Multiple Node Fault Diagnosis System in Externally Managed Networks
P. Saranya
1C. Prakash Narayanan
2B. Sakthivel
31
PG Scholar
2Assistant Professor
3Head of Dept.
1,2,3
Department of Computer Science
1,2,3
P.S.V College of Engineering and Technology, Krishnagiri, TN, India
Abstract— In this paper, we break down the effect of system coding (NC) design on the execution of specially appointed systems with the thought of two critical variables, in particular, the throughput misfortune and the disentangling misfortune, which are together regarded as the overhead of NC. Specifically, physical-layer NC and arbitrary direct NC are embraced in static and versatile specially appointed systems (MANETs), separately. Besides, we portray the goodput and deferral/goodput tradeoff in static systems, which are likewise examined in MANETs for various portability models and transmission plans. Additionally, the ideal setup of NC, which comprises of the information measure, age size, and NC Galois field, is inferred to enhance the deferral/goodput tradeoff and goodput. The hypothetical outcomes exhibit that NC does not achieve arrange pick up on delay/goodput tradeoff for each system model and plan, aside from the flooding plan in an arbitrary. portability display. In any case, the goodput change is shown for all the proposed plots in portable systems. To our best learning, this is the primary work to research the scaling laws of NC execution and design with the thought of coding overhead in impromptu systems. Our streamlining objective is to limit the normal cost of redressing (i.e., diagnosing and repairing) all flawed overlay hubs that can't appropriately convey information. Rather than first checking the in all likelihood defective hubs as in ordinary blame restriction issues, we demonstrate that an ideal system should begin with checking one of the competitor hubs, which are recognized in view of a potential capacity that we create. This task proposes a few proficient heuristics for deriving the best hub to be checked in extensive scale systems. By broad recreation, this task demonstrate that we can surmise the best hub and that initially checking the applicant hubs instead of the in all probability flawed hubs can diminish the checking expense of remedying every single broken hub. This venture is created in VB.Net as front – end.
Key words: Network Management, Network Diagnosis and Correction, Fault Localization and Repair, Reliability Engineering
I. INTRODUCTION
Framework parts are level to a combination of insufficiencies, for instance, allocate, association cut, or hub power outage. To shield the broken fragments from obstructing framework applications, it is basic to break down (i.e., recognize and restrict) the parts that are the fundamental driver of framework insufficiencies. Then again, it is moreover appealing to repair the inadequate parts to engage them to return to their operational states. Thusly, we focus on framework inadequacy alteration, by which we intend to break down, and in addition to repair each and every imperfect fragment within a framework. Likewise, it has been shown that a framework power outage can bring vital fiscal setback. In like manner, we have to devise a
monetarily adroit framework weakness correction instrument that changes all framework blemishes in any event cost. To dissect (however not repair) framework insufficiencies, late approachs like use all framework hubs to helpfully achieve this. For instance, in hop by – bounce check each ricochet evaluates bundles got from its past hop and reports botches when groups are seen to be polluted. While such a scattered establishment can absolutely pinpoint framework faults, sending and keeping up different watching centers in a broad scale framework presents significant computational overhead in social event framework estimations and incorporates puzzled legitimate organization. In particular, it is difficult to direct screen and get to all overlay hubs in a remotely supervised framework, whose guiding hubs are independently worked by various definitive territories. For this circumstance, we can simply derive the framework condition from end-to-end information.
II. END-TO-END INFERENCE APPROACH
As addressed in Fig.1 and 2, we consider a conclusion to-end deducing approach which, using to-end-to-to-end estimations, determines portions that are in all likelihood imperfect in sending data in an application-layer overlay mastermind whose overlay hubs are remotely directed via self-ruling administrative zones. We start with a guiding tree topology with a course of action of overlay hubs, since a tree-based setting is regularly found in goal based coordinating and where each overlay hub manufactures a coordinating tree with itself as a root, and furthermore in multicast directing, where a controlling tree is collected to join people in a multicast bundle. We at that point screen each root-to-leaf overlay way. If a way shows any "curious lead" in sending data, at that point some "broken" overlay hub in transit must be careful. Eventually, the correct importance of an "odd direct" depends on upon specific applications. For instance, a way is said to be sporadic if it fails to pass on different right bundles within a period window. Using the way information assembled at the application endpoints (i.e., leaf hubs), we can restricted down the space of possibly inadequate overlay hubs.
