International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
787
Effective Information Retrieval System
Vidya Maurya
1, Preeti Pandey
2, L.S. Maurya
31Student, 2Assistant Professor, 3Associate Professor, CS/IT Deptt. & SRMSWCET Bareilly, India
Abstract--This paper provides some perspective on the effectiveness of information retrieval that had its beginnings long before the creation of the Internet and provides some enlightened predictions on possible future directions of the field. The field of Information Retrieval (IR) was born in the 1950s out of this necessity. Over the last forty years, the field has matured considerably. This paper presents an outline of ‘Effective Information Retrieval Systems’ seeking and searching, other aspects of information conflicting, showing the relationship between communication and information extraction in general with information seeking and information searching in information retrieval systems. It is also suggested that, within both information seeking research and information searching research, alternative information eliciting address similar issues in related ways and that the systems are complementary rather than conflicting. Finally, an alternative, problem-solving issues is presented, which, it is suggested, provides a basis for relating the design issues in appropriate research strategies. As we have learned how to handle text, through to the early adoption of computers to search for items that are relevant to a user’s query. The advances achieved by information retrieval researchers from the 1950s through to the present day are detailed next, focusing on the process of locating relevant information. This paper closes with speculation on where the future of information retrieval lies.
Keywords-- Enlightened predictions, Information conflicting, information elicitation, process of locating, speculation.
I. INTRODUCTION
For thousands of years people have realized the importance of archiving and finding information. With the advent of computers, it became possible to store large amounts of information; and finding useful information from such collections became a necessity. The field of Information Retrieval (IR) was born in the 1950s out of this necessity [7]. Information is an art and science, and the term system is an organized relationship among function in units or components. Now then information system is the science of locating, from a large documents collection, those documents that fulfill a specified information. Information Retrieval (IR) is finding material of an unstructured nature that satisfied a information need form within large collections. Actually, what is Information Retrieval? An information retrieval process begins when a user enters a query into the system, query are formal statements of information needs. In information retrieval a query does not uniquely identify a single object in the collection. Instead several objects may match the query, perhaps with different degrees of relevancy.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
788
If the user wishes to refine the query. Language and text and their impact on IR are considered first, then examination of the interaction of users, their environment, and relevance. After everything is presented, a conclusion follows.
II. MOTIVATION
Information retrieval (IR) deals with the representation, storage, organization of data and access to information items. The representation and organization of the information items should provide the user with easy access to the information in which he is interested. Unfortunately, characterization of the user information need is not a simple problem. Consider, for instance, the following hypothetical user information need in the context of the World Wide Web (or just the Web) Clearly, this full description of the user information need cannot be used directly to request information using the current interfaces of Web search engines. Instead, the user must first translate this information need into a query which can be processed by the search engine (or IR system). In its most common form, this translation yields a set of keywords (or index terms) which summarizes the description of the user information need.
III. STOPWORDS
In computing, stop words are words which are filtered out prior to, or after, processing of natural language data (text). There is not one definite list of stopwords which all tools use [5], if even used, some tools specifically avoid removing them to support phrase search. Hans Peter Luhn, one of the pioneers in IR, iscredited with coining the phrase and using the concept in his design. Most search engine do not consider extremely common words in order to save disk space or to speed up search results. These filtered words are known as „stopwords‟.
Elimination of stopwords
Reduce indexing size and processing time. Useless for retrieval.
Occur in 80% documents.
Configure and manage stop words and stop list for full text search--- To prevent a full text-index from becoming bloated, SQL server has a mechanism that discards commonly occurring strings that do not help the search. These discarded strings that do not help the search. These discarded strings are called, stopwords. During index creation, the full text engine omits stopwords. from the full- text index. This means that full- text queries will not search on stopwords. Stopwords are words that, if indexed could potentially return every document in the database if the word was used in a search state space.
IV. STEMMING
In linguistic morphology and information retrieval, stemming is the process for reducing inflected words to their stem, base or root from-generally a written word form. Many search engines treats word with the same stem as synonyms as a kind of query boardenning, a process called conflation. Stemming is used to determine domain vocabularies in domain analysis. I t possible to evaluate stemming by counting the numbers of two kinds of error that occur during stemming, namely: Under Stemming & Over Stemming.
