2017 2nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017)
ISBN: 978-1-60595-485-1
Application of Improved Bayes Algorithm in
Harassing Calls Identification
HONGZHI TANG, ZHIZHONG ZHANG and RUILI ZHAO
ABSTRACT
As a simple and efficient classification algorithm, Naive Bayes (NB) algorithm has been applied in the field of harassing calls recognition, But in reality, it is difficult to satisfy its attribute independence hypothesis. The Weighted Bayes (WB) is an improved algorithm that assigns different weights for different feature attributes to reduce the impact of attribute independence hypothesis on classification results. Different calculation methods of weights will have a great influence on the classification performance. By fruit fly optimization algorithm (FOA) can optimize the weight of attributes, which obtain an Improved Weighted Bayes algorithm (IWB) to improve the performance and accuracy of the recognition of harassing calls. Simulation results show that compared with NB algorithm and WB, IWB algorithm can apparently improve the effect of the recognition of harassing calls, and the recognition accuracy is increased by 3.8% as well.
KEYWORDS
Navie Bayes; Harassing call; Classification; Fruit fly optimization algorithm.
INTRODUCTION
The development of communication industry is a double-edged sword, which brings convenience to people's daily life. At the same time, the phenomenon of frequent occurrence of spam messages and harassing calls has also occurred. These not only disrupt the normal order of telecommunications operations, but also may lead to huge property losses to users, and affect social stability and harmony. In response to harassing calls, telecom operators and Internet Co have proposed some solutions, but the results are not satisfactory. Therefore, the research on the identification and interception of harassing calls has important practical significance. Liu et al applied data mining technology to mobile communication network harassing calls monitoring system, established accurate data model, and screened out harassing telephone number by using Naive Bayes (NB) algorithm [1], However, NB algorithm has the attribute
independence hypothesis, that is, the attributes are independent and do not affect each other, which affects the performance of harassing calls identification. Li et al proposed a constructive idea based on Chi-square fitting statistics to assign different weights to the Bayesian algorithm in order to weaken the assumption of independence [2].
_________________________________________
Hongzhi Tang, [email protected], Zhizhong Zhang, [email protected], Ruili Zhao, [email protected], Chongqing University of Posts and
It has been proved to be effective in the field of text categorization, but the classification efficiency needs to be improved for a class of datasets with higher number of classes. Swarm intelligence optimization algorithm has a good searching performance, but its research and application in the field of harassing calls identification is not enough.
Therefore, this paper proposes an Improved Weighted Bayes (IWB) algorithm and applies it to the identification of harassing calls. On the one hand, the algorithm preserves the efficiency and simplicity of the NB algorithm, i.e. the independence of the feature attributes, which reduces the computational complexity; On the other hand, Fruit fly optimization algorithm (FOA) is used to optimize the different attributes of NB algorithm to get more consistent feature weight and improve the recognition effect of harassing calls.
RELATED TECHNIQUE
Naive Bayes model.
Naive Bayes is an algorithm that uses probability and statistics to classify. Suppose there are P attributes and n samples in the data set. Sample X can be expressed asX
x x1, , ,2 xp
, xi is the value of attribute i. Assuming that there are m categories, the probability that the sample X belongs to classCk(1 k m) can be calculated by the Bayes formula,Need to calculate:
( ) ( )
( )
( )
k k
k
P X C P C P C X
P X
(1)
In formula (1), P X( )can be considered as a constant due to the set of training samples. ( )P Ck s nk , Among them, n is the total number of training samples, and
k
s is the sample number of classCk , which can be directly calculated. Therefore, the value of (P Ck X) depends on the calculation of (P X Ck) . Since there is an attribute independence hypothesis in naive Bayes model, i.e.
1 2
1
( k) ( , , , ,j n k) n ( j k)
j
P X C P x x x x C P x C
(2)Judgment rule: when (P Ck X)P C X( l ) ,kl thenX
x x1, , ,2 xn
Ck .1
( ) j( )
n w
k j k
j
P X C P x C
(3)The key is to construct a reasonable weight coefficient.
Fruit fly optimization algorithm.
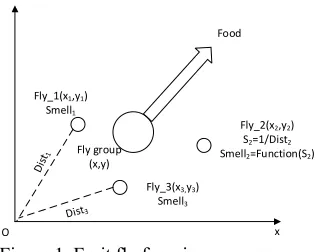
The fruit fly optimization algorithm is a heuristic intelligent optimization algorithm based on the foraging behavior of fruit flies. The whole foraging process is shown in figure 1, which was proposed by Wenchao Pan in 2011 for the study of financial early warning model [3-4]. FOA has a good swarm intelligence, and compared
with other intelligent optimization algorithm, FOA has the advantages of simple algorithm structure, easy programming, less adjustment parameters, small computation, strong global search ability and high precision etc. It has been successfully applied to many scientific and engineering fields [5-6].
