82
International Journal in IT & Engineering http://ijmr.net.in, Email: [email protected] DEVELOPING A HADOOP ARCHITECTURE FOR BETTER RESOURCEMANAGEMENT IN BIG DATA
Reghunath K1, Dr. Om Prakash2
Department of Computer Science
1,2
OPJS University, Churu (Rajasthan) – India
ABSTRACT
Hadoop is a complex disseminated data-processing condition, which contains several configuration parameters. Because of the complexity of configurations, configuring Hadoop group requires bunches of understanding as the administration execution is frequently influenced by mis-configuration (which is inclined to cause resource spills, in this way degrading framework execution). For the time-varying simultaneous outstanding tasks at hand, this issue turns out to be progressively genuine. Beyond the issue in Hadoop configurations, the elements of simultaneous outstanding tasks at hand likewise raise several difficulties to Hadoop group : I) the Hadoop static configurations ought to have the option to be dynamically tuned at run-time; I) the modifications on configuration ought to adjust the Hadoop bunch to the elements of remaining tasks at hand; I) the arrangement ought to have the option to recognize the exhibition degradations of a Hadoop group to keep away from pointless activities, which don't improve the presentation however in turn corrupt it. In this paper we therefore center around the dynamic configuration of Hadoop bunch to eliminate the resource spills brought about by mis-configuration, thereby providing the ideal Hadoop execution for simultaneous remaining burdens dependent on the present infrastructure.
1. INTRODUCTION
According to the ascent of business and development in Huge Data domain, many Cloud providers begin to help Hadoop-related administrations, for example, Amazon EMR, and so on. Indeed, even Open-Stack, an open-source venture which aims to accelerate and facilitate the development and the board of a private Cloud, has propelled a sub venture, named Sahara, to help end-users to effectively send and oversee Hadoop bunch atop of an Open-Stack Cloud. For this situation, the Hadoop execution additionally influences the QoS in Cloud computing. As a notable dispersed data-processing condition, Hadoop is generally utilized in different Enormous Data business to process specially appointed solicitation or simultaneous outstanding burdens. For the specially appointed solicitation, particularly the one processing an immense data set, users can set up a customized Hadoop group to expand the administration execution.
Blind Peer Reviewed Refereed Open Access International Journal
83
International Journal in IT & Engineeringhttp://ijmr.net.in, Email: [email protected] specially appointed requests, Hadoop group additionally processes simultaneous remaining burdens. Be that as it may, the elements of simultaneous outstanding tasks at hand frequently cause trouble for the exhibition of Hadoop bunch, especially for the situation of time-varying remaining tasks at hand. The dissemination of simultaneous occupations, even the progressions of employment sizes, are inclined to result in the resource holes of Hadoop group, because of its unchangeable configurations which cannot be adjusted to the elements at runtime, accordingly causing the degradation of administration execution. Furthermore, Hadoop bunch additionally receives an ace slave architecture, which enables the group administrators to effortlessly scale a Hadoop infrastructure (VMs in Cloud computing). This attracts heaps of attention from elasticity researches for Hadoop resource the executives to adjust a group according to the elements of simultaneous outstanding tasks at hand. My research therefore centers on the resource optimization of Hadoop group. As introduced over, the resource optimization in Hadoop bunch can be separated into two sections:
We therefore center on powerful MARP configuration. In the first place, we recognize the relationship between the MARP parameter and the presentation of assortment of Guide Lessen applications and remaining tasks at hand using set up benchmarks. Second, in light of the investigation, we actualize a self-configuration heuristics as a criticism control circle that continuously changes the MARP parameter at runtime. The evaluation demonstrates that the methodology systematically accomplishes preferable execution over static configuration approaches. Solidly, one can beat the default Hadoop configuration by up to 40% and up to 13% for the best-exertion statically profiled configurations, yet with no requirement for earlier information of the application or the remaining task at hand shape, or any requirement for any learning stage.
The main contributions of the research are:
1. An analysis of the effects of the MARP parameter on the Map Reduce job parallelism and
84
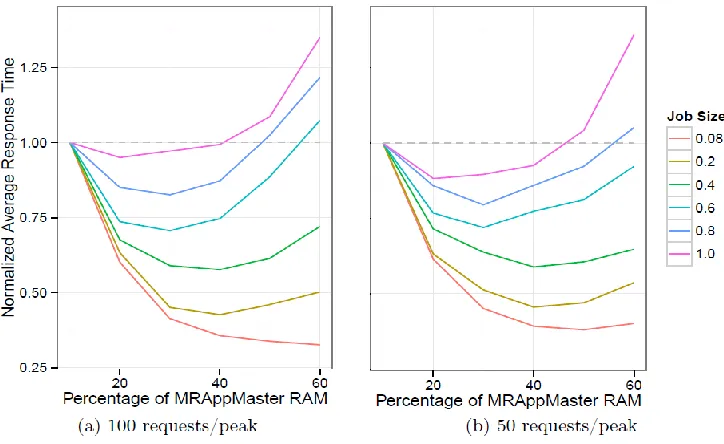
International Journal in IT & Engineering http://ijmr.net.in, Email: [email protected] Figure 1: Relationship between the job size, the percentage of RAM for MRApp Masters,and the average job response time
2. SYSTEM DESIGN
These preliminary experiments illustrate that the MARP configuration affects Hadoop execution. They demonstrate that the default esteem isn't ideal for practically all the considered cases. While one can profile the various applications to distinguish the best-exertion configuration we have appeared any unexpected change in the remaining task at hand elements can corrupt the general execution. To use the required ability, we therefore advocate for a self versatile methodology that continuously changes the MARP configuration dependent on the present state of the Hadoop bunch.