• Under Stemming
This refers to the words that should be grouped together by stemming, but aren‟t. This cause a single concepts to be spread over various different systems, which will tend to decrease the recall in an IR search.
• Over Stemming
[image:2.595.308.555.423.587.2]This refers to the words that shouldn‟t be grouped together by stemming , but are. This cause the meaning of the system to be diluted, which will effects precision of IR.
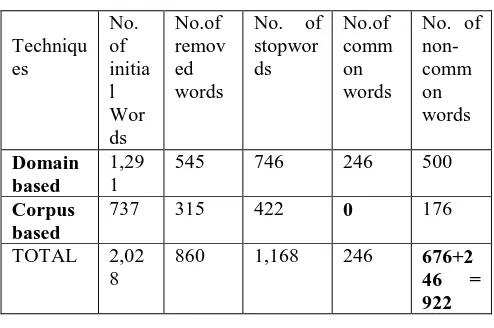
Table 1.
Improve Retrieval Performance
Techniqu es
No. of initia l Wor ds
No.of remov ed words
No. of stopwor ds
No.of comm on words
No. of non- comm on words
Domain based
1,29 1
545 746 246 500
Corpus based
737 315 422 0 176
TOTAL 2,02 8
860 1,168 246 676+2 46 = 922
1. Some Stemming Algorithm
• Porter Stemming Algorithm:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
789
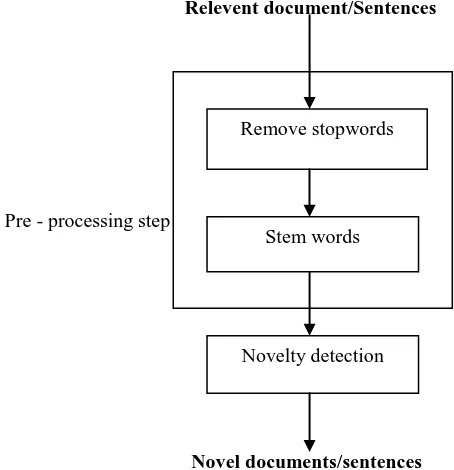
Specifically it has five steps applying rules within each step. Within each step, if a suffix rule matched to a word, then the conditions attached to that rule are tested on what would be the resulting stem, if that The suffix was removed, in the way defined by the rule. For example such a condition may be, the number of vowel characters, which are followed be a consonant character in the stem (Measure), must be greater than one for the rule to be applied. The Porter Stemmer is a very widely used and available Stemmer, and is used in many applications. Implementations of this Stemmer are available at a website by Porter himself, with implementations in Java, C and PERL; the website also includes a copy of the paper defining the Algorithm. Other implementations of this algorithm are available from the Web. Porter's algorithm is probably the stemmer most widely used in IR research. Once a Rule passes its conditions and is accepted the rule fires and the suffix is removed and control moves to the next step. If the rule is not accepted then the next rule in the step is tested, until either a rule from that step fires and control passes to the next step or there are no more rules in that step whence control moves to the next step. This process continues for all steps, the resultant stem being returned by the Stemmer after control has been passed from steps, See figure1.
Relevent document/Sentences
Pre - processing step
[image:3.595.51.278.430.665.2]Novel documents/sentences
Figure 1. Stemming process
2. Lovins Stemming Algorithm:
The Lovins Stemmer is a single pass, context-sensitive, longest-match Stemmer developed by Julie Beth Lovins of Massachusetts Institute of Technology in 1968. This early stemmer was targeted at both the IR and Computational Linguistics areas of stemming.
The Lovins Stemmer removes a maximum of one suffix from a word, due to its nature as single pass algorithm. It uses a list of about 250 different suffixes, and removes the longest suffix attached to the word, ensuring that the stem after the suffix has been removed is always at least 3 characters long. Then the ending of the stem may be reformed (e.g., by un-doubling a final consonant if applicable), by referring to a list of recoding transformations. J.B. Lovins, 1968: "Development of a stemming algorithm," Mechanical Translation and Computational Linguistics. This stemmer, though innovative for its time, has the problematic task of trying to please two masters (IR and Linguistics) and cannot excel at either. The approach does not excel with linguistics, as it is not complex enough to stem many suffixes due to their not being present in the rule list. This is interesting as Lovins‟ rule list was derived by, processing and studying a word sample. Perhaps if this process was repeated with a much larger sample a more satisfactory rule list could be derived. There are also known to be problems regarding the reformation of words. This process uses the recoding rules to reform the stems into words to ensure they match stems of other similar meaning words. The main problem with this process is that it has been found to be highly unreliable and frequently fails to form words from the stems, or match the stems of like meaning words. The Stemmer does not excel from the IR viewpoint either, as its large rule set, and its recoding stage, affect its speed of execution.
