional UBCF. Their work uses ratings of the trusted neighbors to improve the preferences of the active user, so as to help finding more similar user neighbors. UBCF will works effectively when there are a lot of common ratings between two users. Their work suffers from the drawbacks of UBCF. By merging UBC Fand IBCF can also alleviate data sparsity and cold start of CF, such as (Shambour & Lu 2012) combines the user-based trusted-based CF and item-based semantic enhanced CF, and considered user-item ratings information and semantic information about items. However, those hybrid methods usually depend on more heterogeneous information, such as music genre (Lampropoulos et al. 2012) or item taxonomy (Shambour & Lu 2012), so those methods are not generic.
3 PRELIMINARY
We denote the sets of all users, all items and all ratings as U, I and R, respectively. For clarity, Table
[image:2.612.316.555.80.407.2]1 lists the descriptions of notations that will be used in formulas below.
Table 1. Notations.
__________________________________________________ Notations Descriptions
__________________________________________________ u,v, i, j user u, v, item i, j
N The number of testing ratings M The number of predictable ratings Iu Set of items rated by user u
Iu,v Set of common items rated by user u and v I’u Set of items that have been rated by at least one
trusted neighbors but user u has not rated. Ui Set of users who rated item i
U’i Set of users have not rated item i before the
pre-processing step, but merged by trusted users Ui,j Set of common users both rated item i and j NNu Set of similar users for user u
#NNu Number of the similar neighbors of user u
s A predefined user similar threshold
su,v Extent of the similarity between user u and v NNi Set of similar items for item i
#NNi Number of the similar neighbors of item i
’
s A predefined item similar threshold si,j Extent of the similarity between item i and j TNu Set of trust neighbors for user u
t A predefined trust threshold
tu,v Extent of trust between user u and v,tu,v ∈ 0,1 fu,v Extent of familiar between user u and v,fu,v∈ 0,1 cu,i Merged rating confidence
rui Rating of user u on item i
̂,. The predicted ratings
̃,. The merged ratings for user u on item i∈ ′
̅,̅ Average ratings of item I and user u, respectively rmax, rmed,rmin The maximum, median, minimum rating scale
__________________________________________________
4 THE NOVELHYBRID CF ALGORITHM
In this section, we will present our proposed Hybrid method. The details of the approach are given in the subsequent sections.
4.1 Pre-processing of the users’ preference profile
4.1.1 Computing the merged ratings similarity
algorithm. The opinions of neighbors at distance d
are more important than at distance d+1 (Ray & Mahanti 2010). The weighting factor is adopt to distinguish trusted neighbors in a shorter distance with those in a longer distance (Golbeck 2005, Guo et al. 2014).
tu,v=1
d*tu,v
' (1)
Where, u, v∈TNu and tu,u= 1. , is computed by MoleTrustwhich denotes the inferred trust value. To avoid taking more cost of meaningless search and computation, set d≤ 3, t= 0. People trusting each other may not share similar preferences(Singla & Richardson 2008). Two users are socially close if they share numbers of trusted neighbors, it is possible that users may believe more in their familiarity trusted neighbors' ability in giving accurate ratings(Ray & Mahanti 2010).Therefore, it is necessary to consider rating similarity su,v , trust value tu,v and social familiarity fu,v to weight the importance of the trusted neighbors’ ratings:
wu,v=α·su,v+β·tu,v+γ·fu,v (2)
Where wu,v is the importance weight,, and
the linear weighted coefficients with + + =
1. The user similarity is computed by Pearson correlation coefficient(Adomavicius & Tuzhilin 2005):
su,v= ∑i∈Iu,vru,i-r̅urv,i-r̅v ∑ ru,i-r̅u
2
i∈Iu,v ∑ rv,i-r̅v
2
i∈Iu,v
(3)
Trusted neighbors with high similarity have a positive influence on rating protection(Ray & Mahanti 2010). So, we only consider the positive similarity, su,v> 0. Jaccard index is utilized to compute fu,v defined as the ratio of shared trusted neighbors:
, =|"#|"#$$∩"#∪"#&&|| (4)
Finally, we use Eq. (5) considering wu, vto merge all ratings of trusted neighbors on each item j∈ I) into a single merged rating.