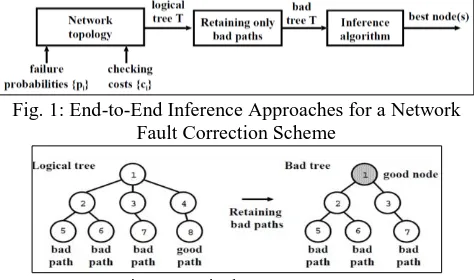
[image:1.595.310.547.618.758.2]Fig. 1: End-to-End Inference Approaches for a Network Fault Correction Scheme
In given a Logical Tree structure, we hold only the horrendous ways and demonstrate any awesome hub. Since way [1,4,8] is a respectable way, it is understood that hubs 1,4 and 8 are awesome. Hubs 4 and 8 can be pruned from the tree, and hub 1 can be appeared as extraordinary. The consequent game plan of horrendous ways will incite a terrible tree. In the above end-to-end course of action, one can tell whether a route carries on strangely, however can't especially tell which and what number of overlay hubs in transit are faulty. Since we can't clearly screen and get to remotely supervised overlay hubs, with a particular ultimate objective to correct the broken hubs, we need to contact the managers of the contrasting territories with physically check a course of action of possibly inadequate hubs and modify any hubs that are seen to be extremely imperfect. Given the unpredictable routes in a tree, our central target is to assemble the best hub (or the best plan of hubs) that should be at first checked with a specific end goal to limit the typical cost of correcting each damaged hub. In this paper, we develop a couple of optimality comes about for inferring the best hub that should be at first checked by a framework inadequacy correction design, with an objective to limit the ordinary cost of reexamining each and every inadequate hub.
III. EXISTING SYSTEM
Existing watching association concedes and faults in an organization provider or undertaking IP framework. Our two-organized procedure attempts to limit both the checking establishment costs and what's more the additional development due to test messages. In the main time of our procedure, we enroll the regions of a unimportant course of action of checking stations to such an extent that all framework associations are secured, even in the region of a couple of association frustrations. In this way, in the second stage, we figure an inconsequential course of action of test messages that are transmitted by the stations to measure association concedes and isolate framework issues. We show that both the station assurance issue and moreover the test undertaking issue is NP-hard. We at that point propose anxious gauge counts that achieve a logarithmic figure variable for the station assurance issue and an unfaltering component for the test assignment issue.
IV. PROPOSED SYSTEM
We propose a couple of capable heuristics for inciting the best hub to be checked in far reaching scale frameworks. By wide entertainment, we exhibit that we can assemble the best hub in no under 95% of time, and that initially checking the cheerful hubs rather than the no uncertainty broken hubs can reduce the checking cost of curing each imperfect hub. Subsequently, we have to devise a useful framework inadequacy change instrument that reviews all framework deficiencies at any rate cost. To examine (yet not repair) framework inadequacies, late procedures like use all framework hubs to helpfully achieve this. For example, in hop by-bob approval each bounce audits groups got from its past hop and reports botches when bundles are seen to be contaminated.
We are to a great degree fascinated to present the optimality comes about for a conclusion to-end acceptance approach to manage right (i.e., break down and repair) probabilistic framework blemishes in any event expected cost. One prodding use of using this conclusion to-end reasoning procedure is a remotely regulated overlay framework, where we can't direct get to and screen hubs that are self-governing worked by particular administrative spaces, yet rather we should infer disillusionments by methods for end to-end estimations. We exhibit that initially checking the hub that is no uncertainty imperfect nor has the scarcest checking cost does not inflexibly limit the typical cost of amending each and every broken hub.