3. Dawson’s Stemming Algorithm
The Dawson Stemmer was developed by J.L. Dawson of the Literary and Linguistics Computing Centre at Cambridge University. It is a complex linguistically targeted Stemmer that is strongly based upon the Lovins Stemmer, extending the suffix rule list to approximately 1200 suffixes. It keeps the longest match and single pass nature of Lovins, and replaces the recoding rules, which were found to be unreliable, using instead an extension of the partial matching procedure also defined within the Lovins Paper. J.L. Dawson, 1974: "Suffix removal for word conflation," Bulletin of the Association for Literary & Linguistic Computing The main objective of the stemming process is to remove all possible affixes and thus reduce the word to its stem (Dawson 1974). Using Stemming, many contemporary search engines associate words with prefixes and suffixes to their word stem, to make the search broader in the meaning that it can ensure that the greatest number of relevant matches is included in search results. Stemming has also applications in machine translation, document summarization (Orasan, Pekar & Hasler 2004, Dalianis 2000), and text classification (Gaustad & Bouma 2002).
Remove stopwords
Stem words
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
790
Conflation Method
Figure 2. Suffixe removal
V. INDEXING WEB DOCUMENTS
IR systems include two types of terms: objective and nonobjective. Objective terms are extrinsic to semantic content, and there is generally no disagreement about how to assign them. Examples include author name, document URL, and date of publication. Nonobjective terms, on the other hand, are intended to reflect the information manifested in the document, and there is no agreement about the choice or degree of applicability of these terms. Thus, they are also known as content terms. Indexing in general is concerned with assigning nonobjective terms to documents. The assignment may optionally include a weight indicating the extent to which the term represents or reflects the information content. The effectiveness of an indexing system is controlled by two main parameters. Indexing exhaustivity reflects the degree to which all the subject matter manifested in a document is actually recognized by the indexing system. When the indexing system is exhaustive, it generates a large number of terms to reflect all aspects of the subject matter present in the document; when it is non exhaustive, it generates fewer terms, corresponding to the major subjects in the document. Term specificity refers to the breadth of the terms used for indexing. 2 Broad terms retrieve many useful documents along with a significant number of irrelevant ones; narrow terms retrieve fewer documents and may miss some relevant items. The effect of indexing exhaustivity and term specificity on retrieval effectiveness can be explained by two parameters used for many years in IR problem.
Multi-term or phrase indexing: Single terms are less than ideal for an indexing scheme because their meanings out of context are often ambiguous. Term phrases, on the other hand, carry more specific meaning and thus have more discriminating power. Phrase generation is intended to improve precision; thesaurus-group generation is expected to improve recall.
A thesaurus assembles groups of related specific terms under more general, higher level class indicators. Methods for generating complex index terms or term phrases automatically may be categorized as statistical, probabilistic or linguistics.
VI. EVALUATION
Objective evaluation of search effectiveness has been a cornerstone of IR [4]. Progress in the field critically depends upon experimenting with new ideas and evaluating the effects of these ideas, especially given the experimental nature of the field. Since the early years, it was evident to researchers in the community that objective evaluation of search techniques would play a key role in the field. The Cranfield tests, conducted in 1960s, established the desired set of characteristics for a retrieval system [1]. Even though there has been some debate over the years, the two desired properties that have been accepted by the research community for measurement of search effectiveness are recall: the proportion of relevant documents retrieved by the system; and precision: the proportion of retrieved documents that are relevant.