3. RESULTS & DISCUSSION
3.1 Memory Consumption of Hadoop
Blind Peer Reviewed Refereed Open Access International Journal
85
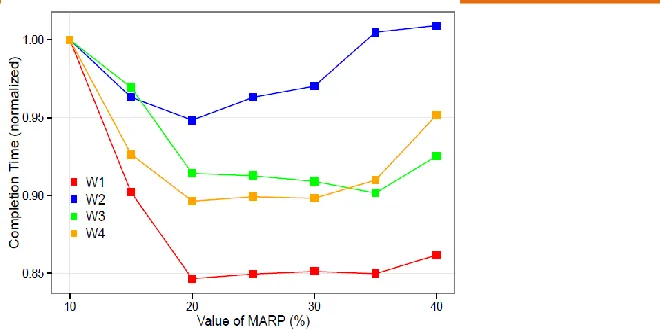
International Journal in IT & Engineeringhttp://ijmr.net.in, Email: [email protected] Figure 2: Effects of different MARP configurations and different SWIM generated
workloads on overall completion time
The memory consumption of this part is almost constant. The other three parts represents the memory held by Node Manager(s) as a result of processing Map Reduce jobs. MJobs contains two parts: MAM and MY C, they are all the memory occupied by Map Reduce jobs, but consumed by MRAppMaster and Yarn Child, respectively.
3.2 Loss of Jobs Throughput
The maximum number of concurrently running jobs, Nmax, in a Hadoop cluster is
(1)
Where Mcontainer is the Node Manager Container size (by default it is 1GB). The smaller the MARP value is, the smaller Nmax will be and the fewer jobs will be able to run in parallel.
In the case that the number of running jobs equals to Nmax, all available application master containers are exhausted and Resource Manager cannot schedule any more jobs into Hadoop cluster for processing. The new submitted jobs therefore become idle, and wait for the permissions in a queue. In this case, Equation (2) can be rewritten as follows:
86
International Journal in IT & Engineering http://ijmr.net.in, Email: [email protected] Where Midle will emerge with a low Nmax (i.e., low MARP value) When the number of running jobs reaches Nmax, MAM = M_AM and no more pending jobs can be run even though Hadoop cluster has Midle (i.e., M_ AM +MY C < M-compute).One can observe that the lower M_ AM + MY C is, the higher Midle is, indicating a memory / container waste that in turn degrades performance. One calls this situation the Loss of Jobs Parallelism (LoJP). Figure 5.6 illustrates such a situation. A Hadoop cluster with 8 containers has the MARP value set too low allowing only one job to be executed concurrently. Any pending jobs will have to wait until the current job has finished despite that there are unused containers. In this case, the waiting time of each pends job increases significantly.
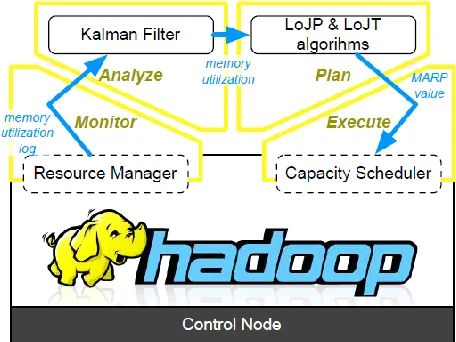
Figure 3: LOJP AND LOJT in Hadoop
3.3 Large Drops of Memory Utilization
Depending on the extent of the jobs and the memory utilized in Yarn Child containers, the dynamic allocation of resources can result in large drops of memory utilization. This is especially true when the tasks are rather fast to complete.
Blind Peer Reviewed Refereed Open Access International Journal
87
International Journal in IT & Engineeringhttp://ijmr.net.in, Email: [email protected] In this scenario, the sent Hadoop job consists of 20map and 1 reduce tasks conveyed in a cluster provisioned with 50GB of memory that we worry with a continuous progression of requests to guarantee that the quantity of running jobs is close to Nmax By increasing the MARP value like clockwork, one can pursue the impact of jobs parallelism on the memory utilization of the cluster. In particular, one can see in Figure 4 that the lower MARP value, the larger and increasingly visit memory drops—notwithstanding for large jobs, which are expected to profit by low MARP value. These memory drops are caused by the diverse lifecycle of containers, and basically appear at the finish of concurrently running jobs. At the point when a job comes as far as possible, all its corresponding MY C will be quickly released. Be that as it may, its MRApp-Master is as yet running to organize data, and to report results to users. A higher MARP value means all the more concurrently running jobs, which probably have increasingly unscheduled map or reduce tasks to avoid the memory drops, and vice versa.