V. METHODOLOGY
The basic focus of various current hub impersonation coordinating traditions is to enhance the likelihood of finding a path with to incredible degree compelled information. To discover such a way, a variety of instruments are used, including surveying hub meeting probabilities, package replication, framework coding, course of action of stationary waypoint stores, and using previous learning of flexibility cases. Heartbreakingly, the heaviness of finding even one way is awesome to the point that present procedures have only a circumstantial instead of a think affect on such coordinating estimations as most negative situation movement torpidity, ordinary deferral, or rate of packs passed on. This isolates between application needs and coordinating traditions disappoints sending of impersonation applications. At this moment, it is difficult to drive the indicating in order to coordinate layer of an impersonation needs, due dates, or cost necessities.
VI. FAULT DETECTION AND CORRECTION
A. Module Description
Execution is the period of the wander when the speculative layout is changed out into a working structure. In this way it can be believed to be the most essential stage in achieving a productive new system and in giving the customer, sureness that the new structure will work and be practical. The use organize incorporates attentive orchestrating, examination of the present structure and it's necessities on execution, arranging of procedures to achieve changeover and evaluation of changeover frameworks.
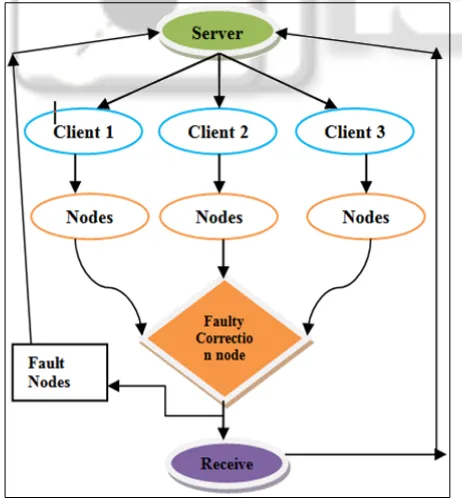
B. Managed Overlay Network
repairing deficient hubs in a remotely regulated overlay framework, in which overlay hubs are unreservedly worked by different definitive territories.
Fig. 3: Basic Structure of the Process
C. Transmitter Module
The transmitter sends a package to the beneficiary and sits tight for its attestation. Considering botch area comes to fruition; the beneficiary makes either a negative confirmation (NACK) or a positive certification (ACK) for each got distribute sends it over a feedback channel. If an ACK is gotten, the transmitter passes on a next package; by and large, if a NACK is gotten, retransmission of a similar package will be arranged rapidly, and this system continues until the point when the bundle is emphatically perceived.
D. Fault Node Diagnosis and Correction
[image:3.595.53.284.435.686.2]We consider a conclusion to-end technique of deducing probabilistic data sending dissatisfactions in a remotely supervised overlay framework, where overlay hubs are independently worked by various administrative zones. Our headway objective is to limit the typical cost of amending (i.e., diagnosing and repairing) all blemished overlay hubs that can't really pass on data. As opposed to first checking the surely softened hubs as up routine issue limitation issues, we exhibit that a perfect skill should start with checking one of the contender hubs, which are recognized considering a potential limit that we make.
Fig. 4: Data Flow Diagram of System Architecture to detect and correct the faulty nodes
We propose a few effective heuristics for inducing the best node to be checked in huge scale systems. By broad recreation, we demonstrate that we can gather the best node in no less than 95% of time, and that first checking the applicant nodes as opposed to the in all likelihood broken
nodes can diminish the checking expense of adjusting every single defective node.
E. Receiver Module
Each data divide the system is recognized by a novel entire number, implied as the hub number. The transmitter has a help, implied as the transmission line, to store package hub sitting tight for transmission or retransmission. The transmission line is relied upon to have a boundless supply of packages, insinuated as the staggering movement condition in relative investigations in hubs. In the transmitter sends packs to the gatherer constantly and gets attestations too. To shield the main arriving solicitation of packages at the recipient, the system has a pad, suggested as the hubs bolster, to store the precisely got groups that have not been released.
VII. ALGORITHMS USED FOR FAULT NODE DIAGNOSIS AND CORRECTION
We have used many ways of Algorithms to find faulty nodes and to correct them. The following algorithms are given below...
1) Inference algorithm
2) Brute-force inference algorithm
3) Breadth First Search Algorithm and Naive heuristics for the inference Algorithm
A. Inference Algorithm
Our inference algorithm to check, each node i is associated with a potential function.