r̃u,j=∑∑v∈TNuwu,v·rv,j *wu,v*
v∈TNu
(5)
4.1.2 Computing the merged rating confidence
The merged rating confidence cu,i is to guarantee merged ratings are correct and reliable. And it also can mitigate influence of less trustworthy users who may be involved into the computing. If the rating value which is greater than rmed, it reflects a positive opinion. Otherwise it reflects a negative opinion:
+, is positive: if, > 678 ;
, is negative: if , ≤ 678 ; (6)
cu,i is a function of pu,i and nu,i defined in the evidence space (refers to (Wang & Singh 2007)):
cu,i= 1
2= >
xpu,i1-xnu,i
= xpu,i1-xnu,idx
1 0
-1>dx
1
0 (7)
Where cu,i∈ ?0,1, i∈
′
. pu,i and nu,i denotes
consistent extent between positive and negative opinions and number of ratings involved into computing merged ratings, respectively. Consequently, the greater pu,i and nu,i, the greater cu,i will be. We usẽ,andcu,i to form a new user preference profile. Since we keep the existed user ratings profile unchanged, the value of cu,i is 1(i∈ ).@= ∪ ′
and AB= A∪ A′denote set of
items and users after merged by the pre-processing step, respectively. Since ∈ B,A∈ AB,,the new rating profile can cover more ratings than the original one.
4.2 Making recommendations
In this section, the new user profile which has been formed in the pre-processing step will be used as a foundation to make recommendations.
4.2.1 User-based collaborative filtering
The first step of UBCF is to compute the similarity between user u and all other users to find similar neighbors. In this section, we use the new rating profile obtained after the pre-processing stage. The new rating profile covers more items, especially for the cold users. It can make more common items between users, so as to find more similar neighbors for the active user. Generally, Pearson correlation coefficient (PCC) is often adopted to measure the similarity between two users or two items. We consider cu,i when applying PCC to compute similarity between the active user u and other users according to their ratings on common items that they have rated, CUPCC (refers to (Xue et al. 2005)):
s'u,v=
∑i∈Iu,vcu,ir̃u,i-r̅urv,i-r̅v ∑i∈Iu,vc2u,ir̃u,i-r̅u2∑ rv,i-r̅v
2
i∈Iu,v
(8)
Where, denotes real ratings rated by user
v(v ∈ DD), cv,i = 1. The purpose of the pre-processing is to find more similar neighbors. Since few similar neighbors will be found especially for cold users, we take the similar thresholding rather than top-N method to select similar neighbors for user u, and user similar threshold sis set to 0.The second step of UBCF is to aggregate all ratings of similar neighbors of user u to produce a prediction on a target item j that the user u has not rated yet. Like related works (Golbeck 2005, Guo et al. 2014),the simple weighted average method is used in our work to produce the prediction:
r̂u,j=
∑v∈NNus'u,v·rv,j ∑ *s'u,v*
v∈NNu
The similarity s’u,v is used as a weight to ensure the users with high similarity will have more influence than low similarity on the predictions.
4.2.2 Item-based collaborative filtering
Similar to UBCF, the first step is to compute similarity between item i and all other items to find similar neighbors. In this section, we use the new rating profile obtained after the pre-processing stage. Since the new rating profile covers more items, it is easy to find more similar item neighbors. Like in the former section, we also use PCC to compute similarity between two items, and consider cu,i, CIPCC:
s'i,j=
∑u∈Ui,jcu,ir̃u,i-r̅iru,j-r̅j ∑u∈Ui,jc2u,ir̃u,i-r̅i2∑ ru,j-r̅j
2
u∈Ui,j
(10)
Where, denotes the real ratings on the item j,
j∈ DD, cu,i = 1. We also take the similar thresholding rather to select the similar neighbors for item i, and the item similar threshold ’sis set to 0. The second step is to aggregated all ratings of similar neighbors of the item i to produce a prediction on a target item
j that the user u has not rated yet. Similarly, The simple weighted average method is utilized in our work to produce the prediction:
r̂u,j=∑ s '
i,j·EF,G j∈NNi ∑ *s'i,j*
j∈NNi
(11)
Where similarity s’i,j is used as a weight to ensure the items with high similarity will have more influence than low similarity on the predictions.
4.2.3 The fusion
CF will works effectively when there are a lot of common ratings. We adopt the new rating profile after pre-processed to cover more ratings especially for the cold users so as to find more similar neighbors. However, the performance will be limited since only a few neighbors can be incorporated by the pre-processing step. One reason is that the trust information is also very sparse. A small number of other users are specified by the active user as their trusted users. Even worse, when the active user has not specified any trusted neighbors, the new profile of the user will has no much difference with the original one. The other is that in order to form a correct and reliable profile and to avoid noisy trusted neighbors involved, a short trust propagation length is selected. Good performance can be achieved by combing UBCF and IBCF. Therefore we take the pre-processing of user profile to cover more ratings, and we also consider the hybrid CF to further improve the performance.
