Available Online atwww.ijcsmc.com
International Journal of Computer Science and Mobile Computing
A Monthly Journal of Computer Science and Information Technology
ISSN 2320–088X
IMPACT FACTOR: 6.017
IJCSMC, Vol. 6, Issue. 4, April 2017, pg.407 – 412
AN INVESTIGATION OF CLOUD
COMPUTING IN BIG DATA ANALYTICS
SASIKALA.M
Assistant Professor & Head, Department of Computer Science, KG College of Arts and Science, Coimbatore
ABSTRACT - This paper describes however cloud huge and large and massive information technologies square measure connection to supply a cheap delivery model for cloud-based big information analytics. Cloud computing may be a powerful technology to perform massive-scale and complicated computing. It eliminates the requirement to keep up pricy computing hardware, dedicated area, and software package. Large growth within the scale of information of knowledge of information or massive data generated through cloud computing has been ascertained. Addressing massive information may be a difficult and time exacting task that needs an oversized procedure infrastructure to make sure undefeated processing and analysis. During this paper the link between massive information and cloud computing, the classification of huge information and also the scope of huge information analytics square measure mentioned.
Index Terms -Big information, Cloud Computing, Infrastructure as a Service (IaaS), web of Things (IoT), Platform as a Service (PaaS), and software package as a Service (SaaS)
1. INTRODUCTION
The continuous increase within the volume and detail of knowledge captured by organizations, like the increase of social media, web of Things (IoT), and multimedia system, has made an amazing flow of knowledge in either structured or unstructured format. Information creation is happening at a record rate [1], said herein as massive information, and has emerged as a widely known trend. Massive information is eliciting attention from the academe, government, and business. Massive information square measure characterized by 3 aspects: (a) information square measure various, (b) information cannot be classified into regular relative databases, and (c) information square measure generated, captured, and processed apace. Moreover, massive information is reworking aid, science, engineering, finance, business, and eventually, the society.
Cloud computing is one in all the foremost vital shifts in fashionable ICT and repair for enterprise
benefits of cloud computing embody virtualized resources, data processing, security, and information service integration with ascendible information storage. Cloud computing can't solely minimize value|the value|the price and restriction for automation and cybernation by people and enterprises
however also can offer reduced infrastructure maintenance cost, economical management, and user
access [2]. As a results of the aforementioned benefits, variety of applications that leverage varied cloud
platforms are developed and resulted in an exceedingly tremendous increase within the scale of
knowledge generated and consumed by such applications.
2. WHAT'S MASSIVE DATA?
Recently, the term of big data has been coined relating thosechallenges and edges derived from assortment and method giant amounts of information. The sources of large quantity of data of information of information of knowledge unit of measurement those applications that gather data from click streams, human action histories, sensors, etc., However, the first downside for the correct definition of ‘Big Data’ is that the name itself, as we'd suppose that it's merely related to the information volume. The heterogeneous structure, varied spatial property, and sort of the information illustration, even have significance inside the large data.
2.1. Classification of Big Data
Big knowledge ar classified into totally different classes to higher perceive their characteristics. Fig. 1.1. shows the many classes of huge knowledge. The classification is very important as a result of large-scale knowledge within the cloud. The classification relies on 5 aspects: (i) knowledge sources, (ii) content format,
(iii) knowledge stores, (iv) knowledge staging, and (v) processing. Figure 1.1: - Classification of Big Data
3. CLOUD COMPUTING
services. The requirement to store, process, and analyze giant amounts of datasets has driven several organizations and people to adopt cloud computing [4]. an oversized range of scientific applications for in depth experiments are presently deployed within the cloud and should still increase thanks to the dearth of accessible computing facilities in native servers, reduced capital prices, and increasing volume of information made and consumed by the experiments [5]. Additionally, cloud service suppliers have begun to integrate frameworks for parallel processing in their services to assist user’s access cloud resources and deploy their programs [6].