Where
pi = failure probability of node i ci = checking cost of node i
Pr(T | Xi, Ai) = conditional probability of having a bad tree T = the event that the tree is a bad tree
Xi = the event that node i is bad
Ai = the event that ancestors of node i are good
We should first check the node with high pi and small ci, i.e., the node with the high potential first. For general cases, we don’t know which candidate node should be checked first to minimize the expected cost.
B. Naive Heuristics for the Inference Algorithm
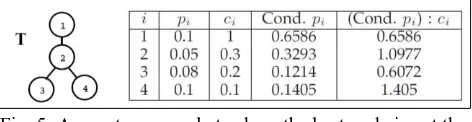
[image:4.595.50.286.294.355.2]Naturally, the best hub returned by the inference figuring could be either the hub that has the most imperative prohibitive disillusionment probability given an unpleasant tree T or the hub that has the base checking cost. Here, we show that these sincere choices don't as a make a difference obviously limit the ordinary cost of revising each and every broken hub. We first give an essential counter-example that invalidates the above honest choices. Figure 3 portrays an appalling tree built up at hub 1 and the looking at frustration probabilities {pi } and checking costs {ci}. As confirmed by the savage power approach in Algorithm 1, the best node is node 2, where a conceivable ideal conclusion succession is [2, 1, 3, 4] and has expected expense 1.044. Then again, node 2 is neither the node with the most elevated contingent disappointment likelihood, nor the node with the slightest checking expense, nor the node with the most noteworthy proportion of the restrictive disappointment likelihood to the checking expense.
Fig. 5: A counter-example to show the best node is not the one chosen by the naïve choices
As Fig.5 express to further understand the performance of the naïve choices, we evaluate three naive heuristics for the inference algorithm:
1) Naive-Prob, which gives back the node with the most astounding restrictive disappointment likelihood. 2) Naive-Cost, which gives back the node with the
slightest checking expense.
3) Naive-Prob-Cost, which gives back the node with the most astounding proportion of the contingent disappointment likelihood to the checking expense.
We balance their execution with that of the monster control deducing count in Algorithm 1 using a phenomenal little scale setting where a horrendous tree incorporates only two repulsive ways (e.g., see Figure 3). Such a setting is to depict a circumstance where most directing ways are disjoint and at most two ways have the same physical sections. In this way, to choose the best hub to first check, our deducing estimation should use a measure that better joins dissatisfaction probabilities, checking costs, and likewise the structure of the awful tree.
C. Heuristics for Inference Algorithm
While the animal power induction calculation (see Algorithm 1) gives back the best node, its factorial unpredictability denies its utilization in substantial scale systems. Subsequently, we propose three distinct gatherings of productive heuristics for the derivation calculation that are suitable for huge scale systems.
Every heuristic fits in with one of the two classes:
1) Naive heuristics, which consider just the undoubtedly defective nodes in view of the restrictive disappointment likelihood conveyance.
2) Candidate-based heuristics, which consider the applicant nodes taking into account both the contingent
disappointment likelihood and additionally the checking expense conveyances.
We additionally execute an applicant based heuristic for surmising various nodes termed Pa-Cand, which gives back the base measured subset Ipc of hopeful nodes that cover every awful way in a terrible tree. The calculation of discovering Ipc is appeared in Algorithm 3, whose multifaceted nature is Ө(|N|^3) because of the pursuit of candidate nodes.
VIII. CANDIDATE NODES
A. Evaluation of Candidate-Based Heuristics
Given the trouble of discovering the best node among an arrangement of applicant nodes, we assess the execution of three competitor based heuristics that estimated the best node choice of the surmising calculation. These heuristics are:
1) Cand-Prob, which chooses the applicant node with the most astounding restrictive disappointment likelihood given a terrible tree
2) Cand-Cost, which chooses the applicant node with the minimum checking expense
3) Cand-Pot, which chooses the hopeful node with the most astounding potential. Our assessment setting is the same as that in Section 4, i.e., we decide the extent of occurrences (out of 200) in which a competitor based heuristic chooses a best node for a given two-way awful tree of size |N| under distinctive disseminations of pi and ci.
