Approach forQuery Aware Strategy
forDetermining Uncertain Probabilistic Data
V.ChandraShekharRao
Associate Professor, Department of CSE
Kakatiya Institute Of Technology And Science, Warangal A.Mounika
M.Tech, Computer Science &Engineering
Kakatiya Institute Of Technology And Science,Warangal
ABSTRACT:In this paper the fundamental difficulty which is regarded is the determinization of probablisticdata which ready toallow such data which is to be stored in legacy techniques that accepts most effective the deterministic enter Probabilistic data is
generated with the aid of automatic data
evaluation/enrichment methods like entity resolution, expertise extraction, and speechprocessing. Legacy system which is used is similar to thepre-present internet purposes like Picasa, Flickr and many others. Ourintention and the very purposeis to generate a deterministicrepresentation of probablisticdata which optimizes the first-rateof the tip-utility developed on
determisnisticdata.This paper uses convergent
encryption process to furnish protection to sensitive data utilizing hybrid computing to authorize deduplication checks.
KEYWORDS-Determinization, data quality, query workload, uncertain data
I. INTRODUCTION
With the introduction of cloud computing and the fastincrease of the use of net-founded purposes, men and women mainlyshop their data in many more than a few existing net purposes.Traditionally, information of consumer is generated routinely by means of
aform of signal processing,query evaluation
/enrichmentapproaches before being stored within the quite a lot of webpurposes. For illustration cutting-edge DSLR cameras aidanalysis of vision with a view to generate tags equivalent toindoors/outdoor, quite a lot of scenery, panorama / portrait and many others.Many cutting-edge image cameras frequently have microphones forusers to speak out a descriptive
sentence which is thenrecognized with the aid of a speech recognizer to generate a collection of tags tobe related to the photograph [2]. The image (along with theset of tags) can be seen in actual-time making use of wirelessconnectivity to internet applications equivalent to Flickr. Putting suchdata into net purposes poses a challenge due to the fact that suchmechanically generated content is on the whole uncertain and may justeffect in objects with probabilistic attributes. For example,imaginative and prescient analysis may just outcomes in tags with chances [3], [4],and, in a similar fashion
computerized speech recognizer (ASR) may
justproduce an N-exceptional list or a confusion community of utterances[2], [3].This form of probabilistic query ought to be“determinized" before being saved in legacy webpurposes. We check with the crisis of mappingprobabilistic information into the equivalent deterministicrepresentation as the determinization difficulty. Many suchstrategies for the determinization crisis will also be made.
Two most important approaches are the top-1 and All approaches,the place we pick the most probabilistic value / all thepossible values of the attribute with the probability non-zero,respectively. For instance, a speech cognizance system thatgenerates a single
answer/tag for every expression can be
seenasutilising a prime-1 technique. Another method might be toopt for a threshold τ and include each and every attributevalues with a likelihood larger than τ . However, suchapproaches being doubted to the end-software by and large result insuboptimal outcome. A
better procedure is to design
determinizedillustration which optimizes the worth of theend-application. Don't forget, for example, an
finish app thatsupports triggers/indicators on
automated content new release.
Examples of such an finish-app
involvespublishing/subscribing method akin to
Google Alert, wherepersons put their subscriptions in the type of index key phrases(e.g.Gujarat earthquake) and predicts over a database (e.g.This knowledge is video). Google Alert finds all corresponding datasets to the user established on the subscriptions. Now for example avideo about Gujarat Earthquake is to be uploaded onYouTube. The video has a collection of tags that had been decided utilizingboth by way of routinely imaginative and prescient processing and/or viaexpertise retrieval approaches put over transcribed speech.
II. RELATED WORKS
[1]Partner abstract explanations/marks with sight and sound substance is among the most ideal approaches to manage sort out and to reinforce look over cutting edge images and intuitive media databases. Regardless of advances in sight and sound examination, intense marking stays, as it were, a manual strategy wherein customers incorporate expressive names by hand, as a rule when exchanging or skimming the social event, much after the photographs have been taken. This strategy, then again, is not useful in all conditions or for a few applications, e.g., when customers may need to
appropriate and confer pictures to others
dynamically. A substitute philosophy is to rather utilize a talk interface using which customers may demonstrate picture marks that can be deciphered
[2]cutting edge understanding getting ready
procedures, for instance, substance choice,
understanding cleansing, knowledgeextraction, and mechanized labelling almost always provide results comprising of items whose features may just include instability.This vulnerability is every once in a while caught as an arrangement of quite a lot of fundamentally unrelated qualityselections for every questionable characteristic alongside a measure of possibility for option values.
[4]inside of the atmosphere of a sent talked dialog advantage, This be trained introduces yet another
elucidation approach taking intoaccount the
specific forms of questions including SPJ inquiries, top-ok positioning questions, bunch by means ofwhole questions, and grouping. For diverse separation measurements, we acquire polynomial time ideal or estimatecalculations for processing the contract replies (or show NP-hardness). The bigger part of our results arefor a common probabilistic database model, known as and/XOR tree model, which vastly sums up past probabilisticdatabase units like x-tuples and piece free disjoint models.