3.1. Cloud Computing Service Models
Common models for cloud computing include platform as a service (PaaS), software as a service (SaaS), infrastructure as a service (IaaS), and hardware as a service (HaaS). Cloud deployment solutions can provide services that businesses would otherwise not be able to afford. Businesses can also use cloud deployment solutions as a test measure before adopting a new application or technology company-wide.
There are a number of alternatives for businesses using the cloud for PaaS. Platform as a Service is the use of cloud computing to provide platforms for the development and use of custom applications.
The PaaS include application design and development tools, application testing, versioning, integration, deployment, and hosting, state management, and other related development tools .
Businesses attain cost savings using PaaS through standardization and high utilization of the cloud-based platform across a number of application. Other advantages of using PaaS include lowering risks by using pretested technologies, promoting shared services, improving software security, and lowering skill requirements needed for new systems development.
As related to big data, PaaS provides companies a platform for developing and using custom applications needed to analyze large quantities of unstructured data at a low cost and low risk in a secure environment. Software as a service which provides businesses with applications that are stored and run on virtual servers in the cloud. The business is not charged for hardware, only for the bandwidth for the time and number of users necessary. The main advantage of SaaS is that the solution allows businesses to shift the risks associated with software acquisition while moving IT from being reactive to proactive. Benefits of using SaaS are easier software administration, automatic updates and patch management, software compatibility across the business, easier collaboration, and global accessibility Software as a Service provides companies analyzing big data proven software solutions for data analysis. The difference between SaaS and PaaS. In this case is that SaaS is not going to provide a customized solution whereas PaaS will allow the company to develop a solution tailored to the company’s needs.
In the IaaS model, the client business will pay on a per-use basis for use of equipment to support computing operations including storage, hardware, servers, and networking equipment. Infrastructure as a service is the cloud computing model receiving the most attention from the market, with an expectation of 25% of enterprises planning to adopt a service provider for IaaS. Services available to businesses through the IaaS model include disaster recovery, compute as a service, storage as a service, data center as a service, virtual desktop infrastructure and cloud bursting which is providing peak load capacity for variable processes.
Benefits of IaaS which include increased financial flexibility, choice of services, business agility, cost- Effective scalability and increased security. While not as yet being used as extensively as PaaS, SaaS, or IaaS, HaaS is a cloud service based upon the model of time sharing on minicomputers and mainframes from the 1960s and 1970s.
contracted. The problem with managed services was the necessity for some MSPs to provide hardware on-site for clients, the cost of which needed to be built into the MSP’s cost. The HaaS model allows the customer to license the hardware directly from the service provider which alleviates the associated cost.
Vendors in the HaaS arena include Google with its Chromebooks for Business, CharTec, and Equus.
4. RELATIONSHIP BETWEEN CLOUD COMPUTING AND LARGE INFORMATION
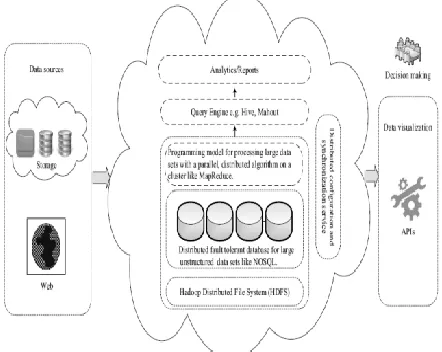
Cloud computing and large information area unit joint. Huge information provides users the power to use artefact computing to method distributed queries across multiple datasets and come resultant sets in an exceedingly timely manner. Cloud computing provides the underlying engine through the utilization of Hadoop, a category of distributed data-processing platforms. The utilization of cloud computing in huge information is shown in Fig. 3. giant information sources from the cloud and net area unit hold on in an exceedingly distributed fault-tolerant info and processed through a programming model for giant datasets with a parallel distributed formula in an exceedingly cluster [7]. The most purpose of information mental image, as shown in Figure four.1, is to look at analytical results given visually through completely different graphs for higher cognitive process.