4. EVALUATION IN HADOOP CLUSTER
In this section, we evaluate the capability of oneself balancing approach to address the issue Map Reduce job parallelism and throughput. We start with a quick outline of the implementation of oneself balancing algorithm pursued by a progression of experiments. The evaluation has been finished using a cluster of 11 physical hosts conveyed on the Grid5000 infrastructure, the same as we utilized.
4.1 Implementation Details
Figure 5 depicts the architecture of the feedback control loop that implements the balancing algorithm introduced in the previous section. It follows the classical
88
International Journal in IT & Engineering http://ijmr.net.in, Email: [email protected] MAPE (Monitor-Analyze-Plan-Execute) decomposition this approach has 4 steps:
Monitor, Analyze, Plan, and Execute. The Monitor step is in charge of reflecting the actual status of memory consumption across the entire Hadoop cluster. The memory information is collected using the Resource Manager services. Using Resource Manager Services is much superior to per-hub monitoring technique. Each Hub Manager regularly reports on the state of corresponding compute hub to Resource Manager by heartbeat (i.e., the framework message in Hadoop), such that Resource Manager can detect the total available resource in Hadoop cluster. Furthermore, each new container of applications ought to be directly launched (MRAppMaster) by, or negotiate (Yarn Child) with Resource Manager.
Resource Manager can record both of the latest memory usage of applications and the
total available resource in Hadoop cluster, hence logs the total memory utilization into the framework log document. To obtain the memory information of Hadoop cluster, the main cost is a reasonable delay (e.g., seconds). In contrary, per-hub monitoring technique requires per-hub sensor which may increase the weight of each compute hub. In addition, this strategy also will occupy the system bandwidth that in turn affects the Hadoop performance.
The Analyze step contains a Kalman channel. As uncovered in the Large Drops is a lot of
fluctuations of memory utilization, which are caused by the application self-managing mechanism introduced by YARN. These fluctuations are changeable, random, and fierce at times. They exasperate the balancing algorithms by misjudging the actual state of Hadoop cluster, thereby reducing the advantage of this approach, notwithstanding making self-balancing approach launch unnecessary adjustments and degrading Hadoop performance. In this case, a Kalman channel is introduced into this approach to smooth the fluctuations, accordingly guaranteeing the effect of self-balancing algorithms.
The self-balancing algorithms are the core of this approach, which are actualized in Plan
step. Based on the smoothed input from Kalman channel, the algorithms will make sense of the optimal MARP value, and require Execute step to revive the parameter in Hadoop cluster.
The Execute step is to update the MARP value and to reload it at run-time. The MARP
value is accessed via YARN configuration and changes to it are applied using YARN resource manager admin client.
The control loop was implemented in Java and runs on the control node alongside with
Blind Peer Reviewed Refereed Open Access International Journal
89
International Journal in IT & Engineeringhttp://ijmr.net.in, Email: [email protected] 5. CONCLUSION
In the Hadoop case, the other Cloud-users cannot re-allocate the provisioned resource regardless of the fact that the Hadoop Cluster becomes idle—i.e., the VMs of idle compute center points in Hadoop cluster cannot be reused by other pressing necessities. This therefore degrades the resource utilization of the Cloud, resulting in high Cloud cost which may affects the lease price of IaaS. Other than the performance enhancement for platform level, we also focus on the resource management in infrastructure and propose another center ware service (i.e., CloudGC) to upgrade the hardened mechanism of resource allocation in Cloud. Based on the experiments and analysis in an Open Stack Cloud, we can find that Cloud-GC is an interesting and feasible choice to avoid the resource leaks caused by resource allocation mechanism.
REFERENCES
[1]. V. R. Borkar, M. J. Carey, R. Grover, N. Onose, and R. Vernica. Hyracks: A flexible
and extensible foundation for data-intensive computing. In ICDE, pages 1151–1162, 2011.
[2]. Y. Bu, V. Borkar, G. Xu, and M. J. Carey. A bloat-aware design for big data
applications. In ISMM, pages 119–130, 2013.
[3]. J. Dolby and A. Chien. An automatic object inlining optimization and its evaluation. In
PLDI, pages 345–357, 2000.
[4]. T.H. Davenport, J.G. Harris, R. Morison, Analytics At Work: Smarter Decisions, Better
Results, Harvard Business Review Press, 2010
[5]. Albeshri A, Caelli W., ―Mutual Protection in a Cloud Computing Environment‖, Proc.
IEEE International Conference on High performance Computing and Communications, 641-646, 2010.
[6]. Chenguang Wang, Huaizhi Yan., ―Study of Cloud Computing security based on Private
Face Recognition‖, International Conf. on Computational Intelligence and Software Engineering, pp 1-5, 2010.
[7]. Jun-Ho Lee, Min-Woo Park., ―Multi level Intrusion Detection System and Log
management in Cloud Computing‖, Proc. Advanced Communication Technology, 13th International Conference, 552-555, 2011.
[8]. Lei Xu, Chunxiao Jiang, Jian Wang, Jian Yuan, Yong Ren, ―Information Security In