UBCF and IBCF have their own advantages and disadvantages. If the active user has already rated many items, and these items have high similarity, it indicates that the active user has a more single and
stable interest reference. In this case, it is more appropriate to choose IBCF to make a recommendation. Similarly, if the active user has many similar neighbors, it is more appropriate to choose UBCF. Since each user has different situation, we should choose a hybrid method for each user. Because of the numbers of similar neighbors and the value of similarity are used as a foundation for prediction, it is necessary to consider them to reflect the situation of each user. The situation of items, which the active user has already rated, can be defined as Q(i). Similarly, the situation of similar neighbors for the active user can be defined as Q(u):
H?I = ∑&∈MM$JK$,&L
###$ (12)
H?OI =∑Q∈MMPJKP,QL
###P (13)
Where, s’u,v and s’i,j denote the similarity considered the merged ratings confidence between two users and two items, respectively. Because of the neighbors with high similarity have a positive influence than low similarity on the rating protection, we use the sum of squares of the similarities to mitigate the influence of the less similarity users and to hence users with high similarity. When if the active user u has many (i.e.10) similar neighbors but the similarity is very small (i.e.0.01) between two users, and if the test item i has few (i.e.1) similar neighbors but the similarity is almost equal to 1, we think that the item
i is more valuable and reliable for prediction andIBCF is more suited to make a recommendation. To choose an approach method for each user, we shall introduce the parameter Rto makeQ(i) and
Q(u)comparable:
+if if λ·Qλ·Q??uuII>Q≤Q??iiII, select the UBCF;, select the IBCF ; (14)
Considering the possible noises may introduce during the pre-processing step, the parameter λ is important and necessary. The value of the λ is tuned and selected an appropriate value for every different dataset views in the experiment.
5 EXPERIMENTS AND ANALYSIS
5.1 Dataset Description
and user-item ratings. Due to the sharing policy, trust values of users are not available and they are converted into binary values. If a user who has been specified by the active user, the trust value is 1, otherwise the value is 0.
5.2 Experimental design and evaluation metrics
The Film Trust data set is studied in three different details as defined in(Massa & Avesani 2007):All Users, represents the whole data set; Cold Users, represents users who rated less than five items;
Niche Items, represents items which received less than 5ratings.
In our experiments, we compare Hybrid with the following approaches:
1. CF computes user similarity using the PCC measure, selects the users whose similarity is greater than a predefined threshold s, and uses their ratings for predictions. In this work, s is set 0 for all methods.
2. MT x(x=1,2,3) is the implementation of the Mole Trust approach(Massa & Avesani 2007) in which trust is propagated in the trust network with the length x. Only trusted neighbors are used to predict item ratings.
3. TCF x(x=1,2) proposed by (Chowdhury et al. 2009) that enhances UBCF by using the ratings of the similar users' trusted neighbors.
4. Merge x(x=1,2,3)proposed by (Guo et al. 2014) that incorporates trusted neighbors into traditional UBCF. According to their work, the trust threshold is set 0, and the settings of (, ) are (0.5, 0.3). We adopt the same settings in our experiments.
5. Hybrid x(x=1, 2, 3) is our method with the trust propagation length x, the trust threshold is set 0.
In order to validate the performance of Hybrid, we use a popular technique for evaluating RSs named Leave-one-out. In this paper, we use three important and commonly used evaluation metrics: mean absolute error (MAE), ratings coverage and the overall performance in considering both rating accuracy and coverage measures-measure (F1):
TUV =∑ ∑ *Ŵ$ P $,PXW$,P*
# (15)
YZ =[# (16)
\1 =]∙[_`∙ab[_`cab (17)
OTUV = 1 −W [_`
efgXWePh (18)
iMAE is another accuracy metric which is normalized MAE by the range of rating scales. The smaller the MAE is, the more accurate the prediction is. RC measures the degree to which the testing ratings can be predicted and covered relative to the whole testing ratings.
5.3 Results and analysis
Three data set views, namely All Users, Cold Users
[image:5.612.315.551.137.280.2]and Niche Items are tested. The results are presented in Tables 2-4 corresponding to the predictive performance on the Film Trust dataset.