Figure 4.1: - Cloud computing usage in big data
Big information utilizes distributed storage technology supported cloud computing instead of native storage hooked up to a pc or device. Massive information analysis is driven by aggressive cloud-based applications developed mistreatment virtualized technologies. Therefore, cloud computing not solely provides facilities for the computation and process of huge information however conjointly is a service model.
4.1. Cloud Computing Environments for Big Data
Figure 4.2: - Illustration of the layers for the Service-Oriented Architecture
A file system for the storage of Big Data, i.e., a wide amount of archives of large size. This layer is implemented within the IaaS level as it defines the basic architecture organization for the remaining tiers.
An execution tool to distribute the computational load among the computers of the cloud. This layer is
clearly related with PaaS. A query system for the knowledge and information extraction required by the system’s users, which is in between the PaaS and SaaS layers.
5. THE SCOPE OF BIG DATA ANALYTICS
Early interest in huge information analytics centered totally on business and social information sources, like e-mail, videos, tweets, Facebook posts, reviews, and net behavior. The scope of interest in huge information analytics is growing to incorporate information from intelligent systems, like in-vehicle motion picture, kiosks, sensible meters, and plenty of others, and device sensors at the sting of networks, some of the largest-volume, fastest-streaming, and most complicated huge information. Present property and therefore the growth of sensors and intelligent systems have spread out a full new repository of valuable data. Interest in applying huge information analytics to information from sensors and intelligent systems continues to extend as businesses look for to achieve quicker, richer insight additional cost-effectively than within the past, enhance machine based decision making, and personalize customer experiences.
6. CONCLUSION
The size of knowledge at the moment is big and continues to extend each day. The range of knowledge being generated is additionally increasing. the speed of knowledge generation and growth is increasing attributable to the proliferation of mobile devices and different device sensors connected to the net. These information offer opportunities that permit businesses across all industries to realize period of time business insights. The employment of cloud services to store, process, and analyze information has been offered for a few time; it's modified the context of knowledge technology and has turned the guarantees of the on-demand service model into reality. During this study, we tend to bestowed a review on the increase of huge information in cloud computing. We tend to projected a classification for large information, a abstract read of huge information, and a cloud services model. Within the future, vital challenges and problems should be self-addressed by the academe and trade. Researchers, practitioners, and science students ought to collaborate to confirm the long success of knowledge management in an exceedingly cloud computing surroundings and to jointly explore new territories.
REFERENCES
[1] R.L .Villars, C.W. Olofson, M. Eastwood, Big data: what it is and why you should care, White Paper,
IDC, 2011, MA, USA.
[2] L.Chih-Wei, H.Chih-Ming, C.Chih-Hung, Y.Chao-Tung, ―An Improvement to Data Service in Cloud
Computing with Content Sensitive Transaction Analysis and Adaptation, Computer Software and Applications Conference orkshops(COMPSACW),2013IEEE 37th Annual, 2013,pp.463–468.
[3] M.Armbrust, A.Fox, R.Griffith, A.D.Joseph, R.Katz, A.Konwinski, G. Lee, D.Patterson, A.Rabkin,
I.Stoica, M.Zaharia, A view of cloud computing, Commun.ACM53 (2010)50–58.
[4] L. Huan,Bigdata drives cloud adoption in enterprise, IEEE Internet Comput. 17(2013)6871.
[5] S.Pandey, S.Nepal, Cloud computing and scientific applications — big data, Scalable Anal.Beyond,
Futur.Gener.Comput.Syst.29 (2013)1774–1776.
[6] D.Warneke, O.Kao, Nephele: efficient parallel data processing in the cloud, in: Proceedings of the 2nd
workshop on many-task computing on grids and super computers, ACM, 2009,p.8.
[7] Marx V. The big challenges of big data. Nature 2013, 498:255–260
[8] Creeger M. Cloud computing: an overview. ACMQueue 2009, 7:2.
[9] Vaquero LM, Rodero-Merino L, Caceres J, Lindner.M. A break in the clouds: towards a cloud definition
SIGCOMM Comput Commun Rev 2008, 39:50–55.