III. THE PROPOSED APPROACHES
In the proposed system a hybrid cloud, a combination of both the private cloud and public cloud is implemented. Public cloud security cannot be processed as all the files can be access publicly which results in the loss of private data. Security of both private and public clouds systems are implemented to avoid deduplication of the files are increased. Duplicate copies of the files are avoided and users can only upload and download files from the public clouds. Only authorized users who have access to the private could can access the private cloud which makes the system secure and tokens are generated for each file to avoid deduplication which is specified before.
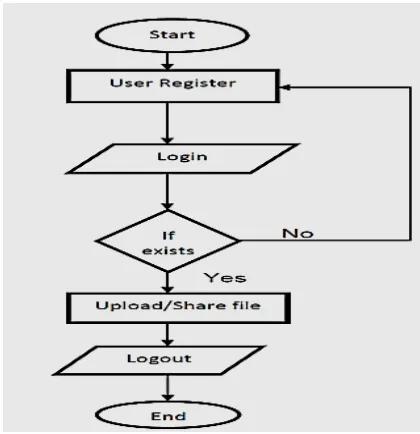
•File uploading: Flow chart for file uploading process is shown in Figure 1. When user upload the file to the public cloud the user first encrypt the file which is to be upload by the symmetric key and then send it to the public cloud and at the same time the user generates the key for the file and send it to the private cloud for uploading the file.
Figure 1. Flow Chart for File uploading
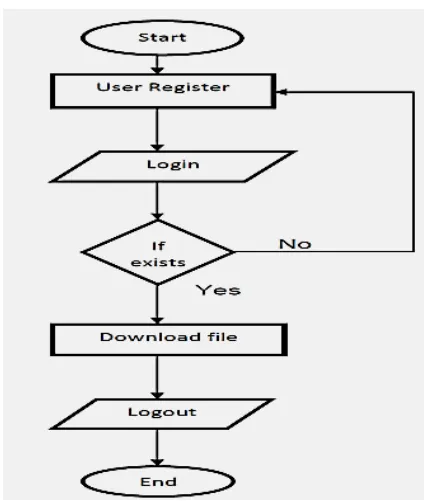
Figure 2. Flow Chart for File Downloading
The implementation of the system depends upon three main entities. They are client program, private server program and the storage server program. The client server program manages the upload and download of the files by the user. The private cloud server program manages the private key and token computations. The storage server program maintains the S – CSP which stores and deduplicates files. The function calls that are used in the program are as follows.
• FileTag (File) - It computes SHA-1 hash of the File as File Tag.
• TokenReq (Tag, UserID) - It request the private server for File Token generation.
• FileUploadReq (FileID, File, Token) - File is uploaded to the Storage Server if the file is Unique and updates the File Token stored.
• TokenGen (Tag, UserID) - It loads the associated privilege keys of the user and generate the token with HMAC-SHA-1 algorithm.
• ShareTokenGen (Tag, {Priv.}) - Share token is generated with the corresponding privilege keys of sharing the privilege set with HMAC-SHA-1 algorithm.
• DupCheck (Token) - It searches the file to token map for duplicate.
• FileStore (FileID, File, Token) - It stores the File on Disk and updates the Mapping.
IV. CONCLUSION
Hereafter, from this paper we have deliberated problem ofdeteminizing uncertain objects in order to organize and storesuch data in already existing
systems example Flickr whichonly accepts
deterministic value. Our aim is to yield adeterministic depiction that optimizes the quality of answersto queries/triggers that execute over the deterministic datarepresentation .Security analysis demonstrates the schemes are secure in terms of both insider and outsider attacks specified in the proposed model.
REFERENCES
[1] D. V. Kalashnikov, S. Mehrotra, J. Xu, and N. Venkatasubramanian, “A semantics-based approach
for speech annotation of images,” IEEE
[4] B. Minescu, G. Damnati, F. Bechet, and R. de Mori, “Conditional use of word lattices, confusion networks and 1-best string hypotheses in asequential interpretation strategy,” in Proc. ICASSP, 2007.
[5] J. Li and A. Deshpande, “Consensus answers for queries over probabilistic databases,” in Proc. 28th
ACM SIGMOD-SIGACTSIGART Symp.PODS,
New York, NY, USA, 2009.
[6] D. V. Kalashnikov and S. Mehrotra, “Domain-independent data cleaning via analysis of entity-relationship graph,” ACM Trans. Database Syst.,vol. 31, no. 2, pp. 716–767, Jun. 2006.
[7] C. Wangand, F. Jing, L. Zhang, and H. Zhang, “Image annotation refinement using random walk with restarts,” in Proc. 14th Annu. ACM Int.Conf. Multimedia, New York, NY, USA, 2006.
[8] M. W. Storer, K. Greenan, D. D. E. Long, and E. L. Miller, “Secure data deduplication”, in proc. of Storage SS, 2008.
[9] Z. Wilcox-O’Hearn and B. Warner, “Tahoe: the least-authority file system”, in proc. of ACM Storage SS, 2008.
[10] J. R. Douceur, A. Adya, W. J. Bolosky, D. Simon, and M. Theimer. Reclaiming space from duplicate files in a server less distributed file system. In ICDCS, pages 617–624, 2002.
Authors:
V.ChandraShekharRao working as Associate
Professor, Department of CSE in Kakatiya Institute Of Technology And Science, Warangal
A.Mounika pursing M.Tech in Computer Science
Engineering from Kakatiya Institute Of