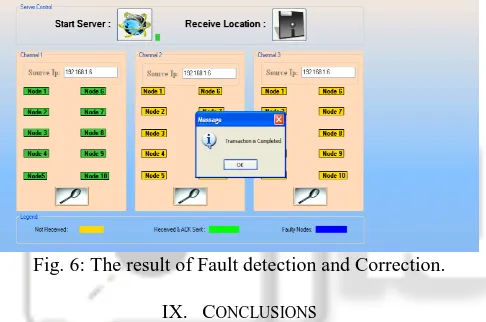
[image:5.595.47.290.313.474.2]Fig.6 shows that after analysis the faulty nodes and corrects them by using inference algorithm and sends the best nodes to the receiver side.
Fig. 6: The result of Fault detection and Correction.
IX. CONCLUSIONS
We show the optimality comes about for a conclusion to-end inducing approach to manage right (i.e., dissect and repair) probabilistic framework inadequacies at any rate expected cost. One stirring usage of using this conclusion to-end enlistment approach is a remotely supervised overlay framework, where we can't direct get to and screen hubs that are uninhibitedly worked by particular definitive territories, yet rather we should accumulate disillusionments by methods for end to-end estimations. We show that initially checking the hub that is without a doubt inadequate or has the base checking cost does not as per normal procedure limit the typical cost of redressing each imperfect hub. In context of this, we fabricate a potential limit with regards to perceiving the cheerful hubs, one of which should be at first checked by a perfect framework. As a result of the inconvenience of finding the best hub from the course of action of candidate hubs, we propose a couple of viable heuristics that are reasonable for changing issue hubs in immense scale overlay frameworks.
REFERENCES
[1] Varsha Peter1, Priya.M.2, Rajalakshmi.R.3, Muthu Bharathi.R.4, Pramila.E.5, Christo Ananth6, “Network Fault Correction in Overlay Network through
Optimality”, Mary IJARTET, Vol. 2, Issue 8, August 2015
[2] Patrick P. C. Lee, Vishal Misra, and Dan Rubenstein, “Toward Optimal Network Fault Correction in Externally Managed Overlay Networks”.
[3] Patrick P. C. Lee, Vishal Misra, and Dan Rubenstein “Toward Optimal Network Fault Correction via End-to- End Inference”.
[4] N.G. Duffield, J. Horowitz, F. Lo Presti, D. Towsley “Multicast Topology Inference from Measured End-to- End Loss”.
[5] Francesco Lo Presti, N. G. Duffield, Senior Member, Joe Horowitz, and Don Towsley, “Multicast-Based Inference of Network-Internal Delay Distributions”, IEEE, Fellow, IEEE.
[6] M. Adler, T. Bu, R. Sitaraman, and D. Towsley “Tree Layout for Internal Network Characterizations in Multicast Networks”. In Proc. of NGC’01, 2001. [7] D. Andersen. Mayday: “Distributed Filtering for
Internet Services”. In 4th Usenix Symposium on Internet Technologies and Systems, Mar 2003."
[8] D. Andersen, H. Balakrishnan, F. Kaashoek, and R. Morris. “Resilient Overlay Networks”. In Proc. of the 18th ACM Symposium on Operating Systems Principles (SOSP), Oct 2001.
[9] Avramopoulos, H. Kobayashi, R. Wang, and A. Krishnamurthy “Highly Secure and Efficient Routing”. In Proc. of IEEE INFOCOM, March 2004.
[10]R. C´aceres, N. Duffield, J. Horowitz, and D. Towsley. “Multicastbased Inference of Network-Internal Loss Characteristics”. IEEE Trans. on Information Theory, 45(7): 2462–2480, November 1999.
[11]D. Dagon, G. Gu, C. P. Lee, and W. Lee. A Taxonomy of Botnet Structures. In Proc. of NDSS, 2007.
[12]W. Du and A. Mathur “Testing for Software Vulnerability Using Environment Perturbation”. In Proc. of the International Conference on Dependable Systems and Networks, 2000.
[13]N. Duffield, J. Horowitz, F. L. Presti, and D.Towsley “Multicast Topology Inference from Measured End-to-End Loss”. IEEE Trans. on Information Theory, 48:26– 45, January 2002.