VII. RETRIEVAL EFFECTIVENESS ASSESSMENT
The formal precision and recall measures used to quantify retrieval effectiveness of IR systems are based on evaluation experiments conducted under controlled conditions [10]. This requires a test bed comprising a fixed number of documents, a standard set of queries, and relevant and irrelevant documents in the test bed for each query. Realizing such experimental conditions in the Web context is extremely difficult. Search engines operate on different indexes, and the indexes differ in their coverage of Web documents. We must therefore compare retrieval effectiveness in terms of qualitative statements and the number of documents retrieved. We evaluated various search tools and services using two queries: “latex software” and “multi agent system architecture.” The first query was intended to find both public-domain sources and commercial vendors for obtaining LaTex software, whereas the second query was intended to locate relevant research publications on multi agent system architecture. Table 1 presents results for the first query. The second column indicates the number of documents retrieved by interpreting the query as a disjunction of the query terms.
VIII. IMPROVING RETRIEVAL EFFECTIVENESS
The design and development of current-generation Web search tools have focused on query-processing speed and database size.
Manual Automatic
Affix removal Successor
variety Table
lookup
n-gram
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
791
This is largely a response to the lack of features in the original Hyper Text Markup Language for representing document content to search tools5,6 (not surprising, given HTML‟s original purpose: to render documents on a wide array of output devices without concern for the computer to which the device was connected). HTML Version 3 introduced the META tag, which allows authors to specify indexing information. We expect this trend to continue, establishing standardized tags for Web document content. Meanwhile, as we have seen, the query representation. The first, modification of term weights, involves adjusting the query term weights by adding document vectors in the positive feedback set to the query vector. Optionally, negative feedback can be used to subtract document vectors in the negative feedback set from the query vector. The reformulated query should retrieve additional relevant documents similar to the documents in the positive feedback set. This process can be carried out iteratively until the user is satisfied with the quality and number of relevant documents in the query output.
IX. TECHNIQUES FOR IMPROVING IR EFFECTIVENESS
Interaction with user (relevance feedback) - Keywords only cover part of the contents - User can help by indicating relevant/irrelevant document
The use of relevance feedback To improve query expression:
Qnew = *Qold + *Rel_d - *Nrel_d
where Rel_d = centroid of relevant documents NRel_d = centroid of non-relevant documents
Data retrieval, in the context of an IR system, consists mainly of determining which documents of a collection contain the keywords in the user query which, most frequently, is not enough to satisfy the user information need. In fact, the user of an IR system is concerned more with retrieving information about a subject than with retrieving data which satisfies a given query. A data retrieval language aims at retrieving all objects which satisfy clearly defined conditions such as those in a regular expression or in a relational algebra expression. Thus, for a data retrieval system, a single erroneous object among a thousand retrieved objects means total failure. For an information retrieval system, however, the retrieved objects might be inaccurate and small errors are likely to go unnoticed. The main reason for this difference is that information retrieval usually deals with natural language text which is not always well structured and could be semantically ambiguous. On the other hand, a data retrieval system (such as a relational database) deals with data that has a well defined structure and semantics. One may want to criticise this dichotomy on the grounds that the boundary between the two is a vague one.
And so it is, but it is a useful one in that it illustrates the range of complexity associated with each mode of retrieval. Let us now take each item in the table in turn and look at it more closely. In data retrieval we are normally looking for an exact match, that is, we are checking to see whether an item is or is not present in the file. In information retrieval this may sometimes be of interest but more generally we want to find those items which partially match the request and then select from those a few of the best matching ones. The inference used in data retrieval is of the simple deductive kind, that is, aRb and bRc then aRc. In information retrieval it is far more common to use inductive inference; relations are only specified with a degree of certainty or uncertainty and hence our confidence in the inference is variable. This distinction leads one to describe data retrieval as deterministic but information retrieval as probabilistic. Frequently Bayes' Theorem is invoked to carry out inferences in IR, but in DR probabilities do not enter into the processing.
X. INFORMATION VERSUS DATA RETRIEVAL
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 3, Issue 4, April 2013)
792
The inference used in data retrieval is of the simple deductive kind, that is, aRb and bRc then aRc. In information retrieval it is far more common to use inductive inference; relations are only specified with a degree of certainty or uncertainty and hence our confidence in the inference is variable. This distinction leads one to describe data retrieval as deterministic but information retrieval as probabilistic [12]. Frequently Bayes' Theorem is invoked to carry out inferences in IR, but in DR probabilities do not enter into the processing.