According to the thought of the FOA, the process of optimizing the algorithm can be divided into the following steps:
(1) Set the parameters, i.e. the population size of the flies (sizepop) and the number of iterations of the algorithm (maxgen). Randomly initialize the flies' population position (X_axis,Y_axis);
(2) Giving individuals of flies the random distances and directions to search for food using scent, with the range of [-1, 1], as formula (4),
_ 2 () 1
_ 2 () 1
i
i
X X axis rand
Y Y axis rand
(4)
(3) Since the location of the food is not known, the distance from the origin (Disti) is estimated first, as formula (5). Then calculate the taste concentration value (Si) as formula (6); which is the reciprocal of the distance,
2 2
(
i i i
Dist X Y (5)
1
i i
S Dist (6)
(4) The taste concentration value (Si) is substituted into the taste concentration determination function (or Fitness function) to determine the taste concentration (Smelliof the individual position of the fruit fly, as formula (7),
( )
i i
Smell function S (7)
In the formula, the taste concentration decision function needs to be determined according to the actual situation;
(5) Compare the taste concentration at each location ( , )X Y of the fruit fly and
Fly_1(x1,y1) Smell1
Fly_2(x2,y2) S2=1/Dist2 Smell2=Function(S2)
Fly_3(x3,y3) Smell3 Fly group
(x,y)
Food
O x
[image:4.612.229.387.58.184.2]y
Figure 1. Fruit fly foraging process.
(6) Determine the location of the fruit flies with the highest taste concentration and the current taste concentration values. Using the fruit fly's vision all flies fly to the optimum individual position and update the location of the population.
(7) Enter the iteration to find the optimal value. When the iterations are less than the maximum number of iterations (maxgen), repeat the step (2) ~ (6). And determine whether the taste concentration is better than the previous one, if so, implement step (6) until the maximum number of iterations, find the target location.
HARASSING CALLS CLASSIFICATION OF IWB BASED ON FRUIT FLY OPTIMIZATION ALGORITHM
Selection of eigenvalues.
When a data sample is represented as a feature vector, the original feature space is usually up to tens of dimensions. If the classifier is trained and classified directly in such a high-dimensional feature space, not only the computational complexity of the sample classification is too large, but also the estimation of the statistical features of the sample becomes very difficult. Therefore, it is necessary to reduce the dimension of the original space without affecting the accuracy of classification before training the training samples. The method of information gain is used to reduce the dimension of the original space [7]. The definition of information gain is as formula (8):
2 2
1 1
2 1
( ) ( ) log ( ) ( ) ( | ) log ( | )
( ) ( | ) log ( | )
m m
i i i i
i i
m
i i
i
IG T P C P C P t P C t P C t
P t P C t P C t
(8)Among them, ( )P Ci is the probability that occurrence of class Ci , ( | )P C ti is
the probability that contains attribute t and belongs to class Ci , P C t( i| )
is a probability that does not contain attribute t, but belongs to class Ci , ( )P t is the
probability that the occurrence of attribute t, ( )P t
average ringing time, number concentration, dial empty number ratio are selected as a decision attribute according to the size of the contribution of the system information.
Improved weight calculation method based on fruit fly optimization algorithm.
This paper selects the call frequency, turn-on rate, the average ringing time, number concentration, dial empty number ratio as a decision attribute. According to the fruit fly optimization algorithm, the objective function is first defined, i.e. the taste concentration decision function. Initialize 5 groups of flies, assigned towj, j1, 2, 5 . Each group had 10 fruit flies and randomly initialized the location of the flies group, ranging from [0, 1]. Perform iterative optimization steps. Searching for the best wj by
100 iterations makes the prediction approach to the target value gradually. In the ideal case, as shown in formula (9):
1, 0,
Y N
x C
x C
(9)
Let (1) be, in this paper, the objective function of the weight
w is determined by the least-square method, as shown in formula (10):
5
2
1
( ) min ( )
j
f w
(10)Sample classification.
Use formulas (1) and (3) to calculate (P Ck X), when (P CY X)P C( N X), we
can determine that number is a harassing phone number, otherwise it is a non-harassing phone number.