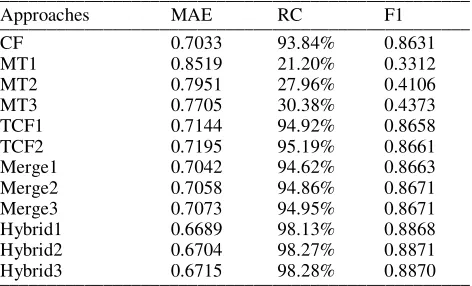
Table 2. Accuracy, coverage and F1 measures on All Users data set views for different algorithms.
[image:5.612.314.551.320.462.2]__________________________________________________ Approaches MAE RC F1 __________________________________________________ CF 0.7033 93.84% 0.8631 MT1 0.8519 21.20% 0.3312 MT2 0.7951 27.96% 0.4106 MT3 0.7705 30.38% 0.4373 TCF1 0.7144 94.92% 0.8658 TCF2 0.7195 95.19% 0.8661 Merge1 0.7042 94.62% 0.8663 Merge2 0.7058 94.86% 0.8671 Merge3 0.7073 94.95% 0.8671 Hybrid1 0.6689 98.13% 0.8868 Hybrid2 0.6704 98.27% 0.8871 Hybrid3 0.6715 98.28% 0.8870 __________________________________________________
Table 3. Accuracy, coverage and F1 measures on
Cold Users dataset views for different algorithms.
[image:5.612.315.550.504.644.2]__________________________________________________ Approaches MAE RC F1 __________________________________________________ CF 0.7442 39.64% 0.5273 MT1 0.8530 17.11% 0.2790 MT2 0.8797 23.19% 0.3541 MT3 0.8195 23.85% 0.3637 TCF1 0.7511 39.97% 0.5298 TCF2 0.7512 40.79% 0.5369 Merge1 0.7676 53.45% 0.6346 Merge2 0.7721 54.11% 0.6388 Merge3 0.7677 54.28% 0.6403 Hybrid1 0.7549 54.11% 0.6404 Hybrid2 0.7633 54.93% 0.6453 Hybrid3 0.7633 54.77% 0.6442 __________________________________________________
Table 4. Accuracy, coverage and F1 measures on
Niche Items dataset views for different algorithms.
__________________________________________________ Approaches MAE RC F1 __________________________________________________ CF 0.9869 54.05% 0.6167 MT1 1.0310 14.04% 0.2342 MT2 1.0106 19.35% 0.3043 MT3 0.9617 25.36% 0.3758 TCF1 1.0140 64.20% 0.6744 TCF2 1.0119 66.79% 0.6887 Merge1 0.9798 57.18% 0.6374 Merge2 0.9868 59.30% 0.6496 Merge3 0.9825 60.47% 0.6570 Hybrid1 0.9025 95.54% 0.8354 Hybrid2 0.8851 96.87% 0.8436 Hybrid3 0.8728 96.96% 0.8462 __________________________________________________
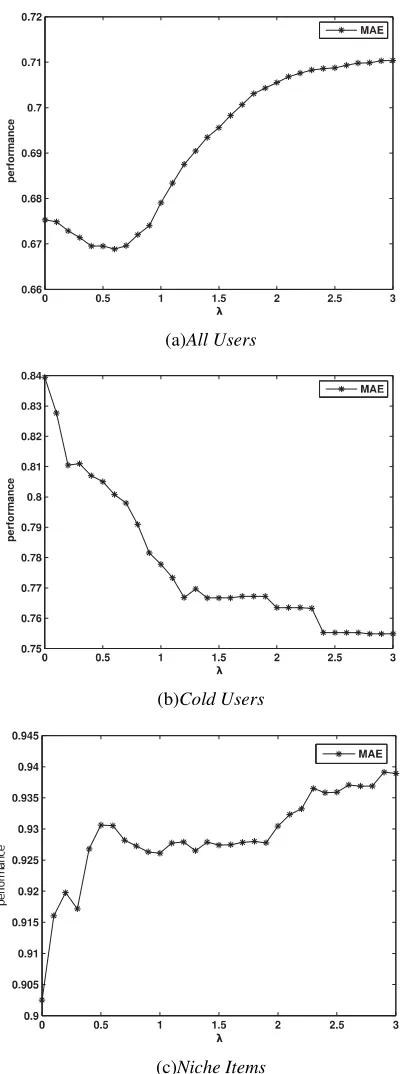
5.3.1 Effect of the fusion parameter
illustrated in Figures 1-2. The settings of parameter
R for Hybrid x are determined by experiments. The settings are: (1) Hybrid1: R = 0.6,2.8, 0corresponding to the data view of All Users, Cold Users and Niche Items, respectively; (2) Hybrid2 andHybrid3: R= 0.4, 2.8, 0 corresponding to the data view of All Users, Cold Users and Niche Items, respectively(Because ofHybrid2 and Hybrid3 have the same results, we use one figure to display ). The appropriate value of the parameter R setting is almost the same for Hybrid x from the results of experiments. Especially in view of Niche Items, the best method is IBCF.