Table 1.1
DIFFERENCE BETWEEN DATA RETRIEVAL AND INFORMATION RETRIEVALs
S.No
Characteristics Data
Retrieval (DR)
Information Retrieval (IR)
1 Matching Exact match Partial match, best match
2 Inference Deduction Induction 3 Model Deterministic Probabilistic 4 Classification Monothetic Polythetic
5 Query language Artificial Natural 6 Query
specification
Complete Incomplete
7 Items wanted Matching Relevant 8 Error response Sensitive Insensitive
XI. OTHER TECHNIQUES AND APPLICATIONS
Many other techniques have been developed over the years and have met with varying success. Cluster hypothesis states that documents that cluster together (are very similar to each other) will have a similar relevanceprofile for a given query. Document clustering techniques were (and still are) an active area of research. Even though the usefulness of document clustering for improved search effectiveness (or efficiency) has been very limited, document clustering has allowed several developments in IR, e.g., for browsing and search interfaces. Natural Language Processing (NLP) has also been proposed as a tool to enhance retrieval effectiveness [8],but has had very limited success. Even though document ranking is a critical application for IR [2], it is definitely not the only one. The field has developed techniques to attack many different problems like informationfiltering, topic detection and tracking (or TDT), speech retrieval, cross-language retrieval, question answering, and many more.
XII. CONCLUSION
The field of information retrieval has come a long way in the last sixty-eight years, and has enabled easier and faster information discovery. In the early years there were many doubts raised regarding the simple statistical techniques used in the field.
However, for the task of finding information, these statistical techniques have indeed proven to be the most effective ones so far. Techniques developed in the field have been used in many other areas and have yielded many new technologies which are used by people on an everyday basis, e.g., web search engines, junk-email filters, news clipping services. Going forward, the field is attacking many critical problems that users face in today information-ridden world. With exponential growth in the amount of information available, information retrieval will play an increasingly important role in future. There exist some future aspects like significant quality improvements still a tedious and difficult task, need more research requires and close cooperation.
Acknowledgment
The authors are grateful to the anonymous refers whose suggestions have significantly improved the clarity and content of this article. I would like to express our sincere gratitude towards our Chairman Shri Dev Murti, Principal T. D. Bhist, and Miss Manvi Mishra (Head of Deptt.). Without these members this manuscript is not possible. Under their cooperation we are able to make this manuscript successful. We are also thankful to our Assistant Prof. Preeti Pandey She helps me throughout this research paper. Last but not the least we are heartily thankful to my institution which bestowed this opportunity to me.
REFERENCES
[1 ] LANCASTER, F.W., Information Retrieval Systems:
Characteristics and Evaluation, Wiley, New York (1968).
[2 ] BAR-HILLEL, Y., Language and Information. Selected Essays
on their Theory and Application, Addison-Wesley, Reading, Massachusetts (1964).
[3 ] BARBER, A.S., BARRACLOUGH, E.D. and GRAY, W.A.
'On-line information retrieval, Information Storage and Retrieval, 9, 429-44- (1973).
[4 ] CLEVERDON, C.W.,Evaluation of information retrieval
systems', Journal of Documentation, 26, 55-67, (1970).
[5 ] Stopwords Algorithm: webconfs.com/stopwords.php.
[6 ] Dawson‟s Algorithm: [email protected] or
www.comp.lancs.ac.uk
[7 ] C. J. van Rijsbergen. Information Retrieval. Butterworths,
London, 1979.
[8 ] T. Strzalkowski, L. Guthrie, J. Karlgren, J. Leistensnider, F. Lin, J. Perez-Carballo, T. Straszheim, J.Wang, and J. Wilding. Natural language information retrieval: TREC-5 report. In Proceedings of the Fifth Text Retrieval Conference (TREC-5), 1997.
[9 ] VENKAT N. GUDIVADA Dow Jones Markets, VIJAY V.
RAGHAVAN University of Southwestern Louisiana, Information retrieval on the world wide web. Ieee internet computing,1991.
[10 ]WILLIAM I. GROSKY Wayne State University, RAJESH
KASANAGOTTU University of Missouri, “Effective search and retrieval are enabling technologies for realizing the full potential of the web.
[11 ]For figure, images, diagrams, tables:
http://wang.ist.psu.edu/IMAGE.
[12 ] (van Rijsbergen, C.J. (1979)