TEST RESULT AND ANALYSIS
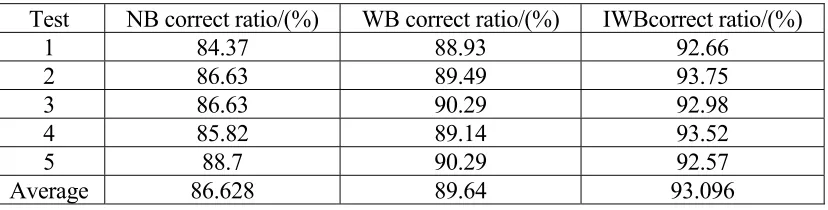
[image:5.612.93.507.617.722.2]In order to verify the classification effect of the proposed IWB algorithm, we have implemented NB algorithm, WB algorithm and IWB algorithm on the computer with CPU of 3.30 GHz and 16.00 GB of memory. Five tests were conducted using the method of cross validation. In each test, the training set is 80% and the test set 20%. The correct rate of classification was obtained under three kinds of algorithms, and the average of the tests was taken as the result. The test results are shown in table 1.
Table 1. Comparison of test results.
Test NB correct ratio/(%) WB correct ratio/(%) IWBcorrect ratio/(%)
1 84.37 88.93 92.66
2 86.63 89.49 93.75
3 86.63 90.29 92.98
4 85.82 89.14 93.52
5 88.7 90.29 92.57
1 2 3 4 5 50
55 60 65 70 75 80 85 90 95 100
Number of times
Corre
ct
Ra
tio
/(%
)
[image:6.612.142.453.61.228.2]NB WB IWB
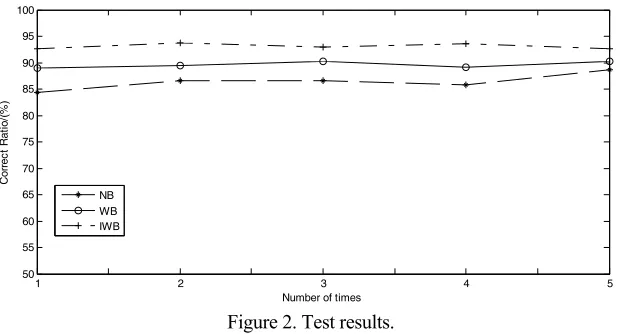
Figure 2. Test results.
As can be seen from table 1, when we use WB algorithm, the accuracy of classification is better than that using NB algorithm; when using IWB algorithm for weight optimization operation, the correct rate has been further improved, Compared with the WB algorithm, the increase is about 3.8%. In order to facilitate the visual observation, the accuracy rate of the 5 cross experiments is described in this paper as shown in figure 2.
SUMMARY
In this paper, the algorithm is improved based on Bayesian correlation theory, and the IWB algorithm is applied to the identification of harassing calls. This algorithm retains the advantages of simplicity and efficiency of naive Bayes, and reduces the influence of attribute independence hypothesis on classification results by attribute weighting method. The least-squares method is used as the objective function to calculate the weights, and the weights are optimized by FOA algorithm to improve the classification effect of the harassing calls. The experimental results show that the IWB algorithm can effectively improve the classification accuracy of the harassing call. The limitation of this algorithm is that FOA uses fixed search step size, and it is difficult to take into account both global search ability and local search ability in iterative optimization, which affects the convergence speed and accuracy.
REFERENCES
1. Jian Liu. Realization of harassing telephone identification based on Data Mining Technology [D]. China University of Geosciences (Beijing), 2011.
2. Fang Li, Qiongsun Liu. A Naive Bayesian Classification Model Based on Improved Attribute Weighting [J]. Computer Engineering and Application, 2010, 46 (04): 132 -133 +141.
3. Wenchao Pan. A new evolutionary computation approach: Fruit fly optimization algorithm [C]//2011 Conference of Digital Technology and Innovation Management, 2011.
4. Wenchao Pan. Application of fruit fly optimization algorithm to generalized regression neural network for evaluation of enterprise performance [J]. Journal of Taiyuan University of Technology (Social Science Edition), 2011, 29(04): 1-5.
5. Ziguang He, Fasuo Zhao, Bin Wu. Application of fruit fly optimization algorithm in slope minimum safety factor search [J]. Journal of Catastrophology, 2015, 30(04): 29-33.
6. Xu Tian, Jie Li. Improved fruit fly optimization algorithm and its application in aerodynamic optimization design [J]. Acta Aeronautica ET Astronautica Sinica, 2017, 38(04): 60-70.