(a)All Users
(b)Cold Users
(c)Niche Items
Figure 1. The effect of R for performances of Hybrid 1 in three different data views.
(a)All Users
(b)Cold Users
(c)Niche Items
Figure 2. The effect of R for performances of Hybrid 2 andHybrid 3 in three different data views.
5.3.2 Trust propagation in different lengths
[image:6.612.327.532.38.593.2] [image:6.612.71.273.195.732.2]propagation length, it may result in some noisy trusted neighbors involved. Moreover the trust information is also very sparse, only a few neighbors can be incorporated by the pre-processing step. Therefore, considering the cost and limits of the trust propagation, we should combine UBCF and IBCF to make a further improvement.
5.3.3 Comparison with other methods
From Tables2-4, CF method works worse in both coverage and F1, especially in Cold Users and Niche Items views. So, CF suffers from cold start and data sparsity problems. MT x methods obtain the worst performance. It is because they predict ratings only based on the ratings of trusted neighbors. However, trust information is also very sparse. TCF methods are slightly improved in both coverage and F1 compared with the baseline CF method. It is because TCF use CF to find similar neighbors before trust information is merged. Merge x methods outperform TCF, because Merge x methods merge trust information to form user profile before applying CF. Since Merge x methods suffer from the drawbacks of UBCF, Merge x work not good in Niche Items
view. No matter when only the direct trusted neighbors are used(x=1) or when the trust propagation length is longer, our Hybrid x methods outperform others in all three data views.
6 CONCLUSIONS
In this paper we have presented our proposal for enhancing traditional CF by using trust information and combining UBCF and IBCF, aiming to all eviatedata sparsity and cold start problems. Firstly, we use ratings of trusted neighbors to form a new user profile which covered more ratings in the pre-processing step to help finding more similar neighbors. Then specifically considering the sparsity of the trust network and the limits of the trust propagation, we make further improvements by combining UBCF and IBCF. We consider both numbers of similar neighbors and the value of the similarity to select an appropriate fusion parameter value in the three different data views. Experiments on the real-world data set are conducted and the results showed that our proposed Hybrid approach outperformed other approaches both in accuracy and coverage as well as the overall performance. In the future, we will merge implicit trust in the pre-processing step and explore some better CF fusion methods.
7 ACKNOWLEDGMENTS
This work was supported by National Science Foundation of China (Grant No. 61173106).
REFERENCES
[1]Adomavicius, G. & Tuzhilin, A. 2005. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. Knowledge and Data Engineering, IEEE Transactions on, 17, 734-749.
[2]Chowdhury Y, M., Thomo, A. & Wadge, W. W. Trust-Based Infinitesimals for Enhanced Collaborative Filtering. COMAD, 2009.
[3]Golbeck, J. A. 2005. Computing and applying trust in web-based social networks.
[4]Guo, G., Zhang, J. & Thalmann, D. 2014. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowledge-Based Systems, 57, 57-68.
[5]Lampropoulos, A. S., Lampropoulou, P. S. & Tsihrintzis, G. A. 2012. A cascade-hybrid music recommender system for mobile services based on musical genre classification and personality diagnosis. Multimedia Tools and Applications, 59, 241-258.
[6]Massa, P. & Avesani, P. Trust-aware recommender systems. Proceedings of the 2007 ACM conference on Recommender systems, 2007. ACM, 17-24.
[7]Ray, S. & Mahanti, A. Improving Prediction Accuracy in Trust-Aware Recommender Systems. Proceedings of the 2010 43rd Hawaii International Conference on System Sciences, 2010. IEEE Computer Society, 1-9.
[8]Shambour, Q. & Lu, J. 2012. A trust-semantic fusion-based recommendation approach for e-business applications. Decision Support Systems, 54, 768-780.
[9]Singla, P. & Richardson, M. Yes, there is a correlation:-from social networks to personal behavior on the web. Proceedings of the 17th international conference on World Wide Web, 2008. ACM, 655-664.
[10] Wang, Y. & Singh, M. P. Formal Trust Model for Multiagent Systems. IJCAI, 2007. 1551-1556.